基于LSM树的云存储数据差异性存储节能优化算法
2022-08-15梁少林
梁少林
(四川文理学院 数学学院, 四川 达州 635000)
0 引 言
随着云计算技术的快速发展, 社会逐步进入大数据时代, 网络数据文件的访问量和储存量呈爆发式增长, 传统的云储存技术已经很难适应现阶段的大数据环境, 也不能满足大基数数据信息的要求。所以在信息量高速增长的背景下, 需要运用更高效的云储存技术帮助数据管理系统更好地发挥应用性能, 提高信息文件的可伸缩性和实用性, 降低储存耗用, 减少数据库负担, 使云储存技术可以紧跟时代的脚步, 成为数据管理中不可或缺的一部分, 关于此项技术的提升和改进已经成为目前的研究热点之一。
杨挺等[1]提出建立一种基于数据优化的文件储存系统, 通过优化日志的储存结构帮助提升数据储存速度, 达到节能效果。但由于日志频繁写入和发出导致系统出现超负载现象, 进而影响数据的储存进度, 降低整体效率。
赵彦庆等[2]采取一种分类进行的方法帮助实现数据的节能储存, 该方法虽然处理速度较快, 但分类识别的基数较大导致误差率较高、 影响储存精度。
基于上述问题, 笔者提出一种基于LSM(Log Structured Merge)树的云存储数据差异性存储节能优化算法, 利用LSM树的高效数据压缩及分类重复组件的特点, 能有效实现数据的节能储存。该方法还可对有效范围内的重复数据进行排查清除, 从而降低了储存功耗, 达到节能优化的效果。仿真实验证明, 本方法不仅数据的平均耗用功率较低, 还对噪声数据和冗余数据有较好的去除效果, 能实现有效的数据节能优化储存。
1 基于LSM树的数据分片储存模型设计
1.1 LSM树的基本构架
LSM树是一种支持高速数据搜索的量化性树状储存结构, 其基本工作思路是通过其核心特点帮助数据储存实现网络分层, 并提高数据的读写性能。可将储存结构经过分层分为内存和文件两部分, 从而提高数据的处理效率, 使后续节能存储算法有效实施, 其LSM树的基本构架如图1所示。

图1 LSM树的基本构架
通过上述对LSM树基本结构的研究与分析, 并结合云储存数据的差异性特点, 建立相应的数据储存模型, 具体判断数据云储存节点的耗时及传输速度, 再进行详细的计算与分析, 为后续的储存节能算法提供有效帮助。
1.2 基于LSM树的数据分片储存模型
设模型中的数据储存节点的数量为n, 文件为fi, 储存大小为S, 全部数据的网络带宽[3]为B, 链路数据长度为L, 数据在网络信道中的实时传输速度为v。其中储存节点、 各类用户端以及PC端对数据进行传输、 储存、 整合等操作处理产生的延迟为tc。所有文件在网络信道中出现的总传输延迟为T; 数据发送延迟为Ts; 数据接收延迟为Tt; 数据处理延迟为Tp, 通过各储存节点确定, 此时, 若不对数据文件进行分割, 则有
T=Ts+Tt+Tp
(1)
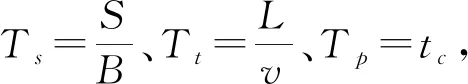
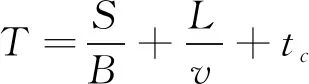
(2)

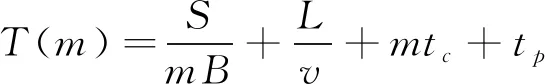
