基于K-means的大数据相似重复记录检测
2022-08-12张平程新莲
张平,程新莲
(1.安徽职业技术学院 信息工程学院,安徽 合肥 230011;2.嘉善万顺达电子有限公司,浙江 嘉兴 314100)
0 引 言
目前大多数企业的业务系统积累了大量业务数据,其中不乏许多的冗余数据,严重影响了数据分析和数据挖掘的结果,冗余的数据导致数据价值密度低。为了能够从数据中获取更精准的有价值的信息,有必须对数据进行清洗,也成为数据预处理。数据清洗就是从大量的数据中找出重复、无用或歧义的数据并去除,其中检测出这些脏数据尤为重要。
近些年来国内外很多学者和专家都重视数据清洗工作的研究,大量学者都专注于相似重复记录检测的研究,相似重复记录检测是数据清洗工作的重要环节。目前大数据具有维度高、数据量大、数据结构复杂等特点,导致传统的检测方法对大数据的相似重复数据检测时间效率和准确率都不高,大量的排序和比较工作耗费大量的时间,加上数据复杂,很多算法都不能有效进行检测,因此,本文根据大数据的特点提出了通过聚类分组后再检测相似重复记录的方法,提高了检测效率和检测的准确率。
1 相似重复记录
大数据中的重复数据又分为完全重复数据和相似重复数据两种情形。如果数据集中存在两条记录,除了主键字段不同,其他字段的值都相同,那么这两条记录即为完全重复数据。如果数据集中存在两条记录,除了主键字段不同以外其他字段在描述或格式书写上存在差异,但是表示的内在含义是相同的两条记录即为相似重复记录。如表1所示。

表1 学生信息表
如表1所示学号为100001和100002的两条记录,除了主键字段不同以外,其他字段的值都是完全相同的,故为完全重复记录,而学号100001和100003的两条记录,除了主键字段相同以外,其他字段存在虽然表示方法不一样,但是含义是一样的字段,比如性别字段“1”表示男性的意思;还存在字段值意思相同的简称表示,比如学校使用全称和简称表示,其实表示的都是一个意思;这些本质上是同一个含义而不容易发现的重复数据称为相似重复记录。本论文主要研究重点是相似重复记录检测问题。
2 相似重复记录检测
数据中存在大量的相似重复记录影响了数据的质量,为了能够挖掘出有价值的信息,需要对数据进行清洗,从多维复杂的数据集中把冗余数据检测出来的过程称为相似重复记录检测。
目前检测相似重复记录的主要方法有两类:
排序比较检测算法,先进行数据集某几个关键字段排序,经过多轮排序,具有相同或相似的字段值的数据就会聚集在一起;还可以通过滑动窗口在一定范围内从上往下逐一比较进行相似记录筛选来检测相似记录。
相似记录转换为相似度比较检测。两条记录是否相似是通过比较李璐相似度进行度量的,相似度的计算主要采用编辑距离的算法,距离公式的选择有多种诸如欧式距离、余弦距离等。相似检测的时候首先会根据距离公式计算一条记录中的每个字段的相似度,在合并统计出整条记录的相似度,同时会科学设定相似度的阈值范围,接近阈值的筛选归集为相似重复记录,本文的算法就是基于该思想实现的。
