基于深度学习的FDD大规模MIMO系统下行CSI反馈技术*
2022-08-10华敏妤张逸彬孙金龙杨洁
华敏妤,张逸彬,孙金龙,杨洁
(南京邮电大学通信与信息工程学院,江苏 南京 210023)
0 引言
大规模MIMO(Multi-Input Multi-Output,多输入多输出)技术被认为是未来通信的关键技术[1-3],然而,对于大规模MIMO 系统,其潜在的益处很大程度上取决于BS(Base Station,基站)侧CSI(Channel State Information,信道状态信息)的准确获取[4]。在FDD(Frequency Division Duplexing,频分双工)系统中,由于上下行通信链路所处的频段不同,无法利用信道互易性由上行CSI 估计得到下行CSI[6],所以必须采用反馈方案让BS 侧实时地获取CSI,这必然会消耗宝贵的带宽资源[7]。在大规模MIMO 系统中,随着系统带宽的增加,反馈量也会成倍增加,而降低反馈量可以有效提升频谱利用率和系统性能。因此,合理的信道反馈是较为精确地获取下行CSI 的有效方案。
近年来,许多学者致力于探索在FDD 系统下CSI 反馈的方案。与传统的基于码本的部分CSI 反馈相比,更多的研究方案倾向于使用DL(Deep Learning,深度学习)技术获取BS 侧的CSI[8]。C-K Wen[8]等人使用深度学习技术开发了一种新型CSI 压缩反馈机制:CsiNet。该机制有效利用了训练样本中的信道结构,在UE(User Equipment,用户设备)侧将估计的下行CSI 压缩成码字并反馈给BS,再在BS 侧恢复下行CSI。J Guo[9]等人基于CsiNet 进一步提出了一个多种压缩率的传感神经网络框架:CsiNet+,提升了CsiNet的网络性能。与CsiNet+不同的是,刘振宇[10]提出了基于维度压缩与码字量化联合优化的CSI 反馈方案CQNet 网络,以解决CSI 矩阵压缩反馈传输效率低的问题。除此以外,随着对下行CSI 反馈研究的深入,下行链路会造成过大的开销。对此,Y Cui[11]等人探索了一种新的解决方案,提出了基于Google 著名的Transformer 结构的深度学习网络TransNet 来完成CSI 的压缩和反馈。
目前无线通信领域中许多IEEE802.11 标准使用OFDM(Orthogonal Frequency Division Multiplexing,正交频分复用)调制信号,上述方法不可避免地会带来I/Q样本的分解问题。针对训练过程分解复值带来的信息损失,本文提出了一种基于深度学习[12]的FDD 大规模MIMO系统CSI 压缩反馈方案——CVCNN(Complex-Valued Convolutional Neural Network,复数卷积神经网络)。该方案利用CVCNN 架构对CSI 中的I/Q 样本直接进行压缩和解压缩,在BS 端近乎完美地恢复出了完整的CSI。
1 系统模型
本文考虑一个简单的大规模MIMO 通信系统[16],假设在BS 端有Nt根发射天线,UE 端有Nr根接收天线,该通信系统有Nc个子载波、No个OFDM 符号数。由于传输过程中不可避免会产生噪声,因此在第i个子载波上接收信号可以表示为:

其中,yi∈C 为接收端的信号,为发送数据矢量,为第i个子载波上Nt根发射天线与Nr根接收天线之间的信道矩阵,ni∈C 为信道中的加性高斯白噪声。CSI 对应的信道矩阵H是每个子载波信息的集合,则CSI 矩阵可以表示为:

其中,hi为一个复数值,代表第i个子载波的衰落增益和相位偏移,i取整数且。
在FDD 系统中,下行链路CSI 矩阵由UE 估计并反馈给BS,具体的CSI 反馈过程如图1 所示。假设UE 端获得了完美的下行CSI,故将重点放在下行CSI 的压缩反馈过程中。本文提出的CVCNN 算法将编码器部署在UE端,编码器由特征提取模块和压缩模块组成,以减少反馈开销。压缩后的CSI 矩阵H可以表示为:

