基于Transformer编码器的智能电网虚假数据注入攻击检测
2022-08-10唐永旺
陈 冰 唐永旺
1(河南工业大学漯河工学院电气电子工程系 河南 漯河 462000) 2(中国人民解放军战略支援部队信息工程大学信息系统工程学院 河南 郑州 450002)
0 引 言
智能电网以其可靠、高效和经济的传输特点成为现代电力系统最重要的组成部分,然而智能电网严重依赖数据通信和大规模数据处理技术,容易遭到各种恶意网络攻击[1]。尽管已经颁布了很多针对智能电网安全的通信标准、官方指南和监管法律(如IEC 61850-90-5、NISTIR7628等),恶意网络攻击仍活跃于智能电网中。
虚假数据注入攻击(False Data Injection Attacks,FDIA)是Liu等[2]提出的恶意网络攻击技术,被证明是一种对智能电网状态估计产生严重影响的恶意网络攻击行为。其通过规避现有数据注入监测系统,篡改电网的状态估计数据,诱导电网控制中心作出错误决策,导致整个智能电网出现故障。如何高效地检测 FDIA,对于保障智能电网安全运行具有重要意义。
传统的FDIA检测思路主要归为两种[3-4]。一种是策略性的保护部分关键基础测量数据的安全,避免恶意数据注入的发生。如:Kim等[5]提出两种快速贪婪算法分别用于选择待保护的测量子集数据和寻找存储安全相量测量单元的位置。Bi等[6]利用图形分析研究方法引入到FDIA检测中,提出精确、低复杂度的近似算法来选择保护系统中最小的数据测量值。另一种是通过独立检验每个状态变量进行FDIA检测。例如:Liu等[7]考虑到电网状态时间测量的内在低维度以及FDIA的稀疏性质,将FDIA检测视为低秩矩阵分离问题,并提出核规范最小化和低秩矩阵分解两种优化方法来解决该问题。Ashok等[8]提出了一种在线FDIA检测算法,该算法利用统计信息和状态变量的预测来检测量测异常。
近年来随着智能电网通信数据量级的增加和FDIA方法的不断升级,传统方法在进行FDIA检测时越来越力不从心。机器学习以及深度学习算法逐渐应用在智能电网恶意网络攻击检测中,并较传统检测方法检测性能有明显提高[9-13]。Ozay等[14]利用监督和半监督机器学习方法完成对高斯分布式攻击的分类。Esmalifalak等[15]设计了一种基于分布式支持向量机的标签数据模型和一种无监督学习的统计异常检测器。He等[11]采用条件深度信念网络有效学习了FDIA的高维时间行为特征。Niu等[16]利用卷积神经网络提取和长短时记忆网络(Long Short Term Memory Network,LSTM)学习量测状态序列的时间和空间关系特征,进而实现FDIA检测。James等[17]基于小波变换和单向门控循环单元(Gated Recurrent Unit,GRU)进行系统状态连续估计,检测序列状态中的FDIA。Wang等[18]利用3层LSTM作为序列编码器,学习FDIA样本的特征,在测试数据中准确率高达90%。深度学习算法可以自动学习电网中各节点的状态量测数据特征,发现异常状态序列或对异常序列分类,整个过程不需要人工设定特征。
然而,现有基于循环神经网络[16-18](Recurrent Neural Network,RNN)的FDIA检测方法在训练量测值时仅使用了多层单向的RNN训练框架,单向的RNN模型在处理序列数据时只能利用已经出现过的序列元素,忽略了未来的序列信息,导致模型性能下降,影响特征最终的提取效果。这些方法中只选取RNN最后一个时刻的隐状态或者各时刻隐状态的拼接作为提取的特征,无法突出注入攻击数据的特征。因为注入攻击向量不一定会对状态量测数据的每一维都均匀地注入攻击,有可能只对一部分维数的数据进行攻击。另外,这些方法只针对单个样本参数(电压、电流、有用功、支路电流等)进行分析,没有考虑连续时间样本参数之间的关联关系。再者,RNN的顺序性决定其训练缓慢,因为长序列需要更多的处理步骤,反复循环的结构也使训练更加困难。
Transformer[19]是当前机器翻译领域的主流模型,利用基于注意力机制的编码器和解码器直接学习源语言内部关系和目标语言内部关系。相较于RNN,Transformer无循环结构,可以并行处理序列中的所有元素,从整个样本序列中挖掘与当前预测元素关系紧密的上下文元素,Transformer编码器具有更强的特征提取能力。
考虑到Transformer以上优点以及量测数据序列元素互相依赖、关系紧密的特点,本文提出一种基于Tansformer编码器的FDIA检测框架,输入两个连续时间量测样本,对后一时刻的样本进行检测。首先,对连续时间样本数据进行归一化处理,结合连续时间样本中元素相对位置信息得到连续时间样本向量。然后,采用Tansformer编码器对量测序列进行建模,通过多头自注意力机制计算长距离依赖关系,挖掘结合样本中和样本间测量值的特征表示。最后,将该特征表示输入到全连接神经网络层和Softmax层,输出后一时刻样本受到注入攻击的概率,完成FDIA检测。
1 相关背景
1.1 虚假数据注入攻击
在电力系统中,待估计的状态变量包括电压幅值V∈Rn和相位角θ∈([-π,π])n,n是总线数量。令z=[z1,z2,…,zm]T∈Rm表示量测向量,x=[x1,x2,…,x2n]T∈R2n代表状态变量,e=[e1,e2,…,em]T∈Rm代表量测误差向量。在标准直流系统下,可忽略电阻,电压幅值均为1,仅考虑带有相位角的状态变量,量测值和状态变量的关系如式(1)所示。
z=Tx+e
(1)
式中:T是m×n的拓展结构雅可比矩阵。求使加权残差平方和最小的状态估计变量x,目标函数如式(2)所示。
j(x)=(z-Tx)TR-1(z-Tx)
(2)
式中:R是协方差矩阵。利用加权最小二乘法求解式(2)的目标函数,如式(3)所示。
(3)