国内外学者目前对相似重复记录检测提出了很多方法,比如Hemandez等提出了近邻排序(SNM)算法,该算法先分析数据确定关键字段,依据关键字段进行排序,然后通过滑动窗口对排序后相近邻的记录逐个比较找出相似的记录。很多国外内学者根据SNM算法提出了如多趟近邻排序等改进算法或者变步长改进了SNM算法提高了检测精;梁雪提出了一种量子群与向量机相结合的算法检测相似重复记录,改善了检测的精度;吕国俊等人提出了多目标蚁群与二分类支持向量机结合的算法检测相似重复记录;张平等人采用q-gram将记录映射为空间点,将大数据进行划分后采用改进的SNM算法检测,提高了检测效率。以上这些方法在小数据量情况下检测精度都有明显的提高,但是针对大数据的检测耗时问题没有很好地解决。
本文对传统检测算法对大数据不能有效处理的情形,提出了一种本文提出K-means聚类分组在检测的算法。首先通过改进K-modes聚类算法对大数据集进行相似聚类分组,然后再各分组中采用经典的近邻比较算法SNM提高检测的精度。
3 K-means聚类分组检测算法
3.1 K-means聚类分组检测流程
聚类分析方法是将数据对象划分成多个类或簇,是一种非监督学习方法,通过聚类可以将大的数据集划分成多个簇,在同一个簇中的数据之间相似度接近,而不同簇中的数据之间相似度差距较大,通过聚类可以较好地划分数据集。数据间的距离度量是根据编辑距离来度量的,采用不同的距离算法略有差异,聚类算法广泛运用于数据挖掘中数据集的划分。
K-means聚类是一种无监督的学习,它可以把相似的对象聚集到同一个簇中。根据这个原理,可以考虑通过聚类把大数据中的记录映射成一个个空间对象点,然后通过聚类把相似的记录聚集到一个簇中,从而筛选出相似重复记录。当然,受聚类中心的点选择的影响,各个聚集的相似重复记录可能会有交叉现象产生,可以通过在各个簇内进行二次检测就能很快剔除相似重复记录。本文基于这个思想提出了一种在大数据环境下通过K-means聚类进行分组,在从聚类后的簇中进行二次SNM检测,这样就能确保精度的情况下减少大数据集排序的耗时问题
SNM近邻排序算法思想:先根据专家经验评估确定排序关键字段的生成方法,然后遍历整个数据集,对每一条记录生成排序关键字,按照排序关键字对记录进行排序,这样数据集排序后使得相似记录都处于邻近位置,最后采用滑动窗口对数据集进行相似重复检测。
聚类分组的检测步骤主要分为聚类分组和组内相似检测两个阶段,第一阶段采用K-means聚类对大数据集进行分组,随机选择个聚类中心,通过聚类迭代,产生个聚类分组的数据相似簇,每个簇内数据相似,不同簇间的数据有较大差异。第二阶段采用经典的SNM近邻排序算法在聚类簇内进行检测,确定排序关键字对相似簇进行排序,在用滑动窗口逐一比较检测,从而确保了检测的准确性。具体检测步骤如图1所示。
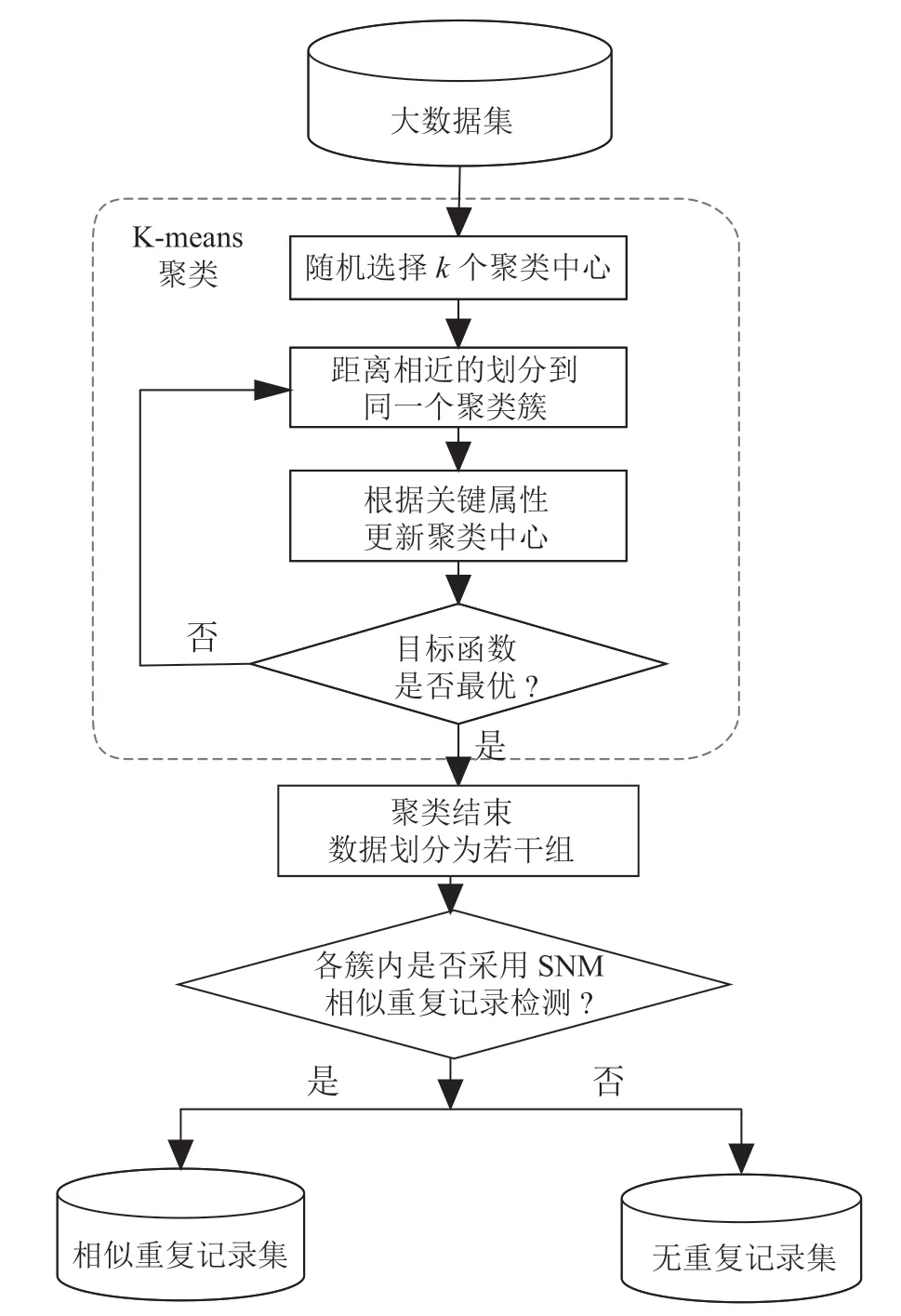
图1 聚类分组的检测流程图
3.2 K-means聚类分组检测算法
