基于VEM框架的教学资源共享平台设计
2022-08-15唐小娟
唐小娟
(长沙师范学院 信息科学与工程学院, 长沙 410100)
0 引 言
随着网络通信技术和计算机技术的迅猛发展, 越来越多的学校开始建立专用的网络学习平台, 整合多种优秀资源。虽然这种方法扩大了学生视野, 但也具有一定的局限性, 学校间没有统一的沟通平台, 优秀的资源只能在本校内消化, 造成资源浪费。同时由于教学资源的形式多种多样, 不仅传播速度非常快, 而且其中包含的信息量也是巨大的, 是当前教学活动中主要的辅助资源。因此, 随着教学资源数量的不断增多, 导致越来越多不同类型、 不同属性的资源被混合在一起, 形成了分类难、 管理难、 查找困难的局面。因此, 对其展开资源分类与共享是非常有必要的。
范颖等[1]在云技术的基础上, 建立资源共享平台, 并且分设了教师和学生板块。在教师板块中, 可实现对学生作业的批改、 发布作业内容、 共享优质资源等; 在学生板块中, 可查看教师发布的内容、 与同学讨论问题以及查看共享的资源等。该方法借助云平台, 实现了高效的资源共享, 但并未对资源进行分类, 用户在查找资源时浪费大量的时间。管皓等[2]利用PaaS(PlatformasaService)结构与动态几何、 代数等相结合, 提出了一种新的教学资源共享平台设计方案。该平台分级定制多种教学资源, 深入研究教学资源内容规律, 为用户提供了完全开放的资源共享平台。该方法深入资源内部、 挖掘深度信息, 为学生提供了定制的教学资源, 但这对系统的内存和应用环境要求较高, 一些学校很难实现。
基于上述方案, 笔者在变分期望最大化(VEM: Variational Expectation Maximization)框架的基础上, 改变了传统方法中资源分类与共享分开的局面, 将二者融为一体, 提高了分类性能以及共享效率。笔者设计的共享平台主要由资源处理模块、 特征提取模块、 分类模型以及共享模块4部分组成。4个层次之间协同工作, 前期实现对资源的预处理, 删除冗余信息, 对保留的资源进行特征提取, 将特征度较大的词汇筛选出作为特征词, 然后对特征词运用上下位关系进行分类, 最后进行编号处理, 分别存储, 便于后续共享。
1 基于VEM的教学资源共享平台体系结构
基于VEM的教学资源共享平台由4部分组成, 体系结构如图1所示。

图1 基于VEM的教学资源共享平台体系结构