1.2 注意力机制
注意力机制的本质是将一个查询向量和一组键值向量对映射到输出,查询向量与键向量用于计算每个值向量对应的权重,值向量的加权和为输出。常用的注意力函数为加法注意力(additive attention)和点乘注意力(dot-product attention)[21],由于点乘注意力可以利用高度优化的矩阵乘法运算,高效且更加节省空间,因此本文选取放缩点积注意力,其计算流程如图1所示,其中:Q代表查询向量矩阵;K代表键向量矩阵;V代表值向量矩阵;Q和K中每个向量的维度为dk,V中每个向量维度为dv。

图1 放缩点积注意力计算流程

(4)
2 基于Transformer的FDIA检测方法
本文利用Transformer编码器提取攻击样本的特征,提出基于Transformer编码器的FDIA检测框架,其训练结构如图2所示。

图2 本文提出的FDIA检测模型框架
该框架主要分为输入层、Transformer编码层、全连接层和Softmax层四大部分,[CLS]是样本之间的分类符,表示样本A之后的连续时间样本B是否受到虚假数据注入攻击。[SEP]是样本之间的分隔符,为便于区分连续时间样本的切割点。该训练框架将连续时间样本A、B作为模型输入,通过Transformer编码层提取单样本各测量值之间的特征和两个连续时间样本A、B整体之间的特征,用于判断样本B是否被注入攻击。
2.1 输入层
输入层的作用是将样本A、B向量化,将Toki的向量、相应的位置向量、分割向量进行求和[22],如图3所示。

图3 输入层向量化的过程
由于Transformer编码器中没有循环或者卷积结构,无法使用序列元素的位置信息,因此对序列编码时需要添加位置信息。相对位置编码表示如下:
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(5)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(6)
式中:pos代表位置;i代表维度。相对位置编码的每个维度均采样于正弦曲线,根据式(7)和式(8)可知任意位置的编码PE(pos+k)都可由PE(pos)的线性函数表示,该特点为模型捕捉序列元素之间的相对位置关系提供便利。
sin(α+β)=sinαcosβ+cosαsinβ
(7)
cos(α+β)=cosαcosβ-sinαsinβ
(8)
2.2 Transformer编码层
Transformer编码层由三层的双向Transformer编码器构成,具体结构如图4所示。

图4 Transformer编码层
图4中每个Trm均代表一个Transformer编码器;Ei表示输入的词向量,由Toki的向量、位置向量、分割向量的和组成;Ti表示第i个Token在经过Transformer编码层处理之后得到的特征向量,其模型结构如图5所示。

