基于加权硬投票融合模型的互联网消费金融借款人违约风险预测
2022-08-12司筱涵魏建国魏英杰
司筱涵, 魏建国, 魏英杰
(武汉理工大学 经济学院,武汉 430070)
近年来,我国互联网消费金融快速发展,市场规模不断扩大。Wind数据显示,2019年互联网消费金融市场交易规模达22800亿元,互联网消费金融从2013年的60亿元增长到2019年的22800亿元,年平均增长率达169.13%。尽管2020年受新冠疫情影响,互联网消费金融增长速度有所减缓,但后疫情时代还将迎来快速增长。然而,由于我国互联网消费金融发展尚处于探索阶段,主要服务对象是低收入弱信用的长尾人群,加上我国征信体系尚不完善、平台内部风险控制机制还不健全等,借款人违约现象频发。中国银监会和保监会的数据显示,消费金融行业不良率逐年攀升,由2012年的0.56%上升至2018年的8%,7年间增长了1328.57%。
本文构建了消费金融借款人违约风险评估的二分类加权硬投票融合模型,对借款人违约率和违约因素作出预测,并采用Kaggle网站发布的某互联网消费金融平台交易数据作实证分析,以检验该模型的预测精度,以期为我国互联网消费金融违约风险管理提供新方法。
一、 相关文献综述
目前学界在对借款人违约特征及影响因素的研究上,主要集中在内源性因素与外源性因素两个方面。林慰曾等指出,互联网消费金融发展失范的根源在于信用错配,特别是平台次级客户高额授信会诱发违约行为[1]。岳森认为互联网消费金融平台无法准确审核借款人信息真实性,导致授信准确度难以保障,会增加违约风险[2]。张茂军等认为,金融科技的发展增强了信息获取能力,却在信息处理能力上存在局限性,使之在决策时存在偏差,加剧了平台的违约风险[3]。Chiang SL认为借款人抵押贷款的凸性对违约概率变化影响最大[4]。Lee等的实证研究表明,借款人样本语音数据提取的参数可作为违约风险评级水平的决定因素[5]。Sangwan S提出借款人的家庭社会经济地位特征将显著影响违约行为发生的可能性[6]。
在对借款人违约的评价指标体系的研究方面,周永圣等选取借款人的基础信息、行为和心理等三个方面因素构建了互联网消费金融违约风险指标体系[7],王正位等提出了个人特征、信用变量、历史表现、借款信息等四项一级指标,对网贷平台违约风险进行评估[8],Carlos Eduardo Canfield等从信用评分和借贷者特征两方面构建网贷平台违约风险指标体系[9],Oded Netzer等分别从借款人的人种、性别、外貌等特征方面构建互联网消费金融违约风险指标体系,实证结果表明,黑人的借款成本更高[10],Frydman H等在评价违约风险时,更注重借款人基本信息、借贷信息、还款能力三个层面[11]。
在对借款人违约的预测方法的研究方面,李汛等运用多个机器学习模型预测借款人的违约概率,其研究表明,机器学习预测借款人违约行为的准确率普遍高于传统回归模型[12],马晓君等采用CatBoost算法构建P2P违约预测模型,并与LightGBM,XGBoost进行对比,发现CatBoost的性能总体上优于LightGBM,XGBoost[13],杜梅慧等采用两步子抽样方法抽取样本,建立logistic回归模型,提高了违约率预测精度[14],Cowden C等基于支持向量机算法建立违约风险预测模型,其模型具有良好的特征稳定性与分类准确性[15],KHAN等使用Fama-French五因子模型考察了新兴市场背景下违约风险因子的有效性,与其他模型相比,可以提高选取特征变量的准确率[16]。
综上可知,国内外学者对借款人违约的相关研究主要集中在对风险评估的指标选择与算法测定上,对一般性消费金融违约风险的研究较多,且多是将传统金融机构管理客户违约风险的算法和模型应用到消费金融之中,对互联网消费金融违约风险及其预测方法的研究不够。本文通过确定借款人违约风险预测指标体系,构建改进的XGBoost-Light、GBM-CatBoost三阶段融合模型,以用于预测借款人违约风险,为互联网消费金融平台的风险管理提供依据。
二、 理论分析与研究设计