从图1可以看出, 4个层次之间协同工作、 密不可分, 最顶层的资源收集处理模块[3], 主要工作是进行教学资源的收集以及预处理; 特征提取模块通过特征提取算法选取教学资源中的特征词; 分类器分类模块根据特征提取结果对教学资源进行分类; 资源分类共享模块[4]通过分类结果对教学资源进行分类存储, 教师可直接查找所需要的信息进行共享即可。
2 功能模块设计
2.1 资源收集处理模块
该模块的主要作用是通过采集终端对存在于网络或计算机中的教学资源进行收集处理。对收集的资源进行筛选[5], 将不可读取资源、 劣质资源或重复、 漏缺的资源等进行删除操作, 防止这些无用资源浪费系统空间, 从而提高了平台的整体运行速度。笔者通过VEM实现对教学资源的预处理。
2.2 特征提取模块
由于教学资源信息量巨大, 因此在共享前需对特征提取进行分类。特征提取是指在一套教学资源中, 将可以代表所有资源的特征词项挑选出, 组成关键词集。其主要目的是将作用不大、 包含信息量较小的词汇过滤掉, 针对剩余的资源进行向量维数空间计算, 避免出现过分拟合, 以提高分类的准确性。在教学资源特征提取的多种方法中, 笔者从文本之间语义联系的角度出发, 提出了一种比较合适的特征提取算法。
2.2.1候选特征词语义邻接矩阵构造
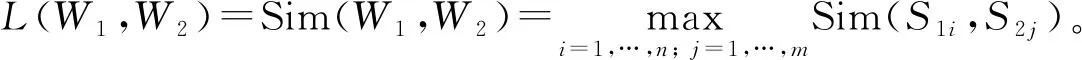
笔者构建的邻接矩阵主要由资源类别之间的语义关系程度决定, 通过以下5个步骤实现。
1) 通过使用分词工具[7]对文本词语进行语义分割, 并将分割后的词语进行标注。
2) 将教学资源中的动词和名词区分开, 分别进行计算。
3) 对每个动词和名词的相似度值进行计算。
4) 通过相似度值, 建立教学资源词语之间的语义相似度表, 如表1所示。

表1 教学资源词语邻接矩阵表
表1中,Wj和Wn表示教学资源中的动词和名词。
5) 特征词语义连接矩阵表达如下

(1)
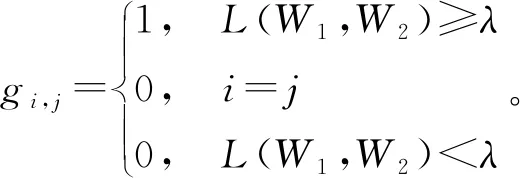
2.2.2 特征词选择过程
将F定义为词语的特征度, 表示候选特征词表征教学资源的重要程度[8]。将所有满足L(W1,W2)≥λ条件的Wj集合定义为Wi的邻接词条。将教学资源中能表达主要内容以及表现力较强的词条看作特征词。在选择特征词时, 应遵循以下两点:
1) 如果教学资源中的词条与某一个词条之间具有较高的连接度, 即可认为该词条的表现力较强, 可作为特征词选择;
2) 如果教学资源中存在特征度较高的词条, 则与之连接的词条同样具有非常高的特征度。
