基于长短期记忆神经网络的 油井产量预测方法研究
2022-08-08李彦普中国石油大港油田公司第一采油厂天津300280
李彦普(中国石油大港油田公司第一采油厂,天津 300280)
0 引言
掌握油井产量变化规律是提高油田经营管理水平的关键。由于油藏地质、举升工艺、作业措施、管理水平等的复杂性,影响油井产量的因素众多[1]。目前常采用油藏工程方法或者油藏数值模拟方法预测产量,所用计算模型不能反映实际储层渗流情况[2]。近年来,基于数据驱动的人工智能技术逐渐应用于油气行业,它们不再依赖于物理模型,而是通过包含各种信息的生产数据进行前后信息关联和预测,取得了较好的应用效果[3-4]。
2020 年,刘巍等[5]考虑油井和周围注水井的油藏静态资料和开发动态参数,建立了一种利用机器学习模型实现油井日产油量的快速预测方法。王洪亮等[6]在对32 个产量影响因素分析的基础上采用长短期记忆神经网络模型进行产量预测,发现该方法的预测结果优于传统水驱曲线方法和全连接神经网络方法。2022 年,Ng等[7]利用元启发式算法(MA) 和机器学习算法对Volve 油田生产数据进行产量预测研究,并对7 种数据驱动模型的预测性能进行了评价,发现长短期记忆神经网络在训练结果和预测准确性方面要优于其他6 个模型。
本文以单井为研究对象,不考虑油井与油井之间的相互影响,建立基于长短期记忆神经网络的油井产量预测模型,实现简便、快捷、准确的油井产量预测。
1 理论与方法
长短期记忆神经网络是一种改进的递归神经网络,适合用于油田生产的长时时序预测。长短期记忆神经网络在递归神经网络的基础上增加了输入门、输出门和遗忘门,其结构如图1 所示[3]。
在t 时刻,长短期记忆神经网络单元处理输入状态xt、短期隐藏状态ht-1和长期隐藏状态ct-1来生成输出状态yt。长期隐藏状态ct-1包含t 时刻之前的时间步的相关信息,短期隐藏状态ht-1包含上一个时间步的信息。
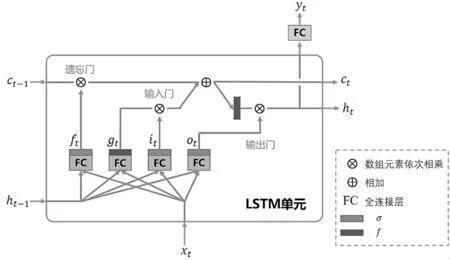
图1 长短期记忆神经网络结构
