Cyberbullying and Cyberviolence Detection: A Triangular User-Activity-Content View
2022-08-13ShuwenWangXingquanZhuWeipingDingandAmirAlipourYengejeh
Shuwen Wang, Xingquan Zhu,, Weiping Ding,, and Amir Alipour Yengejeh
Abstract—Recent years have witnessed the increasing popularity of mobile and networking devices, as well as social networking sites, where users engage in a variety of activities in the cyberspace on a daily and real-time basis. While such systems provide tremendous convenience and enjoyment for users,malicious usages, such as bullying, cruelty, extremism, and toxicity behaviors, also grow noticeably, and impose significant threats to individuals and communities. In this paper, we review computational approaches for cyberbullying and cyberviolence detection, in order to understand two major factors: 1) What are the defining features of online bullying users, and 2) How to detect cyberbullying and cyberviolence. To achieve the goal, we propose a user-activities-content (UAC) triangular view, which defines that users in the cyberspace are centered around the UAC triangle to carry out activities and generate content. Accordingly,we categorize cyberbully features into three main categories: 1)User centered features, 2) Content centered features, and 3)Activity centered features. After that, we review methods for cyberbully detection, by taking supervised, unsupervised, transfer learning, and deep learning, etc., into consideration. The UAC centered view provides a coherent and complete summary about features and characteristics of online users (their activities),approaches to detect bullying users (and malicious content), and helps defend cyberspace from bullying and toxicity.
I. INTRODUCTION
BULLYING is an aggressive and intentional act or behavior frequently conducted by one or a group of individuals against a victim, who often cannot defend him/herself[1]. Bullying can be carried out in many types of forms such as verbal bullying, physical attack, sexual humiliate, social isolation, psychological torment [2]. Cyberbullying is another evolution method from direct physical bullying to electronic devices, i.e., in a cyberspace [3]. National Crime Prevention Council defines cyberbullying as “similar to other types of bullying, except it takes place online and through text messages sent to cell phones. Cyberbullies can be classmates,online acquaintances, and even anonymous users, but most often they do know their victims [4]”. Similar definitions have also been found in several other related online incidents, such as cyberstalking, cyberharassment, online cruelty, or online cruelty in general [3], [5]. In many occasions, online cruelty is also referred to as cyberbullying [3], however, some research considers cyberbullying being part of online cruelty activities.Other online forms of digital activities such as online harassment and online sexual harassment should also be considered as online cruelty [5].
A. Cyberbullying vs. Cyberviolence
Cyberviolence is another term relevant but different from cyberbullying. A key difference between them is that the former targets on a group of individuals with strong political preference, whereas the latter is more focused on individuals,as shown in Fig. 1. A categorization and comparison between cyberbullying and cyberviolence are also summarized in Table I.
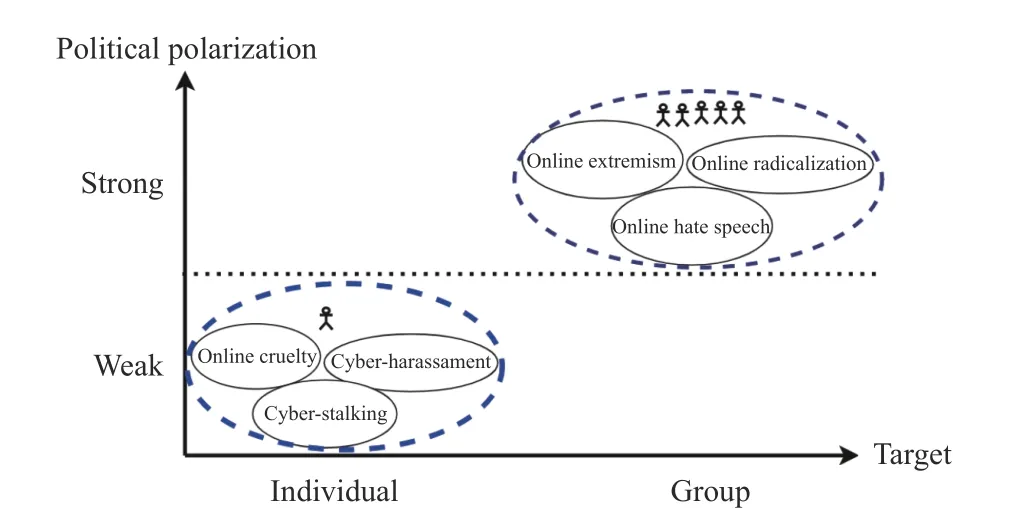
Fig. 1. A simple comparison between Cyberbullying and Cyberviolence w.r.t. targeted audience and political polarization.
In this paper, we consider online cruelty activities along with cyberharassment and cyberstalking part of cyberbullying.Cyberharassment, in general, refers to online interpersonal attacks which occur repetitively, intrusively and provokes anxiety [6]. Cyberstalking is to stalk or harass an individual,group or organization with electronic equipment [7], [8].
Online extremism, online hate speech and online radicalization are forms of cyberviolence. Online extremism is an express of extreme views of hatred toward some group usinginternet technologies to “advocate violence against, separation from, defamation of, deception about or hostility towards others” [9]–[11]. Online hate speech is an expression of conflict between different groups within and between societies based on race, religion, ethnicity, sexual orientation, disability, or gender. Radicalization is a process in which individuals or groups oppose the political, social, or religious status with increasingly radical views. There exists a strong dependency between cyberbullying and digital media such as hurtful images and comments where those contents can remain online accessible to public before they are reported and deleted. The explosive development of Internet technologies provides people more and more opportunities to be exposed to online information, from daily life to social interaction.

TABLE I SUMMARY OF CYBERBULLYING AND CYBERVIOLENCE
Although a large number of audience and users are attracted by continuous and immediate online social media which prompts the wide, quick spread of online contents, due to identification difficulty and loose supervision of the overall internet environment, cyberbullying has become unscrupulous among which, some even mislead to cybercrime, and hate speech. One of the most distinguishing features of cyberbullying is that victims can hardly find an effective solution to get away from it. In other words, even a one time bullying action can lead to continuous ridicule and humiliation for victims,which is possible to result in feelings of powerlessness for the victims. Besides, because of the anonymity feature of cyberbullying, failing to recognize the identity of bully increases feeling of frustration and powerlessness of the victims.According to National Center for Education Statistics, among students ages 12−18 who reported being bullied at school during the school year, 15% were bullied online or by text[12]. Victims of cyberbullying generally develop certain psychological problems such as anxiety, depression, poor performance or committing suicide. Therefore, early cyberbullying detection becomes the utmost important.
B. Computational Approaches for Cyberbullying Detection
Computational approaches, such as machine learning, have been used for automatic detection of cyberbullying, and a general framework used by these methods is summarized in Fig. 2. Online social networks contain useful information from user posts, interactions, etc. Those information can be extracted as features which will then be fed into models to learn and make prediction. One typical way of currently existing studies is using machine learning classifier, combined with text mining, as supervised learning approach in social media[13], [14]. For example, Random Forest is used based on user personality features decided by Big Five and Dark Triad models for Twitter cyberbullying detection and achieves up to 96% precision [15]. Deep learning models bidirectional long short-term memory (BLSTM), gated recurrent units (GRU),long short-term memory (LSTM), and recurrent neural network (RNN) are applied in detecting insults in Social Commentary and their results indicate that deep learning models are more effective when compared with other traditional methods [16].
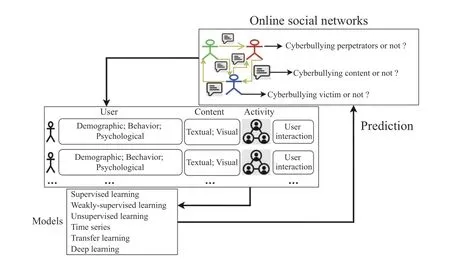
Fig. 2. A conceptual view of computational framework for Cyberviolence and Cyberbullying detection.
Many methods exist for cyberbullying detection. While technical solutions vary, these approaches often face and address similar challenges. First of all, due to the limitations of social media, adequate and informative data collection cannot be guaranteed and users can modify, delete their social media content at any time, which means data availability changes with time. Traditional data cleansing methods may mistakenly filter out important information, which will hurt the ability of machine learning models to discriminate bullying and normal expressions. Besides, unstructured content can be found in multiple language formats and styles, which is often grammatically inaccurate. Another common challenge is that cyberbullying content is quite rare and only limited amount of cyberbullying will be found even in large datasets,which poses a great challenge for traditional machine learning models.
C. Existing Survey, Difference, Contributions

