文本化地质资料Markdown格式规范化方法
2022-08-04
(中南大学地球科学与信息物理学院,湖南 长沙 410083)
0 引 言
随着地质调查工作的发展,海量的地质文档涌现。从不同角度对地质文档进行处理可获取不同价值的地质数据和信息,以解决地质工作中的认知、决策等理论与实际问题(李朝奎等,2015;陈建平等,2017;Qiu et al.,2019;Zhuang et al.,2020;储德平等,2021;刘文聪等,2021)。然而地质文档不仅包括文字资料,还包括表格、图片、图形等资料,存储不同形式的地质文档需要不同的软件,不仅耗时费力,还影响地质数据信息的挖掘,因此亟需解决以统一的数据格式存储地质文档的问题(刘文毅等,2019)。
Markdown是用简洁语法代替排版的一种轻量级标记语言,具有文本格式体积小、通用性高、数据类型多样的优点,能满足地质文档存储的需求。以Markdown格式存储的文本化地质资料通常有2种来源:一是直接遵循Markdown格式语法编写而成,不经文本转换;二是由其他格式资料经文本化处理后生成。受原始数据格式多样、文本化技术限制、计算机资源有限等影响(Cheng et al.,2013),其他格式资料经转换处理后生成的资料出现数据格式多样化、式样信息多样、句子不完整等问题,使得数据的读取、管理和重用变得困难(Xiang et al.,2019)。
Markdown格式的地质资料规范对地质数据信息的快速、有效、准确使用具有深刻影响(Munková et al.,2013;Uysal et al.,2014)。地质资料信息化与地质文本标准化尚处于起步阶段,Markdown格式的地质资料得到很好规范效果的研究鲜有报道。在其他领域,国内外数据规范的理论研究和技术均发展较好,成果丰富。例如,基于特殊数据格式文本信息特点的文本规范化方法,可针对特定格式数据,分析数据自身具有的文本特点,抽取文本格式特征,根据规范目的对文本的内容、格式等进行规范化处理(Bloodgood et al.,2016;顾敏等,2017;张真等,2019;孟鑫淼,2020;沈亮等,2020);基于固定规范化模板的文本规范化方法,利用固定规范化模板,通过语义分析、信息抓取等技术将文本内容整合到规范模板对应位置,从而达到规范化处理的目的(张盈利等,2016);基于相似性数据检测的规范化方法,针对特殊用途的文本,通过判断文本内容的相似性,消除重复记录,从而生成无重复记录的规范文本(刘一佳等,2013)。
针对Markdown格式地质资料的文档格式规范问题,以Markdown格式基本特征及该格式地质资料的文档格式特征为切入点,对Markdown格式地质资料的文档格式问题进行分析,以此定义文档格式规范,将规则存储于Excel表格中以便扩充与完善,通过解析规则构建文档格式规范模型,对文档格式规范结果进行分析。
1 Markdown格式地质资料基本特征
1.1 Markdown格式基本特征
与传统的文本格式资料相比,Markdown格式资料在文本内容的基础上附加了特定的格式标记信息(即基本语法),以此体现文本各部分内容的不同,同时也形成了特定的文档格式信息,主要包括目录、章节、表格和以超链接表示的图片等。
1.2 Markdown格式地质资料特征
Markdown格式地质资料的原始格式具有多样性,包括DOC、DOCX、PDF、HTML、XLS、XLSX等格式。Markdown格式地质资料的多源性也决定了其文档格式特征除包含自身的基本特征外,还包括封面、地质剖面介绍等特征。
2 文档格式问题
由于技术限制、语法标准及数据来源多样、人为因素的影响,Markdown格式地质资料存在文档格式问题,主要表现在表格数据表现形式、文本内容、图名与超链接、标记格式等方面。
2.1 表格数据表现形式多样
表格数据在表体和表名的表现形式上具有多样性。对比原始数据发现:① 原始数据表名的加粗形式多样(图1),导致Markdown格式地质资料的表名加粗形式多样(图2);② 由于原始数据的特殊性或转换工具的原因,Markdown格式地质资料在原有的Markdown标准表格形式基础上,增加了3种表现形式,分别是单线表、多线表和HTML表格(图2);③ 表名中序号之间的符号为单个“—”(图1),经文本化处理后的Markdown形式中,符号出现单个“—”和3个“-” 2种表现形式(图2);④ 部分表名位于表体中(图3)。