通过上述可知,F(Wi)为Wi的特征度, 用Fi表示与有连接关系的词条集合,nj=|Fj|表示所有满足L(W1,W2)≥λ条件的Wj的总数量。F(Wi)值可通过
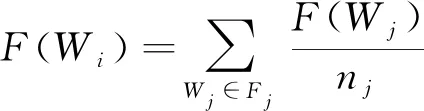
(2)
计算得到。在邻接矩阵H=|gij|基础上, 将式(2)转换为
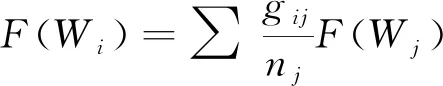
(3)
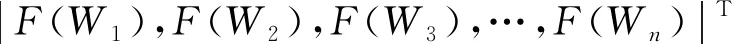
Hx=HTHx
(4)
其中Aij=|gij/nj|。
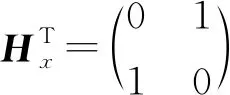
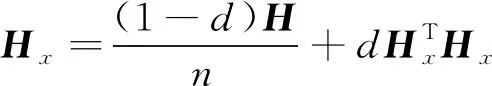
(5)
E为n×n矩阵, 其中所有的元素值都定义为1,d∈[0,1], 笔者将d值设为0.85。
通过上述分析, 得到候选特征词的特征度计算过程如图2所示。
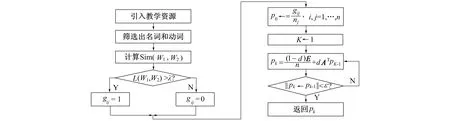
图2 候选特征词特征度计算流程图
假设‖Hk←HxHk-1‖<ε,ε值为10-6, 此时Hk为收敛状态。从Hk中选出特征度[9]较大的词汇作为候选特征词, 以此实现教学资源的分类与共享。
2.3 分类器分类模块
根据上述计算得到的教学资源中候选特征词的特征度, 以此为依据构建分类器, 实现对教学资源的特征分类。主要由以下两部分组成。
1) 从训练样本集中选取具有上下位关系的词汇构成集合。
常用(Ai,Bj)表示两个词汇之间的上下位关系, 在上述提取的特征词汇中, 运用义原树形结构对特征词汇进行上下位关系计算。
为验证概念对之间的上下位关系, 利用首义原在教学资源中的语义距离反映(Ai,Bj)的上下位关系强度
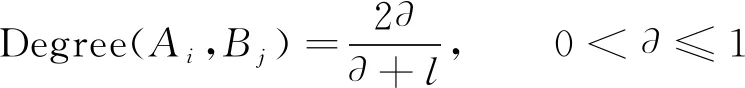
(6)
其中∂为可随意更改的参数项,l为每两个义原之间的上下位距离值。在教学资源中, 如果有两个义原之间可以通过某个子节点实现连接, 则这二者之间的距离可表示为l; 此外, 均认为二者之间无关系,l值为∞。
需要特别注意的是, 当l>3时, 理论上认为两个义原之间的距离较远, 对二者关系强度值则直接为0[10]。
2) 通过概念对的上下位关系反映教学资源中两个词对(A,B)之间的上下位关系。
在词对(A,B)中, 假设A中含有m个概念,B中含有n个概念, 则教学资源中共含有m×n个概念, 所以A、B二者的上下位关系为各概念之间上下位关系的集合, 过程主要由下述步骤实现。
