基于改进GA算法的高速公路交通拥堵状况预测
2022-08-15黄承锋陈一铭李元龙
黄承锋, 陈一铭, 李元龙
(重庆交通大学 经济与管理学院, 重庆 400074)
0 引 言
近年来高速公路覆盖率日益增大, 交通管理难度越来越高, 同时随着社会经济总量不断提升, 车辆保有量逐年递增, 导致交通拥堵情况日益严峻, 这对行车成本、 环境污染、 事故发生概率、 出行时长均有巨大影响, 甚至会阻碍、 制约城际之间的发展协调性[1]。因此, 交通拥堵状况预测方法成为目前重点研究课题之一, 科学预测拥堵状况不仅能为及时疏通车流提供可靠的参考数据, 从而减少发生道路交通拥堵。
戢晓峰等[2]基于深度学习理论, 建立一种长短期记忆-支持向量机回归预测模型, 在预测节假日不同时段、 天气以及流量状态下的交通流时, 表现出较好的适用性; 蔡延光等[3]根据暴雨天气特点, 通过融合布谷鸟搜索改进算法与径向基函数神经网络, 设计出一种收敛速度较快、 预测精度较高的交通流预测模型; 温惠英等[4]在长短期记忆神经网络中融入遗传算法, 架构出预测性能较好的交通流预测模型。
虽然上述方法均有效预测出了高速公路的交通流, 但不能满足当前的预测精度需求, 因此, 笔者基于流量统计理念, 利用改进遗传算法设计了一种交通拥堵状况预测模型。将交通流量参数作为描述拥堵状况特征的物理量, 其具有客观反映拥堵状况的能力; 将固定检测技术与移动检测技术相结合, 使流量数据更准确; 为提升预测精度, 采取不同策略识别、 处理不同种类的异常数据; 设计的预测模型中归一化处理有助于提升网络训练与收敛速度。
1 交通流量统计
1.1 流量数据采集
在高速公路附近与行驶在该条公路上的移动车辆中分别安装多个固定交通检测设备[5]与移动图形处理器[6], 采用互补性较强的固定与移动检测技术完成采集任务, 以取得完善、 精准的交通流量数据, 为后续拥堵状况预测奠定良好的数据基础。
因单一数据无法准确描述高速公路交通拥堵状况, 故选取与交通流量息息相关的3个参数, 从宏观角度反映公路交通流量特征, 参数流量q、 密度k以及速度v分别为交通系统负荷、 交通流量内行车自由度、 交通系统服务水平, 三者之间的关系如下
q=kv
(1)
参数界定内容与计算方法如下。