means算法采用距离来划分聚类,距离的计算方法采用经典的欧式距离度量记录与中心点之间的距离,把距离中心点近的点归到同一个簇中,直到收敛。
定义1:假设维数据可以转换为维度向量x(x,x,…,x)和x(x,x,…,x),则欧几里得几何距离可定义为:
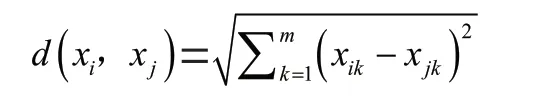
定义2:假设有维的两条记录和,它们对应于属性R的字段值分别为和,则字段间相似度为S(,),则记录的相似度为:

算法:基于的K-means聚类分组检测算法
输入:个维度,个数据的数据集,假设初始聚类数目。
输出:个相似重复记录的聚类簇。
(1)随机选取个不同的数据对象作为初始聚类中心;
(2)计算数据集中个点到个聚类中心的欧式距离,将然后将每个对象分配到与其距离最小的聚类中心所在的簇中;
(3)在得到的个簇中,根据提出的簇中心点的更新方式选出新的中心点,迭代直到簇中心不发生变化,聚类过程结束,得到个的相似的聚类簇。
(4)用近邻SNM算法对已经排序后的记录簇进行相似重复记录检测。对每个簇内数据确定排序关键字的生成方案,设定滑动窗口大小为;
(5)对每个簇内每条记录生成排序关键字,按照排序关键字对簇内记录进行排序;
(6)采用滑动窗口对已经排序后的记录比较进行相似重复记录检测。检测设置阈值,如果相似度大于或者相似度为1的都归集为相似重复记录。
4 实验分析
本文采用Febrl数据集的数据,通过生成器人工生成了10、20、30、40和50万条数据集进行相似重复记录检测的验证。实验为了能进行有效对比,人为地增加相似重复记录,故数据集中的数据由原始数据和相似重复数据构成,它们之间的占比为各50%。
评价相似重复记录检测的评价标准主要从两个方面一个是的准确率和运行时间。为了验证算法的有效性,我们将该文所提出的K-means聚类分组相似记录检测算法与文献[2]所采用的经典SNM算法从准确率和运行时间两个方面进行了对比实验,如图2所示。

图2 检测精度和运行时间对比
从图2中可看出,从检测精度上对比看,当数据量较少时聚类检测准确率低于SNM方法这是因为聚类对小数据集会导致相似记录在不同的簇中交叉,簇之间的距离差异不够明显,并不能将相似重复数据分散的不同的簇中,但随着数据量的增大,聚类分组的方法明显优于SNM方法,检测精度明显改善。从时间上看,数据量较小采用聚类分类数据相对来说比较耗费时间,检测时间较长,随着数据量的增加,聚类分组体现出其处理大数据的优势,随着数据量的不断增大,检测时间比SNM算法少的明显。
5 结 论
本文针对大数据环境下相似重复记录检测时间效率和精度不佳的问题,提出了一种基于K-means聚类分组检测算法。实验分析表明,该方法在大数据相似检测方面优势明显,运行时间和检测精度都比直接检测算法都有明显的提高。本文中聚类中心是随机选择的,对于不同的数据集应用该算法可能会导致数据中心敏感问题,下一步将会对聚类算法进行改进,通过改善聚类中心敏感性问题,对大数据集能有效划分,进一步提高检测的精度。