Fig. 3. The systematic literature review process of the proposed study.
A handful of survey already exist to focus on cyberbullying detection from different perspectives. Techniques utilized in the field are briefly summarized as two categories, machine learning methods and natural language processing (NLP)methods [17]. A survey of the main algorithms for text mining with a focus on cyberbullying detection is proposed in which the most common methods such as vector space modelling are discussed [18]. Supervised learning, lexicon-based, rulebased, and mixed-initiative classes are proposed in order to categorize approaches used for cyberbullying detection and features in those reviewed papers are separated into four main groups, content-, sentiment-, user- and network-based features[19]. Challenges ranging from definition of cyberbullying,collecting data, feature selection and model selection are surveyed and suggestions for tackling those limitations are proposed in a survey on automated cyberbullying detection[20].
Although cyberbullying research has received increasing attention for more than a decade, majority of the current survey papers focus on introducing methods used and certain general feature categorization, which is limited to provide detailed, precisely instructions for researchers and practitioners in the field. Many key questions remain unanswered. For example, what is the source of information for cyberbullying detection? What are the essential components of cyberbullying detection and how do these components interplay with each other? Finally, what are available approaches for cyberbullying detection?
Motivated by the above, in this paper, we propose a triangular user-activity-content view of cyberbullying detection. The unique view defines that users in the cyberspace are centered around this triangle to carry out activities and generate content. The interplay between these three factors(users, activities, and content) essentially sheds the light for designing cyberbullying detection algorithms. Following this triangular view, we further review methods for cyberbully detection, by taking supervised, unsupervised, transfer learning, and deep learning, etc., into consideration. In addition to the introduction of these approaches, we also explain how they focus on different types of features and the common combinations of different types of features, with respect to the proposed UAC triangular view.
D. Literature Review Process
To ensure comprehensiveness and completeness, we carried out a literature search strategy to collect papers and set up a selection criterion to choose final reference for this report. Edatabases of IEEE Xplore, Science Direct, PubMed, Google scholar and arXiv were explored in order to collect adequate literature. Snowball sampling method was conducted from the reference of chosen studies to find more related papers. At first, we used keywords like Cyberviolence detection, Cyberbullying, Cyberbullying detection, Cyberbullying prediction to search records. The original research did not bring us enough papers, therefore, we expanded research with more keywords,like Online cruelty, Cyber-harassment, Cyber-stalking, Online extremism, Online hate speech and Online radicalization.Papers containing the above mentioned keywords in tile,abstract, keywords and published in English language are included in our final paper resource. Studies from short paper summaries, magazines, non-machine learning methods are included, incomplete studies or those not published in English language are excluded in this research. The complete selection process of reviewed articles in this research is as shown in Fig. 3. Table II reports the number of papers selected in the review study.
II. USER-ACTIVITY-CONTENT TRIANGLE
In cyberspace, the impact of cyberbullying and other harmful materials/activities are facilitated through three major parties: User, Activity and Content, which form a UAC triangle. Fig. 4 shows the relationship between User, Activity and Content. A user is the main part of cyberbullying who carries out activities and form interactions with him/herself and other users. The content produced from user activities is the consequence causing people to suffer from cyberbullyingand affecting subsequent user activities. Despite the actual forms of online harmful activities, e.g., texts, images, symbols, slang, etc., they are always around this UAC triangle.

TABLE II SUMMARY OF FINAL PAPER NUMBERS FOR REVIEW STUDY

Fig. 4. The proposed UAC triangle to characterize relationships between users, user activities, and content generated by users.
Using UAC triangular view, we can further understand the difference between cyberbullying and cybervoilence, as summarized in Table I. Cyberviolence is similar to cyberbullying, but unlike cyberbullying the majority of which happen between individuals (both the activity initiator and target). In most scenarios, online extremist, online hate speech and online radicalization are started by a group of people and aim the abuse at a collective identity for example, specific groups.Once the activity is initiated, the interaction between activity conductor and victims in cyberbullying is more frequent than that in cyberviolence. In general, cyberbullying conductors are aware of their behavior as well as the possible results of them,however, cyberviolence materials are usually considered as educational rather than offensive [11], [21]. In addition, as indicated in our table, cyberviolence activities usually have stronger political overtones as shown in Fig 1. than cyberbullying because the objective of them is trying to spread their beliefs, ideas and alter others’ belief. Most cyberviolence activities do not directly promote violence, and exposure does not necessarily cause trauma or other adverse effects [22]. On the contrary, both mental and physical damage can be observed immediately from cyberbullying victims. Based on the UAC triangle, we propose a cyberbullying feature taxonomy in Fig. 5, where features commonly used in cyberbullying are categorized into three groups, User feature, Activity feature, and Content feature.
III. USER-CENTERED FEATURES
User centered features include three main aspects, demographics, behaviors, and physiologic, in an increasing level of intelligence. In an ideal case, such features can help characterize users by answering: who are the authors (gender,locations, etc.), what are their behaviors (online active/inactive, etc.), and what are their personality traits (extroversion/openness, etc.). Table III summarize main user-centered features, including sub-features, strength and weakness of these features.
A. Demographic
Demographic features or user characteristics can be defined as one’s personal information such as gender, age, race,education level and profession on the social platforms which usually can be found from user account profile. For online social networks, user profile is a collection of information associated with a user which includes key information used to identify individuals, such as name, portrait photos, number of followers. User profiles most often appear on social media sites such as Facebook, Instagram, and LinkedIn; they serve as individuals’ voluntary digital identities, highlighting their main characteristics and characteristics. Such personal profile information is used as the basis for grouping users, sharing content, and recommending or introducing people who are engaged with direct interaction [23]. However, their reliability has caused major concern because social networks allow individuals to create unlimited personal profiles, making it easy to create false or inconsistent personal information.
To find out relationship between user profile and cyberbullying, the number of following and followers are integrated as profile feature and the result proves that fake user file is one of the main factors causing cyberbullying because users with fake profiles usually pretend as someone else in order to attack and offend others [24]. User influence in the spreading of cyberbullying is studied to find out how much the contribution the number of followers and friends of a user in Tweeter will be by posting a thread comment by the user.Based on the results, user profile feature is regarded as informative in cyberbullying detection [25]–[27]. Valuable user basic information can be provided by demographic features and using these information can differentiate or compare the behavioral patterns of users based on a group that belong to.Studies have argued that it is common to observe various cyberbullying prevalence rates among different population groups [28]. Study points out that sexual orientation is strongly related with cyberbullying victimization and LGBT identification suffers a higher rate of cyberbullying [29].
The most commonly used demographic features are gender,age, race/ethnicity, sexual orientation, socioeconomic status,profession, education level, marital status. Dadvaret al.[30]investigated the role of a gender-based feature for extracting the cyberbullying on MySpace dataset. Their first observation shows that the frequency of using unpleasant words among female and males are significantly different. For example,female used to express the profanity words indirectly or in the implicit vein. Thus, SVM classifier is used to confirm that the incorporation of gender-based feature can improve the accuracy of cyberbullying detection. A close tie between age and cyberbullying is realized which means people’s attitude would change over time. Their meta-analysis method represented that cyberbullying can increase among the boys particularly as they start the high school, and goes down as they get older [31]. Gender-based language, age-based language and user location features are added into a semisupervised learning for cyberbullying detection with a fuzzy SVM algorithm. The evaluation conducted on different scenarios shows the performance improvement of the proposed fuzzy SVM with those three features [32].

Fig. 5. Feature taxonomy for cyberbullying detection.

TABLE III SUMMARY OF USER-CENTERED FEATURES

TABLE IV POPULAR POST CONTENT FOR DIFFERENT USER CATEGORIES [34]
B. Behavior Features
Behavior features refer to individual user activity mode which contains the information of users’ activities in online environment, such as online social network log in frequency,how long user maintains online status as well as user online language pattern. The history of user comments allows algorithms to monitor user’s activities by considering the average of context features like profane words to find out the established language pattern and further to see whether there is any usage of offensive language. Additionally, the posting behavior also allows to trace user’s reaction toward the bullying or harassing post in different online platforms [33].Through the posting behavior, for example, we can observe what would be the real reflection of one person when they have experienced a harassing post in the YouTube.
Table IV summarizes popular topics and hashtags posted by four different groups of network users [34], [35]. Normal users prefer to talk about various topics and use different hashtags such as social problems and celebrities while inappropriate content can be found in spammers’ post, by which more attentions can be obtained from other online network users and help them to gain followers. Some sensitive issues are more discussed by bully users such as feminism and religion. Unlike normal users expressing their true feelings about popular topics, aggressor users more tend to deliver negative opinions on those topics.
C. Psychological Features
Psychological features are characteristics that define an individual including personality traits and behavioral characteristics. Research has shown that certain groups of people are more inclined to become perpetrators or victims of cyberbullying violence based on their personality traits. In addition, cyberbullying can threat the victims psychological and physical health. Therefore, some studies have started to extract psychological features to make early intervention or prevention of cyberbullying. One of the most comprehensive approaches to recognize personality is based on the Big Five model that describes personality traits from 5 aspects [36],[37]. The Big Five model comes from a statistical study of responses to personality items. Using a technique called factor analysis, researchers can look at people’s responses to hundreds of personality items in a test and ask the question“What is the best way to summarize a person?” [38], [39]
As shown in Table V, extroversion defines the tendency of outgoing, sociable, interested in others, decisive, positive,caring more about external events and seeking stimulus.Agreeableness measures the tendency to be kind, friendly,gentle, get along with people, and be enthusiastic about people. Conscientiousness feature indicates how much a person care about others when making a decision. The following is called neuroticism that means the tendency to depression,fear, and moodiness. Openness shows the tendency to be creative, insightful, thoughtful, open-minded, and willing to adjust activities based on new ideas [38], [39].

