基于Scrapy的开源核情报采集系统构建
2022-08-10胡家全
黄 禹 兰 洋 张 玥 胡家全 黄 粲
(中国核动力研究设计院,四川 成都 610000)
0 引言
二十一世纪以来,突飞猛进的网络化、信息化、数字化进程,使得社会知识传播方式发生了巨大变革。互联网因其多样性、及时性和共享性的特点,已经成为人们获取信息的重要载体,渗透到政治、经济、科研、生活的方方面面。随之而来的就是大数据时代下海量数据的激增,网络资源变得多元化,人们面对纷繁多扰的信息资源时,反而陷入了“信息迷航”“信息过载”的困境,而在针对具体领域开源情报(Open Source Intelligence,简称OSINT)的获取方面尤为如此。基于此,不同于通用搜索引擎的基于主题的采集技术应运而生,该技术是传统搜索引擎的延伸和发展,专注于某一行业或某一领域的信息资源的获取,具有“专、精、深”的特点,在各领域开源情报获取方面得到广泛应用。基于此,本文利用Scrapy技术构建开源核情报采集系统,旨在提升对开源核情报的搜集效率。
1 基于主题的数据采集技术在开源情报获取方面研究现状及相关技术介绍
1.1 国内外研究现状
基于主题的数据采集技术作为目前主流的开源情报获取方式,在各领域的数据采集中得到广泛的应用,周昆团队构建党建采集主题用以采集互联网中的党建领域页面内容;屈莉莉等人基于WebMagic框架搭建职位主题用以实现对招聘网站职位需求变化的持续监测;刘灿等人为满足对教育类新闻关注的实际需求,提出了一种面向教育新闻的采集系统;黄炜团队提出了一种针对网络恐怖信息的主题信息采集系统,以实现提升开源网络采集网络恐怖信息效率的目的;郭颂等人为准确高效采集航天领域内的竞争情报,设计了一款新的航天领域情报采集的总体框架,实现了航天领域情报的高效采集。
相较于国内,国外对基于主题的数据采集技术的应用起步更早,并且将机器学习等先进算法应用到采集程序中,实现对采集效率的提升。近五年来,Shiqi Deng针对矿产开源情报领域的特点,提出了一种基于文本语义相似度与网页URL结构结合的主题采集策略,从而较高地提高了互联网上矿产开源情报的获取效率;Sumita Gupta等人在主题中融入元数据标准,用以优化数字图书馆搜索引擎,提升检索结果的匹配度;Aamir Khan与Dilip Kumar Sharma在社交网站中集成本体的概念,使得社交网站的搜索功能成为更加精准的基于用户信息主题的采集程序,提升了对具体用户信息的查询。
综上,基于主题的数据采集技术在互联网信息的采集中应用广泛,是当前缓解“信息迷航”,提升开源情报精准获取的必要手段。
1.2 相关技术介绍
1.2.1 Scrapy框架
Scrapy是一个能够快速搭建部署的基于Python语言的基于主题的采集技术运用框架,该框架基于Twisted异步网络库处理网络通信,具有模块化、定制化、易拓展等点,同时该框架支持采集进程的并行采集和分布式采集,极大地提高了数据采集的效率。Scrapy框架结构如图1所示。