图5 Transformer编码器
Transformer编码器由6个相同的编码层堆叠而成,每个编码层又包括两个子层,分别为多头自注意力层和位置全连接层。为了更好地优化深度网络,整个网络使用了残差连接和层归一化。因此,每层输出可以表示为LayerNorm(x+Sublayer(x)),其中Sublayer(x)为各层的功能函数。为了使模型正常训练,模型中的所有子层以及嵌入层都需要产生维度dmodel的输出。
(1) 多头注意力机制。一次自注意力计算关注到的序列关系有限,而量测数据中的功率、电压、电流、有用功率、无用功率、总功率和分支功率等数据之间关系多样,因此本文采用多头注意力使编码器同时关注来自不同位置的不同表示子空间的信息,其具体计算流程如图6所示。

图6 多头注意力机制计算流程
图6中,首先将Q、K、V线性变换后分h次输入到放缩点乘注意力模型,h即为多头注意力的头数,每次线性变换的参数矩阵不同。然后将h次的放缩点积注意力结果拼接后再进行一次线性变换得到多头注意力的结果。计算公式如下:
Multihead(Q,K,V)=Concat(head1,head2,…,headh)WO
(9)
(10)
(2) 位置全连接前馈网络。位置全连接前馈网络分两层,用于处理每个位置的多头注意力计算结果,其输入和输出的维度相同。第一层的激活函数是ReLU,第二层是线性激活函数,如果多头注意力层输出表示为X,则FFN可表示为:
FFN(x)=max(0,XW1+b1)W2+b2
(11)
式中:W1、b1和W2、b2分别是两个激活函数的参数。Transformer编码器通过对输入的序列不断进行注意力机制层和普通的非线性层交叠得到最终的序列表示。
2.3 全连接层和Softmax层
对于量测数据训练集C,给定输入样本A:x1,x2,…,xN,样本B:x1,x2,…,xM和对应标签y。[CLS]在最后一个Transformer编码器的隐藏层输出记为C∈Rdmodel,经过全连接层和Softmax层后对y进行预测:
P(y|||x1,x2,…,xN,x1,x2,…,xM)=Softmax(CWf+b)
(12)
式中:Wf是全连接层的权重矩阵;b为偏置;P(y|||x1,x2,…,xN,x1,x2,…,xM)是Softmax层计算的概率结果。则模型训练的目标为最大化目标函数L(C):
(13)
FDIA检测模型训练完毕后,就可以对连续时间的量测数据样本进行检测。
3 实 验
3.1 实验数据
本文选择该领域主流的IEEE 14-bus和IEEE 30-bus节点测试系统作为测试环境,系统网络拓扑、节点数据、支路参数等均从Matpower中获得。在每个环境中利用Matpower软件仿真生成150 000对连续时间的正常量测数据样本和50 000对后一时刻量测值被注入攻击的样本,标签分别为-1和1。IEEE 14-bus中每个样本包括54个量测值,IEEE 30-bus中每个样本包括112个量测值。每个测试系统的量测值包括电压幅值、总线相位角、总线注入有功功率和无功功率、各支路注入有功功率和无功功率等,将正常样本和FDIA样本进行去均值和归一化处理,分别按照7 ∶3的比例随机抽取样本制作训练集和测试集。
3.2 评测标准
本文采用准确率、漏报率和误报率三个FDIA检测领域通用的评测指标验证本文方法的可行性和有效性,首先定义以下变量:
真负类(Ture Negative)表示将正常量测样本正确地识别成正常量测样本的数量,记为Tn。
假负类(False Negative)表示将正常量测样本误识别成FDIA样本的数量,记为Fn。
真正类(Ture Positve)表示将FDIA样本正确地识别成FDIA样本的数量,记为Tp。
假正类(False Positive)表示将FDIA样本误识别成正常量测样本的数量,记为Fp。
(1) 准确率(记为Ac)计算表达式为:
(14)
式(14)表示所有被正确判断的样本数量占所有样本的百分比,准确率越高,算法越好。
(2) 正报率计算表达式为:
(15)
式(15)表示在所有被检测为FDIA样本中,被正确预测FDIA样本所占的百分比。正报率越高,算法越好。
(3) 误报率计算表达式为:
(16)
式(16)表示在所有被检测为正常样本中,被错误预测样本所占百分比,误报率越高,算法越差。
3.3 实验设置与分析
本文选取文献[15,18]的方法作为对比方法,文献[15]利用标签数据的监督学习训练分布式支持向量机对FDIA样本检测,测试结果记为SVM;选取文献[18]提出的方法,基于三层双向LSTM模型学习单个样本状态量测值序列的特征,测试结果记为Bi-LSTM。另外,将三层双向Transformer编码器作为编码器,测试结果记为Bi-TRAM。
本文方法首先分别将IEEE 14-bus和IEEE 30-bus环境中获取的单个样本归一化处理为60维和120维(54维和112维数据通过补零变为60维和120维,方便后续处理)的序列向量,则输入为120维和240维的连续时间序列向量。使用TensorFlow深度学习框架构造模型结构。根据模型训练经验,选取多头注意力的头数为10,在训练IEEE 14-bus环境样本时dk=dv=dmodel/h=6,在训练IEEE 30-bus环境样本时,dk=dv=dmodel/h=12,全连接层的隐藏节点数量为768。优化算法选取Adam[23],令β1=0.9,β2=0.98,ε=10-9,epochs设置为100,每批数据batch_size大小为256,学习速率为2e-5,本文连续时间样本训练的方法测试结果记为CON-TRAM。
实验硬件配置为Intel Xeon E5-2650,128 GB内存的服务器、配备12 GB的双GTX 1080Ti独立显卡进行加速训练。
(1) 综合对比实验。本文方法与各对比方法测试结果如表1和表2所示。

