面向增量分类的多示例学习
2022-08-12魏秀参徐书林
魏秀参 徐书林 安 鹏 杨 健
1(南京理工大学计算机科学与工程学院 南京 210094)2(综合业务网理论及关键技术国家重点实验室(西安电子科技大学) 西安 710071)3(高维信息智能感知与系统教育部重点实验室(南京理工大学) 南京 210094)4(社会安全图像与视频理解江苏省重点实验室(南京理工大学) 南京 210094)5(计算机软件新技术国家重点实验室(南京大学) 南京 210023)6(中国海洋石油集团有限公司信息技术中心 北京 100010)
多示例学习(multi-instance learning, MIL)是一种弱监督学习,其在药物活性检测任务[1]中被自然提出,随后被广泛应用于许多现实任务,例如图像分类或检索、人脸检测、文本分类和计算机辅助医疗诊断等.传统的单示例学习中一个示例会有一个或多个标签与之对应.与单示例学习不同:MIL中的训练单元——多示例包(bag)——由多个示例构成,多示例包有对应的标签,但包中的示例没有与之对应的标签.多示例学习系统的目标是对已知标签的多示例包进行学习后需要能够对未知的多示例包进行类别预测.
另一方面,现实生活中的许多系统需要不断地从新类新样本中学习新的知识,并且能够很好地保存以前学习的旧类别和旧知识,即增量学习(incremental learning)所解决的问题.在过去的几年里已经开发了很多有效的多示例方法[2-12]解决多示例学习中示例缺失带来的困难,也有很多方法被提出解决增量学习[13-29]的灾难性遗忘问题,然而很少有人提出有效方法来处理多示例学习下的类别增量问题.据我们所知,只有Mera等人[30]提出了一种以集成学习框架为基础的方法Learn++.MIL解决此难题.Learn++.MIL使用了在传统单示例学习中所提出的集成学习的策略去解决增量学习的遗忘问题,并简单地使用早期的MIL-Boost[31]作为集成学习中的基分类器使之能够处理多示例数据.所以此方法并不能很好地解决复杂的面向增量分类的多示例学习问题.同时,传统增量学习方法由于同样仅针对单示例数据设计,无法处理多示例学习中一对多的样本与示例的对应,故而难以解决多示例学习中的训练样本歧义而难以良好工作.
本文面向增量分类的多示例学习提出了一种基于注意力机制及原型分类器映射的多示例增量学习方法(multi-instance class-incremental learning, MICIL).我们的方法主要包含2个模块,基于注意力机制的多示例汇合表示模块和基于类别原型映射的多示例增量分类器生成模块.前者将复杂的多示例包表示汇合成统一的特征向量,并且基于注意力机制给予包中关键示例(key instance)更高的汇合权重,这么做的动机是因为包中的关键示例更能体现包的类别信息.在得到包的统一汇合向量表示之后,我们计算所有同类别多示例包表示的质心而得到对应的类别原型并存储起来.对于后者,类别原型通过一个类别原型映射得到对应的类别分类器,基于所有类别原型生成分类器进行监督学习可以学得增量阶段新类别的知识,基于上一增量阶段生成的旧类别分类器的预测结果对当前阶段生成的旧类别分类器的预测结果的知识蒸馏便可一定程度保留旧类别的知识.尤其是,使用类别原型我们可以用极小的存储代价保留旧知识,并且由于每类只有一个类别原型使我们能很好地解决新旧数据的不平衡难题,由此得到无偏鲁棒的类别分类器.通过上述框架,我们能够很好地在类别增量环境下进行多示例学习数据挖掘.
在实验中,我们在3类多示例多类别问题的数据集Text[32],COREL[33]和NYU-v1[34]上进行增量学习任务的实验验证.实验结果表明MICIL方法与其他方法相比取得了最优的增量学习识别精度,包括最新针对多示例学习的增量学习方法[30]和目前最新的面向增量分类的多示例学习[29].
