动车组PHM模型数据处理架构优化及关键技术研究
2022-08-08李超旭乔成珍
李超旭,王 辉,李 燕,乔成珍
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
故障预测与健康管理(PHM,Prognostics and Health Management)技术诞生之初是为了提高航空飞行器的运营维护(简称:运维)效率,保障飞行设备的运行安全,通过基于状态修的维修方式,降低故障率与运维成本[1-2]。随着PHM技术的不断发展,其技术理念与应用效果,得到了众多行业的关注。近年来,轨道交通领域的PHM和大数据技术研究与应用的热度持续上升[3-5],随着修程修制改革、状态修、智能运维等动车组运维目标的设立[6],中国国家铁路集团有限公司(简称:国铁集团)从2018年开始开展动车组PHM技术研究工作,已取得一定的进展,设计了一套可应用于全国铁路范围的开放式动车组PHM系统方案,搭建了动车组PHM系统,并与各铁路局集团公司开展了试用联调工作,相关功能研究工作也在稳步进行[7]。
动车组PHM模型是指利用新造、运用、检修、环境等相关数据,借助算法对动车组系统或其部件进行故障预测、故障诊断、健康评估及运维决策的逻辑组合[8]。动车组PHM模型是动车组PHM的研究重点,是动车组PHM系统实现故障预测与健康管理功能的关键。PHM模型的设计与应用,可为提升动车组智能运维水平、提高检修效率、实现修程修制改革提供技术支撑。
1 动车组PHM模型应用现状分析
截至2021年11月,国铁集团研发的动车组PHM系统中已上线部署百余个阈值类PHM模型,适配车型10余种。现场联调测试结果表明,这些模型的投入使用减少了动车组运维单位的工作量,有效指导了动车组部件的精准维修,可做到及时预防行车过程中的安全隐患,保障运输安全,同时为延长修提供监测支持。由于动车组PHM技术的研究内容较为宽泛,且全国铁路范围的动车组PHM技术研究处于早期发展阶段,诸多关键技术尚未解决。PHM模型作为动车组PHM技术的重点研究内容,面临着数据处理和应用等方面的难题。