(3)
式(3)表示在数据分割的情况下, 经分割后的文件在进行数据传输时, 产生的时间延迟是不分割时的1/m倍, 提高了m-1倍的数据处理效率, 并且还可保证传输延迟不会增加, 随着数据储存节点数量的增多, 即可根据上述步骤, 对所有数据文件fi进行传输、 储存、 整合的处理时间都可实现相应计算。
为提高储存节点的数据传输效率, 设1/T(m)为储存节点的分割数据映射算法[4]效率, 直接数据映射算法为1/T, 则分割映射算法与直接映射算法的工作效率比值为
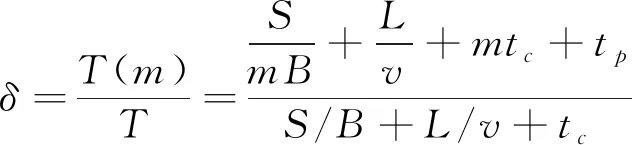
(4)
其中δ为分割映射算法与直接映射算法的工作效率比值, 若δ<1, 表示数据的分割映射算法比直接映射算法的工作效率高[5]; 若δ=1, 表示二者的数据储存节点的传输效率相同; 若δ>1, 表示数据的分割映射算法的工作效率低于直接映射算法。在δ<1的情况下,δ越小, 表示分割映射算法效率上升空间越大, 效果越好。


(5)


(6)
根据式(4)及对δ数值的具体分析, 如果得出δ>1, 则说明基于分片模式下的数据储存模型进行的数据传输效率是优异的。考虑到实际的数据云储存情况, 如果通过模型计算得出δ=1或δ<1, 则不需要进行分片储存的设计, 此时文件fi采用的关系措施表达式为
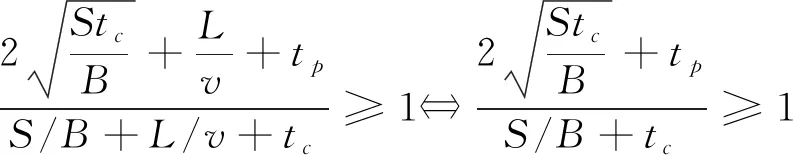
(7)
基于式(7)的原理并结合实际的数据云储存情况和动态网络信道中的储存节点的网络带宽B, 文件发送、 接收的实际延迟tp, 以及整合处理的实际延迟tc, 就能对不同数据文件的数量及大小S准确有效地确定出是否需要分片储存。采用分片储存模型可有效减少节点处理的时间, 提高工作效率。
2 节能优化算法
在一般的服务器系统中能耗较大的主要为数据处理器、 固态内存以及各类服务磁盘[7]。所以从最主要的服务器入手, 分析其中储存节点的静态功耗与动态功耗的详细构成, 以得到节能优化的重要切入点。假设数据云储存的静态功耗为Pstatic、 动态功耗为Pdynamic、 服务器功耗为Pserver, 3者的关系为
Pserver=Pdynamic+Pstatic
(8)
其中数据储存的动态功耗
Pdynamic=aCV2f
(9)
其中a为数据云储存线路翻转频率,C为数据的负载电容,f为在各个时刻下数据的传输频率,V为储存节点传输电压, 并且传输频率f与电压V和系统的实际性能成正比, 则将上述数据云储存服务器进行功耗简化后得到
Pserver=σc+μcsa,a>1
(10)
其中σc为空闲数据储存功耗;s为储存服务器的数据服务速率并且与式(9)中传输频率f成正比;μc和a为常数无特殊意义, 与笔者云储存节点设备有关, 其值在0~3之间, 结合实际情况, 笔者采用1,1.66,1.62作为a的取值。
因为在网络通信中, 数据云储存能耗与功耗是两种不同的概念[8], 所以需要分别进行计算, 得出最节能的优化算法。云储存能耗是指在服务器中某一段时间内的全部节点所消耗的能量总和, 单位为J, 设在Δt时间内的能耗定义为