本文工作的主要贡献包括3个方面:
1) 提出一种基于注意力机制及原型分类器映射的多示例增量学习方法MICIL,通过构建和存储多示例类别原型应对多示例类别增量学习任务.
2) 基于注意力机制的多示例汇合操作构建了包含了多示例包显著类别相关信息的统一特征表示;原型分类映射器能够生成平衡无偏的分类器,并在知识蒸馏的作用下很好地保留旧类别相关信息.
3) 在3个不同任务的多示例数据集进行实验验证,结果表明我们提出的MICIL方法能够很好地解决多示例学习环境下的类别增量问题.
1 相关工作
MIL是机器学习中的一种弱监督学习任务,其中一个标记的包(bag)与多个未标记的示例相关联.随着MIL在文献[1]中的开创性提议,许多MIL算法已经被开发出来以帮助人们解决一系列实际应用.近年来,得益于深度学习的发展,在传统机器学习方法[2-4]的基础上,许多基于神经网络的MIL方法[5-8]被提出并取得了不错的效果.
首个MIL研究[1]中给出了标准假设(standard assumption).在标准假设中,通常每个示例都有一个未知的类标签,将其标识为正或负,当且仅当一个包至少含有一个正示例时这个包才被认为是正的.随着MIL研究的发展,这个假设并不适用于所有MIL问题.在某些情况下,需要一个广义的假设:集体假设(collective assumption)被经常使用,在这个假设中包的类标签是与该包中所有示例相关的一个属性.总的来说,在集体假设中有2种方法可以获取包的类别标签.一种是示例级方法[2,10],该方法有一个示例级传递函数来获取每个示例的分数,然后通过一个MIL汇合(例如最大汇合和均值汇合)来获得包的类标签.另一种是包级别方法[5,11],它将多示例数据转换为包级别的表示,然后在包级别表示上训练包级别分类器来预测包的类标签.在大多数情况下,包级别方法更显灵活且更具竞争力.
本文我们研究面向增量分类的多示例学习,除了多示例学习还主要涉及到了增量学习的问题.增量学习意味着我们需要从随时间出现的一系列数据中学习,已有的参考文献中增量学习主要分为了3类:任务增量学习(task-incremental learning)、领域增量学习(domain-incremental learning)和类增量学习(class-incremental learning, CIL).本文中我们主要关注类增量学习:随着时间的推移会出现新类别的数据且旧类别的数据不可见,我们需要学习一个统一的分类器去识别所有新旧类的组合.这是一个非常现实的问题,在这个过程中主要面临旧数据遗忘的挑战.
现有的解决CIL中遗忘挑战的方法有2类主流,分别是基于数据的方法和基于参数的方法.基于数据的方法会在新数据中放入一部分旧数据,有的方法[13-15]试图从旧数据中选择一组代表性的样本存储备用,有的方法[16-18]使用合成的样本来表示旧数据的分布.这时新旧任务之间的不平衡问题成为关键挑战.具体而言,文献[13-14,19]通过减少对新数据的偏见来缓解这个问题.基于参数的方法中主要有基于正则化和基于结构2种策略.前者基于显式或隐式的正则化策略使用不同的指标来识别和惩罚原始网络重要参数的变化,例如弹性权重巩固(elastic weight consolidatio)[21]、突触智能(synaptic intelligence)[22]、记忆感知突触(memory aware synapses)[23]和知识蒸馏(knowledge distillation)[24-25]等方法.后者[26-28]主要保持与旧类相关的网络参数固定,并以不同形式分配新参数去学习新类的知识.
本文提出的基于注意力机制及原型分类器映射的多示例增量学习方法,动态地对类别增量多示例数据进行学习和识别.不仅解决了多示例数据的统一表示和分类问题,还使其能够在类别增量的环境下很好的运行.该方法可以用极低的存储代价很好地保留旧多示例类别信息,并对不平衡的增量新旧数据保持无偏和鲁棒的效果.