(一) 互联网消费金融违约风险及其特征
互联网消费金融的违约风险,是指借款人不能履行借款合约的还款义务,使贷款平台遭受损失的情况。其一方面表现为借款人收入不稳定时产生的被动违约行为,强调其非预谋性[17];其另一方面表现为借款人事先有违约动机,在有支付能力的前提下,不按期还款而产生的主动违约行为,强调其预谋性。
互联网消费金融的违约风险有如下特征:一是客户的特殊性。互联网消费金融的客户群体大多是被传统金融排斥的长尾客户,他们往往是低收入或无稳定收入、无资产抵押、无财务记录、征信数据缺乏,部分借款人还存在非理性消费行为。二是消费行为的多样性。目前消费贷场景主要集中在购物、租房、装修、旅游等方面。一些电商平台基于数据挖掘技术精确分析客户行为特征,给客户大量推送金融营销广告和具有吸引力的商品,在支付环节提供各种“分期、免息、免费”的金融产品,对消费者形成了极大的诱惑,导致一部分消费者出现“超前消费”“过度消费”的情况,并因此而背负沉重的债务包袱。三是贷款产品的特殊性。消费金融产品贷款额度小、期限短、放款快,为了弥补较高的违约风险,借款利率往往高于银行一般性商业贷款。四是平台管理不规范。一些游离在金融监管之外的中介机构通过互联网渠道,以“低息、低费、快速、无抵押、无担保、无须审查征信”等广告宣传诱导消费者贷款,使部分消费者陷入“贷款陷阱”。
(二) 互联网消费金融形成违约风险的理论分析
互联网消费金融平台主要服务于低收入的弱信用群体,因而面临比传统金融风险更高的信用风险。由于借款人客群分散、线上融资,互联网消费金融平台难以全面获知和辨别借款人的真实准确的信用信息。信用等级低的借款人会掩饰个人收入状况,甚至提供虚假信息,以提高信用等级而获得贷款,于是就会出现逆向选择问题,从而增加违约风险。
借款人在获得贷款后,可能违背贷款协议,出现了到期不能按时还款的现象,即发生了道德风险。出现道德风险的原因在于:首先,由于信息不对称和借款人高度分散的特征,贷款平台出于成本考虑,难以对借款人进行事后监督,借款人在获得贷款后,可能会违反借、贷双方对贷款用途的约定,将贷款用于高风险的投机活动,一旦投机活动受挫,违约风险就不可避免。其次,即使借款人将贷款用于约定的消费用途,借款人也可能由于意外事件出现而导致收入困难乃至难以还款,从而发生违约风险。
(三) 借款人违约风险指标体系的构建
根据互联网消费金融平台和借款人特征,参考国内外相关文献所选取的指标,考虑到指标数据的可获得性和量化性,基于定性和定量指标相结合的原则,本文构建借款人违约风险预测指标体系,以借款人解释变量作为自变量,将所搜集到的借款人信息进行分类,其内容包含借款人基本信息、借贷信息、信用状况、还款能力四个一级指标,以及19个二级指标,同时将借款人违约与否作为因变量,具体分组见表1。

表1 互联网消费金融借款人指标体系
1.借款人基本信息,包括年龄、性别、受教育程度等,它们在一定程度上反映了借款人的收入情况,特别是借款人的房产情况直接反映出其资产水平,是判断借款人还款能力的重要指标。此外,借款人的婚姻状况、工作职称等指标与借款人发生逾期后所需承担的违约成本相关。
2.借款人借贷信息,包括借款金额、借款周期、借款目的等,能够帮助审核人员了解当前借款人的资金使用情况,从而有助于分析借款人正常还款的可能性,也便于了解贷款的内在风险。同时,审核人员可通过借款人贷款状态判断其信用品质,是影响贷款回收金额的重要因素。
3.借款人信用状况,包括信用等级、未结信用额度、公共事业差评数等。借款人的信用历史可以很直观地体现出其偿还借款的意愿。能主动且及时履约的借款人,一般都具有良好的信用,而曾经发生过借款逾期甚至经常发生逾期的借款人,则属于高危借款人群。
4.借款人还款能力,包括未平仓交易数、负债率、账户余额等。这些指标反应借款人的资金流向和资产状况,方便审核人员对借款人的资金进行监管,有助于判断借款人能否按时足额还本付息,以防范违约行为的产生。
(四) 模型构建