1) 流量q。其反映某地单位时间内的行车数量。假设在T时长的检测时段内, 总共行驶过n台车辆, 则交通流量为
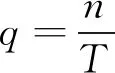
(2)
2) 密度k。其反映某地单位距离内的现有车辆个数。由于该参数属于瞬时值, 受距离、 时间干扰较大, 故替换成由时间占有率Rt与空间占有率Rs构成的占有率参数, 其中前者表示交通流量状态, 后者表示交通密度, 计算公式如下
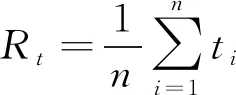
(3)
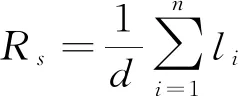
(4)
其中高速公路的检测距离为d, 通过固定交通检测器测量长度为li的第i台车辆需要花费ti时长。
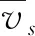
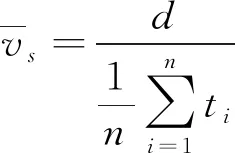
(5)
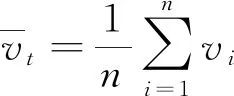
(6)
其中vi为第i台车辆通过检测位置时的速度。
1.2 流量数据预处理
为保证数据质量, 识别、 处理具有不同异常情况的交通流量数据。
1) 冗余数据识别与处理。采用图1所示的流程识别冗余数据, 直接去除识别结果。
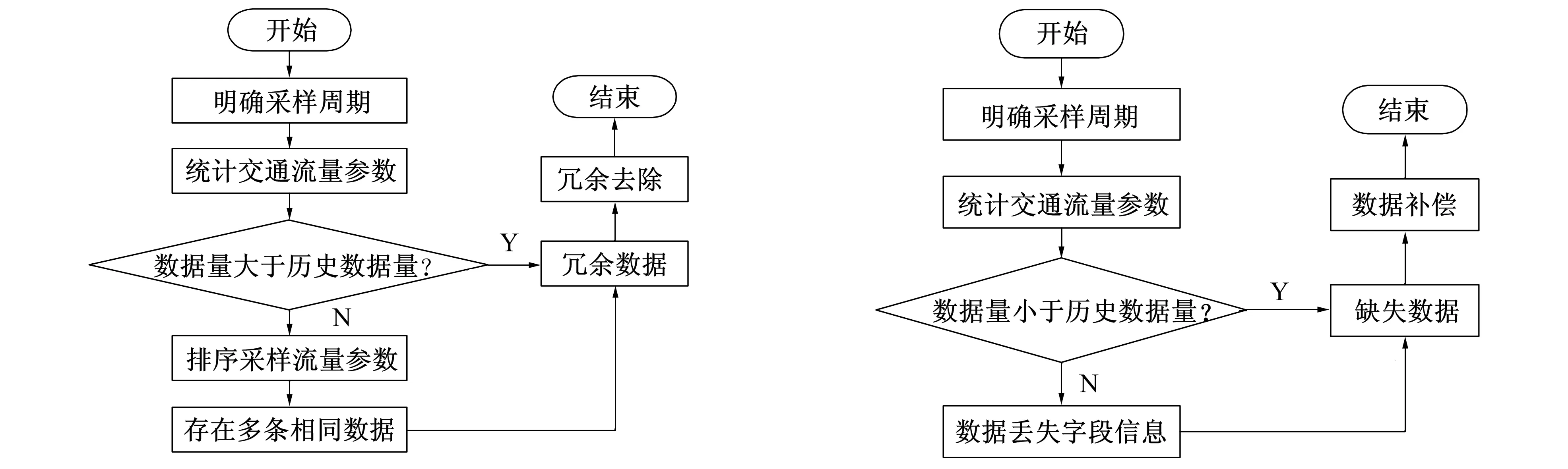
图1 冗余数据识别流程图 图2 缺失数据识别流程图
2) 缺失数据识别与处理。采用图2所示流程识别缺失的交通流量数据。
针对未更新或少更新与字段信息丢失等两类缺失数据, 采取不同的补偿策略。
1) 当缺失数据属于未更新或少更新情况时, 分为部分缺失与大量缺失两种状况, 前者丢失的是不大于3个连续采样周期的数据量, 后者丢失的则是超过该采样周期的数据量。对部分缺失数据量, 利用K近邻非参数回归补偿算法[7], 依据图3流程进行完善。
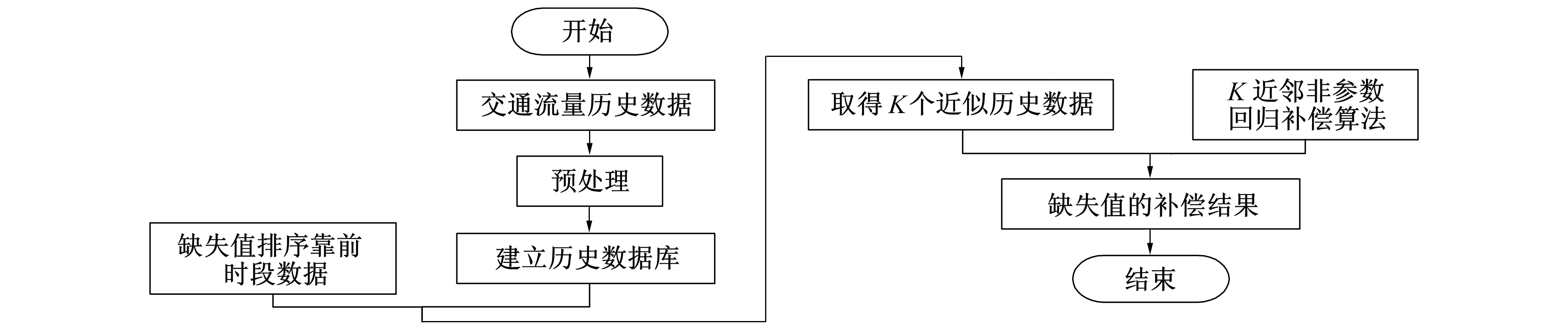
图3 补偿算法流程图
2) 字段信息丢失。若极少量数据缺失, 则忽略不计; 若大量数据缺失, 则补偿方法同上。
3) 错误数据识别与处理。假定样本均值与标准差分别为μ、δ, 则车辆在单位时段中行车时间的正态分布[8]范围为[μ-2δ,μ+2δ], 当行车时间比合理时限小时, 认为对应数据为错误数据并去除该数据; 对合理时限内的数据, 通过方程组