2 本文方法
本节我们主要介绍针对类别增量数据挖掘任务的基于注意力机制及原型分类器映射的多示例增量学习方法MICIL.
MICIL方法流程如图1所示.首先,针对多示例包(MIL bag),通过基于注意力的多示例汇合操作将每个包表示为包层级特征表示,其中,注意力机制主要设计用于关注并增强包中的关键示例(key instance),进而突出包中的类别相关信息.之后,在每类的包层级特征表示基础上将得到每类对应的类别原型特征,该原型可包含类别级信息,并具有一定的判别能力与鲁棒性.同时,由于类别原型每类仅有一个,可有效缓解增量学习中较为显著的类别不平衡问题.基于类别原型,我们提出构建以多层感知机为实现形式的类别分类器映射函数,将类别原型映射为类别分类器.与此同时,对于增量学习中的已知类别,我们将其类别原型进行存储,在推理时使用参数共享的类别分类器映射函数由存储的类别原型获取对应的已知类别分类器.损失函数方面,对于增量学习新任务中的多示例包,一方面将其作用于已知类类别分类器得到已知类类别预测;另一方面作用于增量新任务的类别分类器得到对应类别预测,对于该2种不同类别预测,将通过对应的损失函数作为模型驱动进行参数训练及优化(详见第2.4节内容).

Fig. 1 Framework of our proposed MICIL method图1 基于注意力机制及原型分类器映射的多示例增量学习方法(MICIL)示意图
2.1 问题定义及符号表示

2.2 基于注意力机制的多示例包表示
根据2.1节描述,多示例包具有较为复杂的集合结构,对于数据挖掘任务的后续处理构成了一定挑战.如何构建既能体现多示例包信息又形式统一简单的包级别特征表示,是MICIL需要解决的首要问题.
此外,多示例包的另一特点为包中示例的无序性与数量不定性,即多示例包中示例的顺序与数量对于包的类别标记无任何影响.因此,我们提出基于注意力机制设计适应多示例包形式的包级别汇合操作(MIL bag pooling),用以将多示例包表示为单一的特征向量.
(1)
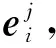
(2)
其中,αj为权重参数,其形式化为
(3)
其中,v和M为MICIL法注意力机制中的参数,可通过最终模型的损失函数进行整体优化.
可以发现,上述式(2)的注意力汇合操作可赋予包中示例不同重要程度的权重,因此包中反映类别信息的关键示例(key instance)可获得较大权重,无关示例则对应较小权重,如此便可更好地在Xi的包级别特征表示ui上体现类别相关信息.
2.3 基于类别原型映射的多示例增量分类器生成
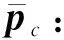
(4)
其中,Ωc={k|yk=c}.类别原型表示具备较强泛化能力与鲁棒性[35],同时不同类别均只有一个类别原型,因此使用类别原型进行后续操作可避免不同类别样本不平衡带来的影响与挑战.
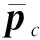
(5)
MICIL推理时,即使用wc对多示例包Xi的包级别特征ui进行类别预测:
(6)
2.4 损失函数及模型训练
针对2.1节的多示例学习类别增量设定,模型首先根据已知类别样本集合Do,由式(4)得到类别原型特征表示并进行存储,同时基于式(5)获得Do中类别的类别分类器,根据式(6)的操作可进行模型训练获得初始阶段Do对应的类别分类器映射函数.
之后,待第t阶段训练新任务及对应训练集合Dt到来时,对Dt中的多示例包做式(4)同样操作得到Dt中对应的类别原型特征表示.随后,对于存储的已知类类别原型和Dt中对应的类别原型,一同作用类别分类器映射函数fmapping(·;θmapping),由式(5)分别可得已知类(old class)类别分类器{wo}及第t阶段新任务(new task)中对应类别的分类器{wn}.
