乳腺癌预测模型构建研究*
2022-08-04阮旭凌郭志恒晏峻峰
阮旭凌 刘 琦 郭志恒 晏峻峰
(湖南中医药大学信息科学与工程学院 长沙 410208)
1 引言
近期世界卫生组织国际癌症研究机构发布全球最新癌症数据,显示乳腺癌已成全球第1大癌症[1],不仅女性会患上乳腺癌,男性乳腺癌患者数量也不容小觑,乳腺癌防治形势的严峻性需要引起全社会重视,因此做到早发现、早确诊、早治疗对于患者具有重要意义。随着医疗技术发展,大量数据分析技术应用于乳腺癌疾病诊断。吴辰文、李长生和王伟等[2]提出基于加权特征向量核函数的支持向量机算法对乳腺癌进行分类预测;刘军、彭慧娴和黄斌等[3]提出BP-GamysBoost算法模型运用于乳腺癌疾病诊断;于凌涛、夏永强和闫昱晟等[4]采用卷积神经网络分类乳腺癌病理图像;冯照石和范祺[5]通过双重加权朴素贝叶斯算法预测乳腺癌患者复发率;余莹、樊重俊和朱人杰等[6]基于系统聚类和支持向量机算法模型对乳腺癌不同肿瘤特征进行诊断。上述几种算法虽然都取得良好效果,但分类预测精度有待提高。由于乳腺癌产生机制具有不确定性,且不同患者身心素质差异较大,因此需要针对个人制定个性化治疗方案以提高治疗效果[7]。在乳腺癌个性化治疗过程中,患者需要检查多项指标,如何在众多信息中迅速找到对患者病因有重要影响的指标是解决问题的关键。在乳腺癌原始检验指标中常存在冗余信息和噪声数据,如维度较大会导致问题的复杂性和时间的复杂度扩大,对数据特征属性进行降维能够降低系统计算量,结合机器学习算法构建预测模型,以此来诊断乳腺癌病发率,能够较好地辅助医生对患者进行乳腺癌早期诊断,具有重要现实意义。
2 数据集
2.1 数据集描述