动车组PHM系统现有的模型数据处理流程如图1所示,动车组运行监测数据通过动车组车载信息无线传输系统(WTDS ,Wireless Transmission Device System)传输至中国铁路主数据中心(简称:主数据中心)后,由主数据中心将车载运行监测数据转发至动车组PHM系统所属的消息队列中,再由PHM模型对实时数据进行分析处理。该处理流程与机制可基本满足实时环境下PHM模型计算所需的条件,但存在较大的局限性,例如,不能较好进行高并发情况下的模型快速响应、存在一定的数据存储冗余等问题。且该架构只适用于实时数据处理,对批处理模型与多源模型的数据需求缺乏一定的考虑,在一定程度上限制了系统支持的模型种类。
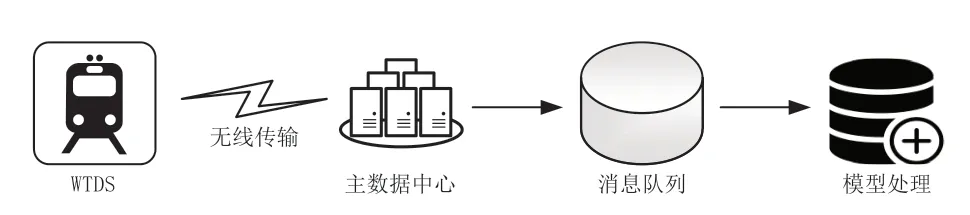
图1 既有动车组PHM模型数据处理流程
为满足PHM模型计算对WTDS实时数据与历史数据的需求,提升数据处理效率,提高数据可用性,在遵循动车组PHM总体技术架构规划下,本文提出优化的动车组PHM模型数据处理架构。
2 动车组PHM模型数据处理架构优化设计
2.1 总体架构优化设计
优化的动车组PHM模型数据处理总体架构在既有的模型数据处理流程基础上,引入动车组运维信息系统的数据作为新的数据源,满足模型对多种类源数据的需求;同时,针对WTDS实时数据,设计了分布式存储、消息队列、缓存3种数据持久化方式,满足模型对实时数据和历史数据的处理需求,提高数据处理效率,总体架构如图2所示。
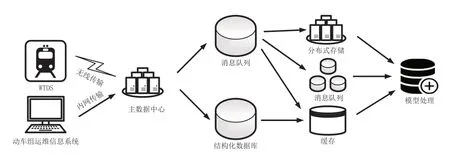
图2 优化的动车组PHM模型数据处理总体架构
2.2 技术架构优化设计
优化的动车组PHM模型数据处理技术架构如图3所示,共分为4层,分别为源数据层、数据汇集层、数据处理层、数据汇总层。
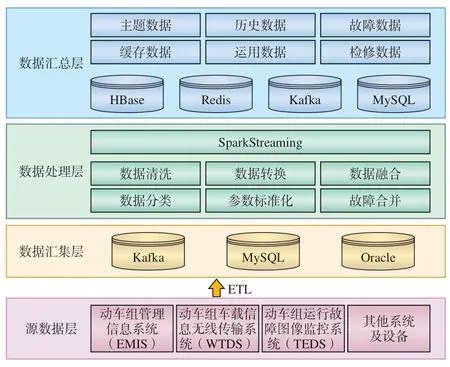
图3 优化的动车组PHM模型数据处理技术架构
(1)源数据层。包含动车组PHM模型运行所需的数据,来自动车组运用检修、行车安全检测等相关的信息系统及相关作业设备。
(2)数据汇集层。主要负责源数据的抽取、汇集工作,根据数据结构特点及业务需求,选择适合的数据ETL(Extract-Transform-Load)方法进行数据抽取,汇集源数据层的数据并持久化,供数据处理层使用。