图2 Markdown格式地质资料Fig. 2 Geological texts in Markdown (a) Single-line table; (b) Multi-line table; (c) HTML table

图3 Markdown格式地质资料表名位于表体中Fig. 3 Geological textual data in Markdown format where the table name is contained in the table body(a) Primary data; (b) Data in Markdown format
2.2 文本内容断开
文本内容断开包括受技术限制导致的文本内容非自然断开以及人为因素导致的文本内容断开。在Markdown格式地质资料中,文本内容断开主要表现为相邻断开和非相邻断开2类。
2.2.1 相邻断开 指一个自然段落的内容断开为相邻的两行内容且段落下一行不为单独的换行符“ ”。在Markdown格式资料中,段落与段落之间以单独的换行符“ ”为分割标志,但部分资料出现了相邻断开(图4)。
2.2.2 非相邻断开 指一个自然段落不是自然断开而是由单独的换行符“ ”隔开。相较于文本内容的相邻断开,非相邻断开通常表现为以“,”“:” ““” “[”等符号结尾且下一行为单独的换行符“ ”,同时,对于部分符合上述符号结尾的文本而言,也不一定是非相邻断开,因此识别难度较大,在计算机上需要借助相关的段落特征标志才能发现。
除上述普通的非相邻断开外,还有一类常见于地质剖面介绍的特殊情况(图5)。在地质剖面介绍中,以“序号+具体剖面详述”为一行,此类数据的断开与原始数据的编辑标准密切相关。
2.3 图名与超链接问题
在Markdown格式地质资料中,图名与超链接问题主要包括下列3方面。
2.3.1 图名与超链接相邻 图片与图名超链接的表现形式为超链接在前,图名在后,且由单独一行“ ”隔开,但Markdown格式地质资料中出现图名与超链接混在一起且相邻的情况(图6a)。
2.3.2 多超链接与多图名 DOC、DOCX、PDF等格式文档常出现多张图片与图名共处一行的情况(图6b),经文本化处理后获得的Markdown格式数据也沿袭原始的数据展示形式,2个图名与2个超链接共处一行,且为紧邻行。
2.3.3 图名符号多样 以“图 序号 名称”形式呈现的图名的序号为“数字-数字”形式,数字之间应为英文状态下的“-”,但在Markdown格式地质资料中图名内符号连接呈多样性(图6c)。
2.4 标记格式问题
2.4.1 错误引用 指在原始数据并不存在引用的情况下,Markdown格式地质资料中不存在引用的地方出现了引用符号“>”,产生大量失真文本,影响信息的连贯性与真实性(图7a)。
2.4.2 多余空格 运用计算机处理和获取文档信息内容时,文字的连贯性与获取信息的正确性有着密切的联系。部分地质资料在人员信息部分,由2个字构成的姓名中间添加了空格,影响信息的正确性(图7b)。

图4 Markdown格式地质资料相邻断开Fig. 4 Adjacent disconnection in geological textual data in Markdown format (a) Primary data; (b) Data in Markdown format