GBDT模型是由多个决策树共同构建的一种加性回归模型①。与传统的统计学模型相比,GBDT模型可以有效量化捕捉不同单位或数量级的自变量对因变量的影响程度,并通过对数据进行学习来调整自变量权重,进而提高模型的估计精度,因此,利用GBDT对互联网消费金融违约行为进行建模是可行的。在研究互联网消费金融的违约问题中,假设x和y分别表示借款人的解释变量与借款人违约状态,可将其算法列为T={(x1,y1),(x2,y2),…,(xn,yn)},xi∈Nm,yi∈(-1,1)。目前,GBDT有许多不同的改进模型,其中最具代表性的分别为XGBoost、LightGBM、CatBoost。
1.XGBoost模型。XGBoost与GBDT模型最大的区别在于对借款人解释变量数据集进行训练时所需的损失函数不同,XGBoost所运用的算法机制更易实现。GBDT的均方差损失函数如公式(1)所示:
L(y,G(x))=[y-G(x)]2
(1)
XGBoost相较于GBDT的改进在于对损失函数可运用二阶泰勒公式求近似值,通过加入正则项Ω(gi)来控制模型的复杂程度,表达式如公式(2)所示:
(2)
2.LightGBM模型。LightGBM分别从借款人解释变量的维度与特征两个方面对GBDT加以改进,其核心技术是实现精度与效率的平衡。GBDT通过使用叶子节点后的方差来衡量信息收益,可用公式(3)表示:
(3)
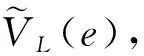
(4)
3.CatBoost模型。CatBoost的基本原理是解决原始GBDT中所存在的各种数据偏移问题,能够更好地处理类别特征。GBDT算法在处理借款人类别型变量,如性别、婚姻状况等,常用其对应的数据集平均值来代替,并把它作为决策树中节点分裂的标准。这种方法被称为Greedy TBS,具体公式如下:
(5)
Greedy TBS使得处理后的借款人二级指标中对比实际数据集包含更多信息,所以用实际数据集的平均值来替代解释变量,在训练集和测试集数据分布与结构不同的情况下容易出现条件偏移。
针对这种情况,CatBoost通过添加先验分布项的方式改进Greedy TBS,减少了噪声和低频数据对于数据分布的影响,具体公式如下:
(6)
4.XGBoost-LightGBM-CatBoost融合模型。本文所设计的XGBoost-LightGBM-CatBoost融合模型如图1所示。在训练阶段采用5折交叉验证方式寻找到模型的最优参数;在测试阶段将特征变量作为XGBoost、LightGBM和CatBoost的输入,并对三个分类器输出的类别进行二分类加权硬投票法得出预测结果。

图1 模型设计
图2所示的二分类加权硬投票,就是指根据XGBoost、LightGBM和CatBoost预测的准确率计算出其加权准确率,观察三个分类器的预测结果并比照准确率高的分类器来确定最终的预测值。例如,XGBoost、LightGBM、CatBoost三个分类器预测的准确率分别为0.65、0.68、0.96;计算其加权的准确率为0.28、0.3、0.42。通过观察发现,任意两个分类器其加权准确率相加的值大于0.5。使用Sigmoid函数对其进行分类,当任意两个分类器预测结果相同时,样本标签0或1将与结果保持一致。

图2 二分类加权硬投票
三、 实证分析
(一) 数据来源与处理
1.描述性统计
本文数据来源于Kaggle网站上某消费金融平台的交易数据,采集了个人信贷申请记录252970条,特征数量61个。这里将每一笔数据中的目标变量“Target”取值为0与1,分别代表借款人正常还款与违约。其中,正常还款数据为207722条,违约数据为45248条,可得其违约率为17.9%。
贷款周期方面,分别为36个月与60个月,占比70.05%、29.95%,分别对应15.88%、20.93%的违约率,由此可见,贷款周期越长,违约发生的可能性就越大。工作年限方面,其数据主要集中在1到10年,各个工作年限的逾期率差异不大,5~7年相对较高,均在7%以上。
如图3所示,平台客户的贷款利率在5%到37%之间;在10%到20%这一区间,各个利率对应的概率密度分布比较均匀,其他区间概率密度较低。从图3中可看出,违约客户分布更右偏,其对应的贷款利率水平相对更高。