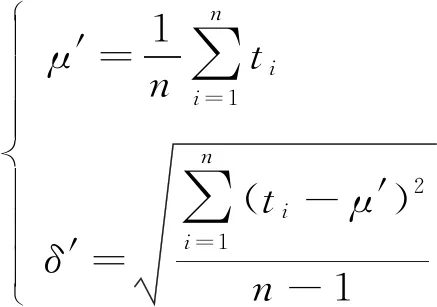
(7)
求解均值与标准差。
若将解值代入[μ-2δ,μ+2δ]后超出给定的正态分布范围, 则去除该错误数据; 待全部数据均位于正态分布范围内, 停止迭代, 错误数据全部被处理。
2 高速公路交通拥堵状况预测模型构建
依据高速公路基本服务水平分析指标与分级标准, 划分交通拥堵状况如表1所示的6个等级。在拥堵状况判定阶段设定阈值Tthr, 根据交通流量的速度标准化函数v′与占有率标准化函数R′, 通过

表1 高速公路交通拥堵状况等级
Tthr=βv′+γR′
(8)
求解出对应等级的交通拥堵状况阈值。其中β、γ分别为对应参数权值。
2.1 基于遗传算法-反向传播神经网络的预测模型
利用反向传播神经网络改进遗传算法[9], 构建拥堵状况预测模型如图4所示。

图4 基于遗传算法-反向传播神经网络预测模型结构图
该模型的预测过程如下。
1) 经过加载样本数据, 实施归一化训练, 令取值范围为[0,1]。
2) 明确网络层数及其节点个数, 若输入层有p个节点, 隐藏层有θ个节点, 输出层有h个节点, 则通过不等式

(9)
明确隐藏层节点个数。其中变量因子a的取值范围为[1,10]。
3) 为避免快速饱和, 从[0,1]中选取较小值, 赋值初始网络权重与阈值。
4) 在遗传算法内输入初始权重与阈值, 获取最优解。
5) 输出结果, 通过误差函数不断训练网络, 以取得最佳权重与阈值, 待满足预设条件后终止训练。
6) 基于训练过的预测模型, 把测试样本数据输入模型, 输出最终的流量预测结果。
2.2 基于遗传算法-支持向量机回归的预测模型
图5为遗传算法与支持向量机回归[10]相结合的拥堵状况预测模型。
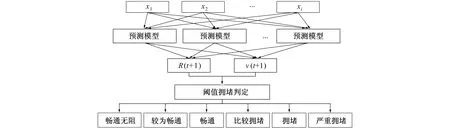
图5 基于遗传算法-支持向量机回归的预测模型示意图
该模型的预测过程如下。
1) 输入流量数据, 将数据归一化至0~1之间, 取得训练与测试数据;
2) 编码处理模型的不敏感损失ε、 惩罚参数C、 核函数参数σ, 设定筛选参数标准为K-交叉验证[11]的均方偏差均值;