图5 Markdown格式地质剖面介绍Fig. 5 Geological section introduction in Markdown format(a) Primary data; (b) Data in Markdown format
2.4.3 标记缺失 在文本化地质资料中,受原始编辑操作、编写标准、转换技术等影响,可能出现各级标题标记缺失、遗漏等情况,经文本化处理后获得的Markdown格式也并未对其进行标题标记(图7c)。这类标题标记缺失问题的出现,影响了标题和文档结构的规范程度。
3 文档格式规范模型
规范文档格式是解决Markdown格式地质资料文档格式问题的主要手段。在总结Markdown格式地质资料文档格式问题特征的基础上,建立文档格式规范特征描述机制,规则化文档格式特征及问题,通过规则解析,构建Markdown格式地质资料文档格式规范模型(图8),规范Markdown格式地质资料的文档格式。
3.1 文档格式规范特征描述
Markdown格式地质资料文档格式特征或问题包含诸多格式控制字符与关键词,可采用正则表达式对其进行有效提取,但单一正则表达式不能通用于所有段落,还需借助段落位置信息以及多个特征进行判别。文档格式规范特征不仅需考虑文档格式问题特征和文档格式规范特征,还需考虑规范的先后顺序,例如相邻断开的规范应在非相邻断开规范前,否则会导致文档混乱。基于上述考虑,定义了由正则表达式、关联特征描述语言、优先级和规范化方法构成的文档格式规范特征描述语言。
3.1.1 正则表达式 又称规则表达式,通常用于检索或替换符合某个模式(规则)的文本,主要应用对象是文本,在各种文本编辑中广泛使用,根据文档格式问题特征,基于正则表达式原则,使用普通字符与元字符对文档格式问题特征进行描述。
3.1.2 优先级 规定了文档格式问题识别的先后顺序,以避免在文档格式规范过程中出现错误内容。定义优先级描述语言有0~5级,0级为最优级,其次为第1级,以此类推。
3.1.3 关联特征描述语言 正则表达式能描述文档格式规范中关键字、控制字符的特征,1个正则表达式可描述1个文档格式规范特征。然而,有的文本化地质资料的文档格式规范特征是由多个特征构成,例如一级标题的文档格式规范特征包含标题特征和标记特征,而单一的正则表达式无法描述多个特征,因此定义了包括多条件描述语言和方法标识符的关联特征描述语言。

图6 图名与超链接问题Fig. 6 Figure name and hyperlink problems (a) Figure names adjacent to hyperlinks (primary data in the figure above and data in Markdown format in the figure below); (b) Multiple hyperlinks and multiple figure names (primary data in the figure above and data in Markdown format in the figure below); (c) Figure names in various connectives (primary data in the figure above and data in Markdown format in the figure below)

图7 标记格式问题Fig. 7 Markup format problems(a) Misquotation (primary data in the figure above and data in Markdown format in the figure below); (b) Extra spaces; (c) Markup missing (primary data in the figure above and data in Markdown format in the figure below)
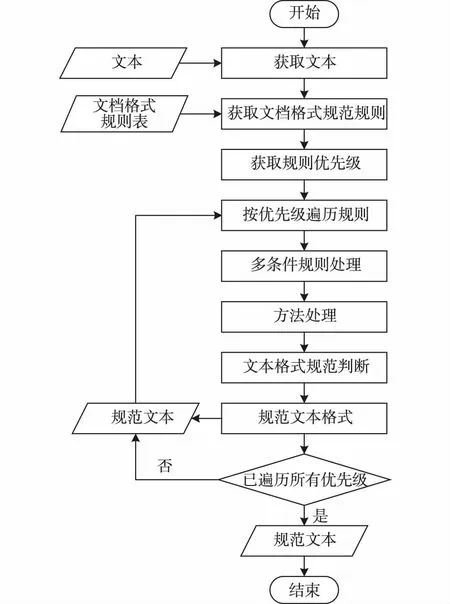
图8 文档格式规范模型Fig. 8 Text format specification model
多条件描述语言可描述多个特征构成的文档格式规范特征,借助连接词将多个特征关联起来,主要包括“和&&”“或||”以及“非NOT”。方法标识符的形式为“/%name%/”,其中的name为方法包括:① until方法,查找符合条件的多行文本,方法前后跟随开始特征与结束特征,具体表述为“开始特征 /%until%/结束特征”;② nextline方法,其后跟随下一行的特征;nexttwoline方法(即下两行的方法),其后跟随下两行的特征;③ LEN方法,计算匹配结果长度的特殊方法,格式为“LEN(正则名)<|>number”。
3.1.4 规范化方法 基于文档格式问题特征构建规范化方法,以规范化方法描述语言对方法进行描述(表1),通过该语言调用规范化处理方法,对存在文档格式问题的段落进行规范。