(3)数据处理层。主要负责对汇集的数据进行清洗、转换、融合与分类,借助SparkStreaming实现数据去重、噪点数据过滤、数据标准化、故障合并等处理步骤,将数据加工成可被动车组PHM模型直接利用的数据格式。
(4)数据汇总层。包含数据处理层处理后的数据,根据数据结构及类型对数据进行划分,并持久化到不同的数据库中,供模型程序调用。该层数据根据业务划分后主要包括主题数据、WTDS历史数据、动车组运用、故障和检修数据及相关业务缓存数据。
3 关键技术
3.1 数据处理
目前,PHM模型的应用大部分基于对WTDS实时数据的处理,以达到实时故障预测或提供维修处理建议的目的。在不考虑模型逻辑的前提下,WTDS数据质量对模型应用效果有较大影响。
WTDS数据可实时刻画列车在运行过程中各部件、系统的状态参数[9],包含车组故障信息、运行状态、地理位置信息等。对WTDS运行状态参数数据可进行如下抽象。
假设某一时刻某列动车组的WTDS数据集为R;车厢号为n,编组长度为l,n=1,···,l;运行状态参数为c,集合为C,参数集合数量为m。该车组第n个车厢,第i个时刻的 WTDS数据集合为
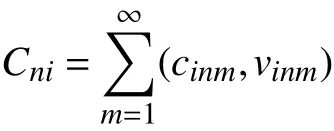
其中,cinm为第i个时刻接收到的第n节车厢的第m个参数;vinm为cinm对 应的参数值。令则有,WTDS数据集R为
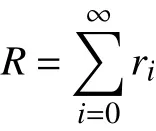
当前,WTDS数据治理工作尚未全面开展,存在一定的数据质量问题,因此模型计算前的数据处理十分必要[10]。
3.1.1 数据清洗
数据清洗是数据处理过程中的必要环节,通过数据清洗可纠正源数据的各类数据问题,提高数据质量,保障模型输出的准确度。结合运用经验,WTDS数据主要存在以下2类问题。
(1)重复数据
数据重复是一种常见的WTDS数据质量问题,具体表现形式可描述为:在第i个时刻,接收到同一列车的数据中存在多个相同的参数集合(cinm,vinm)。该类数据问题会影响模型的计算效率,增加数据处理负担,降低模型准确率。对此类问题,可将数据抽取到数据汇集层后再进行去重处理。结合WTDS数据特点,单条WTDS数据内去重可采用Hash算法,剔除数据内的重复参数数据;对不同时序上的WTDS数据间去重,可采用Simhash算法,利用“分词—Hash—加权—合并—降维”处理步骤得到1条WTDS数据的Simhash签名,通过计算不同WTDS数据Simhash签名间的汉明距离(Hamming Distance),判断数据间的相似度,达到去重的目的。