3) 针对支持向量机回归核函数[12], 其表达式由高斯径向基核函数实现界定, 即
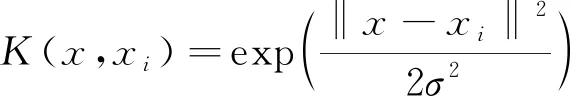
(10)
4) 将得到的不敏感损失ε、 惩罚参数C以及核函数参数σ的最优解代入遗传算法-支持向量机回归预测模型, 预测出交通流量参数数据。
2.3 混合预测模型
基于上述两种预测模型, 根据确定的各模型权重, 经加权处理构建出一种混合预测模型, 如图6所示。
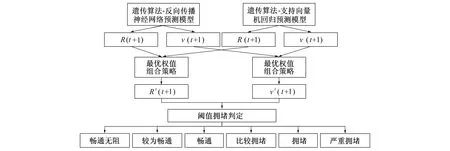
图6 混合预测模型示意图
假设遗传算法-反向传播神经网络预测模型的预测结果为f1, 遗传算法-支持向量机回归预测模型的预测结果为f2,w1、w2分别为两模型的对应权值系数, 由此得到混合预测模型的交通流量数据预测表达式如下
fb=w1f1+w2f2
(11)
其中b为正整数, 取值为1或2。
为提升模型预测准度, 采用最优权值组合策略获取模型权值系数, 该策略目标函数及约束条件如下
max(min)Q=Q(w1,w2)
(12)
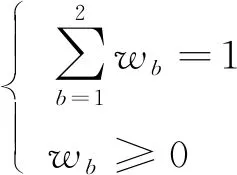
(13)
假设时刻t的模型预测偏差为ebt, 混合预测模型的偏差平方和为
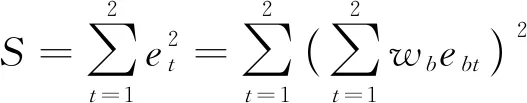
(14)
结合偏差平方和S与目标函数Q, 推导出最小化偏差平方和的目标函数表达式如下
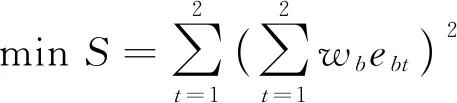
(15)
式(15)的约束条件同式(13)。若两预测模型在t时刻预测的拥堵偏差分别为e1t、e2t, 则构建下列方程组
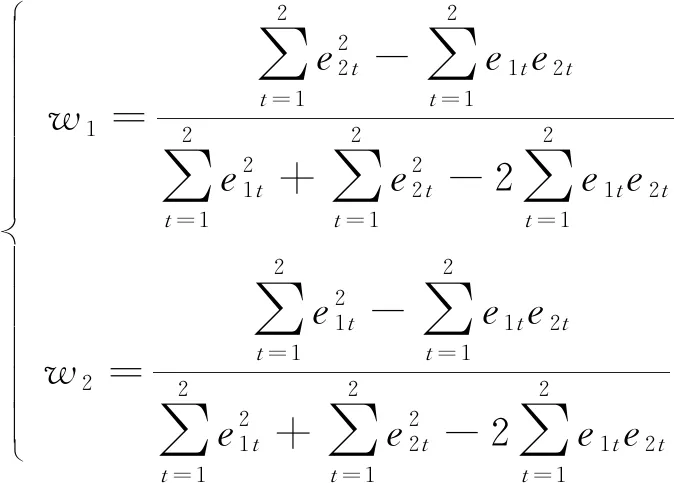
(16)
通过式(16)修正混合预测模型的权值系数。对遗传算法-反向传播神经网络与遗传算法-支持向量机回归预测模型, 通过训练数据并经组合后得到混合预测模型, 根据测试数据预测交通拥堵状况, 设定该混合模型的预测时间间隔为10 min, 即每隔10 min可以获得一个新的预测结果。
3 高速公路交通拥堵状况预测实验