表1 规范化处理方法
3.2 规则存储与解析
3.2.1 规则存储 遵循定义的特征描述语言对文档格式及问题特征进行描述,即形成文档格式规范规则。由于规则不可能覆盖所有文档,故采用Excel存储文档格式规范化规则(表2),便于在不同文档应用中对规则进行扩充,提高通用性和可迁移性。
3.2.2 规则解析 将规则解析为计算机能够直接使用的语言,是文本化地质资料文档格式规范过程中的重要环节。
(1) 规则遍历。 获取文档格式规范规则表Rlist,并根据优先级级别按升序的形式获取优先级列表plist,按优先级顺序对规则进行逐级遍历处理。每次遍历的当前优先级为CurPri,设每次遍历的当前规则为rule。逐级遍历时,若当前规则rule的优先级与当前优先级CurPri相等,则直接对当前规则rule进行处理;遍历一遍所有优先级等于当前优先级CurPri的规则,即遍历完当前优先级CurPri所含的规则;然后进入下一优先级的遍历,直至遍历完所有优先级包含的规则。

表2 文本化地质资料文档格式规范规则存储示意
(2) 多条件规则处理。指对包含多条件描述语言(“和&&”“或||”)的规则进行处理。以多条件描述语言为特征,将规则分割为多个子规则,按顺序遍历子规则,对规则逐一进行遍历,直至子规则遍历完毕。具体实现过程见下列算法1:多条件规则解析算法。
1 获取多条件规则R
2 多条件规则处理
判断多条件规则R包含的多条件控制字符是“和&&”、“或||”
以控制字符“和&&”、“或||” 为关键字符,分割多条件规则R为规则列表集Rlist
按顺序遍历规则列表集Rlist,依次读取并处理各子规则r,直至结束
(3) 方法处理。指对含方法描述语言(如“/%.*%/”)的规则进行处理。笔者定义的方法包含3类用途:多行内容获取、后续行内容获取和文本长度判断。以方法描述语言“/%.*%/”为特征获取具体方法,根据方法对规则进行处理。方法包含直到方法(until)、下一行方法(nextline)、下两行方法(nexttwoline)和LEN方法。
① 直到方法(until)。可获取多行文本以进行文档格式规范。文本化地质资料中的表格、地质剖面介绍等由多行文本构成,其规范规则通常包含直到方法的描述语言(until),需解析后获取多行文本并依据规范方法对文档格式进行规范处理。见算法2:直到方法算法。
1 获取直到方法规则R,获取当前文本C
2 直到方法规则处理
以“/%until%/”为关键字符, 获取关键字符“/%until%/”前后规则为S_R、E_R
IF当前文本C符合规则S_R
获取当前文本C的位置索引号为Cinx
从索引号Cinx加1位置开始按顺序遍历整个文本资料,查询符合规则E_R的行文本,记录该行文本索引号为Einx,结束遍历
② 后续行方法(nextline与nexttwoline)。部分文本格式的规范与其后续文本的特征相关,依据定义解析定义的后续行是规则解析中的一环。定义的后续行方法包括下一行方法(nextline)和下两行方法(nexttwoline)。处理过程见算法3:后续行方法处理算法。
1 获取后续行方法规则R,获取当前文本C的位置索引号Cinx
2 后续行方法处理
判断后续行方法规则R是下一行方法还是下两行方法
以“/% nextline%/”或“/% nexttwoline %/” 为关键字符,获取其后规则为R
判断行文本是否符合规则R(若为/% nextline%/为Cinx加1位置的行文本,否则为Cinx加2位置的行文本)
③ LEN方法。描述定义为用于判断实际规则匹配数是否符合预先规定的规则匹配数。具体过程见算法4:LEN方法处理算法。
1 获取LEN方法规则R,获取当前文本C
2 LEN方法处理
以关键字符“LEN/((.*)/)”获取子规则r
查询文本C符合子规则r的个数n
判断LEN方法规则R是包含的是“>”或“<”,并获取“>”或“<”后跟的个数N
判断符合子规则r的个数n是否“>”或“<”个数N
(4) 文档格式规范。文档格式规范是文本化地质资料文档格式规范的最后环节。文档格式是否需要规范取决于文档格式是否存在问题,需确定文档格式是否符合文档格式规范规则。在经过多条件处理和方法处理后可获取需要规范的文本,再调用该规则对应的规范方法对文本进行规范,即可完成文档格式规范。见算法5:文档格式规范算法。