其中,fen表示压缩过程,H和分别表示原始的和压缩后的下行CSI 矩阵,λ1表示压缩过程的训练参数。将通过信道发送给BS,BS 端部署了相应的译码器,通过解压缩操作重构接近最佳的信道矩阵。具体的解压缩过程可以表示为:

其中,fde表示解压缩过程,表示从重构出的下行链路CSI 矩阵,λ2表示解压缩过程的训练参数。

图1 CSI反馈过程图
结合式(3) 和式(4),可以采用MSE(Mean Square Error,均方误差)来衡量整个网络的损失。MSE 的公式可以表示为:

其中,H和分别表示神经网络的输入和输出,表示L2范数。
为了进一步减小MSE 的误差影响,使用NMSE(Normalized Mean Square Error,归一化均方误差)来衡量测试值与真实值之间的差异,NMSE 的公式为:
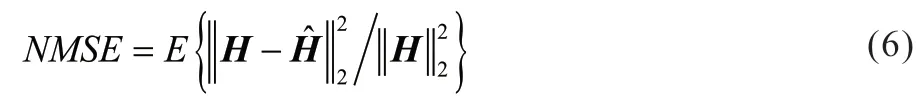
其中,H和分别表示原始的CSI 矩阵和重构得到的CSI 矩阵。此外,为了衡量反馈CSI 的质量,还需余弦相似性指标:
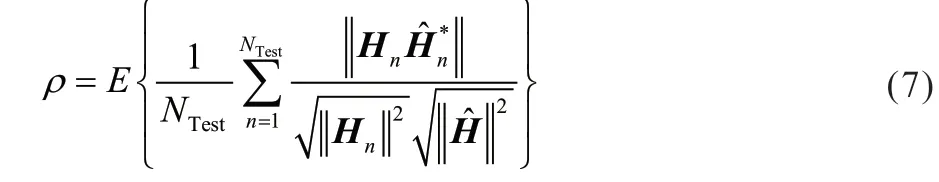
其中,Hn表示第n个样本的原始CSI 矩阵,表示第n个样本重构出的CSI 矩阵,NTest表示测试集的样本数。
2 提出的CVCNN压缩反馈算法
目前大多数用于深度学习的体系结构以及算法都是基于实值表示的,然而对于无线通信领域采用的OFDM调制信号来说,这会带来I/Q 信号分解的问题。受复卷积和复数批量归一化算法[18]的启发,提出了采用复数网络的CVCNN 算法对高维I/Q 信号直接进行操作,避免信号分解带来的信息损失问题。
2.1 复数卷积神经网络
由于CVCNN 算法中采用的是三维复数卷积核,为了更好地理解三维复数卷积,参考Trabelsi[18]等人的相关工作,简要介绍二维复数卷积操作。
为了在复数域中实现与传统实值二维卷积等价,Trabelsi等人将复数滤波器矩阵W=A+iB与复数向量h=x+iy卷积,其中A和B是实数矩阵,x和y是实数向量。卷积可得:

为了更加直观地体现二维复数卷积操作,复数卷积过程示意图如图2 所示:
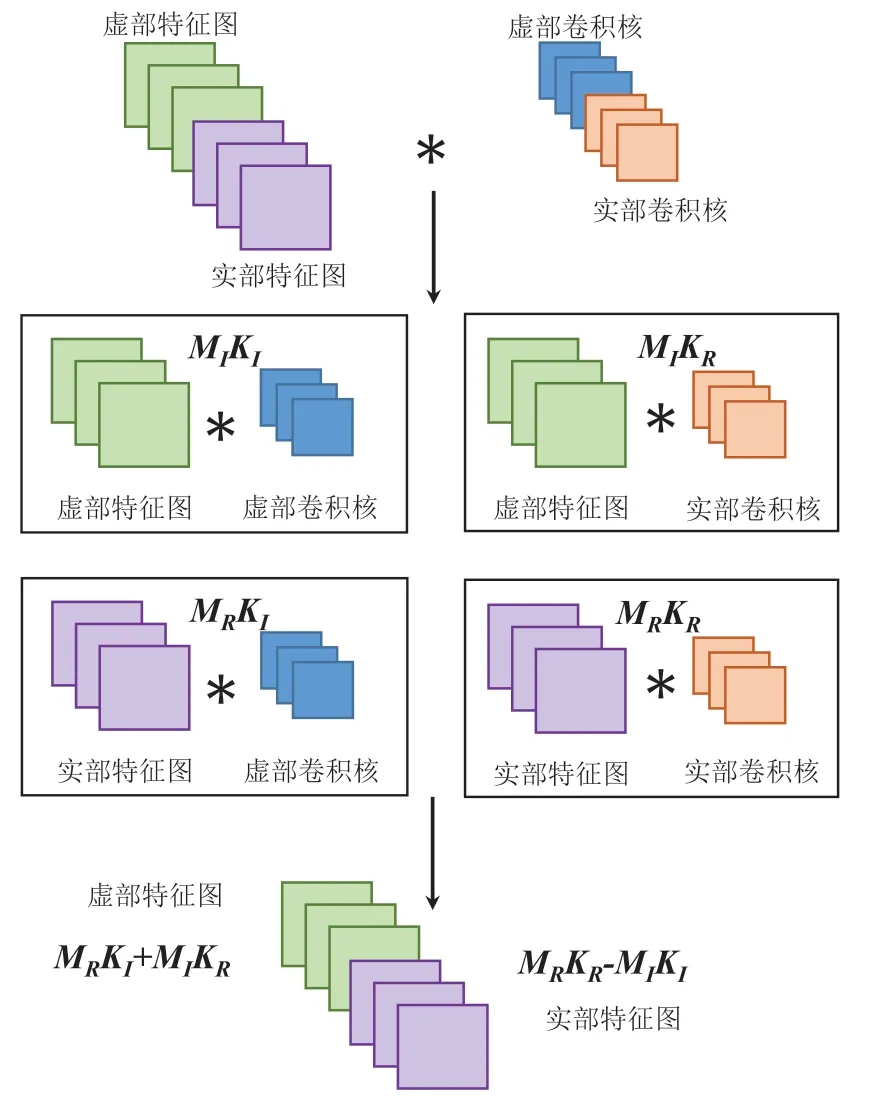
图2 二维复数卷积过程示意图
在二维复卷积操作的基础上,Trabelsi 等人提出了一种基于二维矢量白化的方案以实现复数BN(Batch Normalization,批量归一化),加快网络的训练速度。
2.2 残差网络
K He[19]等人指出,可以通过在原有的模型中加入残差网络,以此缓解在深度神经网络中增加深度带来的梯度消失问题。残差网络由于普适性较好,本文将其沿用于CVCNN 架构,用于提升译码的准确度。
残差网络通过反向传播来自任务特定损失函数的误差来训练该残差块的参数。为此,CVCNN 对复数输入执行Conv→BN→激活函数操作,然后将其反馈到第一个残差块。将最后一个残差块的输出与其上卷积的输出连接在一起,作为残差深度神经网络的输出,以此提升译码准确度。具体的残差网络结构如图3 所示:

图3 残差网络结构示意图
在CVCNN 架构中加入了残差网络模块,有效控制了网络退化的问题,提升了网络的表现。
2.3 CVCNN压缩反馈架构
为了降低反馈开销,传统的基准算法CsiNet 及其改进型在压缩和解压缩过程中采用FC(Fully Connected Layer,全连接层),然而,在使用FC 将高维矩阵降维至一维时,会增加不必要的计算开销。因此,基于复数神经网络和残差网络,提出了CVCNN 压缩反馈架构。CVCNN创新性地使用复卷积层和反卷积层来进行压缩与恢复所估计的下行CSI 测量值。具体来说,即在编码器中使用复卷积层将高维的下行CSI 矩阵压缩成低维的码字,在译码器中使用反卷积层解压缩码字,恢复出高维的下行CSI。
在所提出的CVCNN 架构中,压缩模块和解压缩模块分别采用一个复卷积层和一个反卷积层来控制CR(Compression Ratio,压缩率),即当步长设置为(2,2,2)时,CR=1/8,此时压缩模块的输入和输出的形状分别为(Nc,No,Nt,Nr,2)和(Nc/2,No/2,Nt×Nr/2,2)。具体的CVCNN 架构如图4 所示。
CVCNN 通过加深网络来提高网络的学习能力,其中,特征提取模块中每个卷积层滤波器的个数为8-16-32-16-8-1。由于在复卷积层中,滤波器会以2 倍的系数进行运算,故最后一个复卷积层中滤波器个数设置为1,以此保证输出数据维度不变。与此同时,在每一个复卷积层和反卷积层后使用复数BN层和LeakyReLU,分别用于防止过拟合和避免梯度消失。
综上所述,可以用算法流程图来表示整个CVCNN的相关架构。