遗忘门决定t 时刻ct-1被遗忘的部分,通过执行ft和ct-1之间的数组元素相乘来实现,当ct-1里的元素被0 相乘则全部遗忘,被1 相乘则全部保留;输入门通过执行gt和it之间的数组元素相乘来决定在长期隐藏状态中gt被保存的部分;遗忘门信息(ftct-1)和输入门信息(gtit)相结合得到时刻t 的长期隐藏状态ct;输出门处理新的长期隐藏状态ct和输出向量ot来生成新的短期隐藏状态ht;输入状态xt和短期隐藏状态ht-1通过全连接层FC 进行处理,其中gt、ft、it、ot分别为:
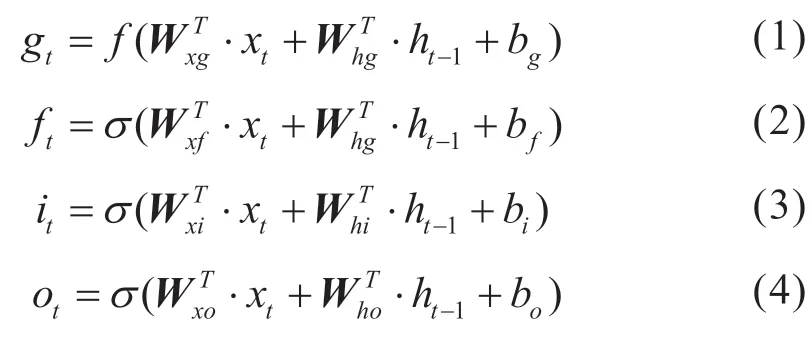
式(1)~(4)中:f 为非线性激活函数,一般为tanh或ReLU;σ 为激活函数,通常为Sigmoid;ft、it、ot由激活函数σ 决定,分别控制遗忘门、输入门和输出门,取值范围在0 到1;gt为由非线性激活函数f 决定,与it一起控制输入门的参数,取值范围为0 到1;Wxg、Wxf、Wxi、Wxo为处理输入xt的权重矩阵;Whg、Whf、Whi、Who为处理短期隐藏状态ht-1的权重矩阵;bg、bf、bi、bo为偏置项;权重矩阵和偏置项是状态矩阵中每个元素的加权系数,在神经网络自我学习过程中由程序自动调整。
2 数据预处理与模型训练
2.1 数据样本
本文以某油井生产数据为例,收集和整理该井自2019 年2 月27 日至2022 年1 月26 日的生产时间、冲程、冲次、套压、气油比、日产液、日产水数据并进行数据清洗,主要包括清除数据异常点、补全缺失数据,保证整个生产时段内数据的完整性和有效性。
2.2 数据归一化
为了提升长短期记忆神经网络模型计算精度,使得不同维度之间的特征在数值上有一定的可比性,同时为了提升长短期记忆神经网络模型的收敛速度,采取最大最小归一化方法将数据映射到[0,1] 区间,计算公式如下:

式中:x 为某特征待归一化的数据;xmin为该特征的最小值;xmax为该特征的最大值。
2.3 样本集构造
2.3.1 特征向量构造