1 获取需要规范的文本T,解析规则R对应的规范化方法Fun
2 规范文档格式
调用规范方法Fun,对文本T进行规范化处理,获取规范文本
根据对文本化地质资料文档格式特征及文档格式问题特征的归纳分析,确定了文档格式规范方法,受篇幅限制,仅对单线表(图4)的规范方法进行详细介绍。首先根据文档格式规范识别规则获取完整的单线表,然后对其进行规范。单线表的规范方法表示为“sintomd”。规范过程见算法6:单线表的规范方法算法。
1 获取需要规范文档格式的单线表List
根据优先级和文档格式特征规则“^(*-+ (?![du4E00-u9FA5])){2,}/%until%/^(*-+ (?![du4E00-u9FA5])){2,}”获取单线表内容,解析规范化方法“sintomd”
2 单线表规范
设空列表resultList存储最终结果
去除单线表List每个元素结尾的换行符“ ”
按顺序遍历单线表List
当前遍历数据为dataItem
IF 数据dataItem符合单线表开始特征
以英文空格为标志,分割数据dataItem结果存储于表头列表handList
ELSE
IF 数据dataItem符合表名特征
赋予其表名标记并存储于resultList
ELSE
在dataItem数据中文字符后添加英文占位符“-”,根据表头列表handList各元素长度,获取每格数据开始与结束节点,以此为据分割dataItem,转换dataItem为字符串以“|”为标记隔开相邻的两个列表元素,并存储于resultList中
4 结 果
4.1 表格格式规范
Markdown格式地质资料的表格形式包括单线表、多线表、HTML表、Markdown格式表。其中Markdown格式表格形式的可读性和标准型较高。选用Markdown格式表格作为Markdown格式地质资料表格的规范形式,对单线表、多线表和HTML表格进行文档格式规范(图9—图11),同时对Markdown格式表格中存在的不规范格式进行规范。
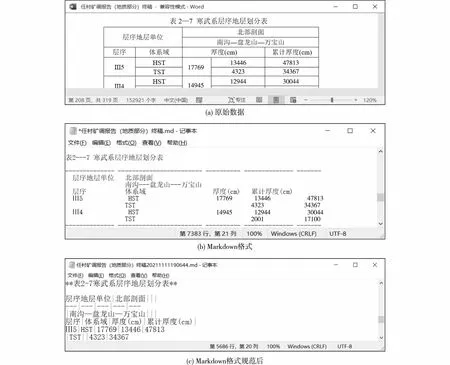
图9 单线表格规范Fig. 9 Single-line table format specification(a) Primary data; (b) Markdown format; (c) Specified in Markdown format
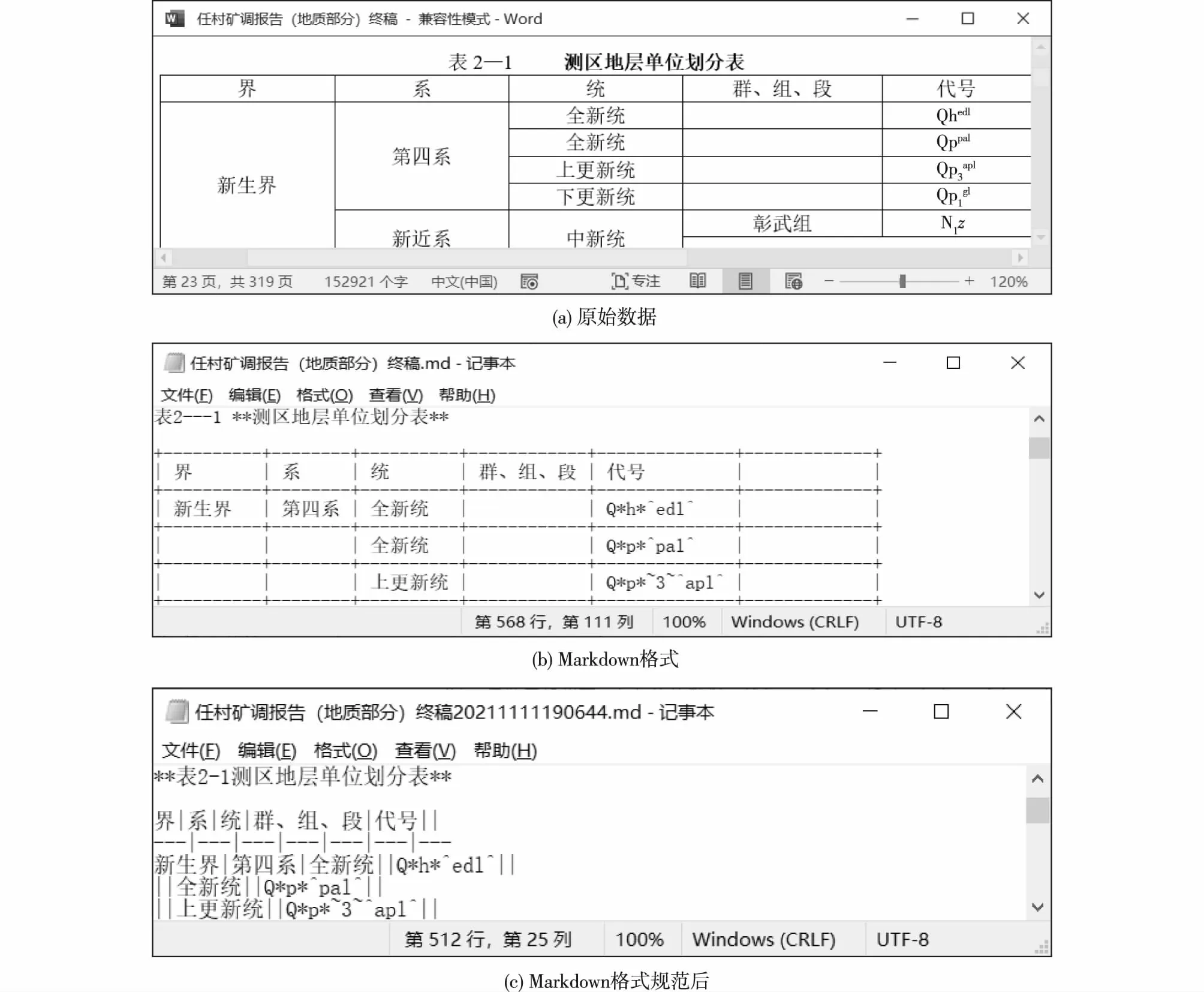
图10 多线表格规范Fig. 10 Multiple-line table format specification(a) Primary data; (b) Markdown format; (c) Specified in Markdown format
4.2 标题格式规范
为便于识别,采用的所有标题皆直接在标题前加上与标题等级数相匹配的“#”进行标记,对Markdown格式地质资料的标题进行规范(图12)。
对Markdown格式地质资料标题标记缺失内容的规范化处理(图13)显示,在原始数据中(图13a)并未对具有章节标题特征的“(3)年度资料整理”和“(4)野外验收前资料整理及野外验收”进行特殊标记,在文本化处理后获得的Markdown格式地质资料(图13b)也未遵循Markdown格式语法对标题进行标记,故需应用文档格式规范方法对其进行规范标记(图13c)。
4.3 文本内容断开规范
相邻行断开问题的规范化(图14)结果显示,Word中地质资料的一个完整段落(图14a)经文本化处理后获得了Markdown格式地质资料(图14b),但出现了断开现象,为还原原始信息,调用文档格式规范算法,获得了完整的Markdown格式段落(图14c)。
非相邻行断开问题的规范化(图15)显示,因地质剖面介绍的一条记录(图15a)过长,超过了1行所能容纳的文字数,故而以换行符将其分3行记录,经文本化处理获得Markdown格式的地质资料(图15b),但不能展现完整的地质剖面介绍信息,因此对其进行规范(图15c)。