(2)无效数据
无效的WTDS数据主要有噪点数据和干扰数据2种表现形式。噪点数据主要表现为某一时刻接收到的WTDS参数值较该条数据前后时刻的数据参数值变化率超出了正常的数值波动范围。例如:在某一时间序列上的前后2包数据内的轴温参数值由50℃跳变为300℃。干扰数据则表现为同一部件、相同位置的运行参数,在同一时间戳i上,存在两个不同的参数值,即存在多个不同的vinm与同一cinm对应。噪点数据与干扰数据都会对模型逻辑处理产生严重干扰,影响模型结果准确性,2类数据清洗工作的开展需要结合业务经验,针对数据使用场景,研究数据清洗的方式方法,例如,对跳变类的噪点数据可通过对比前后2包数据的最大数值差实现跳变数据的基本过滤;对多值类的干扰数据可结合WTD设备的数据传输策略制定数据清洗方法。对作为实时计算模型的源数据,选取的数据处理算法应高效、快速,最小限度地降低数据时效性损失,保障模型输出的及时性。
3.1.2 参数标准化
WTDS数据落地时需要利用解析协议对数据进行解码,明确每个车载参数代码所代表的参数含义。由于解析协议来源于各主机厂,协议规范尚未统一,不同车型对应的数据解析协议也有差异,存在代表相同含义的参数因解析协议不同而编码不同的情况。因此,需根据WTDS参数的含义与类型,将WTDS数据进行标准化转换,形成统一规范的数据编码格式,从而提高模型程序构建效率,降低维护成本。
3.2 数据存储
动车组PHM模型种类多样,适用范围覆盖动车组运维过程的多个阶段,模型的输入数据源包含多个动车组运维类信息系统,数据特点呈现多样性和异构性。按照数据结构分类,常用的模型输入数据源可分为以动车组管理信息系统(EMIS,EMU Management Information System)数据为代表的结构化数据和以WTDS数据为代表的非结构化数据。考虑到数据结构的差异性与模型计算所需的数据条件,模型接入的源数据的存储与获取方式选择尤为重要。
3.2.1 实时数据