图1 Scrapy框架
Scrapy框架主要包含以下五个模块:
(1)引擎模块Engine:负责整体的数据协调以及各模块之间的数据流动。
(2)调度器模块Scheduler:负责接收Engine的请求,并将请求加入队列,实际上是对目标URL进行管理。
(3)下载器模块Downloader:负责下载Web页面的相关数据,并将这些数据发送给Engine。之后Engine将数据传给Spider,目的是使Spider的函数对数据进行分析。
(4)采集模块Spider:用户自定义的程序,负责分析回应和获得数据,或者跟踪深层次的URL。
(5)数据流水线模块ItemPipeline:负责对获得的数据进行后续数据处理。处理方式包括:数据冗余消除、数据合法化、数据存储。
(6)中间件模块Middlewares:由下载中间件和采集中间件组成,是各组件之间的桥梁。
1.2.2 Xpath技术
Xpath是一门在XML文档中查找信息的路径语言。用以对XML文档中的元素和属性进行遍历,并确定数据的位置。Xpath基于XML树状结构,因此能够方便地查询树状结构的节点,在基于主题的数据采集行为中常用作查询语言用以提取网页结构中所需的数据信息。
常用的Xpath路径表达式如表1所示。
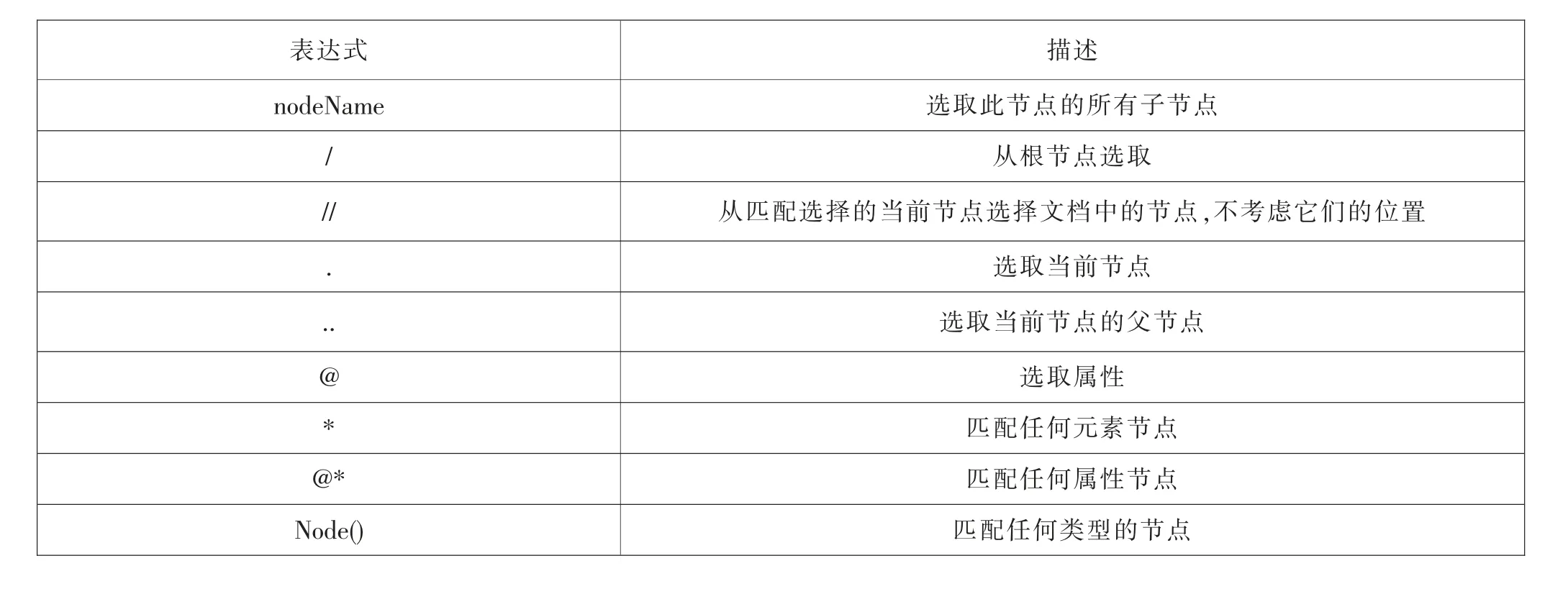
表1 Xpath路径表达式
2 基于Scrapy的开源核情报采集系统需求分析与概要设计
2.1 系统功能需求分析
面对海量的互联网网页数据时,仅利用通过搜索引擎(如百度、谷歌、必应等)对国外开源核情报进行检索,会返回大量的检索结果,由于商业竞价、SEO优化等因素的影响,排序靠前的匹配结果可能并不是人们所期望的内容,并且会包含大量与专业领域无关的网页。基于传统搜索引擎在专业开源情报获取方面的局限,本文的开源核情报采集系统利用Python语言基于Scrapy框架进行定制开发,实现对目标站点下信息资源的发现、采集、解析与存储。下面就开源核情报采集系统的功能需求进行简要介绍:
(1)成功请求响应。设计的基于主题的开源情报采集程序能够在对目标站点发起请求后,从目标站点成功获取响应数据。
(2)完成网页文本内容解析与提取。系统页面解析模块能够从网络页面中成功解析到需要提取的数据字段。
(3)数据分类存储。系统存储模块能够根据针对数据按照其结构化和非结构化特性进行分类后在进行存储。
(4)用户界面。用户能够通过一个可视化的系统界面实现对各采集程序的开启与关闭等相关操作。
2.2 系统基本结构
本文所构建的开源核情报采集系统,整体采用C/S架构,通过前端页面完成与用户的交互,后端服务器提供后台的业务逻辑处理,使用Mysql数据库对采集的网页信息进行存储。主要分为页面请求模块、情报解析模块、情报存储子模块以及用户界面模块。系统结构如图2所示。
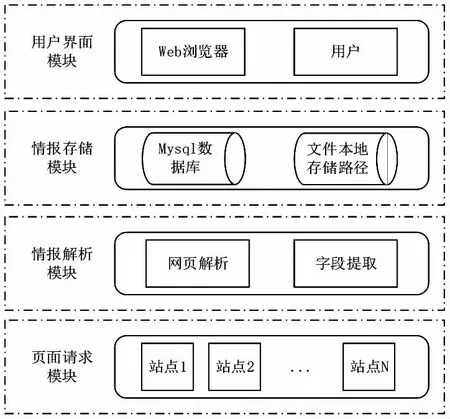
图2 系统基本结构
由图2可得,本系统页面请求模块主要实现通过网络采集程序对站点集群内的所有站点的URL发起网络请求,从而获取到数据的响应;情报解析模块主要包括网页解析以及字段提取,从而实现对目标网页内所需内容的解析与采集提取;情报存储模块包括Mysql数据库和本地文件存储路径,用于对采集结果保存和文本附件的存储;用户界面模块为一个可视化的交互界面,由Web浏览器和用户共同构成,用户通过浏览器打开本系统的前端页面实现交互操作,通过封装好的接口连接到后端,实现对用户在前端操作的响应。
3 基于Scrapy的开源核情报采集系统详细设计与实现
本文基于Scrapy的开源核情报采集系统的设计与实现过程中所采用的开发以及测试环境为Windows 10操作系统,开发工具为Pycharm,使用Python为系统主要开发语言,使用的开发框架为Scrapy框架,前端页面使用JavaScript与HTML,存储数据库为Mysql数据库。前后端的通信遵循Http/Https协议。
3.1 页面请求模块
本系统所构建的页面请求模块,通过对站点集群内的所有站点URL发起网络请求,采取深度优先的采集策略,使得数据采集程序采集流程从一个站点初始化种子URL出发,发起网络请求,尽可能在目录页URL中提取到最多的详情页URL。在响应的页面中提取新的URL链接添加到待采集的URL列表中,循环往复直至获取到所有符合条件的URL,同时,将成功获取到响应的页面信息传入至情报解析模块中。本模块的网络请求流程如图3所示,具体的流程步骤如下:

图3 页面请求流程
(1)步骤1:在一个站点内选取一个URL链接作为数据采集程序的初始化种子URL,该URL可为网站一级URL,也可为下一级版块URL。由于本文采用深度优先采集策略,优先选择网站二级版块URL作为初始化种子URL。
(2)步骤2:采集程序开始执行对URL的请求,获取对应的响应信息。
(3)步骤3:采集程序对URL响应的页面进行采集。
(4)步骤4:提取网页上的所有URL链接,获取页面下新的URL链接。
(5)步骤5:判断获取的URL链接是否符合所需采集URL条件,若满足条件,则将新的URL放入待采集URL队列,继续执行URL的请求,同时将该URL的响应内容传入情报解析模块。若不满足条件,则结束页面请求流程。
本文在测试阶段所构建的网站集群包含站点如表2所示。

表2 采集站点列表
3.2 情报解析模块
本系统所构建的情报解析模块主要功能为对采集程序请求到的网络页面进行解析以及对需要获取的字段进行提取。由于每个站点的页面结构不同,数据的渲染方式各异,因此在设计和编写解析规则时需要具体站点具体分析,根据每个站点的结构特征来设计合适的解析规则,这也是在系统构建中最费时的地方。本文以世界防务关键词匹配采集任务为例,阐述页面的解析与字段的提取。
世界防务网站的采集策略为通过关键词构建用于检索的URL,对该URL发起请求从而获取检索结果的响应结果,再从检索结果页面出发,提取检索结果的URL进行更深一层详情页面的请求,最终获得详情页面的响应结果进行解析和字段提取。
3.2.1 页面分析与解析
通过对世界防务网的URL进行访问请求后,获得检索页面的响应结果,利用Xpath从页面响应的源码中解析出各条检索结果的详情页URL,进而能够对详情页面发起请求,从而最终从详情页解析到需要的字段。检索界面的响应结果和详情页面如图4、图5所示。

图4 世界防务检索结果页面展示
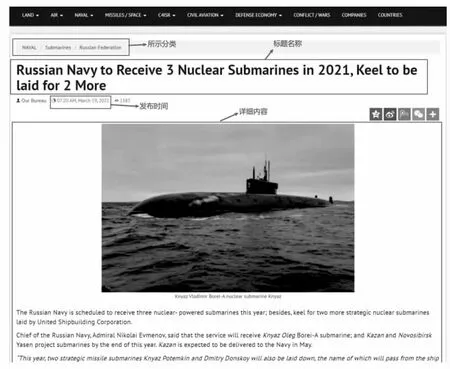
图5 世界防务详情页面展示
实现上述解析提取的关键代码如下:

3.2.2 解析字段设计
以世界防务网站中的开源情报为抓取目标,在对页面结构进行分析后,需要从中解析出的字段如表3所示。
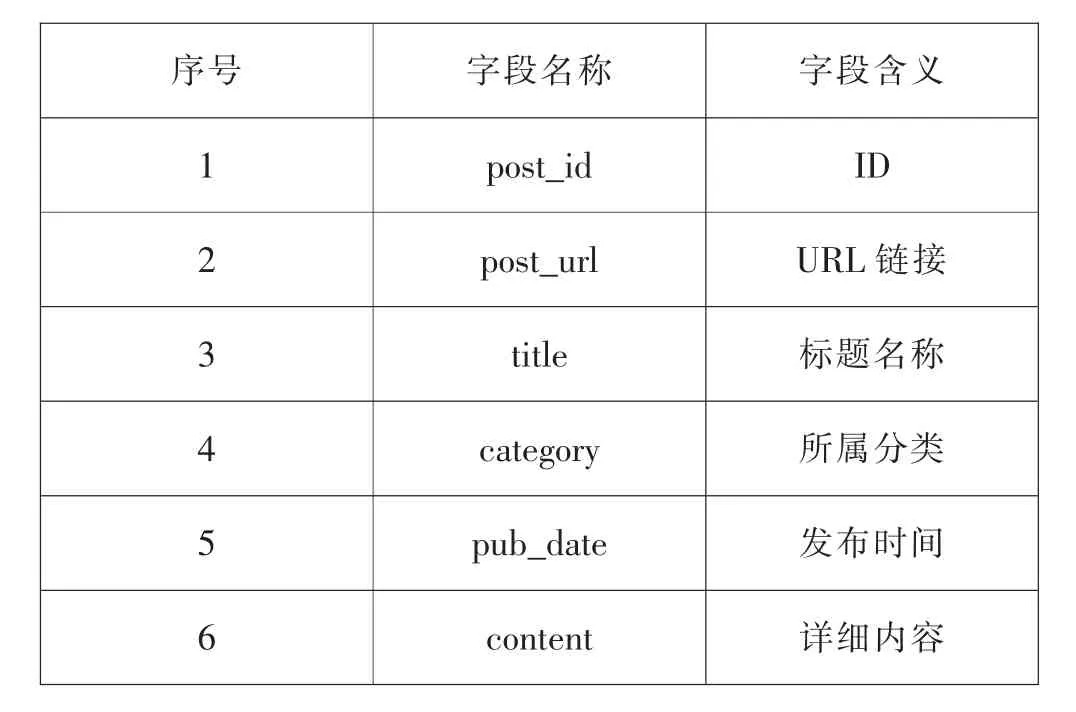
表3 世界防务开源情报ITEM构成表
其中,post_id为某条信息在世界防务网站中的唯一标识ID,post_url为该条信息的访问URL链接,title为该信息的标题名称,category为该信息在世界防务所属的分类信息,pub_date为该信息的发布时间,content为该信息正文详细内容。
3.3 情报存储模块
基于Scrapy框架开发的开源核情报采集程序,在对页面的字段进行解析提取后,会转入框架的PipeLine中进行下载和存储,在世界防务案例中,仅能采集到以标题、URL、详情内容等类的文本类字符串数据,因此在设计存储业务逻辑时,将解析提取的字段存入本地Mysql数据库的对应表中,并将该信息的详细内容转换为pdf文档格式进行本地化存储,以便阅读与使用。
以世界防务为例,设计的数据库存储表结构如表4所示。

表4 数据库中世界防务信息存储表属性
对于该表,前六个字段用于存储从页面中解析出来的字段,crawl_time属性用于存储信息采集入库的时间,file_path用于存储详情内容转换为pdf文件后的本地存储位置的路径信息。
本系统测试环节共从世界防务网站采集到包含“Nuclear”关键词的数据1 188条,耗时6分钟,采集后存储至本地Mysql数据库的数据如图6所示。

图6 世界防务采集数据存储结果
3.4 用户界面模块
本文基于Scrapy的开源核情报采集系统实现对站点集群内站点的核开源情报的采集,但在数据采集程序执行的过程中难免会因为各种问题造成执行的中断,因此需要实现对数据采集程序运行状态的实时监测,使得用户通过可视化界面的方式对采集程序运行状态的直观监测。基于此,本系统基于ScrapydWeb框架完成相关编码工作,实现通过用户界面对采集程序运行状态的监测。
4 结语
为了提升对核开源情报的搜集效率,本文基于Scrapy技术构建了开源核情报采集系统。该系统具有页面请求模块、情报解析模块、情报存储模块以及用户界面模块,在测试阶段实现了对国际原子能机构、世界核新闻网、动力工程、世界防务以及中国核网这5个网站特定版块的数据采集,采集数据完整,采集效率较高。在接下来的实验与研究中,本系统还需要拓展对更多核开源情报网站的采集,并且不断完善本系统功能,集成数据预处理、数据挖掘以及数据可视化等更多功能。