图3 贷款利率
如图4所示,借款人的负债率在-3%到40.5%之间;对于违约客户而言,-3%到20%对应的区间面积要略大于20%到40.5%,说明借款人负债率在-3%到20%之间产生违约行为的概率更高。对于正常客户,则情况正好相反,13%到40.5%的区间面积大于-2%到13%,说明当负债比高于13%时,其履约行为随着负债比的增加而下降。
图4 负债率
表2所示为贷款申请人的信用评级信息。其中信用评级A到G的占比分别为16.71%、30.07%、25.82%、16.02%、7.58%、3.03%、0.77%,对应的违约率分别为6.19%、12.51%、19.35%、25.89%、32.62%、38.30%、40.87%。这表明平台的主要服务对象为信用评级在A-D区间内的人群,而且信用评级越高,贷款违约率越低。

表2 信用评级统计信息
资产状况反映了借款人的偿债能力,与违约率呈负相关关系。在申请贷款的客户中,无房产客户与其他客户人数占样本量万分之三左右,但其违约率占比高达27%;拥有房产(包括抵押与自用)的借款人占比60%,其对应的违约率最低,仅占总人数13%,说明无固定资产的借款人违约率较高。在年收入方面,正常客户年收入均值为74161元,违约客户为65085元,违约客户年收入整体偏低。在所有账户活期余额方面,正常客户与违约客户均值分别为143791元与114454元,说明违约客户拥有更少的流动资金。
2.数据预处理
由于平台给予的数据信息不完整,通常含有缺失值或格式不统一等问题,因此需要对数据进行预处理。具体分为缺失值处理、独热编码以及类别平衡等。
(1)缺失值处理。由于XGBoost、LightGBM和CatBoost本身具有自动处理缺失值的能力,所以在数据预处理阶段对数值型变量和连续型变量不处理缺失值;而对于类别型变量的缺失值使用“null”填充,同时对缺失值比例大于50%的变量予以删除;数据集中异常值存量非常少,可以忽略不计,不做异常值处理。
(2)独热编码(OneHotEncoder)独热编码是将字符型的特征转化为二进制向量,主要用于处理类别型变量(如收入来源是否核实),特征取值之间不存在任何关联关系。使用独热编码将类别型变量转化为数值,如将“收入来源是否核实”中的“已核实”“未核实”分别转换成“1”“2”。如表3所示,将整数值表示为二进制向量,除该整数被表示为“1”外,其余均为“0”。

表3 特征verification_status独热编码转换表
(3)类别平衡。互联网消费金融的信贷业务常常面临类别不平衡问题。将样本按7∶3的比例划分训练集和测试集,其正负样本比约为4.6∶1,此时正样本与负样本差别过大,即使将所有负样本的错误预判都归类于正样本,模型预测准确率也能达到93%,此时的模型不具有实际意义。本文采用代价敏感学习法②,通过设置权重来处理类别不平衡的问题。
3.特征选择
(1)基于相关系数的特征选择。相关系数属于包裹式③特征选择方法。本文采用相关系数法对特征进行筛选,剔除解释变量系数小于0.001的特征,总共剔除4个特征(如表4所示),保留特征数57个。

表4 基于相关系数的特征筛选
(2)基于Catboost的特征筛选。Catboost是一种嵌入式④特征选择方法。经过相关系数法筛选特征,剩余特征数57个,数量较多,易发生维数灾难或产生过拟合现象。本文根据Catboost可返回抽样学习的特点,对57个特征作进一步选择,设定阈值为3%,最终保留46个特征。
(二) 分类效果的评价
为了辨别基于二分类加权硬投票的互联网消费金融违约预测模型的分类效果是否比其他分类器更优,本文采用四种评价指标进行说明,分别是ROC曲线、AUC值、KS值与准确率,其评价指标均可通过混淆矩阵(如表5所示)计算得出。

表5 混淆矩阵
ROC曲线称为受试者工作特征曲线,通过模型得到不同阈值下的分类结果,其横纵坐标分别用真正率TPR(True Positive)和假正率FPR(False Positive)表示。当TPR越高,FPR越低时,ROC曲线向左上角移动,模型的预测能力越强。AUC表示ROC曲线下方面积,AUC值越大意味着样本预测排序质量越好。