TABLE V BIG FIVE FEATURES
Another personality model that has gained momentum in cyberbullying research is the Dark Triad, which pays more attention to the shady characteristics of users’ personalities. It refers to three different but (to others) unwelcome characteristics, namely Machiavellianism (that is, lack of empathy and the tendency to engage in impulsive and stimulus-seeking behaviors), psychosis (that is, strategically the tendency to manipulate others) and narcissism (that is, the tendency to feel superior, magnificent, and empowered) [40]. Similarly to Big Five model, participants are required to answer a series of questions so that researchers are able to calculate their scores[41]. The relationship between Dark Triad and Big Five is presented in Table VI where “–” means negative correlation between two personalities, “+” is positive relationship and “/”is no relationship [40], [42], [43]. Users personality has been linked with cyberbullying with empirical evidence. Cyberbullying detection using the Big Five found that agreeableness and conscientiousness are negatively related to cyberbullies,while extroversion and neuroticism are positively related [44],[45]. Studies exploring the relationship between cyberbullying and darker personalities (Dark Triad) have presented evidence that cyberbullying behavior appears more often with these three traits among which narcissism is found to be more linked with cyberbullying whereas psychopathy is more related to cyber-aggression [46]–[48].
IV. ACTIVITY-CENTERED FEATURES
Activity centered features intend to characterize user activities in order to understand how cyberbullying users (and cyberbullying content) different from normal users. Such activities are often studied from two main perspectives 1) how users interact with each others, and 2) how same users behave across temporal or spatial scales. For the former, networks are commonly used to study user interactions. For the latter,users’ activities are considered spatio-temporal, or time series,for analysis.
A. User Interactions
We define user interaction feature as the activities conducted between online social network users which focuses on group interaction instead of individuals.
1) Local Interaction Feature:For online social networks,node degree which means the number of followers or friends can be a proper scale to explore the person social activity to examine their influence on one another. Users are indicated in a weighted direct graph method to detect the cyberbullying,the researchers consider the volume of interactions or conversation among the users, because they believe that the more rate of connection among nodes goes up, the more the probability of bullying would increase [54]. Similarly, pairwise influences such as edge betweeness and peer pressure are taken into consideration for cyberbullying detection because users can make influence on or be influenced by their peers bullying behavior and even follow those to become cyberbullies. They believe that the influence of a user on others is a function of the weight of social relationships of users on their proposed graphs, the time of influence, the probability that influenced user might get involved in cyberbullying, posting content from the influencer, and the social networks of both users [26].
Fig. 6 shows common social network structure graphs. In the 1.5 ego networks (Fig. 6(a)), 1-ego is for direct and 1.5 for dash connection lines; the combined version defined for the relationships of two users A as a sender and B as a receiver; In the star network (Fig. 6(b)), the neighbors are fully disconnected, but in the near-star few of them are connected; In the clique (Fig. 6(c)), all neighbors are fully connected, but nearclique few of them are disconnected.
Anomaly detection on multi-layer social network (ADOMS)[58] is a multi-layer method using graph mining to detect cyberbullying. The intuition behind this approach is that in the social network, we can consider users showing abnormal behavior regrading their neighbors as outliers. The study attempts to detect the outliers based on scoring the nodes compare to the predefined social networks like Clique/Nearclique or Star/Near stars to show that to some extent a node can vary from their neighbor nodes. However, since users get involved in various social networks such as Facebook,Twitter, and Instagram, their interactions are considered in different layers through multi-layer networks. In other words,an anomaly score in the individual layer is assigned for each node upon its degree similarity to the Clique/Near-clique or Star/Near stars. The ratio of followers to friends [51] can be computed as an index for users’ popularity, total number of their own and liked tweets [31] as another index for activity rate. The studies prove that closeness, betweeness, out-degreecentrality respectively can be prominent user interaction features in terms of information that provide for cyberbullying detection in Twitter users.