本实验采用kaggle数据库提供的乳腺癌诊断数据集(Breast Cancer Wisconsin (Diagnostic) Data Set)。其中良性样本(标签为0)308例,恶性样本(标签为1)190例,每例样本中有30个特征属性,1个类别标签和1个样本id,类别标签表明患者乳腺细胞核属于良性还是恶性,特征属性描述细胞核的10个实际值特征,是鉴别患者是否被诊断为乳腺癌的关键指标。本实验将数据集的70%作为训练样本,剩余30%作为测试样本,见表1。

表1 特征属性

续表1
2.2 数据预处理
经过对数据集的筛查,未出现数据缺失、数据异常、数据重复等情况,且正负样本数据较均衡。本数据集的诊断类别为字符串,为方便对照将诊断结果量化为2种,其中0代表乳腺细胞核为良性,1代表乳腺细胞核为恶性。在数据维度较高时,为提取有用特征方便计算,通常进行数据降维。原始数据集有特征属性30项,在这些指标中常存在冗余信息,增加了系统计算量和时间复杂度。通过线性判别式分析(Linear Discriminant Analysis,LDA)方法合并特征属性,减少数据冗余引起的误差,快速缩小数据维度,降低系统复杂性。
3 基本原理与模型建立
3.1 LDA方法
3.1.1 定义 LDA是基于分类模型进行特征属性合并的方法,是一种有监督的降维方式[8]。其基本原理是将带有类别标签的数据投影到维度更低的空间中,以便按类区分投影后的点。投影后空间中同类点之间距离会更接近、方差更小,而不同类之间的方差越大[9]。降维能够减少冗余信息引起的误差,提高识别准确率。
3.1.2 LDA降维步骤 假设存在数据集D={(x1,y1),(x2,y2),...,((xm,ym))},其中有n维向量样本xi,Nj(j=0,1)为第j类样本的个数,Xj(j=0,1)为第j类样本的集合,LDA降维步骤[10]如下:
首先计算每个样本的均值向量μj和协方差矩阵∑j:
(1)
Σj=∑x∈Xj(x-μj)(x-μj)T(j=0,1)
(2)