TPR=TP/(TR+FN)
(7)
FPR=FP/(FP+TN)
(8)
KS值表示TPR曲线与FPR曲线的最大间隔距离,反映了模型区分正负样本的能力。KS在0到1的范围内取值。一般而言,当KS值小于0.8时,值越大意味着模型区分正负样本的能力越强。
准确率(Accuracy)表示被正确预测的正常还款借款人与违约借款人的样本个数占总样本的比率,其数值越高代表模型的预测效果越好。
Accuracy=(TP+TN)/(TP+FP+TN+FN)
(9)
(三) 模型预测结果的对比分析
经过对样本的数据预处理,特征筛选和基于贝叶斯调参的XGBoost-LightGBM-CatBoost模型训练后,采用训练好的最优参数XGBoost-LightGBM-CatBoost对测试集进行分类。同时,本文比较了单模型XGBoost、LightGBM、CatBoost在测试集上的分类效果,以上单模型均经过贝叶斯调参达到最优。为保证各单模型分类效果的稳定,所有数据均通过五折交叉验证并取其平均值。数据实验的操作环境为Python 3.7,依赖包为pandas、numpy、sklearn、seaborn、datetime、scipy、XGBoost、lightGBM、CatBoost。具体计算结果如表6所示。

表6 不同模型预测结果对比
图5为处于最优参数时,测试集与训练集上XGBoost-LightGBM-CatBoost模型的ROC曲线。
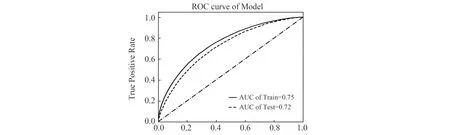
图5 XGBoost-LightGBM-CatBoost模型的ROC曲线
由表6可知,XGBoost-LightGBM-CatBoost融合模型在测试集上的准确率为0.826,AUC值为7.18,KS值为0.320,其指标值均优于其他三个单分类器,说明融合模型具有更好的预测性能。同时,由图5可知,XGBoost-LightGBM-CatBoost模型其测试集的ROC曲线被训练集包裹,测试集中AUC的值为0.72,训练集中AUC的值为0.75,这表明XGBoost-LightGBM-CatBoost模型在贷款申请人的样本数据中存在轻微过拟合学习问题,可忽略不计。
(四) 结果分析
本文从借款人的基本信息、信贷信息、历史信用状况、银行账户信息四个维度出发,分析其所包含的二级指标来判断违约的影响因素。同时,由表6可知Catboost模型对于大规模、多维度的数据处理比其他两个分类器更具优势,因此本文通过Catboost模型对借款人特征进行重要性排序,具体情况如表7所示。

表7 特征重要性排序
表7列出了各解释变量对模型的贡献情况,将位于前十的各解释变量贡献度由高到低进行排列,分别为贷款利率、年收入、负债比、公共事业差评纪录、信贷循环余额、账户余额、信用额度、未平仓交易数、循环信用额度占比、贷款金额。贷款利率的贡献度最大,高达20.3%;年收入与负债比分别贡献了14%、9%;其中前十个特征贡献度高达70.7%。
在前十个特征中并未完全体现一级指标的重要性,不能对所归类的四个维度进行很好的解释,因此本文通过将一级指标项下的特征所得分进行加总求其算数平均值,获得一级指标的重要性排序,具体情况如表8所示。

表8 一级指标重要性排序
在本文归类的四个一级指标中,借款人信贷信息占比最高,说明借款人的信贷信息对借款人违约与否影响最大;借款人的基本信息对借款人违约情况的影响最小。由表8可知,四个维度的影响程度由高到低排序为:借贷信息、信用状况、还款能力、基本信息。