TABLE VI THE RELATIONSHIP BETWEEN DARK TRIAD AND BIG FIVE

Fig. 6. Examples of typical social network graph structures: (a) 1.5 and Combines ego-network; (b) Star and Near-star network; (c) Clique and Near-clique network.
2) Global Interaction Feature:User global feature represents the community feature in which users are located in. User number and user connection level can be described as Vertex and Edge Counts. Cluster coefficient measures a node variety relative to the graph density and density corresponds to the ratio of the number of existing edges to the number of edges in a complete graph containing the same number of vertices. The length of the longest path in a graph is described as diameter [56]. Neighborhood Overlap is used to scale the relative position of receiver and sender users in the direct following network as an adjusted version of Jaccard’s similarity index [55]. In their research, five related measurements of neighborhood overlap are considered for a given author and target, namely Downward, Upward, Inward,Outward, and Bidirectional. Values of downward and upward measurements indicate the low and high position of sender versus receiver, while inward and outward showing the visibility.
In Table VII, we summarize major features used to characterize user interactions, including their cyberbullying implication, advantage, and disadvantages. The local/global column indicates whether the feature(s) is intended to capture international in a local (a user and his/her surrounding) vs.global scale (the whole community).
B. Spatio-Temporal Features
Cyberbullying is normally not an incident occurring only once or in a distinct fashion. Rather, it can be continuous and repeated or persisted over time. Cyberbullying could be conducted on the same victims for several times and some cyberbullying victims even become the perpetrator of cyberbullying [24], [59]. To date, cyberbullying detection using temporal features still remains lots of potential as there are insufficient studies related to this specific aspect.
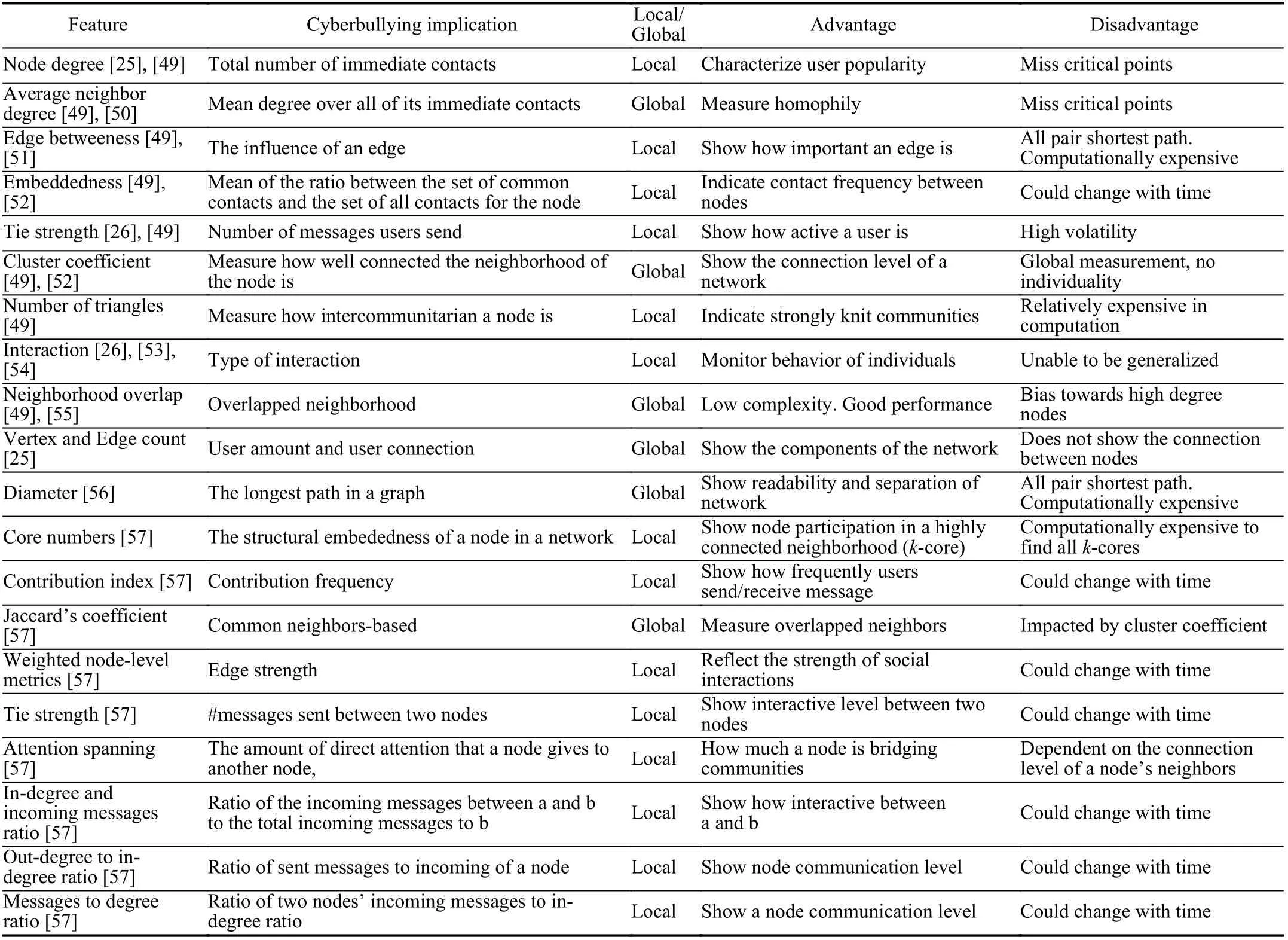
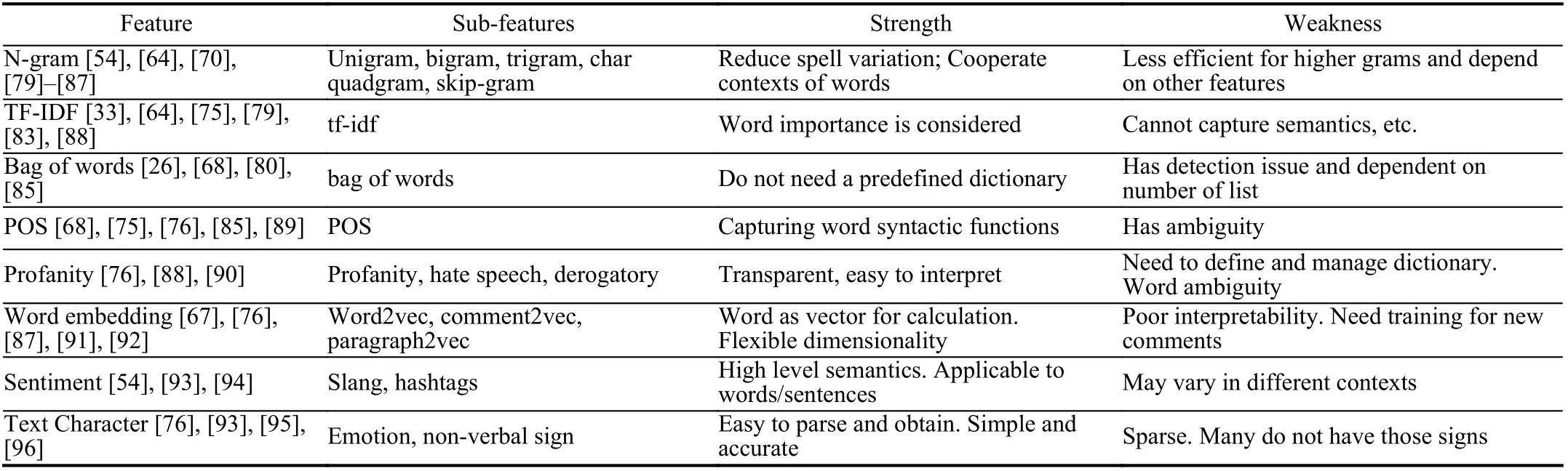
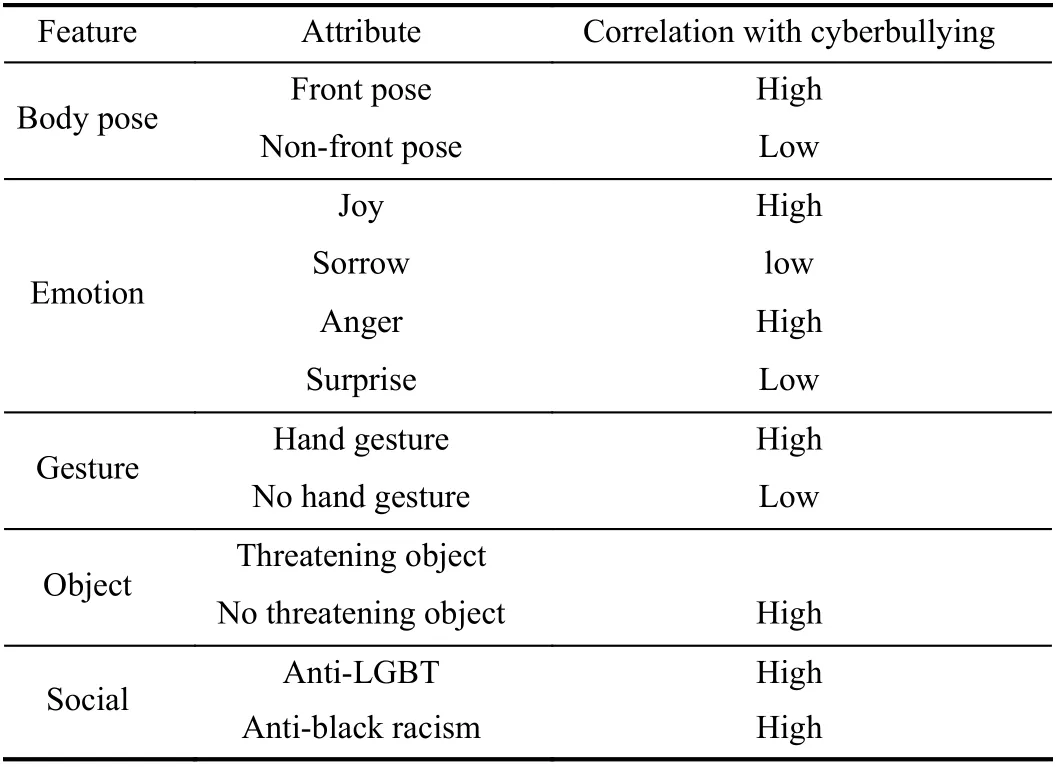
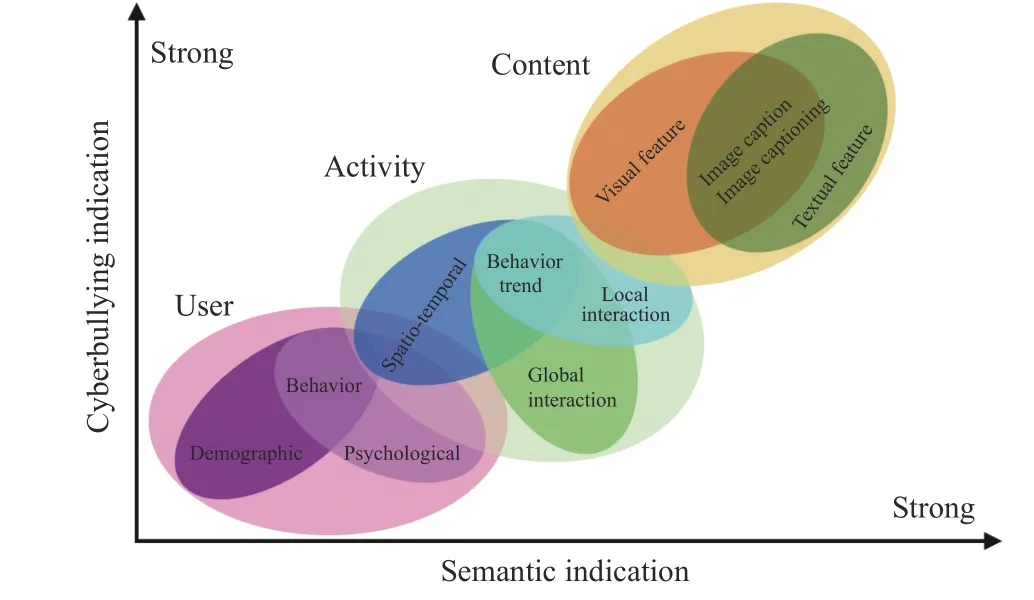
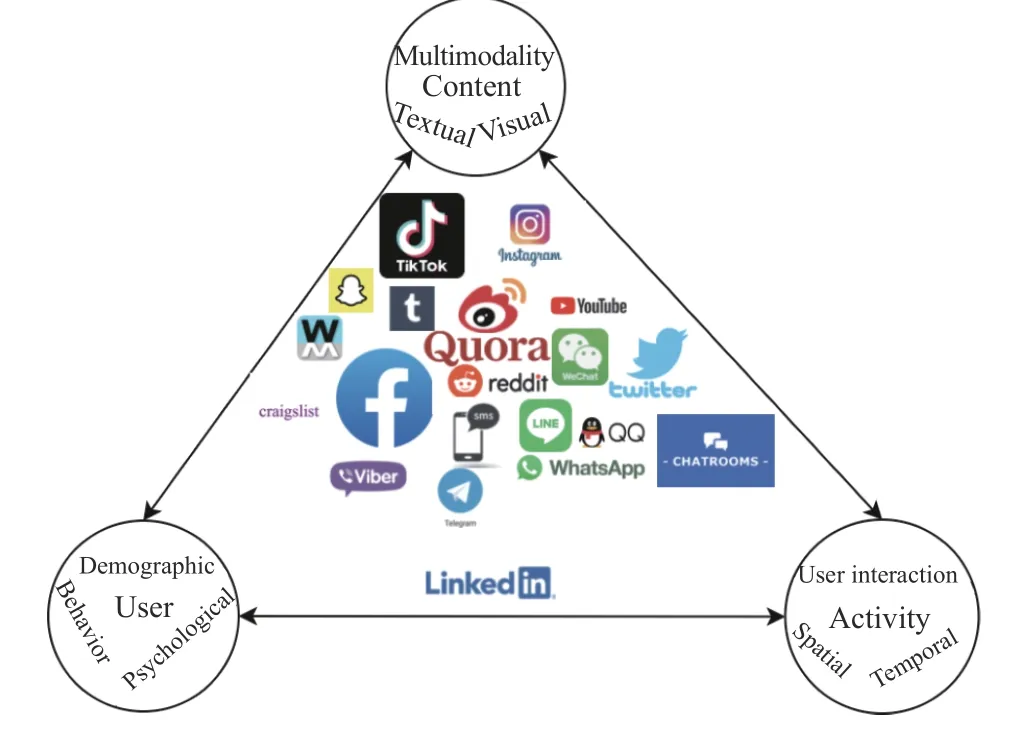
In order to model temporal dynamics of cyberbullying sessions, nine temporal features, includingTime to first comment, ICI mean and variance, ICI coefficient of variation,Number of bursts (Commenting behavior trend), and Amountof total activity and its average, are applied to statistically differentiate the bullying and non-bullying comments [60].They use a function δ (t) to denote the number of comments at a given timetas shown in (1) whereNis the subsequent of comments in timeti(hours). They also considered the time between any two consecutive comments as inter comment interval (ICI) andD={∆|0 In a graph temporal model, TGBullying [63], user interaction in the long term is fed into a graph based temporal model to improve the performance of cyberbullying detection.Because cyberbullying is a repetitive action on any social media, the user interaction can pave the road for characterizing it based on analyzing both content and temporal as well as tracking the users’ roles. In this regard, however, they found thesparsityandcharacterizing of repetitionanduser characteristicsas strong challenges to modelling the user interaction. Content centered features are the main category of features used in majority research, where texts and images are the main source of information implying whether a user’s message contains bullying content. Features in this category areextremely rich, and majority of them are related to natural language processing and image analysis. TABLE VII SUMMARY OF USER INTERACTION FEATURES Textual features are most commonly used to analyze cyberbullying, a lot of research study papers are using textual features as one part of the processes together with classification algorithms such as deep learning to detect cyberbullying from the raw text data [64]. In this paper, we grouped textual feature into linguistic feature, semantic feature and syntactic feature and summarized them in Table VIII. 1) Linguistic Feature:Dictionaries are the predefined set of profanity or hate words in the comments or texts, such as swear words. Nadaliet al.[65] reviewed and presented that textual features approach is often categorized as two groups,one is based on a dictionary to filter the cyberbullying posts called “lexical” features. The other group is called“behavioral” features which happen in conversations.However, the performance of these features limited and might not cover all offensive words, in particular those are ended with the domain of specific-textual orientations. Bag-of-words (BOW) are a list of negative words such as swear, profane occurring more frequently in any text or document. It is worth mentioning that, the word and its order,position in the document do not matter [66]. However, there are some concerns regarding the use of the BOW. It turns out that it is susceptible to the sparsity related the dependency of its features (elements), therefore, it is not able to capture the semantic information [66], [67]. To address this, some works use other features alongside BOW, considering BOW as a single feature might cause miss-classification due to the fact that words can have different usage in the texts. For example,the BoW based method is improved by combining other features such as part of speech, negative connotations with BOW [68]. N-gram is a sequence of n-words or characters allows to count the number of occurrence in size list in the texts. Unlike BoW ignoring the word orders, n-gram can improve the classifier performance thanks to incorporation of some degree in the context for each word [69]. However, n-gram approach is suffering some limitations such that it is not efficient for high level distances [70]. Term frequency inverse document frequency (tf-idf) is the most common numerical statistic feature applied by textual studies that measures the importance of a word in the comments or documents. The tf-idf value increases in proportion to the number of times the word appears in the document, and is offset by the number of documents in thecorpus containing the word, which helps to adjust the fact that certain words usually appear more frequently. It performs better than the BoW model with considering the importance of words in the document, but still is not able to capture word semantics. TABLE VIII SUMMARY OF TExTUAL FEATURES AND THEIR STRENGTH VS. WEAKNESS FOR CYBERBULLYING DETECTION 2) Semantic Features:Semantic is an element of a word’s denotation or denotative meaning and semantic analysis technology has been considered for cyberbullying detection,such as filtering malicious information and spam in online communication [71], [72]. A novel approach uses word embedding to model words in Tweets [73], so semantics of words is preserved and the feature extraction and selection phases are eliminated. In order to capture semantics, latent semantic indexing (LSI) is used for cyberbullying detection which is able to bring out the latent semantics in a collection of documents [74]. LSI is based on singular value decomposition (SVD) which decomposes a term-by-document matrix,Ainto three matrices: a term-by-dimension matrix,T,a singular-value matrix,S, and a document-by-dimension matrix,D, as shown in (3). In addition to above approaches which use latent vector to capture word semantics, some methods use more transparent way to model semantics. Profanity is a lexicon of negative words that is commonly used to detect cyberbullying.Profanity feature together with general features such as tf-idf is categorized and utilized from YouTube dataset to detect the explicit form of abuse verbal by their pattern-based stable patterns [75]. NLP as a supervised classification method is used to detect abusive language over time on the News and Finance comments of Yahoo dataset. In this regard, the researchers use lexicon (Hate speech, Derogatory, and profanity) as a guideline to annotate the data whether the text is clean or abusive from which profanity returns sexual remarks and other negative words [76]. Sentiment analysis based on user social network post reveals users’ opinions, emotion and behaviors [34]. Sentiment is usually categorized into the three groups which are positive, negative, or neutral and these can indicate how user feels at the moment they conduct post, comments. Naharet alpropose a graphic based approach to detect predator and victim in the collected dataset [54] where sentiment is selected as desired feature. Experiments regarding the sentiment features and results prove that sentiment features can improve classifiers performance in cyberbullying detection. For online bullying activities like cyberbullying, or abusive language,text characters are more frequently used by the people,because of their ambiguity property, non-verbal signs [77]. Word embedding is a vector exhibition of words in which words are set with degree of similarity. This vectorized representation of words allow us to capture the discriminative features of dataset like the words distance [76], [78]. 3) Syntactic Features:Syntactic features contain typed dependencies and part of speech features extracted from sentences. Part of speech (POS) corresponds words in a text to a specific part of speech such as noun, verb, adjective, and adverbs according to their context and definitions [34].Chatzakouet al.[34] used Tweet NLP’s POS tagging library to extract the POS tag from the contexts. Their descriptive statistics represents that the lower rate of adjective as well as adverbs categories are used in cyberbullying comments. POS is used to determine the score of an aggressive text. Typed dependencies means the syntactic grammatical association in the sentence which can be used as features to extract cyberhate in social media. The Stanford Lexical Parser is used as a popular tool to identify the type dependency. It returns 51 different linguistic labels, namely nsubj, det, dobj,nmod,compound, and advmod. For instance the parser nsubj as an abbreviation of nominal subject provides the relationship of any syntactic subject with other terms or words. Visual contents are defined as silent or motion pictures depicting a story or an incident. For example, drawings or depictions can express thoughts, feelings, ideas to be understood by people and by now they have been converted to new forms such as images, videos, or cartoons. Additionally, the rapid and tremendous growth of the technology regarding the telecommunication industry enables users to capture photos,record videos, create animations and to name but a few and instantly shares them with others through online social networks. They have been identified as potential factors in spreading of anti-social movements namely violence, haras-sment, aggression, and bullying in the online social media. In order to reduce the pace of such adverse activities, therefore,content of the visual posts needs to be described and detected automatically. Feature categories, sub-features and their strengths as well as weakness are summarized in Table IX. TABLE IX SUMMARY OF VISUAL FEATURE AND THEIR STRENGTH VS. WEAKNESS FOR CYBERBULLYING DETECTION 1) Image Features:Images are