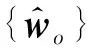
(7)
其中,l为当前阶段的已知类别数.另一方面,对于第t阶段新任务中的类别预测损失则较为直观.在第t阶段,Dt中的样本同时含有X及其真实标签y,故其损失函数可表示为常用的交叉熵损失:
(8)
总体而言,模型训练的损失函数为式(7)和式(8)的结合,即:
L=Lnew+λLold,
(9)
其中,λ为两项的调节因子超参数.
3 实验与结果分析
本节我们首先介绍实验数据集和实验设定,之后介绍主要的对比方法及汇报实验结果,最后对MICIL方法进行消融实验并进行讨论分析.
3.1 数据集和实验设置
我们分别在3类多示例多类别问题上进行增量学习任务的实验验证:
1) 文本分类.文本分类是多示例学习的重要应用领域,相关数据中Text[32]是较为常用的标准数据集.Text数据集共有12个文本类别,每个样本对应一篇学术论文,论文摘要和参考文献中的摘要对应了多示例包中的若干示例.TF-IDF[36]特征用来抽取摘要内容的向量表示,此后,主成分分析(principal component analysis, PCA)[37]被用于该向量表示进行去噪操作,最终示例的向量表示长度为300维.
2) 物体图像识别.图像识别亦是多示例学习的重要应用任务.本文我们在物体图像识别(object-centric image recognition)和场景图像分类(scene-centric image classification)这2类经典的图像识别任务进行实验验证.在物体图像识别任务中,我们选用多示例学习中常用的COREL数据集[33]进行实验.COREL共有10个图像类别,每类含有100张384×256分辨率的图像,其示例表示形式我们遵循文献[36]中的设定,即将图像划分为6个大小相同的图像块,之后通过预训练的Alex-Net[38]抽取4096维特征,再经过主成分分析降维到200维.
3) 场景图像分类.该任务中我们选用NYU-v1[34]进行实验验证.该数据集共含有2 284张640×480分辨率的图像,对应7个场景类别.与COREL不同的是,NYU-v1还提供了超分辨率图像块作为像素语义标签.我们根据语义标签产生相应的图像区域并将其作为示例进行特征抽取[36],与COREL类似,最终的示例特征为200维的经PCA后的特征向量.
对于MICIL方法中的实现细节,式(1)中的特征嵌入函数我们将其实现为2层多层感知机,中间层使用ReLU作为激活函数.式(5)中的类别原型映射函数我们将其实现为3层多层感知机,中间层使用ELU作为激活函数.式(9)中的超参数设置为1.另对于增量学习设定而言,我们共设置4个阶段,3个数据集的各阶段类别划分如表1所示:
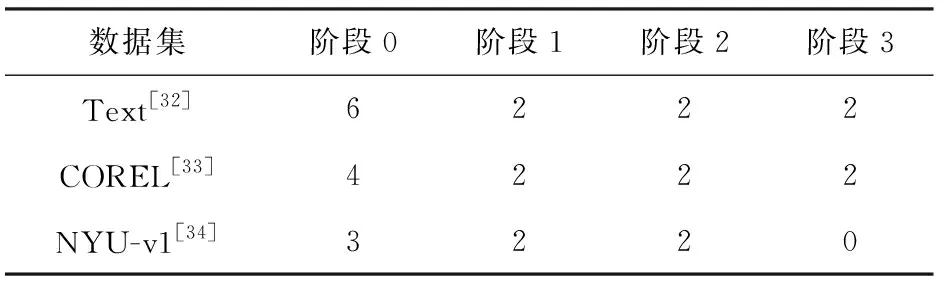
Table 1 Categories Splitting in the Incremental Learning Setting表1 增量学习设定下的类别划分
3.2 对比方法
本文主要选取代表性方法作为对比方法进行实验验证与结果对比,简述如下:
1) FineTune[39].直接基于MICIL方法中存储的类别原型映射生成分类器,并在当前轮次数据上进行模型微调(fine-tuning),但可以预计该方法会引起模型“灾难性遗忘”.