从影响违约因素的解释变量中可以发现:(1)贷款利率的贡献度高达20.3%,贷款金额重要性排序占比为3.5%,两个指标都反映了借款人的信贷信息,其中贷款利率与贷款金额所对应的数值越高,意味着借款人每月需要偿还的金额越多,财务压力的增大将增加违约产生的可能性;(2)年收入、负债率、账户活期余额与未平仓交易数累计贡献率为26.8%,这四类指标在一定程度上反映了借款人的财务状况,通过对其进行监测来判断借款人贷款到期时能否按时足额还本付息;(3)公共事业差评记录、信贷循环余额、信用额度、循环信用额度占比累计贡献率为20.1%,以上指标反映了第三方机构对借款人的信用评价,在一定程度上体现了借款人的履约意愿。除图6中出现的十类指标外,其余指标贡献度均低于3%,因此在对本文建立的借款人违约行为指标进行分析时,贷款利率与贷款金额应作为借款人借贷信息的主要参考指标;年收入、负债率、账户活期余额与未平仓交易数应作为借款人还款能力的主要参考指标;公共事业差评记录、信贷循环余额、信用额度、循环信用额度应作为借款人信用状况的主要参考指标。
四、 研究结论与建议
通过上述研究,本文得出如下结论:
其一,互联网消费金融平台与借款人之间存在高度的信息不对称,容易出现借款人违约行为;对这个弱信用群体的违约率的预测不能采用传统方法,要结合互联网消费金融的特性开发新的违约风险预测方法。
其二,根据互联网消费金融的运行特征和客户特性,建立了客户违约风险指标体系,包括借款人基本信息、借贷信息、信用状况、还款能力四个一级指标,以及19个二级指标。
其三,XGBoost-LightGBM-CatBoost融合模型对于互联网消费金融借款人的违约风险预测效果较单模型更好,其精确度更高。
其四,XGBoost-LightGBM-CatBoost融合模型的预测准确率为82.6%,即预测平台违约率为17.4%,而根据Kaggle网站数据计算得出的实际违约率为17.9%,说明运用XGBoost-LightGBM-CatBoost融合模型构建互联网消费金融借款人违约预测模型在分类精度、分类准确度上具有一定优势,对实际结果的拟合效果较好。
其五,本文采用Kaggle数据,归纳了违约风险预测中需要关注的四类特征,通过Catboost模型进行特征筛选,选出权重值高的三类特征中贡献度排名前十的二级指标,供平台筛选贷款申请人时参考。
根据以上研究结论,本文就互联网消费金融平台加强违约风险管理提出以下建议:
第一,应加强借款人信用信息采集,提高信用评价效率。为避免客户恶意违约行为,互联网消费金融平台可以设置客户群体画像,首先依据客户基本信息进行初步分层与评级,对老人、未成年人、低学历者普及消费金融及相关产品知识,说明其优点与潜在的风险;对风险偏好型客户进行重点跟踪监测,提示客户该行为潜在的风险和负担的后果;利用人工智能模型搜集客户的消费习惯和社交区域,将客户的借款意愿与还款意愿进行量化并及时反馈,平台根据分析结果对信用数据良好的客户给予消费优惠,对信用状况差的客户进行消费限制。
第二,应通过与消费场景第三方的结合,获得更多的客户信息。消费金融公司可以基于个人消费者的客户信息作为聚合的消费场景,根据各类消费场景进行差异化定价,并对消费场景进行细分,深化消费场景建设,然后从中找到合适的消费场景切入消费金融业务中。同时,在已有的服务场景中,通过深度挖掘推出更多的子场景或延伸场景。
第三,应加强互联网消费金融平台风险控制能力建设。充分运用以大数据、云计算、人工智能和区块链等为代表的金融科技手段,建立互联网消费信贷贷前识别与反欺诈、贷中追踪与预警、贷后智能催收的全信贷周期智能风控系统,以提升互联网消费金融平台的信用风险精细化管理水平。以数据共享为风控导向,以深度学习为代表的机器学习技术为驱动,创新互联网消费金融业务和风控模式,设计高度适配的信用风险评估模型,增强对平台信用风险的预见性,有效缓解平台的逆向选择和道德风险。
注释:
① 加性回归模型是指通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
② 代入敏感学习法是机器学习领域中的一种新方法,它主要考虑了在分类中,当不同的分类错误会导致不同的惩罚力度时如何训练分类器。
③ 包裹式特征选择方法是从原始特征集中不断选择特征子集、训练模型,并通过学习器对特征子集进行评价,选出最终训练子集。
④ 嵌入式特征选择将特征选择融合在模型训练的过程中,依据模型表现分析特征重要性,在训练过程中自动完成特征选择。