表1 IEEE 30-bus综合实验结果
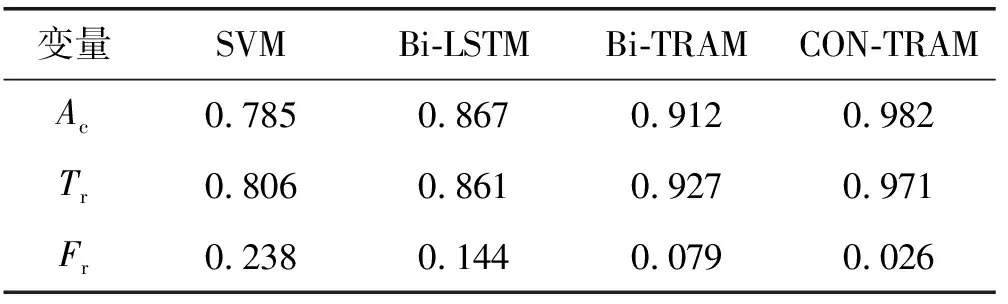
表2 IEEE 14-bus综合实验结果
可以看出,Bi-LSTM的测试结果优于SVM,这是因为RNN网络在处理高维度序列数据方面比SVM更有优势。Bi-LSTM在计算时刻t的隐状态时只利用了量测序列前向t-1时刻和后向t+1时刻的隐状态,而基于自注意力机制的Transformer编码器可以同时利用所有时刻的隐状态,可以轻松捕获长距离的特征,提取量测序列中电压、电流、功率、有用功、无用功、输入功率、输出功率等多种序列关系特征,经过多头注意力层和位置全连接层的多次迭代训练,最终得到量测序列的向量表示。该向量表示可以更加准确地代表量测样本,因此Bi-TRAM三项的评测指标优于Bi-LSTM。本文CON-TRAM不仅关注样本内部特征,还着重考虑了连续时间样本之间的关联特征,利用正常连续内电压、电流、功率、有用功、无用功、输入功率、输出功率等变化的特征判断注入攻击行为。因此CON-TRAM的测试结果与对比方法相比有较显著的提升,与次优结果相比,准确率平均提高7.41%,正报率平均提高4.51%,误报率平均降低60.99%。
(2) 多头注意力机制中头数h的分析。多头注意力计算中头数h是Transformer编码器的关键一步,因此本节以IEEE 30-bus环境的实验数据分析h对FDIA检测的影响。令h在[0,15]内取值,以1为步长训练FDIA检测模型,在测试集进行检测任务,以评测指标准确率分析,结果如图7所示。

图7 准确率随着h的变化分析
可以看出,在[0,10]的区间内,准确率的总体趋势是随着h的增加而增加,从FDIA样本提取的特征关系也越来越多样,说明多头注意力机制对提升检测性能有重要作用。当h为10时达到峰值,随后趋于平稳,可以推测量测样本数据中的电压幅值、总线相位角、总线注入有功功率和无功功率、各支路注入有功功率和无功功率等有10种左右的内在关系,符合数据的真实特征。
4 结 语
本文通过引入Transformer编码器,解决了当前基于单向多层RNN的FDIA检测方法中无法同时利用样本序列前后参数信息的问题。另外,本文提出基于连续时间的量测样本训练FDIA检测模型,利用连续时间样本之间的关联特征进行检测,提高了FDIA检测性能。下一步准备在电网节点规模更大的模拟环境中测试本文方法的有效性。