假设Xt为第t 天产液量和产水量影响因素特征向量,每个特征向量包含生产时间、冲程、冲次、套压、气油比5 个特征,依次编号为Xt1~Xt5。
2.3.2 时间序列数据构造
LSTM 网络要求其输入是特征向量的序列,而序列是由连续的M 个特征向量组成,M 为时间步长。本文构造的输入序列形式为{Xt-M+1, Xt-M+2, …, Xt}。第1 个序列为{X1, X2, …, XM},第2 个序列为{X2, X3,…, XM+1},以此类推。
2.3.3 样本数据集构造
样本由输入时间序列和输出时间序列构成,假设总生产时间为T,时间步长为M,Ytl为第t 天的日产液量,Ytw为第t 天的日产水量,输入时间序列包括I1={X1, X2,…, XM}, I2={X2, X3,…, XM+1},…, In={Xn, Xn+1,…, XM+n-1};输出时间序列包括O1={YlM+1, YwM+1}, O2={YlM+2, YwM+2},…, On={YlM+n, YwM+n},共组成n 个监督学习样本,n=T-M+1。
2.3.4 数据集划分
对选取的生产数据按照8∶2 的比例划分训练集和测试集,即2019 年2 月27 日至2021 年6 月27 日数据作为训练集,2021 年6 月28 日至2022 年1 月26 日数据作为测试集。
2.4 评价指标
采用平均相对误差、决定系数评价长短期记忆神经网络模型训练的好坏。平均相对误差越小则模型训练的越好,决定系数是一个小于等于1 的正数,决定系数越接近1 则模型训练的越好。
2.5 模型训练与自动调优
长短期记忆神经网络的逻辑是输入前M 天生产时间、冲程、冲次、套压、气油比数据,预测第M+1 天的日产液、日产水;接着按照一定步长移动这个M 天时间步,来预测下一个M+1 天的日产液、日产水,从而实现整个数据集的迭代计算。为了防止过度拟合,长短期记忆神经网络模型训练过程中添加忽略层,在每次训练时随机忽略一些神经元。通过网格搜索,得到长短期记忆神经网络模型最优网络结构参数为:忽略层的比例为30%,时间步长3 天、批次大小256、第一层内神经元数目512、第二层内神经元数目256、训练次数=300。