WTDS数据是实时计算模型的主要实时数据源,为满足实时计算模型低时延、高时效的特定需求,可采用Kafka消息队列做为WTDS实时数据的持久化方式,将原始数据与清洗后的数据均存放至Kafka集群,用于实时计算模型消费。由于车组运行过程中,车地数据传输可能会存在一定的信号波动,导致数据落地时序乱序。因此,为最大限度地保障模型输入数据的时序性,原始的WTDS实时数据落地Kafka时可采用轮询的方式写入。对于清洗后的WTDS数据,将数据的车组信息作为该条数据的key写回Kafka,保证同一车组的数据保存在同一分区下,使得模型在实时消费WTDS数据时,可在一定程度上保证数据的时序性。
3.2.2 历史数据
WTDS数据需长期持久化,以满足批处理类模型及上层应用的数据需求。选用HBase存储WTDS历史数据,既可满足大体量数据的分布式存储,又可实现查询的快速响应。由于WTDS历史数据体量较大,且存储周期较长,需考虑数据倾斜问题,避免产生数据热点,造成集群节点性能下降。上述问题可通过采用设置预分区、结合数据特点为行键(Rowkey)添加散列值等方法解决。
3.3 数据缓存
模型计算过程中产生的中间结果需临时存储,供下一步计算时调用。同时,为提高模型的计算效率,可将计算过程中需频繁查询的结构化数据提前抽取到缓存区中,供程序调用。结合模型计算特点及运行环境情况,本文采用公共缓存和特定缓存两种缓存机制,设计了模型数据处理架构的缓存区及其部署架构,如图4、图5所示。
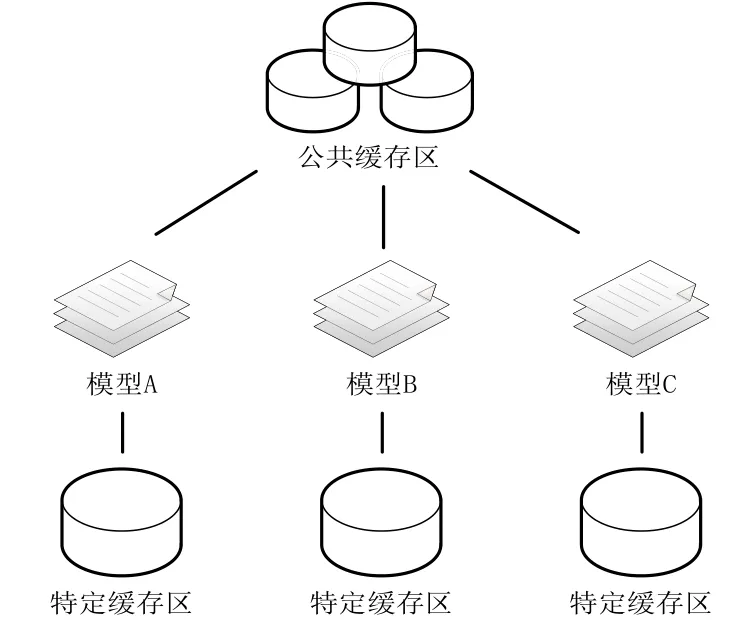
图4 缓存区设计示意
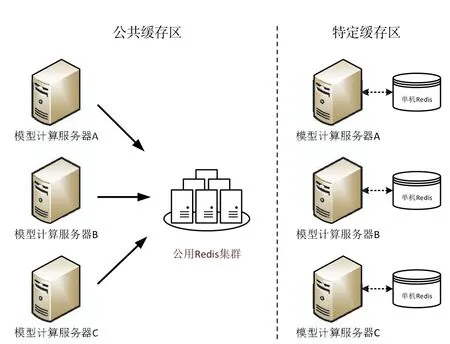
图5 缓存区部署架构
3.3.1 公共缓存区
公共缓存区由多台Redis服务器搭建成Redis集群,用于存储具有同类计算逻辑的中间结果数据和从其他系统中抽取的结构化数据,该缓存区的数据可被全部模型程序共享,且该区内缓存数据由独立的程序负责维护和管理。通过设立公共缓存区,可减少同类计算逻辑的重复计算与跨系统的数据交互,提高模型程序的运算效率。
3.3.2 特定缓存区
特定缓存区用于存储公共缓存区以外的具有特定模型计算需求的中间数据。同时,为提高缓存的读写效率,减少由于集群内网络波动导致的缓存交互时延,特定缓存区需架设在模型计算服务器中。特定缓存区内的缓存数据只可被该节点内的模型共享,其他服务器节点运行的模型程序不可访问,且缓存数据的维护与管理也只由该节点上的模型程序负责。