图11 HTML表格规范Fig. 11 HTML table format specification(a) Primary data; (b) Markdown format; (c) Specified in Markdown format
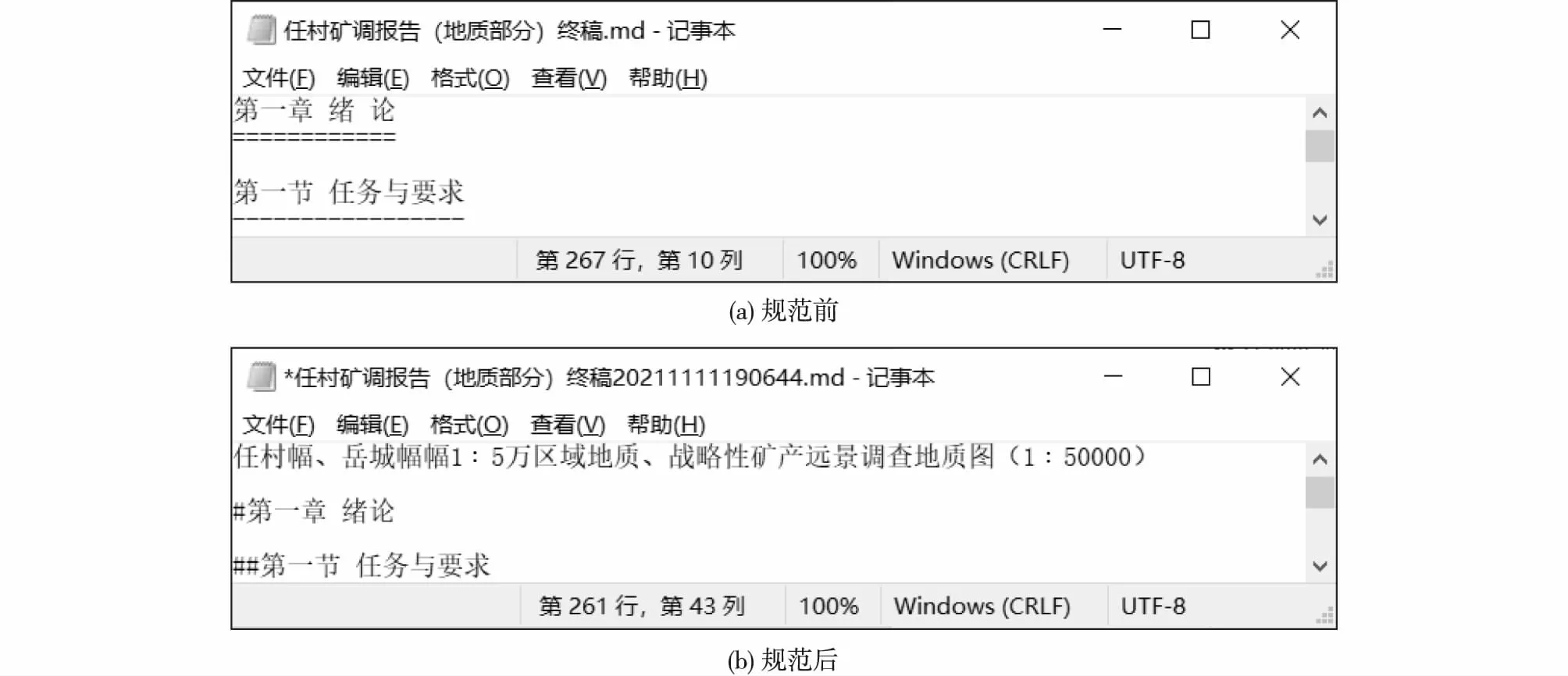
图12 Markdown格式地质资料标题标记规范Fig. 12 Specification for title markup of geological data in Markdown format(a)Before specification; (b) After specification