在长短期记忆神经网络模型训练过程中,采用Adam 优化器寻找模型的最优解。Adam 优化器是自适应学习率优化器的一种,可以让学习率随训练过程自动修改,有着收敛速度快、调优容易等优点。模型训练过程中选择均方差作为损失函数。
3 结果与讨论
模型训练过程中训练集和测试集的损失函数随训练次数的变化如图2 所示。可以看出,训练集和测试集的损失函数随训练次数的增加逐渐减小并趋于稳定,并且两者非常接近,说明长短期记忆神经网络模型训练过程中没有出现过拟合或欠拟合现象。训练集产液量和产水量拟合的决定系数分别为0.980 和0.987、平均相对误差分别为1.36%和4.34%,说明模型具有较高精度。
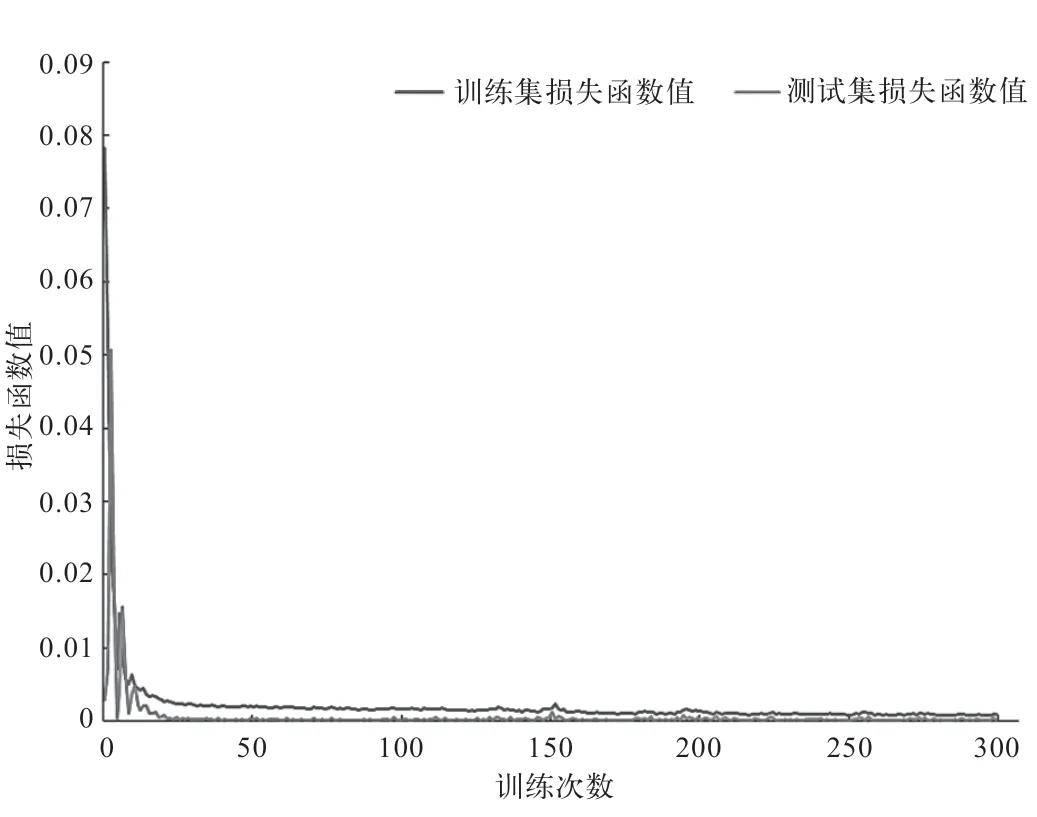
图2 训练集和测试集损失函数随训练次数的变化
该井产液量和产水量预测结果如图3 和图4 所示,其决定系数分别为0.724 和0.780、平均相对误差分别为0.64%和0.96%。部分日期的预测结果统计如表1 所示。预测结果准确掌握了该井产液量和产水量的变化趋势。
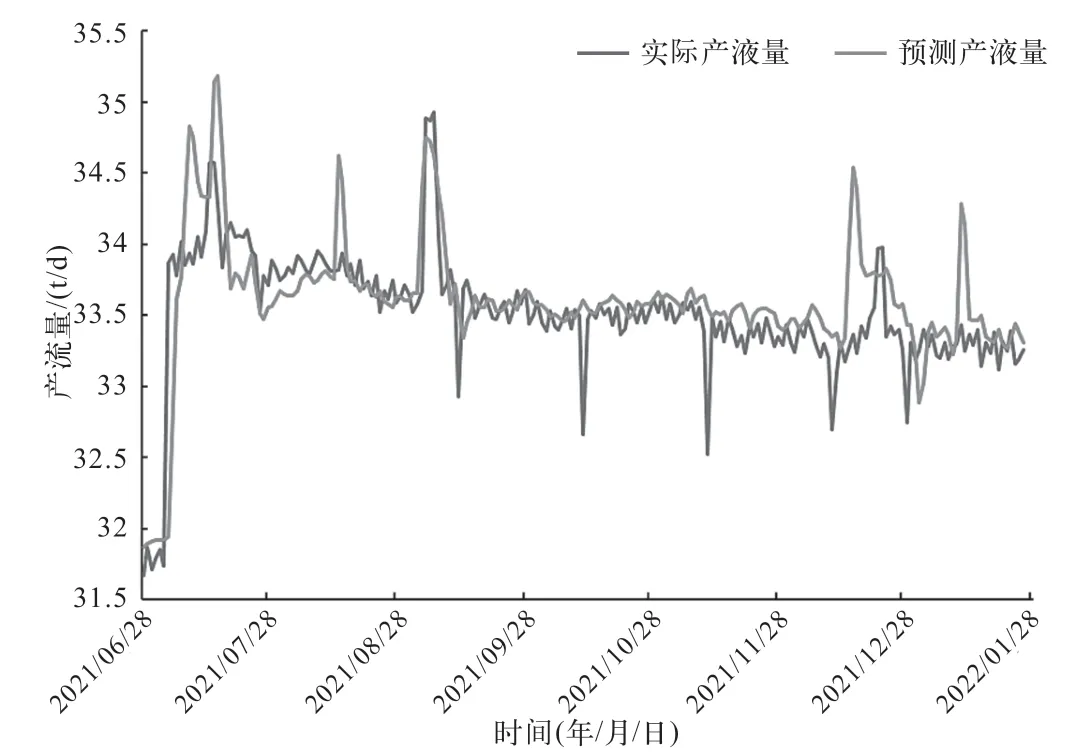
图3 测试集产液量预测结果

图4 测试集产水量预测结果
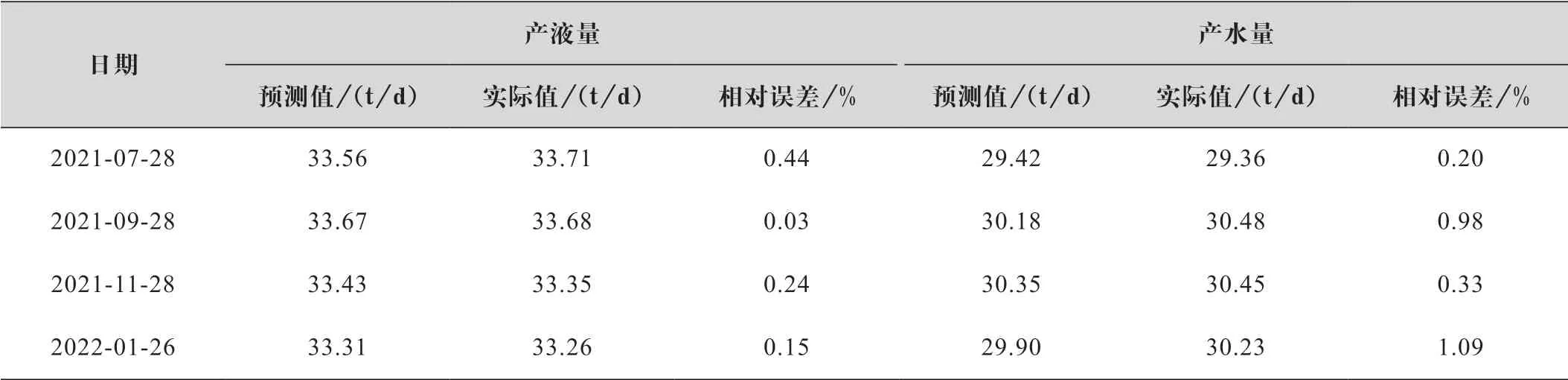
表1 产液量和产水量预测值与实际值统计
4 结语
本文考虑油井生产历史数据的变化趋势和前后关联性,利用单井生产数据建立了一种基于LSTM 模型的油井产量方法。现场实例应用表明,本文建立的长短期记忆神经网络模型具有良好的预测性能,产液量和产水量预测平均误差分别为0.64%和0.96%,预测精度能满足现场工程应用要求。基于目前的研究成果,可以进一步将区块中各口油井之间的相互影响引入长短期记忆神经网络模型中,以考虑油井之间的干扰影响;也可以将注水井引入长短期记忆神经网络模型中,以考虑注水对油井产量的影响。