considered as one of the key components in visual features, especially on online social platforms which allow the users to share image-based posts.Although images grab user attentions and promote their engagement in these media, they can foster aggression, hate speech, and cyberbullying in these platforms. We summarize the relationship between commonly used image features and cyberbullying in Table X. TABLE X CORRELATION BETWEEN IMAGE FEATURES AND CYBERBULLYING a) Body posture:Body posture regards the body pose of people in image in which they are pointing a subject such as a gun to someone else. This feature is highly dependent on the presence of a person. Via the cosine similarity that compares the difference between these features regarding the cyberbullying and non-cybebullying images, Vishwamittaet al.found that there is a strong correlation between cyberbullying images with body-pose when one takes a front pose and pointing a threatening object towards viewers [82], [97]. b) Facial emotion features:Facial emotion features express one’s feelings or emotions in image. In cyberbullying images,predators might bully their victims by showing aggressive or even happy and joyful facial expressions. For example,aggression in image can covey a threatening action to viewers,while happiness can indicate mocking [82]. Using K2 algorithm which is a Bayesian method for summarizing a structure from given data helps to learn the structure among facial features. Bayesian Information Criterion determines the scoreMof K2, which is denoted by (4), whereNdenotes the size of the database,Diis the size of a data, andP(Di) is the occurrence probability ofDi[106]. c) Gesture features:Gesture features represent the motions of hand in several poses or gestures that people make in image. Some are not appropriate and even harmful and are used to frighten or mock at the viewers. In the cyberbullying images, the most prevalent gestures can be a loser thumb, a middle finger, a gun gesture, and a thumb down. Based on the cosine similarity, a study [82] shows that there is a strong relationship between hand gesture in images and cyberbullying. Additionally, a study of online involvements [98] on gang violence has shown that the presence of harmful hand gestures is affiliated to the online media images. 肇庆是珠江下游饮用水源的重要来源地,关系到2000多万人口的饮用水安全,水上加油站选址事关饮用水源安全,肇庆海事局历来都高度重视。为落实中央环保督察回头看及饮用水源专项督察行动,肇庆海事局积极主动与肇庆市经信局、环保局沟通确定需迁移的水上加油站名单,结合辖区通航环境、港口岸线规划、自然保护区划定及加油站选址条件等,充分征求业主意见,共6次专函向市经信部门提供水上加油站调整选址,有效推进迁移工作。 d) Object features:Object features regard to the objects in images. As for cyberbullying, however, some people post images containing the objects to threaten or intimidate the viewers. The most common attributes of which can be gun,knife, revolver, and so on. Most studies explored the presence such objects in cyberbullying. For instance, a significant correlation between the cyberbullying images and such objects in mage is found [82]. e) Social features:Social features represent the usage of ant-social symbols in images. In cyberbullying images,perpetrator uses these symbols to demean and offend special groups. Since the range of this factor is very vast, it is so difficult to define any specific dictionary or attributes. So,each study should limit itself to the images containing these symbols in their datasets. The presence of race or adult content in images is considered as one of visual features to detect cyberbullying in a study [100]. Vishwamittaet al.[82]define the presence of anti-black racism as well as anti-LGBT symbols as a sign of cyberbullying. f) Taxonomy features:Taxonomy features define the special object in image that can grab the attention of the viewers.They can also happen in the absence of person. Money, drugs,animals, and even celebrities are sample attributes of this feature which can convey an intent of cyberbullying [99]. g) Profile based features:Profile based features represent the demographic status of people in image such as gender or age. Some studies [100] found that the gender of people in image can lead to the cyberbullying. h) Image type features:Image type features define the color of images. Images with black or white colors as well as clip art and line drawing type are considered for cyberbullying detection [100]. Colors like red, green, blue (RGB) can be helpful in identifying bullying and non-bullying images [101]. i) Image caption features:Image captions are any textual content labeled on images in order to express the image.Studies have explored the role of the caption in cyberbullying involvements and proposed the approaches to extract the main topic of the captions. Caption feature is incorporated in the study for hate detection. The researchers employ Google Vision API Text Detection model to extract the texts from images. Then, these texts are inputted the model to score the relationship between the caption and the area of image where they are appeared [102] and Hossienmardiet al.[99] also the relationship between the presence of captions and cyberbullying is also explored based on Instagram dataset. j) Image captioning features:Image-generated features are obtained from the converting the contents or objects of images into the words or sentences. In other words, it provides a verbal representation of images. However, the downside of these features is that lots of information might be lost in this process. To address the issue, therefore, the attention mechanism is proposed where the salient region of an image is calculated. To calculate the attention the encoder-decoder architecture is used to translate images to sentences [103]. In the encoder, the image is encoded to a sequence of words. It generates a caption vector likev={v1,v2,...,vC} , whereviis in RK, andKandCare the size of vocabulary and the length of the caption respectively. Then the annotation vector likea={a1,a2,...,aL} where each aiis in RDand related to each part of the image produced by CNN. Image captioning features are denoted asX1={I1,I2,...,Ii} and text features are presented asX2={T1,T2,...,Ti} in VisualBert architecture in which a image likeIis extracted in the multiple region featuresf={f1,f2,...,fn} by usinf Faster R-CNN. Then it is converted into a visual embeddedevby (5), whereesindicates the input is image or text. Similarly, text inputs are embedded as shown in (6), whereftandepare token embedding and positional embedding (relative position) for each token in the sentence. Finally, it outputs two multi-model representation(t1,t2,t3,...)[107]. Likewise, a vector of captions likeX3={C1,C2,...,Ci}are extracted by the Image Caption model based on the attention mechanism. This vector is fed to the BERT architecture (Language model). It outputs a textual representation (p1,p2,p3,...) having same dimension with VisualBert outputs. Through the concatenation or bilinear transformation, their information is transmitted into one vector[108]. a) Color:As a low-level feature in this literature, colors can be an indication of different types of scenes in video clips. For example, the distribution of violent scenes is more likely different from that of non-violent in any movie. In general, the global color histogram provides all information of colors of visual feature as a histogram to show how they distributed over different bins. Color histogram is applied to extract the violence and non-violence activities in the cartoons [104],[105]. For image color feature extraction, Fisher kernels are introduced to characterize the dataset samples. Its gradient vector is shown in (7) and the information matrix is illustrated in (8). Fisher kernel is a powerful framework and it combines the advantages of pattern classification generation method and discrimination method. The idea is to use a gradient vector to characterize a signal probability density function modeling the signal generation process (pdf) [109]. b) Local feature:Local features focus on the specific or exciting regions of a given visual frame. In local features, a patch of a given frame should differ from their immediate surroundings based on the color, texture, shape, etc. Corners,pixels, and blobs can be simple examples of the local features.Thanks to this property, they are usually utilized for the object detection in videos and images and are applied for cyberbullying detection [104]. User-Activity-Content triangle illustrates the interconnection between three types of features. Following the review of features with respect to each vertex of the UAC triangle, we summarize the inter and intra feature interactions between users, activities, and content in Fig. 7. Because UAC futures focus on different aspects, we use two major facets, semantic indication vs. cyberbullying indication, to project them to Fig. 7.More specifically, semantic indication denotes the degree of semantics the feature may imply, and cyberbullying indication represents the strength of correlation that the feature may reflect during a cyberbullying incident. Fig. 7. Inter-feature and intra-feature interactions of the UAC triangle vertices with respect to semantic indication (x-axis) and cyberbullying indication (y-axis). Features towards the origin indicate weaker semantic and weaker cyberbully indication. For all summarized features, texts are most direct and accurate in capturing semantics because languages are the main form of communications. Visual perception is the second most important source of information acquisition, but understanding semantics of visual objects relies on computer vision and image processing, which are often less accurate in comprehending semantics than texts. Collectively, textual and visual features are the most effective ones in capturing cyberbullying indication, mainly because of their strength of semantic relevance. In addition, content-centered features are much easier to harvest, because majority cyberbullying or cybervoilence actions are carried out through texts, images,and videos, etc. Activity centered features can still reflect semantics and shed light for cyberbullying indication. For example, constantly sending messages to a receiver is considered a harassment behavior, especially if the message has no meaning or has a negative sentiment. A person repetitively posting and commenting on pages with aggressive content implies a strong cyberbullying indication. In this case, users’ activities need to be analyzed by social network analysis algorithms [110], in combination with content information. User centered features are considered less informative in terms of semantic indication and cyberbullying indication.This is mainly because of: 1) user features are always noisy and inaccurate, containing many missing or incorrect entries;and 2) user personality and characteristics are compounded factors, making it difficult to capture their semantics. Attacker may disguise themselves using very positive profiles, but their actions, and content associated to the actions, will eventually expose their true cyberbullying indication. Overall, content features have the strongest semantic indication and cyberbullying indication, in which textual features express a more clear indication than visual features.In contrast, demographic, behavior and psychological features from users are inferior to Content in both aspects, in which behavior shows the best in cyberbullying