步骤1 计算概念(Ai,Bj)在教学资源中的分布概率。
将F(Ai,Bj)定义为在教学资源中出现的概率,P(Ai,Bj)表示(Ai,Bj)的分布概率, 通过
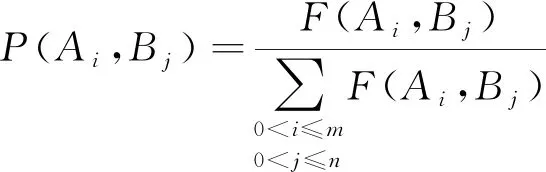
(7)
即可得到P(Ai,Bj)的结果。对(Ai,Bj)频率的确定方法为: 将(A,B)与教学资源中的两个概念对构成概念对集合(Ax,By)。如果A或B只有一个含义, 则可直接与概念对呼应; 如果A或B为多义词, 则需要对该词对进行语义消歧处理, 确保词汇在上下文中的概念。笔者通过义原同现频率方法实现。
步骤2 计算(A,B)的贡献程度。
概念对教学资源中词对的关系程度具有一定的影响, 在计算概念的贡献程度时, 当P(Ai,Bj)的值较大时, 说明贡献程度越高; 反之, 则越低。用CContr_Rate(Ai,Bj)表示贡献程度, 计算过程如下
CContr_Rate(Ai,Bj)=P(Ai,Bj)DDegree(Ai,Bj)
(8)
步骤3 通过式(8)的计算结果, 确定词汇之间的关系强度。
A、B两个词对之间的上下位关系可以理解为概念上下位关系的集合, 所以, 在后续分析词对的关系强度时, 可直接对概念的共享程度之和进行分析即可, 计算如下
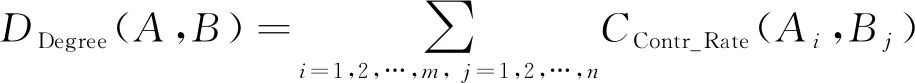
(9)
其中DDegree(A,B)表示0~1之间的整数项, 为将算法误差控制最低, 应预先设定一个阈值, 将计算过程中小于该阈值的关系强度直接过滤。
步骤4 在训练样本中筛选出具有上下位关系的教学资源词对, 构成一个集合。
在训练样本中, 将窗口大小设为Win, 在教学资源内遍历寻找二元词对, 构成一个集合为I1,I1={(w1,w2)|w1,w2}在教学资源内的距离为Win。对训练样本进行特征提取, 构成特征集合I2,I2={wRa|wRa}是根据上述特征选取方法得到的特征项。用I2筛选I1中的词对, 得到集合I3,I3={(w1,w2)|(w1,w2)∈I1,w2∈I2}。通过式(6)计算I3中词对的关系强度, 并进行过滤操作, 将保留的词对按照关系强度不同进行分类, 由此实现对不同种类教学资源的分类。
2.4 资源分类储存和共享模块
根据教学资源分类结果将资源存储于数据库中, 教师和学生可按需求直接查看即可。在进行资源存储时, 数据库起到了不可或缺的作用。由于教学资源数量巨大、 种类繁多, 所以对数据库的要求也比较高, 要同时满足两点要求: 支持分类存储和即时共享。