然后计算类内散度矩阵SW和类间散度矩阵Sb:
SW=∑0+∑1=∑x∈X0(x-μ0)(x-μ0)T+
∑x∈X1(x-μ1)(x-μ1)T
(3)
Sb=(μ0-μ1)(μ0-μ1)T
(4)
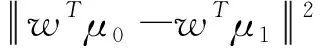
(5)
求得最优投影直线w,对样本集中的每个样本特征xi进行转化得到新的输出样本wTxi,即可完成降维。
3.1.3 30个特征属性对分类结果的重要性计算 在本实验中,利用XGBoost模型计算30个特征属性对分类结果的重要性,这些重要性得分可通过python中的成员变量feature_importances_得到,见图1。取出排名前2位的特征属性radius_worst和concave points_mean进行正负样本分布可视化,两种类别的数据有重合部分,边界数据混杂,因此需进行降维,见图2。
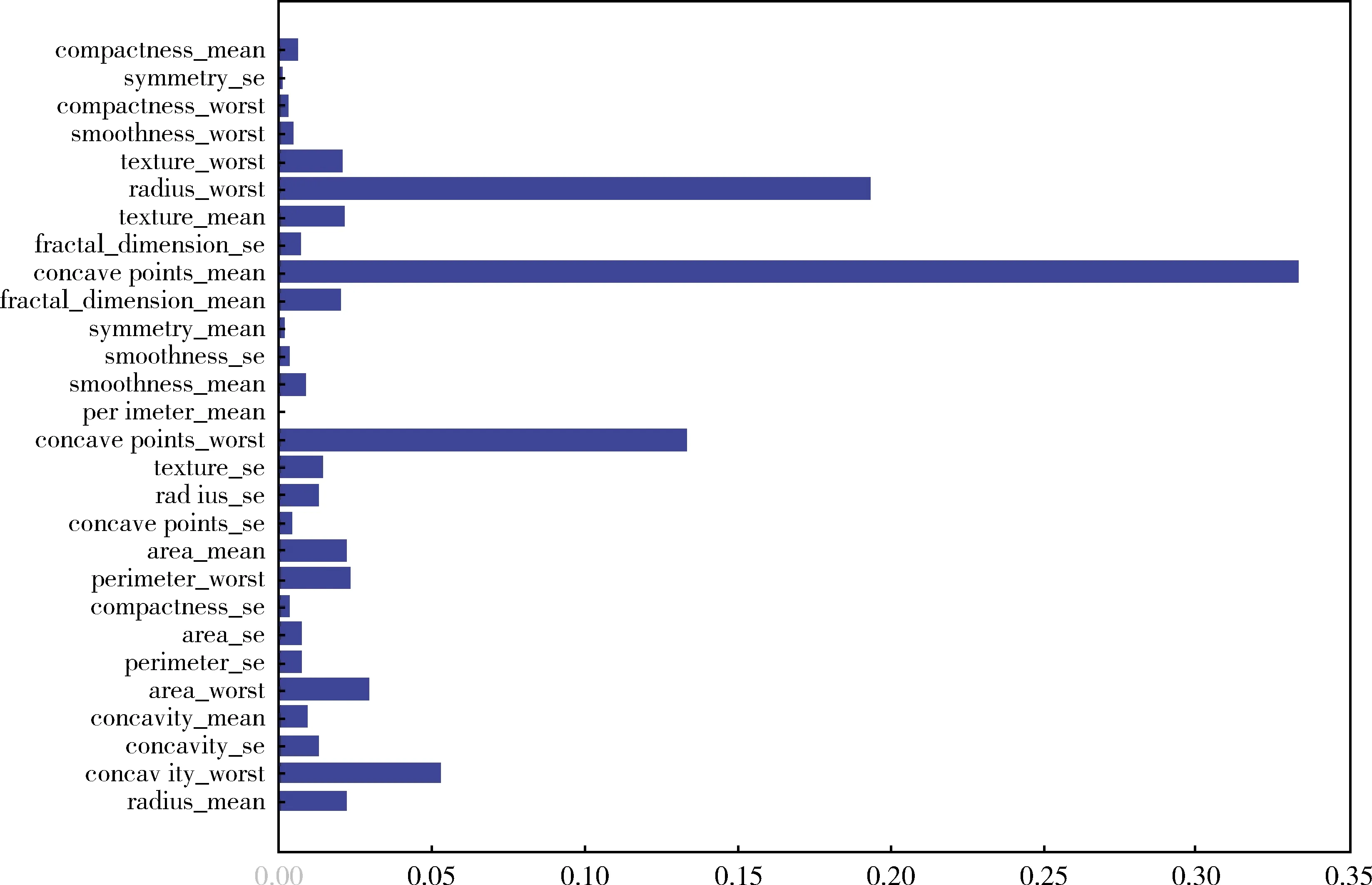
图1 特征属性重要性分布
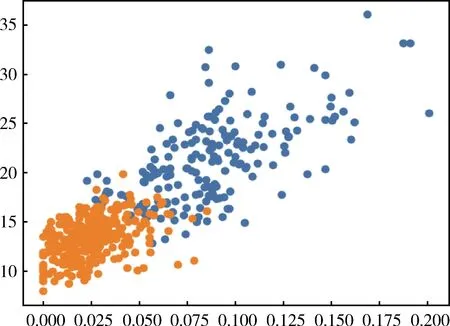
图2 特征属性正负样本分布
3.1.4 降维效果 根据LDA原理可知对于二分类问题降维后的特征维数需不大于1,因此采用LDA方法将数据特征从30维降维到1维,见图3。其中所有数据被投影至同一条直线上,相同类别的数据投影点距离缩小,不同类别数据的中心间距扩大。
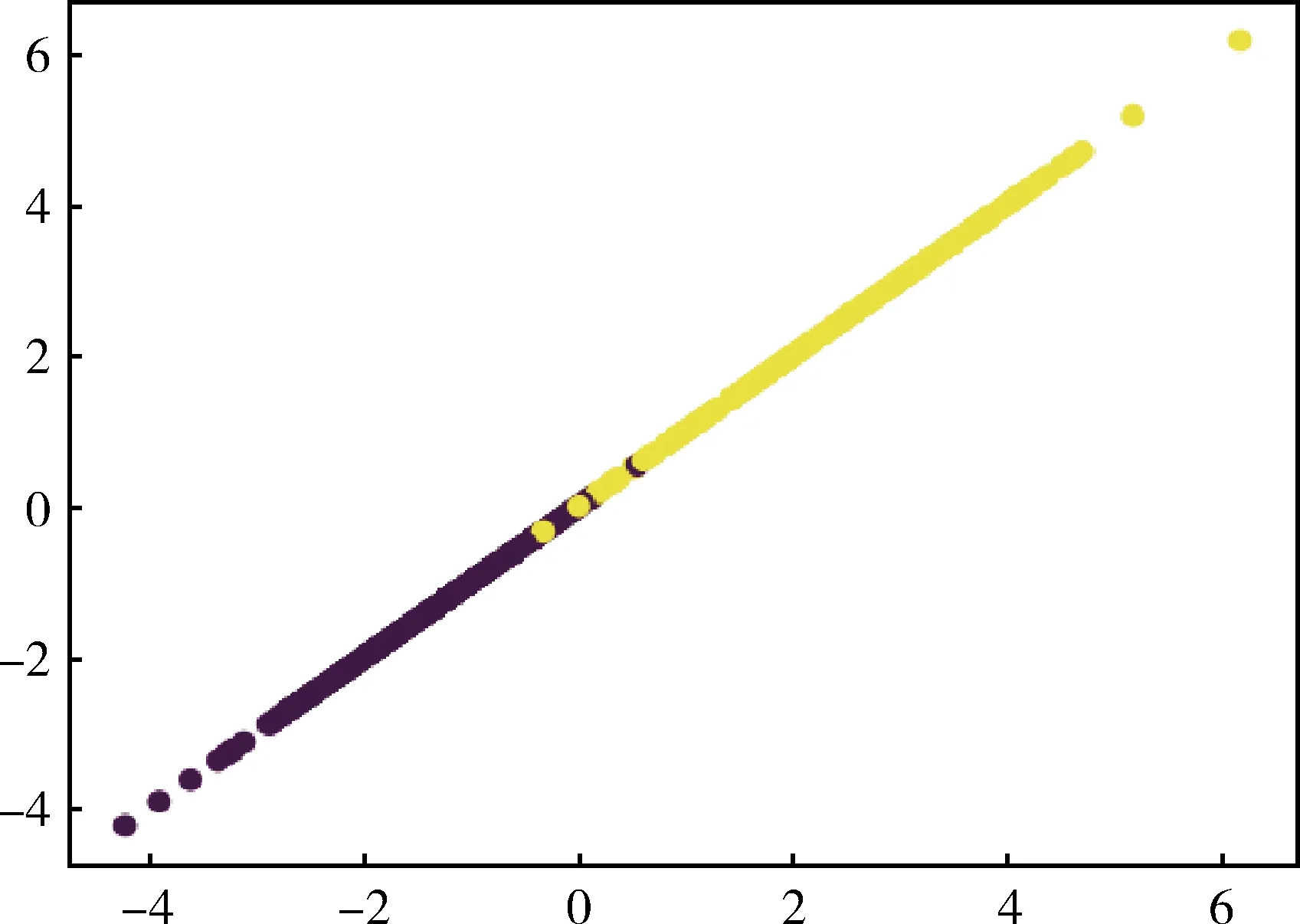
图3 LDA降维后效果
3.2 XGBoost模型