indication. Behavior trend features from Activity have the strongest cyberbullying indication which surpasses local interaction, global interaction as well as spatio-temporal features. Features selected from different platforms may vary in terms of availability and quality. For example, users from LinkedIn are more likely to use their real names and provide more personal information. Instagram posts are more imagebased. In Fig. 8 we discuss the common selection of features in UAC triangle in terms of 23 common online platforms subjecting to cyberbullying or cyberviolence. Although majority of selected platforms have social network components,some systems, such as MitBBs, craiglist, SMS, do not have direct social networking functionality. Fig. 8. A summary of common online platforms subjecting to cyberbullying or cyberviolence, and their features in terms of the UAC triangle. For multimodality-based platforms, such as Instagram and TikTok, studies are more focused on their content features.Multimodality is the interaction between different representational modalities, such as the interaction between textual expressions and videos/images. Features extracted from the majority platforms are content features and user activity features, which makes sense because that is what most people do on online social networks, posting messages/images/videos or interacting with other users through comments, etc.However, for platforms like Linkedin, user-centered and activity-centered features are more important and easier to get such demographic feature. Following the user-activity-content triangular view, we now review machine learning methods for cyberbullying detection.Majority cyberbullying detection methods are based on supervised learning, in which bullying and non-bullying episodes in online social platforms are differentiated. They are usually classified into supervised learning methods and weakly supervised learning methods. Numerous supervised machine learning algorithms have been applied for bullying identification in the virtual social media such SVM, Navie Bayes, Random Forest, Logistic,JRip, J48, to name but a few. It is also worth mentioning that the performance of supervised learning dependent upon various factors, in particular the dataset, data labeling, and features selection. Furthermore, most supervised methods in cyberbullying studies have been concentrated on textual features, while some have recently confirmed that considering other features like social networks or temporal can improve the models performance. We will demonstrate supervised learning methods from three aspects. 1) Text-Based Method:Simple feature based methods are the most common approach for cyberbullying detection. Vast majority of studies have been attempting to identify bullying incidents from textual contents such as comments and posts from online social media. Supervised machine learning combining with a bunch of the textual features, e.g., BoW, ngrams, TF-IDF and word2vector have been exploited to do the classification among bullying and non-bullying incidents,among which SVM is the most frequently used classification method, and Naive classifiers are the most accurate approaches [111]–[113]. While simple, one major weakness of text based methods is the low accuracy. Most of the text based methods analyze textual features which contain aggressive words, however,under some circumstances, aggressive words do not represent cyberbullying and some real cyberbullying incidents may not contain aggressive words. In addition to the sparsity issue, in many cases, cyberbullying is implied in the sentiment of sentences, pictures, or are tied to the behavior of the senders.Therefore, other types of methods, such as network-based,temporal pattern based approaches are nice complement to simple text-based methods. 2) Network-Based Method:Social network relationship features are taken into consideration for cyberbullying detection. The use of social network features such as user activities or behaviors, the aggressive level of a social network group in any online social media is combined with other textual features. Node2vec is used to analyze social network relationship features. The nodes in the graph indicates every user in social network and their labels indicate whether the user belongs to a cyberbullying group. Different single classifiers such as Random Forest, J48, Naive Bayes, SMO,Bagging, ZeroR or the combination of them have been applied to apply the extracted information [25], [114]. C4.5 decision tree is considered as a popular tool because it can support both discrete (categorical) and continuous features such as social network features, user demographics [26]. Recently, the integrated supervised learning methods such as Ensemble classifiers as well as Fusion approach are becoming popular for cyberbullying detection, because this kind of methods can support using multiple features like network-based features along with other types of features [34], [115]. Ensemble classifiers are upon on a set of multiple classifiers in which their single decisions (weighted or non-weighted) are combined to classify new data which is able to produce a better performance compared to individual classifiers since the errors of each classifier are eliminated by averaging over the decisions of multiple classifiers. 3) Temporal-Based Method:The last method is temporal based detection methods. To detect cyberbullying incidents as early as possible, features measuring time difference of the consecutive comments are applied with supervised learning methods. Two different specific early detection models,named threshold and dual are proposed. In threshold method,the decision function for the threshold model is formatted as(9), wheremcan be any machine learning model like Random Forest or Extra tree training the base line features,th+() andth−()are thresholds for negative and positive cases. In this function, the final decision is made based on if there are enough evidence determined by positive and negative class probabilities or not. Regarding the dual method, in contrast, two different machine learning models are trained to detect positive and negative cases separately as well as independently as (10),wherem+andm−are positive and negative learning models respectively [116], [117]. These two independent models are trained with an independent set of features separately where one is to detect positive classes and the other detects negative cases. Considering that labeling a large dataset is not only time demanding, but also needs a massive budget allocated to cover the expenses, recently, weakly supervised learning models(WSL) have been proposed in which a completely annotated training dataset is no longer needed. In weakly supervised learning, there are three main approaches that can lessen the heavy load of the data labeling process, namely incomplete,inexact, and inaccurate. 1) Incomplete Process:The incomplete process only allows a small subset of instances being labeled. Inexact labels allow multiple instances to share labels (e.g., multi-instances labels).Inaccurate data are labeled like the strong supervision, but there might be label errors in the data [118]. Suppose that we have a binary classification problem considering twoYandNclasses, and the task is the learning off:X →Y from a training data set like D. With a strong supervision, an annotated dataset should be a set like D={(x1,y1),...,(xm,ym)} where X is a feature space,Y={Y,N},xi∈X , andyi∈Y. In order to manage the unlabeled dataset, several approaches have been proposed such as active and semi-supervised learning. Active-based learning allows human intervention to annotate selected unlabeled instances with respect to the anticipated costs, while semi-supervised method tries to take advantage of them without human expert, in which the selected unlabeled data can be treated as a test data (transductive) or the test data are considered unknown while unlabeled instances are not selected as test data (pure). For pure semi-supervised learning, the question is how the unlabeled instances can get involved in the prediction process to enhance the related model. Recently, some studies have attempted to answer this question by introducing innovative algorithms such as augmented training [32]. In augmented training, the primary training dataset likeTnis initially divided into two groups such asYnas well asNn, that is,Tn=Yn∪Nn, andUndenotes the unlabeled data. 3) Inaccurate Process:For inaccurate supervision, the training data set is similar to the strong supervision, but the value ofyimay be incorrect, because of annotator errors.Recently, it has been utilized for cyberbullying detection on online social media where labeling the whole data is usually considered as a tedious and time-consuming activity via the traditional learning methods. Among those approaches,participant-vocabulary consistency (PVC) [119] and cotrained ensemble models (CEM) [120] are more popular. PVC attempts to extract cyberbullying involvements in the online platform through evaluating users roles (bullier or victim) and the bullied vocabulary are used in their conversation in the same time. This is because that the bully language strongly depends upon the user role or interactions in a given bully activity. The main shortcoming of supervised learning methods is the labeling of huge and high-dimensional data, because it is time demanding as well as expensive. Even though weakly supervised approaches attempt to alleviate this issue, they still depend upon the labeling of data. Some studies have switched to exploit unsupervised approaches that are mainly based on pattern mining. In general, unsupervised learning methods lie on searching the patterns in the data that share similarities. To our knowledge, several associated methods have been used regarding cyberbullying detection, mapping based method and outlier detection method. 1) Mapping Based Method:As an unsupervised method,self-organizing mapping (SOM) attempts to project a big dataset into a lower-dimension space of neurons in order to discover any similar patterns [121]. In other words, the dataset mapped on one-single layer of a linear 2D with a fixed number of neurons (units) such that the topology of neurons on the layer can be as a rectangular or hexagonal network.Data are categorized with the same attributes by searching their corresponded neurons’ layer. With the required inputx={x1,x2,...,xn} and model vectorswi= is a neighbourhood function. When it comes to cyberbullying detection, although SOM is considered as a powerful tool in structure detection for any large dataset, it is neither inherently hierarchical nor random process to provide a distribution of data. Therefore, GHSOM is applied to work with social media to improve the accuracy [122]. GHSOM has a dynamically growing structure which allows the distribution of data presented on hierarchical multi-layers where each layer is working as an independent SOM [123]. The difference between the input vector and model vector of units is checked by mean quantization error (MQE) as indicated in (16). It measures the heterogeneity of projected input data on the unit wherexjandwiare the input and model vectors respectively,Ciis a universe set of all input vectors. The fine-tuned GHSOM model is tested again Twitter, YouTube and Formspring and is proved to be more accurate in cyberbullying detection [122]. 