2) LwF[25].通过知识蒸馏进行类别增量学习.但LwF原方法不支持多示例形式数据,故实验时将多示例包通过简单的平均汇合操作变换为单一向量后,使用LwF方法进行模型学习与性能评估.
3) Coil[29].通过建模类别语义关系学习相关增量任务间关系,从而支持已知类和新增类别的共同识别.需指出的是,Coil方法同样不支持多示例形式数据,类似LwF中的处理手段,依然使用平均汇合操作变换为单一向量后进行实验评估.
4) Learn++.MIL[30].在集成学习框架下,通过动态选择适合当前轮次数据的多示例分类器并以此进行更新来支持增量类别识别,该方法可直接处理多示例形式数据.
3.3 主要结果
3个多示例、多类别增量任务的对比实验结果分别如表2、表3和表4所示:
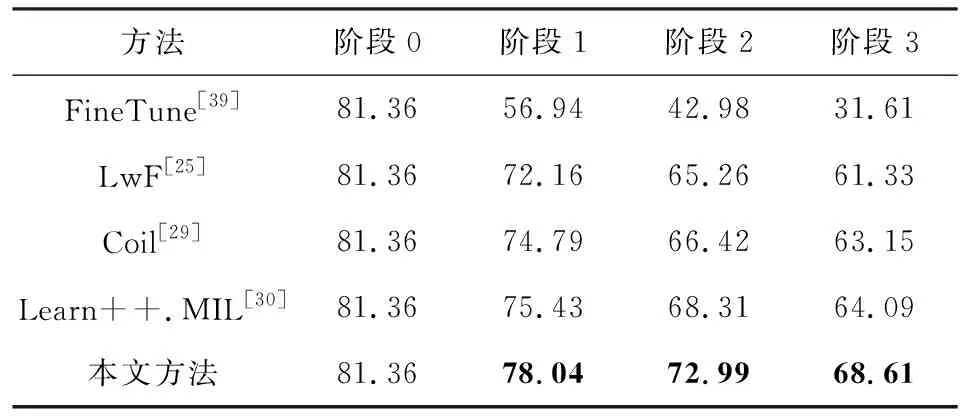
Table 2 Comparison Results on Text Dataset表2 Text数据集上的结果对比
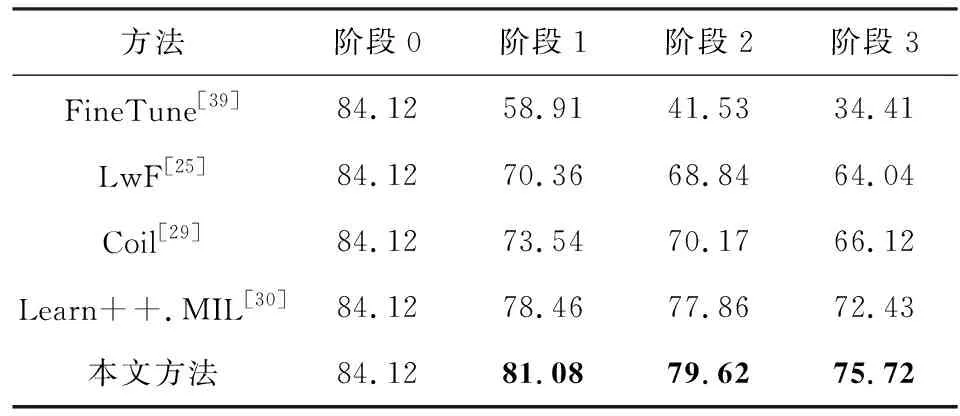
Table 3 Comparison Results on COREL Dataset表3 COREL数据集上的结果对比

Table 4 Comparison Results on NYU-v1 Dataset表4 NYU-v1数据集上的结果对比
其中,为了避免类别不平衡带来的评估不准确问题,我们选用macro-averageF1 score作为评测指标.我们对最好的结果进行了加粗展示,从这3个表中可以看到我们的方法都取得了最好的结果.我们提出的MICIL方法比先前最好的方法在连续的增量阶段中:在Text数据集上分别提升2.61%,4.68%和4.52%;在COREL数据集上分别提升2.62%,1.76%和3.29%;在NYU-v1数据集上分别提升2.91%和3.20%.