3.2.1 定义 XGBoost[11]即极端梯度提升算法,是对梯度提升(Gradient Boosting,GB)算法的改进和高效实现,除了可以是分类回归树算法(Classification And Regression Tree,CART)决策树也可以是线性分类器(Gblinear)[12];同时XGBoost也是集成学习模型,基本思想是将多个分类性能较低的树模型即弱分类器集成一个分类准确率较高的强分类器[13];其支持特征抽样,能有效防止过拟合问题并减少系统计算量[14]。
3.2.2 模型训练流程 其计算定义公式如下:
(7)
其中yi为预测值,K表示树的数量,xi表示第i个样本,将K棵树的输出加权求和即为XGBoost模型的最终预测值。其模型训练函数如下:
L(φ)=∑il(yi,hi)+∑kΩ(fk)
(8)
其中第1项为损失函数,表示第i个样本的预测误差;第2项为正则化项,规范模型的复杂度来防止过拟合。原始数据集经过第1个弱分类器训练后输出结果,再根据其返回的残差不断调整下一个弱分类器,直至指定数目的分类器训练完成,最后将所有输出进行加权求和即为总预测值。
3.2.3 降维后经过XGBoost训练的模型(图4) 在本实验中,利用机器学习包sklearn提供的grid_search网格搜索[15]进行交叉验证获得最优参数来构建XGBoost模型,其中模型学习率learning_rate为0.1, 树最大深度max_depth为2, 最小叶子节点样本权重之和min_child_weight为5, 弱分类器数n_estimators为66,模型惩罚力度gamma为默认值0,随机采样的每棵树的列数占比colsample_bytree为0.3,每棵树随机采样的比例subsample为0.9。
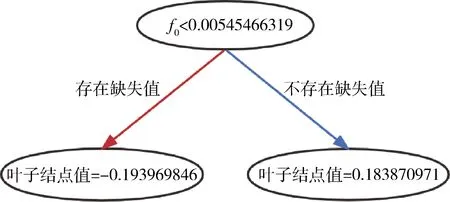
图4 XGBoost模型可视化
4 实验分析
4.1 评价指标