选取某地区的一条高速公路, 在其周边与移动车辆上安装多个检测器, 每隔60 s采集一次公路上的行驶车辆流量、 速度以及占有率等交通流量参数数据, 经预处理后, 将连续10 d内得到的13 482条流量数据划分为两种数据集: 训练数据集与测试数据集。前者用于模型训练, 后者用于检测模型性能。
为检验预测有效性与精准度, 将测试数据集输入已训练的模型中, 得到如图7所示的交通流量数据预测结果。通过对比图7中的实际交通流量参数数据可以看出, 笔者模型针对不同种类的异常数据, 分别采取了不同的识别与处理策略, 使数据更加完整, 预测质量得到保证, 神经网络模型根据误差函数不断训练网络, 取得了最佳权重与阈值, 因此, 具有较高的拟合度与预测精度。
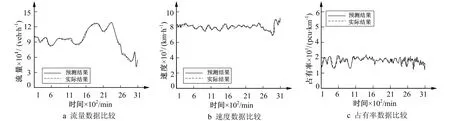
图7 交通流量参数数据预测结果拟合示意图
将标准化处理测得的交通流量参数数据, 代入阈值计算式(8)中, 得到图8所示的交通拥堵状况预测结果。从图8可以看出, 该模型能有效预测出高速公路的交通拥堵状况, 且预测精准度较为理想。这是因为笔者利用与交通流量息息相关的3个参数, 从宏观角度全面、 准确地反映了高速公路的交通流量特征, 不同种类异常数据的识别与预处理阶段, 为拥堵状况预测提供了高质量数据, 将两个预测模型融合, 有助于使两模型得到互补, 经加权处理得到混合预测模型, 并采用最优权值组合策略获取模型权值系数, 在一定程度上提升了模型的预测精准度。
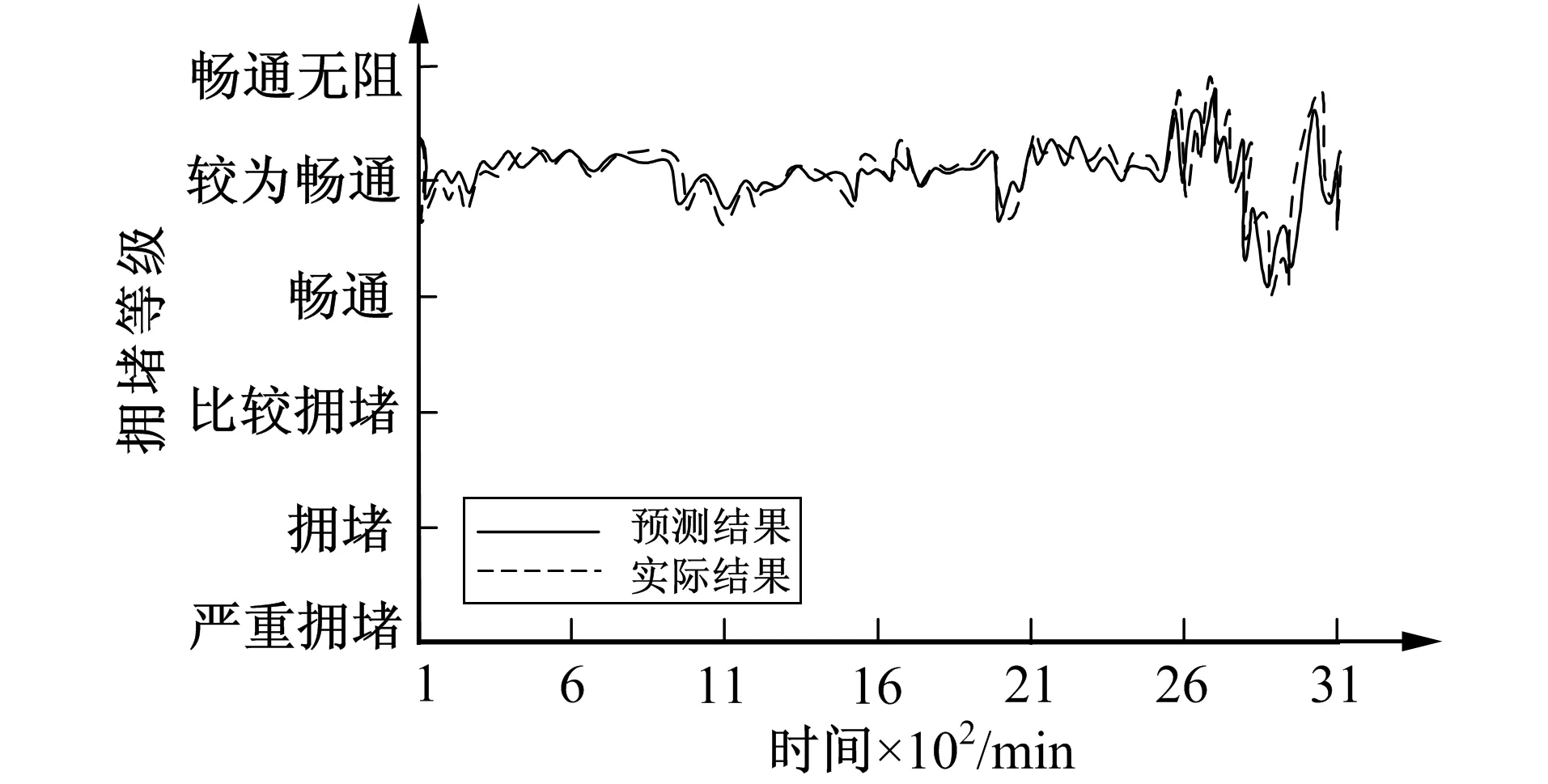
图8 交通拥堵状况预测结果
4 结 语
随着国民经济水平迅猛上升, 城市化进程快速发展, 高速公路领域日益繁荣, 但同时也大幅增加了拥堵的概率。交通拥堵不仅会增加车辆运营成本, 而且还将导致交通事故频发, 延长行车时长, 加剧污染。为缓解高速道路拥堵问题, 交通状况预测技术受重视程度越来越高, 因此, 笔者从宏观的交通流量数据入手, 构建出基于改进遗传算法的交通拥堵状况预测模型。虽然目前研究已经取得了一定的成果, 但仍需针对以下方面加以完善, 进一步加强模型的预测精度与适用性: 需根据公路的重要与非重要时段、 优劣天气条件等影响因素, 综合性地预测拥堵状况; 应基于笔者预测模型, 采用浏览器/服务器模式(B/S: Browser/Server)结构建立一种自动预测系统, 使交通状况预测方法趋向更便捷、 更人性化的方向发展。