图4 CVCNN压缩反馈架构图

3 仿真实验与结果
将所提出的CVCNN 压缩反馈算法与传统的基准算法CsiNet 进行仿真对比,该比较基于相同的数据集与参数设置。
3.1 数据集生成与参数设置
数据集使用Matlab 5G 工具箱进行生成,遵循3GPP TR 38.901 协议标准中的CDL 模型。本数据集采用CDL-A 信道模型,且上行和下行链路的载波频率分别设置为2.0 GHz 和2.1 GHz,载波间隔分别设置为15 kHz和30 kHz。在BS 端使用带有32 根发射天线的均匀线阵,在UE 端使用2 根接收天线。由于在5G NR 中,资源块被定义为12 个连续的子载波,在进行数据集生成时资源块数设置为6,故子载波数为72。OFDM 符号数设置为14,其余的参数设置均是3GPP TR 38.901 协议标准的默认设置。因此,可以生成所需的下行链路CSI 矩阵H0∈C72×14×32×2×2。经过数据预处理后,输入神经网络的下行链路CSI 矩阵变为H∈C72×14×(32×2)×2。
CVCNN 与CsiNet 的参数设置一致,具体设置如表1 所示:

表1 CVCNN参数设置
3.2 性能评估
(1)计算复杂度
通常一个神经网络模型的复杂度可以用2 个指标来描述,分别是模型的参数量和模型的计算量,其中,模型的计算量可以通过浮点运算数FLOPs来衡量。整个神经网络的FLOPs可计算如下:
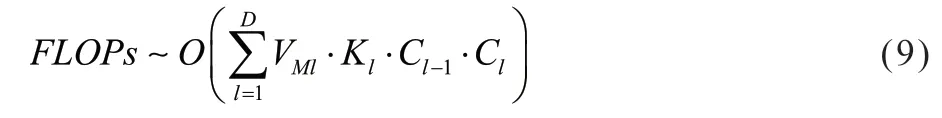
其中,D表示该神经网络的层数,VMl表示某一层输出特性图的大小,Kl表示某一层卷积核的大小,Cl-1和Ci分别表示某一层的输入和输出通道数。根据上述公式和仿真结果,将所提出的CVCNN 和基准算法CsiNet 分别进行了参数量和计算量的比较,比较结果如表2 和表3 所示:
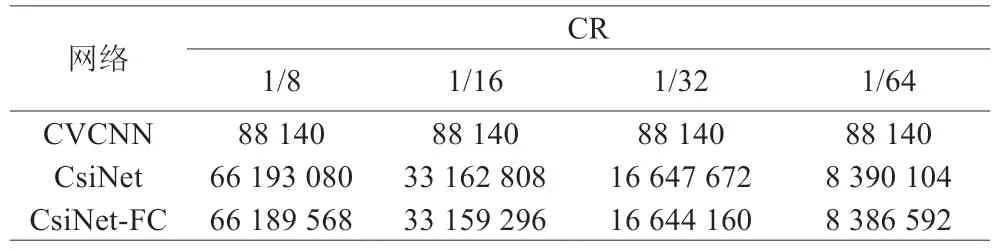
表2 CVCNN与CsiNet模型参数量比较
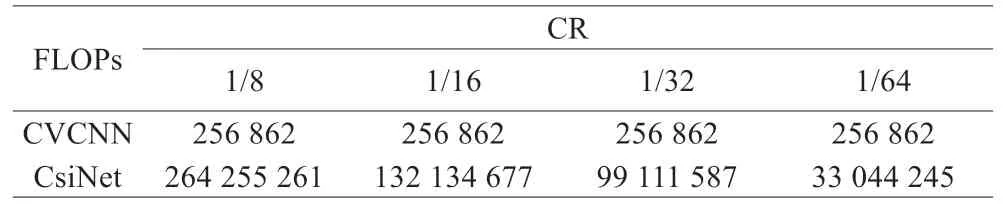
表3 CVCNN与CsiNet模型计算量比较
通过表2 可以发现,基准算法CsiNet 中FC 的参数量几乎占据了全部参数量的99.9%。而本文所提出的CVCNN 算法则由于采用的复数全卷积结构,避免使用FC 层造成参数量过大,使得参数量相较于CsiNet 有了显著的降低。与此同时,比较参数量结果还可以看出,CsiNet 完全依靠FC 层进行压缩,故CR=1/8 时参数量近乎是CR=1/16 时参数量的2 倍,其余压缩比情况均类似。而所提出的CVCNN 有效避免了FC 层的缺陷,通过卷积层压缩成低维码字。在CR 改变的情况下,整体网络的结构不发生变化,仅仅数据维度产生了改变,使得参数量很好地稳定在一个较少的水平。
由表3 可以得出,采用复数全卷积神经网络的CVCNN 在计算量上相较于CsiNet 也有了很大的提升。当CR=1/8 时,参数量降低了750 倍,计算量降低了1 028 倍,大大降低了网络的存储和计算开销。
(2)重构性能
将所提出的CVCNN 复数网络与基准算法CsiNet 实数网络对于下行链路CSI 的重构性能进行了比较,性能比较结果如表4 所示:

表4 CVCNN与CsiNet重构性能比较
为了更加直观地体现CVCNN 与CsiNet 在不同CR情况下的重构性能,根据表4 的仿真实验结果在Matlab中绘制了NMSE 对比表,具体的趋势如图5 所示:
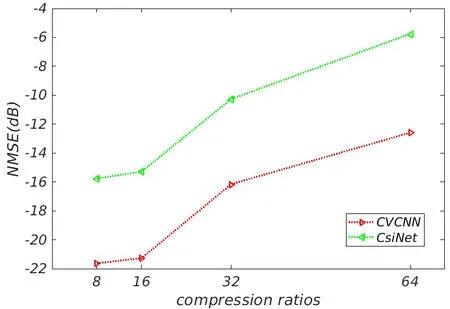
图5 CVCNN与CsiNet在不同压缩比情况下的NMSE对比图
由于本文进行对比实验时选取的是经典的CsiNet,该网络同时也是一个实数网络,可以很好地与所提出的CVCNN 复数网络进行比较。分析图5 可以发现,在不同CR 的情况下,CVCNN 下行链路CSI 的重构精度明显优于基准算法CsiNet,特别是在较小CR 的情况下。与CsiNet 经典实数模型相比,CVCNN 复数模型在重构精度上实现了近6 dB 的增益,证明了复数模型的优越性。然而,通过重构性能可以发现,在CR=1/8 和CR=1/16 的情况下,比较结果差距很小。经过进一步的分析,猜想到可能的情况为:数据维度较大,在进行较小CR 仿真实验时造成结果相差不大,通过CR=1/32 和CR=1/64 的仿真结果验证后,证明了该猜想的可能性。
4 结束语
本文针对传统的实数CSI 反馈算法的弊端,提出了CVCNN 压缩反馈算法,就重建性能、存储和计算开销等方面将CVCNN 与基准算法CsiNet 进行了详细对比。实验结果表明,在计算复杂度方面,CVCNN 算法采用的全卷积层相较于CsiNet 采用的FC 层实现了参数量和计算量的显著降低;在重构性能方面,CVCNN 的复数架构相较于CsiNet 的实数架构也有了近6 dB 的性能增益。CVCNN 算法通过高维复数卷积运算,有效避免了I/Q 样本复值分解的问题,在不损失信息的情况下进一步进行复数域的压缩与反馈,提升了下行CSI 的重构精度。