将分类后的教学资源传送至该模块, 系统自动读取每类资源的类别信息, 将其存储相应的数据库中, 并自动生成编号, 在首页可直接查看, 教师和学生可以轻松找到所需的资源信息, 进行共享和学习。笔者针对教学资源类型多的特点, 建立了一个分类类别数据库表(见表2), 支持超多分类同时查看。

表2 分类类别数据库表
这种教学资源共享模式, 将各学校之间的优秀资源进行了整合, 为教师和学生提供了优秀的辅助教学资源, 无论是对教师自身素质, 还是学生学习兴趣的提高, 都是一种最有效的途径。
3 仿真实验
为验证笔者提出的教学资源共享平台设计方案的合理有效性, 在分类准确性和教学资源共享效率方面与文献[1-2]方法进行仿真实验对比。实验在Windows7系统上实现, 服务器为Internet Information Server 10及以上版本, 资源服务器选用SOL Server 2015。
教学资源分类准确性设计实验。选取了168份教学资源, 将其划分为思政、 英语、 语文、 数学、 科学五大类。利用笔者方法与文献[1-2]方法在分类准确性方面进行验证, 结果如表3所示。
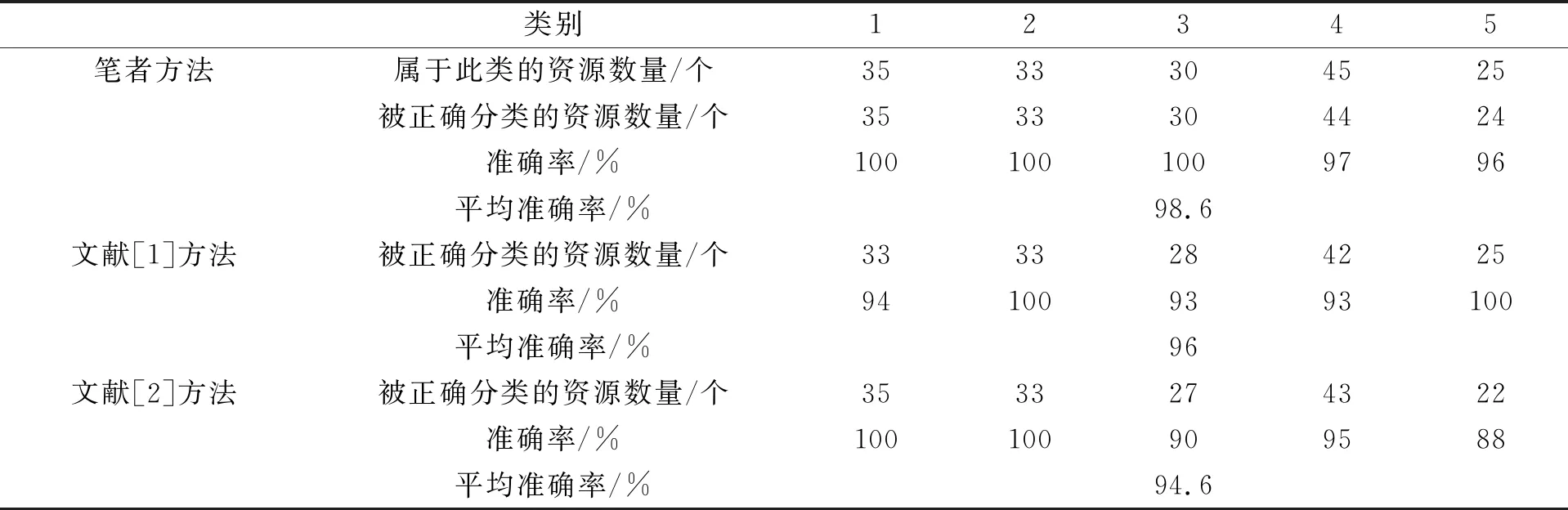
表3 3种方法对168份教学资源的分类结果
从表3中可以看出, 对相同数量的分类对象, 笔者方法对教学资源的平均分类准确性高达98.6%, 明显高于文献[1-2]两种方法, 说明笔者分类算法最优。分类准确性越高, 后期在进行资源共享时起到的推动作用也越大。
共享效率对3种方法对比测试。为确保实验的公平性, 对已分好类的168份教学资源进行共享操作, 实验仅选取了从开始查找到共享结束这段时间作为判断依据, 共进行了10次实验, 结果如图3所示。
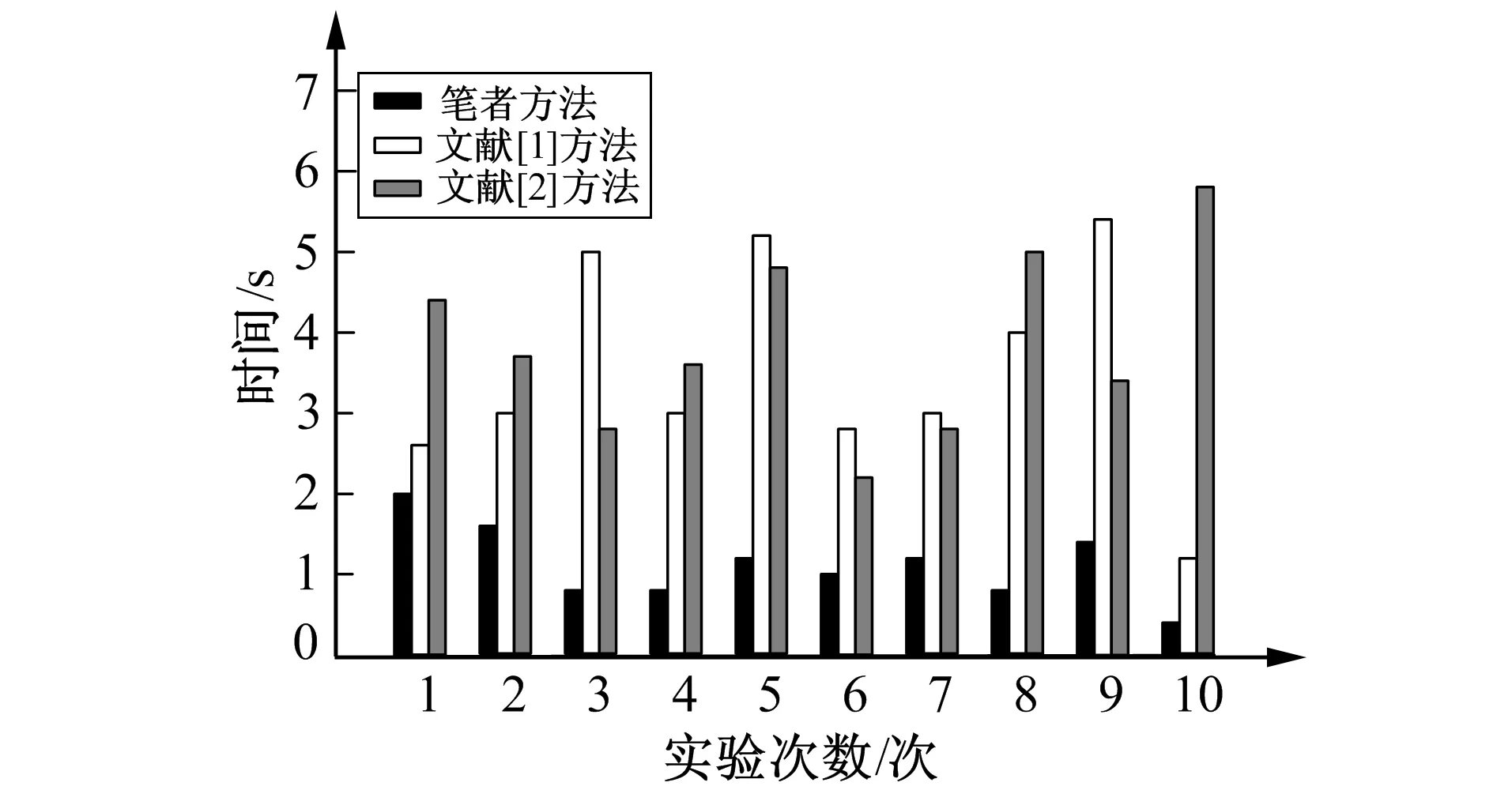
图3 3种方法教学资源共享效率对比
从图3可以看出, 运用笔者方法在对教学资源进行共享时, 平均用时为1.15 s, 而文献[1]方法用时3.5 s, 文献[2]方法用时3.99 s。说明笔者方法将分类与共享融为一体后, 大大提高了资源的共享效率。
4 结 语
笔者在VEM框架的基础上, 提出了教学资源共享平台设计方案, 首次将分类与共享相结合设计了教学资源共享平台。通过实验结果表明, 所设计平台能提高实现教学资源分类准确性, 同时该平台的教学资源共享效率也较好。采用该平台不仅可以提高教师的自身水平, 而且还对学生提高学习兴趣和学习成绩都有较大帮助。