图13 标题缺失规范Fig. 13 Missing title specification(a) Primary data; (b) Markdown format; (c) Specified in Markdown format
4.4 图名与超链接规范
最典型且最易解决的错误是图名与超链接部分的联合,文本化地质资料文档格式规范模型能较好地规范该类错误,同时也能很好地规范多图名与多超链接位置混乱的情况。规范结果见图16。
5 结 论
(1) 以文本化地质资料为研究对象,分析Markdown格式地质资料的文档格式特征,归纳总结文档格式特征和问题。
(2) 定义由描述语言、规则存储与解析共同构成的文档格式规范机制,构建文档格式规范模型,生成Markdown格式地质资料的文档格式规范方法。
(3) 基于文档格式规范方法对Markdown格式地质资料进行文档规范,能够解决Markdown格式地质资料格式不规范的问题。

图14 文本内容断开规范Fig. 14 Text content disconnection specification(a) Primary data; (b) Markdown format; (c) Specification in Markdown format

图15 非相邻行断开规范Fig. 15 Non-adjacent line disconnection specification (a) Primary data; (b) Markdown format; (c) Specification in Markdown format

图16 多图名与超链接规范Fig. 16 Specification for multigraph names and hyperlinks(a) Primary data; (b) Markdown format; (c) Specification in Markdown format