4 应用实例
WTDS数据的转发与解析是WTDS数据处理的重要环节,动车组实时回传的报文数据需要即时解析并传输给PHM模型的输入数据节点及其他有WTDS数据需求的系统,因此,WTDS实时数据抽取的效率是保障PHM系统及模型实时性预警的关键。据统计,当前WTDS解析前数据单通道传输量平均约为14 100条/min,解析后数据单通道传输量平均约为97 020条/min。在测试环境下(测试环境配置如表1所示),采用本文优化的PHM模型数据处理架构,在数据抽取方面实现了单通道29 700条/min解析前数据抽取和119 600条/min解析后数据抽取,如图6所示。在数据处理方面实现了平均2 561条/s的数据解析、清洗与存储,如图7所示。实验结果表明,该数据处理架构的性能可满足WTDS数据处理需求。
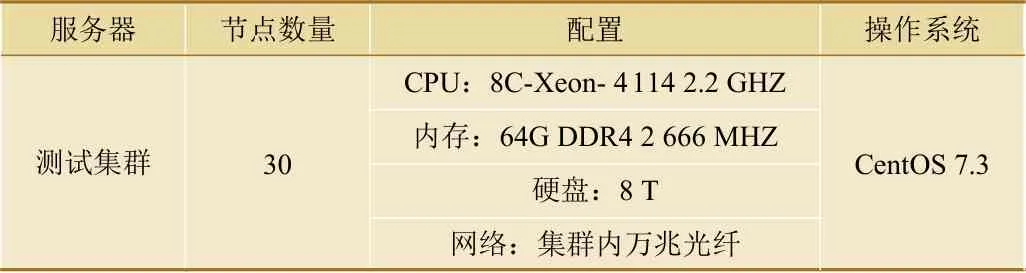
表1 实验环境配置
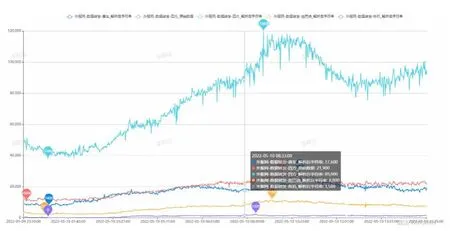
图6 抽取WTDS数据
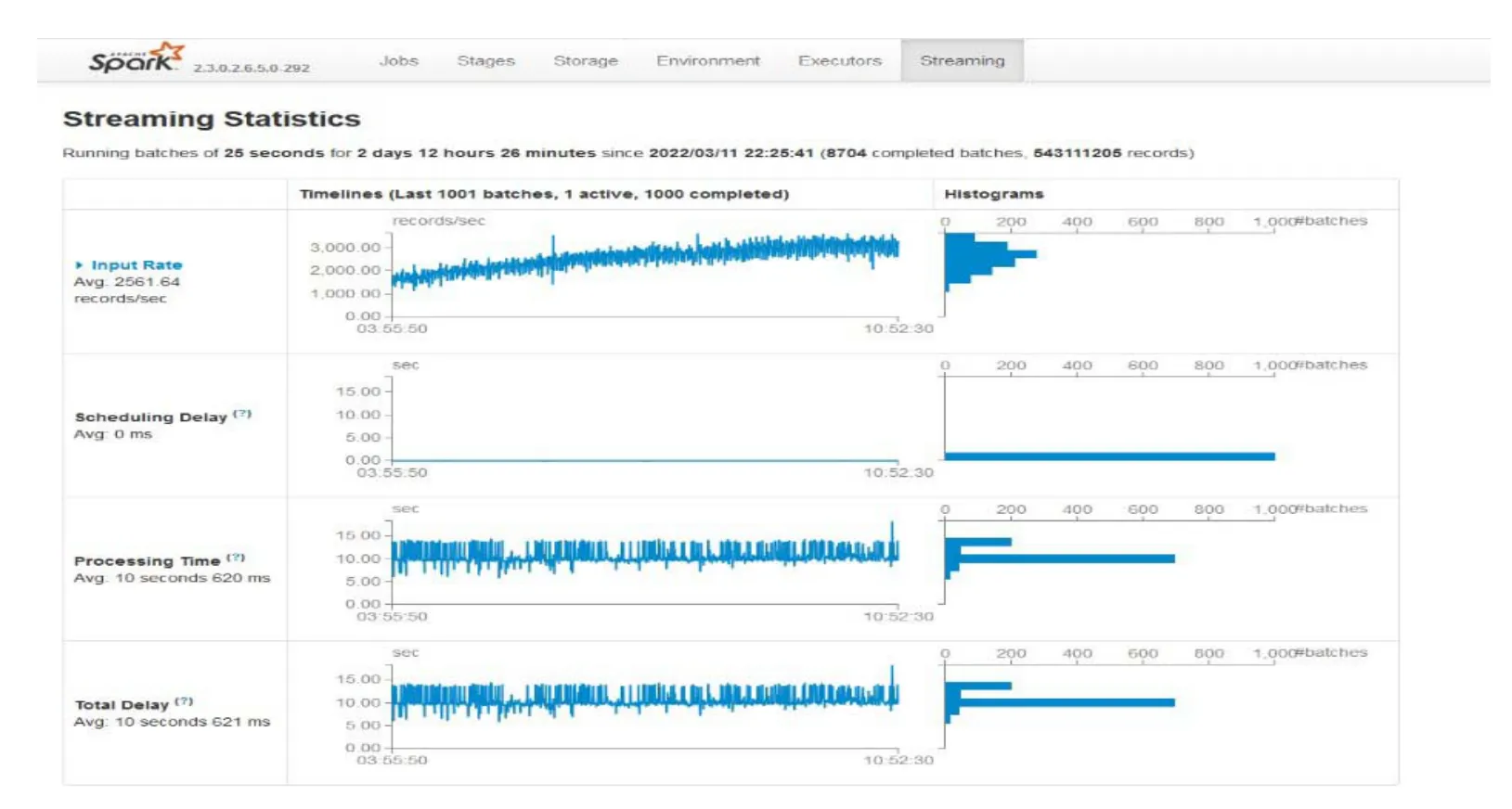
图7 处理WTDS数据
同时,基于动车组PHM模型对EMIS业务数据的需求,结合本文数据处理架构的设计思路,根据EMIS各类业务数据的数据情况与更新频率,制定EMIS业务数据的抽取、清洗策略,将EMIS业务数据持久化到模型数据处理架构的公共缓存区中,供各模型程序使用。如图8所示,在测试环境下借助StreamSets构建了EMIS中动车组开行、走行公里、高级修、配属、车组状态、构型等多类结构化数据的公共缓存区,同时实现了缓存区数据的动态更新。
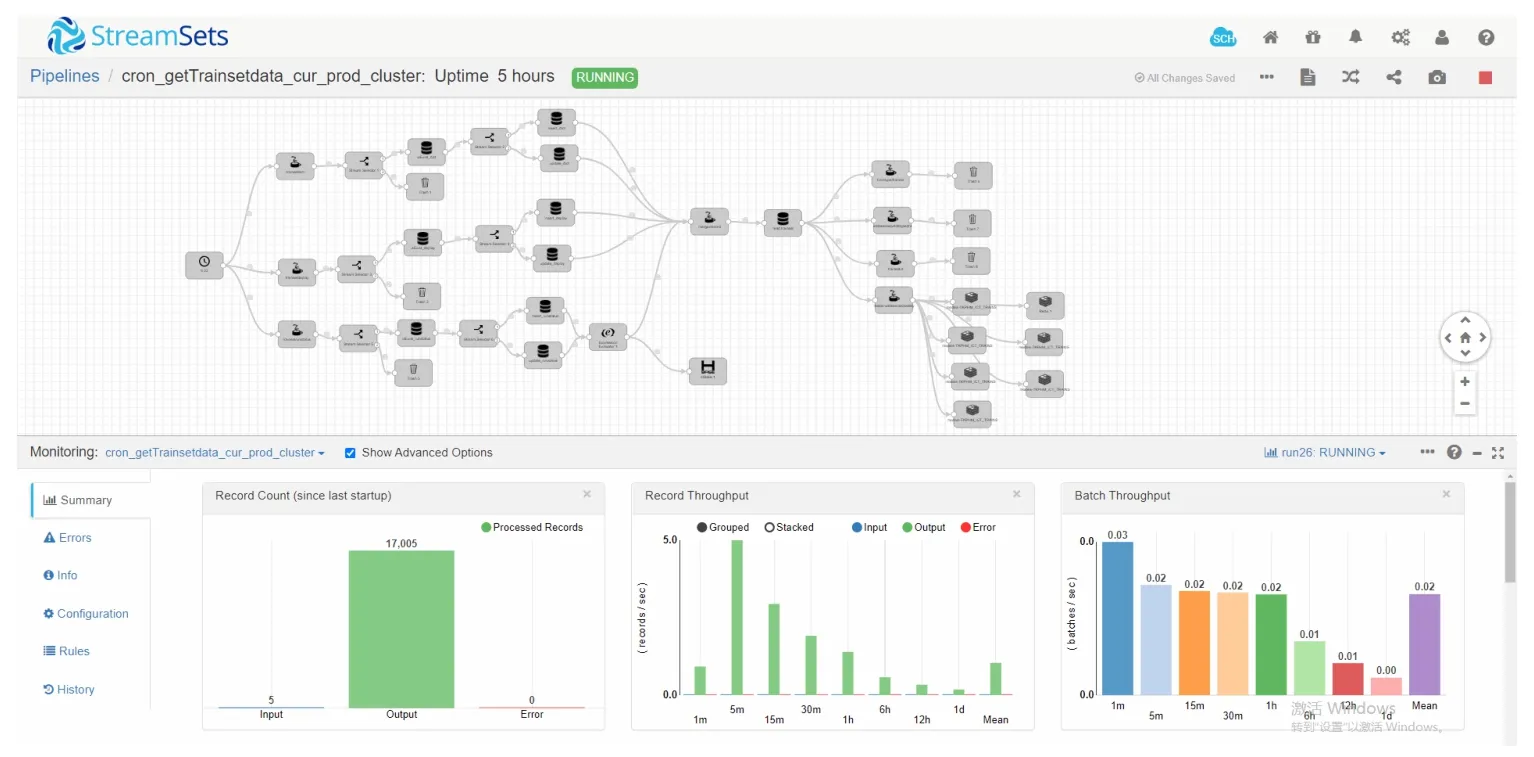
图8 StreamSets构建EMIS数据公共缓存区示意
5 结束语
本文从动车组PHM模型的应用现状出发,针对模型源数据处理,优化了模型数据处理总体架构和技术架构。同时,对WTDS数据处理技术、数据存储、数据缓存等关键技术进行了探讨与研究。经测试验证,该优化的架构高效可行,解决了动车组PHM模型源数据处理难题,为动车组PHM模型更好地服务于动车组运行安全监控与运维指导提供了保障。