总体来看,我们方法几乎在3个数据集上都随着增量数据的增长能够比对比方法展示更大的优势.这说明了我们的方法在多示例学习中可以更好地缓解旧数据遗忘的挑战.
3.4 消融实验及分析
如表5所示,为了验证提出的MICIL方法中2个核心模块的有效性,我们在Text数据集上进行了消融实验.其中行2是我们的方法去掉注意力机制直接使用平均汇合操作的结果.对比行1和行2的结果,可以看到我们基于式(7)的知识蒸馏能够有效地缓解旧数据遗忘的问题,在3个增量阶段分别有16.67%,23.4%和30.95%的精度提升.对比行2和行3可以看出,我们提出的MICIL方法中注意力机制在3个增量阶段分别带来了4.36%,6.61%和6.05%的稳定提升,这验证了挖掘包中体现类别相关信息的关键示例十分有益于MIL任务.

Table 5 Ablation Studies on Text Dataset表5 基于Text数据集的消融实验结果
3.5 注意力机制的分析
如2.2节所述,为应对多示例包的复杂集合结构,我们采用基于注意力机制的包表示方法来刻画多示例样本.本节我们针对COREL数据集对其完成注意力机制后的示例权重进行分布情况分析.
COREL数据集因每个样本对应6个示例(即图像块),在注意力机制完成前,其示例权重αj=1/6;而完成注意力机制后,我们将所有示例权重组织为图2的柱状图形式.
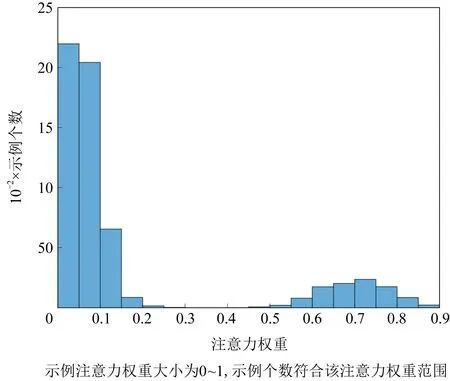
Fig. 2 Histogram of the attention weights in MICIL图2 MICIL方法中的示例注意力权重分布.
可以看出,在经过注意力机制的操作后,多示例包中的示例权重有了明显的改变.大部分示例权重集中在0~0.15左右,该部分示例对应多示例包中的类别无关示例.而可有效刻画类别的关键示例则占比较小,但其权重值较大,多集中在0.75左右,这与多示例包中关键示例的自然观察较为一致.
4 结 论
本文提出了一种基于注意力机制及原型分类器映射的多示例增量学习方法以应对面向增量分类的多示例学习任务.首先,多示例包汇合操作利用注意力机制关注并增强多示例包中的关键示例并将其汇合形成包层级特征表示.之后,包层级特征表示被用于生成对应的包类别原型特征表示并且包类别原型特征将以极小的代价存储下来用于缓解遗忘.然后,类别原型映射函数将所有新旧类别原型特征映射为对应的类别分类器,以对所有新旧类进行预测;同时使用知识蒸馏,将上一阶段类别原型映射函数对旧类别生成的分类器的预测结果作为“教师”,指导当前阶段更新后的类别原型映射函数对旧类别生成的分类器的预测结果,使得类别原型映射函数能够很好地保留旧类别的知识.通过注意力机制对多示例包类别信息的表示、交叉熵损失对增量类别的学习以及知识蒸馏对旧类的指导,我们的方法能够很好地处理面向增量分类的多示例学习问题,并在3个不同任务的多示例数据集上验证了我们MICIL方法的有效性.
未来,考虑多示例包与类别原型关系的类别原型特征表示的构造方法值得进一步研究.