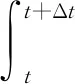
(11)
其中E为在Δt时间内的能耗,P为数据云存储的功耗。能耗在数据的云储存节点中, 可根据实际情况并结合数据块的内部储存结构设置休眠区域, 从而达到储存节能的目的[9]。设所有休眠节点为sd, 则除特殊设置的区域外的休眠节点为k-sd, 在具体实施节能算法前, 所有数据集群的k个储存节点都是较为活跃的, 此时数据集群和k个储存节点的总能耗为
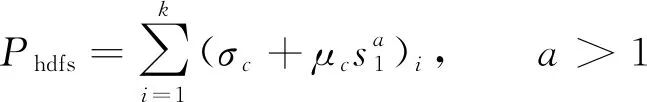
(12)
当实行设立sd个休眠节点[10]后, 剩余k-sd个休眠节点与集群的总消耗为
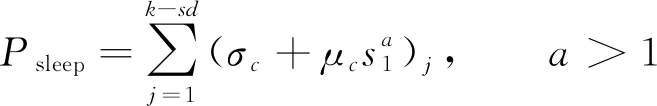
(13)
其中Psleep为休眠节点功耗, 则数据块在储存结构内部运用节能算法产生的功耗为
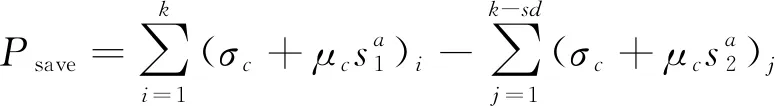
(14)
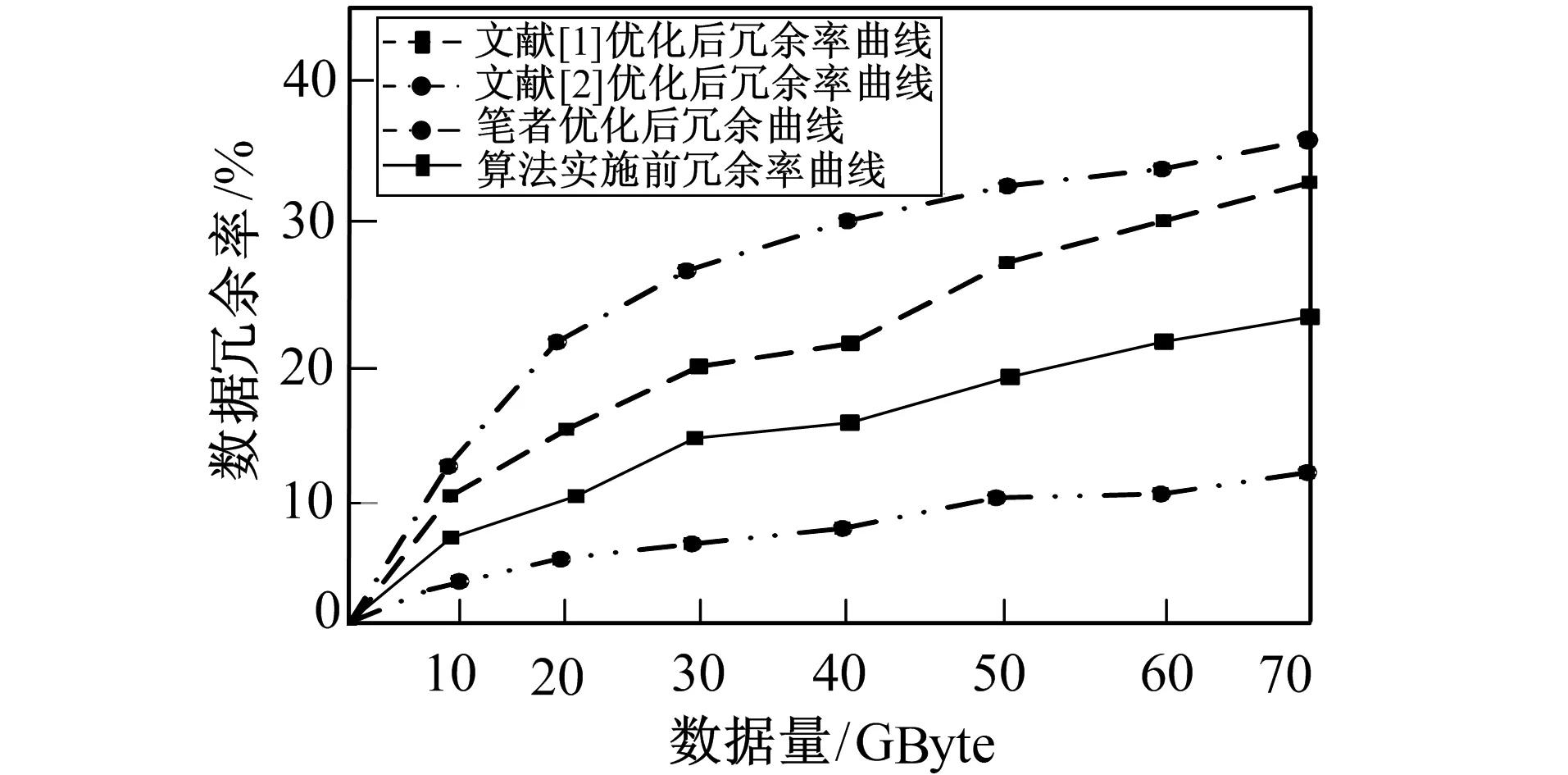
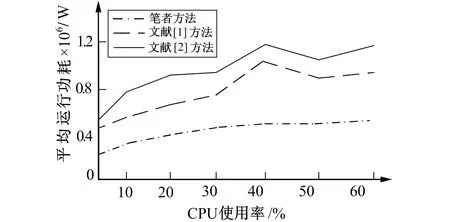
其中s1为算法在执行前服务器产生的速率,s2为算法在执行后服务器产生的速率, 通常有s1 (15) 其中Esave-Δt为时间内的储存节点消耗的能量。根据式(15)即能对在数据集群中的某一特定行列数据进行能量消耗计算, 并对比实施前与实施后的服务器速率, 减少了储存节点的数据传输时间、 降低功耗、 增强整体效率。 为保证实验数据的精准性和合理性, 采用模拟法构建真实的云储存环境。储存运行平台由Image Net数据集构成, 该数据集内包含各种可视化的数据和各类型的信息文件, 同时还包括2个总储存管理节点、 40个数据储存子节点、 2个客户端管理节点以及多个可运行的网络交换机, 从而确保算法的可实施性和实验数据的真实性。空闲功耗是指计算机在没有工作时所产生的功耗, 其值为70/mips。数据采样频率是指对一串模拟信号采样的频率, 本实验的数据采样频率每3 s采集1次数据。上述条件满足实验环境。 模拟实际的云储存实验环境需要进行相应的动态数据生成, 文件大小约为256 kByte~10 GByte, 并根据网络通信中不同储存节点模拟建立出对应的数据可用带宽, 以便于实验结果分析。假设储存节点的带宽为正态分布N(B,δ2), 则为还原实际情况, 需要在实验前对模拟环境中的每个数据储存节点进行带宽变化处理, 使每个节点的带宽都相同, 这样不会出现差异性的影响, 可确保实验顺利进行。数据带宽的变换频率为每10次实验平均变化1次, 并控制在64~512 Mbit/s之间, 分别在64 Mbit/s、128 Mbit/s、256 Mbit/s、512 Mbit/s 4种带宽情况下进行实验, 带宽频率越高其数据储存就越受影响, 这能更准确地判定出实验效果的优异程度。 将笔者云储存的节能算法与文献[1-2]中的方法进行性能对比分析, 通过数据冗余率、 数据储存功耗的结果及评价验证笔者算法的有效性。 