2) Outlier Detection Method:Most studies in unsupervised learning are based on pattern discovery from considerable portion of dataset, while there are some applications in which detecting exception or anomalous cases can be more interesting or useful than the common cases. Local outlier factor (LOF) is a density-based outlier detection technique and considers multivariate outlier detection that can be efficiently used for low-dimensional datasets [91] and it has been employed in cyberbullying detection. LOF assigns anomaly scores to data points and the anomaly score for nodeiin layerlis computed in (17) [58]. Based on this technique, a methodology called ADOMS is proposed and experimental results on several real-world multi-layer network data sets show that this method can effectively detect cyberbullying in multi-layer social networks. The aforementioned methods and algorithms have been mainly focused on the detection task, and views of them try to predict the level or severity of bullying for the future state in terms of the current knowledge. For cyberbullying, apart from detecting it, another important issue is to control and monitor the trend of cyberbullying incident in each platform overtime.To address the above issues, some studies have attempted to take advantage of times series capacities in forecasting [84]and controlling the events overtime [124]. As for cyberbullying detection, the main tendency is based on using dimension reduction in times series data to capture the linguistic behavior of users [124]. For cyberbullying detection, the lack of labeled dataset has become one main challenge, therefore, transfer learning is considered as a sophisticated and economical technique to address this issue [130]. Unlike supervised and semisupervised approaches assuming the distributions of both labeled and unlabeled data are the same, the label distribution of both tasks can be completely diffident but related in transfer learning. Transfer learning is based on two main components, domain and task. Domain includes two parts,χis the feature space andP(X) denotes the marginal probability in whichX=(x1,x2,...,xn) is a vector of instances. Similarly,the task is upon two components, Y denotes the label space andf(·) is an objective function from training data that predicts the related label. Therefore, both domain and task can be notated asD={χ,p(X)} and τ ={Y,f(·)} respectively. Suppose there are two given concepts such asSandTas source and target withDSandDTrespectively. The transfer learning attempts to enhance the prediction function ofT,fT(·)by applying knowledge ofDSand τs, whereDS≠DT, or τS≠τT. It has been applied in cyberbullying and hate speech detection on online social media. Two different datasets (t1as source andt2as target) are fed into the deep neural network where both pass through the shared task like pre-processing(word token), ELMo embedding (word representation) bidirectional LSTM (BLSTM), max-pooling, but split in the classification phase. The main motivation of using transfer learning in this investigation is that the learning oft1can help to improve the classification of hate speech of the target tweetst2[131]. Their transfer learning model is capable of leveraging several smaller, unrelated data sets to embed the meaning of generic hate speech and achieves the prediction accuracy with macro-averaged F1 from 72% to 78% in detection tasks. Three different methods of transfer learning are checked to see how the knowledge gained from applying BLSTM with attention models in one dataset can improve the cyberbullying detection in other different datasets. The first is complete transfer learning (TL1), where a trained model from one data set is directly used to detect cyberbullying in other data sets without any additional training. Next is feature level transfer learning (TL2) and only the information corresponding to the features (word embedding) learned by a model are trained by other datasets. The last one is model level transfer learning(TL3), in which the trained model on one data set and only the learned word embeddings are transferred to another data set to train a new model. These three transfer learning models outperform other machine learning methods on Formspring,Twitter and Wikipedia datasets [132]. Currently, classical deep learning methods such as CNN,LSTM, BLSTM, and BLSTM have started to contribute in cyberbullying detection. The main advantage of these methods compared with other conventional machine learning approaches is that they do not need feature engineering, but only need the data embedded in the vectors as input to be fed into the algorithms. Since data in cyberbullying detection are mainly textual, social network and visual based contents, and each type might have taken different approaches to be represented as a vector, thus, in this section we explore the current methods proposed for representing those features in deep neural networks (DNN). Before being fed into DNN,data should be reconstructed. For example, textual contents need to be encoded to word vectors, while network information should be reconstructed as a graph. 2) Network Feature Representation:Complex social network relationships are usually represented in graph structure.Graph embedding is commonly used to convert the graph into low dimensional vectors. Graph auto encoder (GAE) [136]has been known as a powerful tool, which follows the encoded-decoded approach where a given social network is first encoded in the low-dimension representation and then reconstructed in the decoded step. AssumeG=(V,E) withU=|V| users being a given social network,A∈RU×UandX∈RU×Dbeing adjacency and feature matrices to represent the input graph as well as features of nodes in the input graph respectively. These matrices are first taken by graph convolutional network (GCN) to generate a latent matrixZdefined in (27), whereσis the logistic sigmoid function.Decoder reconstructs adjacency matrixAby an inner product between latent variables to minimize error in (28). The second popular way to convert the graph is Node2vec, in which the original graph structures and characteristics are able to be preserved and the transformed vectors will be similar if nodes have similarities. Node2vec uses a random walk to explore the neighbour nodes as shown in Fig. 9. Because of the combination of Breadth-first search and Depth-first search,both time and space complexity are optimized and the efficiency is also improved [113], [137]. 3) Image Feature Representation:When it comes to dealing with unstructured data, especially image data, deep learning models are preferred. For online social networks, images can be found everywhere from users’ posts to their comments.Fine-Tuned VGG-16 is one deep learning method employed for extracting image features to identify cyberbullying [138],[139], which takes an image with spacial dimension and generates a vector To do so, it is constructed from numbers of conventional layers and dense layers. For each hidden layer,ReLU is used as activation function. Recently, genetic algorithm (GA) has been used to optimize the extracted images from VGG-16 to identify cyberbullying detection. It begins with the random initial selection of the population and then combines by the operators like cross-over to expand the size of current population via generating off-springs and mutation that is used to increase the variation in each generation [139]. The process to convert images into vector for further cyberbullying detection is shown in Fig. 10 ([82]),in which after converting to vectors, images with cyberbullying meaning are closer to each other while non-cyberbullying image is far from cyberbullying ones. Fig. 9. Random walk for Node2vec: When walking from node t to v, bias α is introduced for each step. The next step is decided by evaluation of the transition probabilities on edges (v,x) determined by return parameter p and in-out parameter q. Fig. 10. Image feature representation: The first two images on the left panel have cyberbullying implication while the third image does not. Image feature representation intends to represent each image as a vector, showing on the right panel, with cyberbullying images being close to each other. In Fig. 11, we summarize and compare different methods,with respect to the UAC triangle, which demonstrates the focus of different methods in using features for learning. Fig. 11. A summary of cyberbullying detection methods and their focus on the UAC features. To compare the requirements of methods used for cyberbullying detection, we summarize their dependency to labels, features, and their adaptability in Table XI, where a symbol + means positive correlation whereas a symbol −denotes a negative correlation (the number of +/− denotes the degree of correlation). For example, labels are required for supervised learning methods (+++), but not required forunsupervised learning methods (−). TABLE XI METHOD FLExIBILITY REGARDING WITH LABELS, FEATURES AND ADAPTABILITY TABLE XII SUMMARY OF CYBERBULLYING DETECTION METHODS To further compare the strength and weakness of cyberbullying detection methods, we summarize their advantages and disadvantages in Table XII. In this paper, we conduct a comprehensive review of cyberbullying and cyberviolence, with a focus on identifying key factors associated to cyberbullying and understanding interplay between these factors. We first propose to summarize key factors of cyberbullying as a UAC triangular view.A feature taxonomy with three main categories, user-centered features, activity-centered features, and content-centered features, including sub-features within each category is proposed. Compared to existing work in the field, the UAC triangular view not only dissects seemly complicated features in cyberbullying detection into three major components: user,activity, and content, but also sets forth a clear understanding about how these features interplay with each other. Popular methods for cyberbullying detection are also reviewed,including supervised learning, weakly supervised learning,unsupervised learning, time series method, transfer learning and deep learning. The survey provides a thorough understanding of key factors, their strength and weakness, and available solutions for cyberbullying detection. The survey can also facilitate new designs of computational models for cyberbullying and cyberviolence detection. This survey provides many opportunities for future study on cyberbullying detection. First, our proposed UAC triangle organizes features commonly used in this area into three main categories (User, Activity and Content). Cyberbullying continuously evolves with the Internet. New features, such as location sharing, and regulations, like EU general data protection regulation (GDPR), are being continuous made available. It is necessary to consider new feature types in the algorithm designs and system development. Second, due to page limitations, this review largely overlooks performance metrics, research projects, and actions taken by the industry and commercial systems to prevent cyberbullying. Third,literature from non-English sources can also be included to expand and enrich the scope of the review.
V. CONTENT-CENTERED FEATURES
A. Textual Features