4.1.1 混淆矩阵 使用混淆矩阵将分类结果与实际样本信息进行比较,矩阵中每一行代表预测样本类别,每一列代表实际样本类别,见表2。相关评价指标有准确率、精准率、召回率和F1值。准确率为预测正确的正负样本数量(TP+TN)与总样本数量(TP+FN+FP+TN)的比例,是最常用的分类性能指标;精确率为预测正确的正样本数量(TP)与预测的总正样本数量(TP+FP)的比例,代表预测出为正的样本中有多少样本是真实为正的;召回率为正确预测的正样本数量(TP)与真实正样本数量(TP+FN)的比例;F1-score是目前许多实验推荐的评测指标,是精确率和召回率的调和值,当精确率和召回率接近时,F1-score值最大。

表2 混淆矩阵
4.1.2 ROC曲线 受试者工作特征(Receiver Operating Characteristic,ROC)曲线能够客观衡量模型性能。该曲线的横坐标为假阳性率(False Positive Rate,FPR),即N个真实负样本中被预测为正样本的概率;纵坐标为真阳性率(True Positive Rate,TPR),即M个真实正样本中被预测为正样本的概率;ROC曲线越接近左上角,表明该分类模型性能越好,若ROC曲线是光滑的,可以判定没有过拟合现象。曲线下面积(Area Under Curve,AUC)即ROC曲线下与坐标轴围成的面积,其大小通常处于0.5~1之间,AUC值越大表明模型性能越好、真实性越高。
4.1.3 均方根误差 均方根误差(Root Mean Square Error,RMSE)也叫标准误差,反映预测值与真实值之间的偏差,其数值越小表示模型精度越高、稳定性越好。
4.2 实验结果
4.2.1 性能检验 XGBoost模型训练完成后用测试集检验其性能。为保证评价方法的科学性、客观性、准确性,在保持模型参数不变的情况下,将原始数据集与降维后的数据集作为输入分别得出预测结果;将Adaboost、随机森林、朴素贝叶斯算法作为性能比较分类器。据结果可知降维处理后训练的预测模型分类准确率比降维之前平均高出2.7%,见图5。降维后模型训练时间大幅缩短,减少了系统计算量。