数据的冗余率为在网络通信中经过一定算法改进后, 数据库中表的重复、 属性的重复、 元组的重复以及指定文件的重复率, 其数值越大表示数据重复的消除性越差, 节能效果越差。基于3种方法的冗余率对比结果如图2所示。 图2 3种方法的冗余率对比结果 从图2可以看出, 基于文献[1]和文献[2]方法得到的数据冗余率曲线出现了大幅度上升, 这是由于数据间差异性大且没有进行合理的划分, 导致同一信息多次存储, 从而使文件信息的重复性逐渐增强, 使其更加难以控制和清除, 不方便后续的读取和寻找, 文献方法数据节能储存效果较差; 而从笔者方法得到的数据冗余率曲线可以看出, 其曲线走势较为平稳, 一直处于缓慢的上升状态同时也没有出现消除停滞的现象, 并且与原始的冗余曲线相差较大, 说明在整个储存节能过程中笔者方法都可以很好地解决异常数据问题, 保证数据节能存储过程中的数据稳定性, 降低数据判定误差、 缩短耗时、 增强整体效率。 通过对文献[1-2]及笔者方法的数据云储存功耗实验结果分析, 并采用分别计算静态功耗Pstatic、动态功耗Pdynamic以及服务器功耗Pserver的方法实现算法性能的有效对比。为保证3种功耗与CPU的实时使用率有一定的关联, 方便实验数据的有效获取, 需要给出相应的线性关系模型使实验顺利进行, 其模型为 Pserver=Pmax+(Pdynamic-Pstatic)(2u-ur) (15) 其中Pmax为服务器在满负荷时的运行功耗;u为计算机CPU的实时使用率;r为数据校准系数(即理论功耗与实际功耗之间的方差)。根据式(15)对3种方法的算法运行功耗进行对比实验, 结果如图3所示。 图3 3种方法的运行功耗对比 由图3可知, 随着CPU使用率的不断上升, 3种方法的平均功耗曲线都发生了变化, 其中基于文献[1-2]的曲线变化较为明显, 二者在CPU使用率为40%时, 上升幅度最大且数值间的密度差距较大, 说明40%的使用率是一个数据重载阈值。当数据储存的数量过于庞大时会出现CPU超负荷的现象, 使平均功耗迅速增加、 储存速度降低、 影响整体效率。其主要原因是没有引入关键的异常数据清除技术, 导致过程中频繁受到噪声数据的影响, 并且随着数据处理量的不断增加, 影响程度越来越大。而基于笔者方法的平均运行功耗曲线相对较为平稳, 且上升幅度不大, 说明在整个节能算法过程中对异常数据和大基数数据的处理效果较好, 即使处理数据超出CPU负荷也能保持整体功耗不超出预定值, 效率较高。 笔者针对云储存环境高耗用、 低效率的问题, 通过建立基于LSM树的分片储存模型帮助辨别大范围内的大基数数据, 可缩小一定节能处理范围, 从而降低了后续操作难度、 提高工作过程效率。通过对比实验结果证明, 基于笔者方法的数据冗余率消除效果最好、 耗用最低、 稳定性最强, 综合判定在各性能对比下都是极为优异的。对一些数据结构较为复杂, 负载较大的文件, 如何通过高压操作完成性能互补是下一步的研究方向。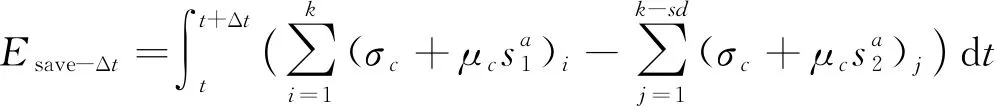
3 仿真实验
3.1 实验环境
3.2 数据冗余率对比分析
3.3 数据储存功耗对比分析
4 结 语