B. Visual Features

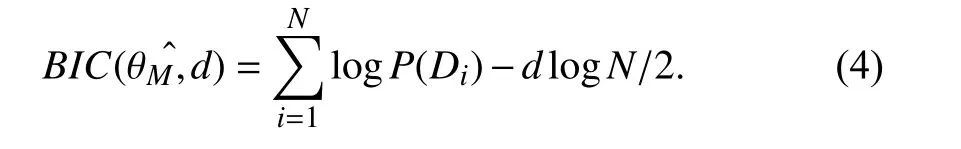

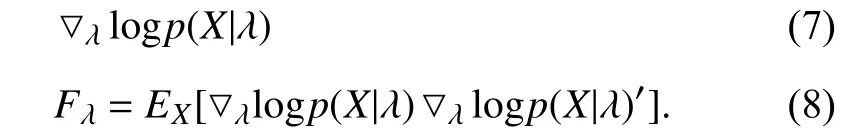
VI. FEATURE INTERACTION AND PLATFORM
A. UAC Feature Interaction
B. UAC Features and Platforms
VII. CYBERBULLYING DETECTION METHODS
A. Supervised Learning Methods


B. Weakly Supervised Learning Methods




C. Unsupervised Learning Methods



D. Time Series Method


E. Transfer Learning Method
F. Deep Learning Method





G. Method Summary and Comparison



VIII. CONCLUSION
猜你喜欢
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Consensus Control of Multi-Agent Systems Using Fault-Estimation-in-the-Loop:Dynamic Event-Triggered Case
- A PD-Type State-Dependent Riccati Equation With Iterative Learning Augmentation for Mechanical Systems
- Finite-Time Stabilization of Linear Systems With Input Constraints by Event-Triggered Control
- Exploring the Effectiveness of Gesture Interaction in Driver Assistance Systems via Virtual Reality
- Domain Adaptive Semantic Segmentation via Entropy-Ranking and Uncertain Learning-Based Self-Training
- Position Encoding Based Convolutional Neural Networks for Machine Remaining Useful Life Prediction