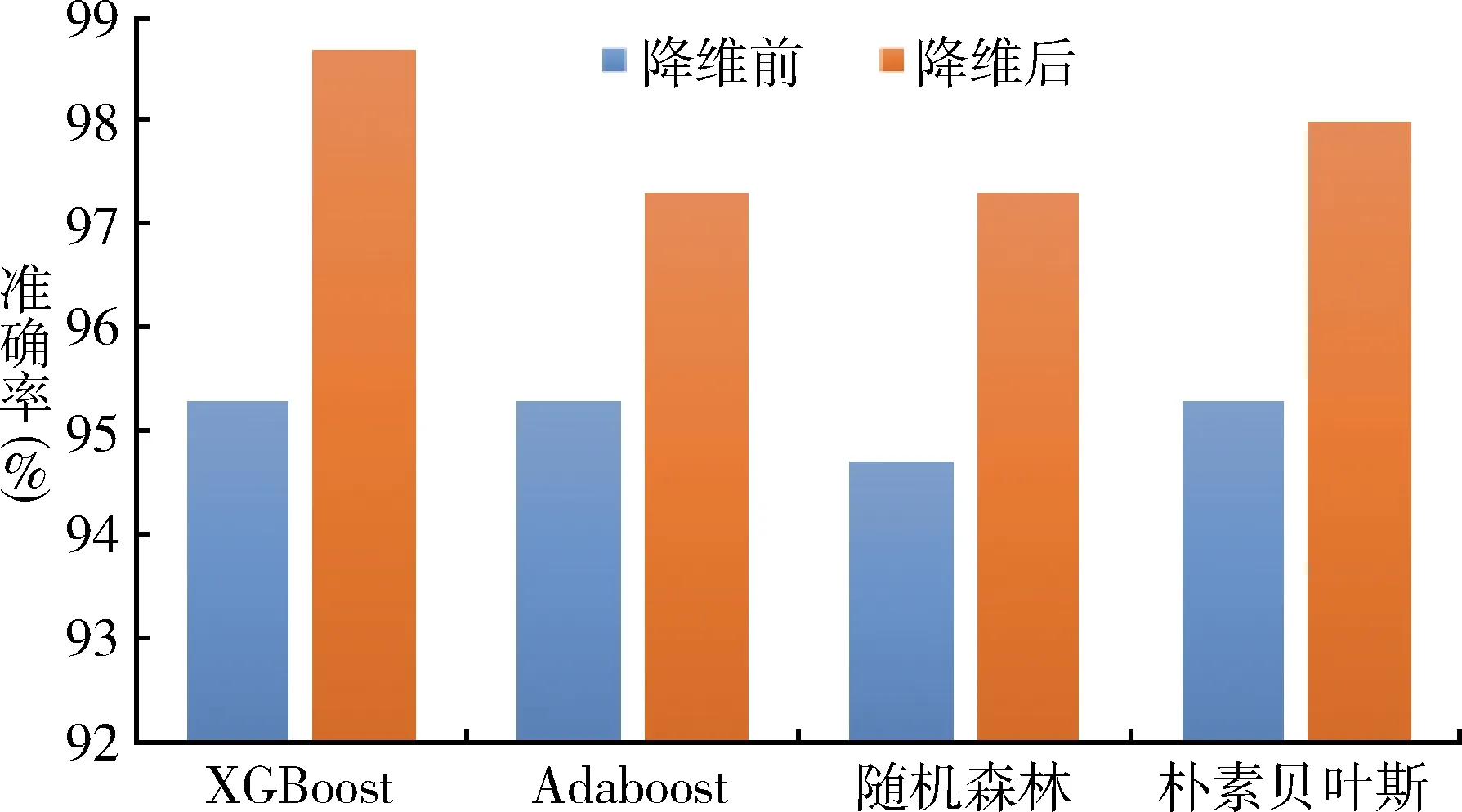
图5 降维前后各算法模型准确率变化
4.2.2 模型性能检验结果 绘制降维后各算法模型的ROC曲线,其中虚线代表某个随机分类器的ROC曲线,模型分类性能越好,离此虚线就越远。本实验中关于乳腺癌的分类预测问题,依据评价指标结果可以看出XGBoost模型性能要优于其他3种模型,其中XGBoost模型的分类准确率均值达到0.987,AUC指标均值达到0.984,均方根误差为0.115,分别比Adaboost、随机森林和朴素贝叶斯的均方根误差低4.8%、4.8%、2.6%,见表3、图6。
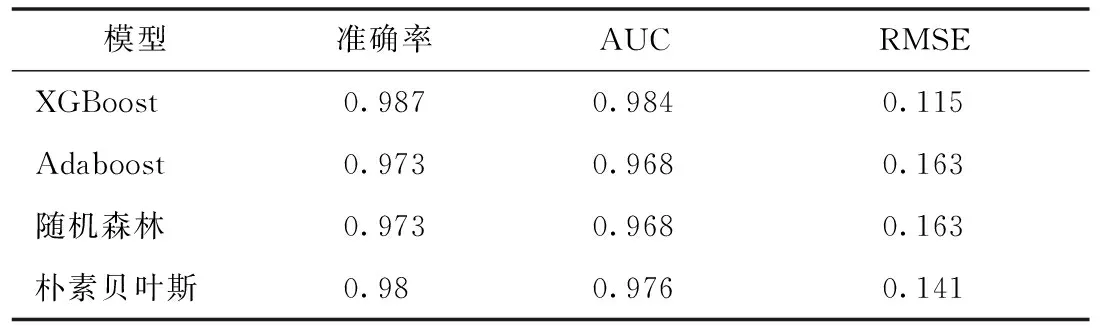
表3 模型性能结果

图6 降维后各算法模型的ROC曲线
4.2.3 结果分析 LDA方法在大幅降低数据维度的同时提高识别精准度、缩短模型训练时间;上述4种算法训练的预测模型分类效果均取得较理想分数,其中XGBoost模型分类效果最佳,具有可借鉴的医学价值。
5 结语
当前乳腺癌防治形势严峻,因此提高乳腺癌诊断率、早发现早治疗具有重要的现实意义。为提高乳腺癌诊断率、加快诊断速度,本实验利用LDA方法将原有多维数据特征合并,降低维度和系统复杂性;从4种算法择优选择XGBoost构建乳腺癌预测模型,利用网格搜索进行交叉验证提高模型准确率并防止模型过拟合;将降维前的原始数据集同样进行训练和预测,实验结果显示降维处理后训练的预测模型分类性能较降维之前更好,证明基于LDA和XGBoost算法构建的乳腺癌预测模型具有良好的分类效果,为更好地辅助医生增强医疗临床应用,提高我国医疗水平提供一定技术方法支撑。
