一种融合义原的中文摘要生成方法
2022-08-02李红莲吕学强
崔 卓,李红莲,张 乐,吕学强
(1. 北京信息科技大学 信息与通信工程学院,北京 100101;2. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引言
随着互联网的飞速发展,网络中的文本数据越来越多,如何快速从大量的文本数据中提取自己想要的信息就显得十分重要。文本摘要[1-2]是快速提取信息的一个重要手段,其可以将文本信息简化为一个包含文本关键信息的摘要,方便人们检索到对自己有用的信息。按照输出类型,文本摘要可以分为抽取式摘要[3]和生成式摘要[4]。抽取式摘要是从原文中抽取关键词或关键句组合成摘要,这种方法提取的摘要在语法方面错误率低,但是由于缺乏连接词,形成的摘要可读性往往很低,而且无法生成原文本中不存在但是对语义理解很重要的词。生成式摘要与人类写摘要的流程比较相似,首先对冗长的文本进行压缩,提取文本的主要语义内容,生成摘要。它生成的摘要中可能会出现原文本中未出现的词语,以帮助理解摘要的语义,但是存在一定的语法错误问题。随着神经网络被广泛应用于自然处理任务,基于神经网络的自动文摘受到越来越广泛的关注[5]。
目前,基于编/解码器与注意力机制结合的模型在生成式文本摘要中得到了广泛的应用,对于数据的处理分为基于字级别与基于词级别的处理。在指针网络(Pointer Network)模型出现之前,基于词级别的数据处理存在严重的词汇表限制(Out-of-Vocabulary,OOV)问题,因此大多模型都是基于字级别的处理研究。Pointer Network的出现虽然缓解了OOV问题,但是对数据集语义的理解还不够完善,影响生成摘要的质量与可读性。
针对以上问题,本文提出一种新的融合义原的中文摘要生成方法ASPM。具体地,在指针网络模型的基础上引入知网(HowNet)[6]中的义原,使用融合义原知识的词义表示模型(Sememe Attention over Target Model,SAT)[7],利用上下文与多义词义原得到词语的语义表示,并且基于LCSTS数据集中的一些多义词构造新的义原,并在数据集中进行标注,以得到更加精确的语义表示。实验结果表明,提出的ASPM方法可以生成可读性更高的摘要文本。
本文在第1节介绍基于神经网络的自动文摘以及HowNet义原相关工作;第2节介绍ASPM的结构及原理;第3节对实验数据集和评测指标进行介绍,并且对比数据集在不同模型中的实验结果;最后一节为总结以及展望。
1 相关工作
1.1 生成式文本摘要
基于神经网络的自动文摘被越来越多地应用在文本摘要中。首先是Sutskever等人[8]提出的序列到序列(Seq2Seq)模型,由一个编码器和一个解码器组成。接着Rush等人[9]将注意力机制与Seq2Seq模型结合,解码器通过解码状态与编码状态的注意力分数从编码器中提取信息。Hu等人[10]创建了一个大规模的中文摘要数据集LCSTS,并且分别以词为单位和以字为单位对数据进行处理,然后使用结合注意力机制的Seq2Seq模型在两种处理方式上进行了实验对比,为中文摘要模型[11-12]的发展奠定了基础。Chopra等人[13]使用循环神经网络(Recurrent Neural Network, RNN)代替神经网络语言模型(Neural Network Language Model, NNLM),结合注意力机制进一步提高了生成摘要的质量,这个模型之后被当作基础模型。Lopyrev[14]使用长短时记忆网络(Long Short-Term Memory,LSTM)代替RNN,缓解了网络对之前信息的遗忘,但是模型依然存在OOV问题。Vinyals等人[15]提出Pointer Network[16-20],通过指针开关决定在解码时刻从原文中复制一个词,还是根据词汇表生成一个词,缓解了OOV问题。
上述工作未能对数据集语义进行很好的理解,因此本文引入HowNet中的义原,并且针对数据集中的一些多义词构建新的义原,训练得到更能理解文本语义的词向量来帮助模型生成更高质量与更具可读性的摘要。
1.2 HowNet义原
引入义原后,如何充分利用义原信息得到更精确的词向量表示是非常重要的。唐共波等人[21]将HowNet中的义原融入到语言模型的训练中,通过义原向量对多义词进行向量化表示。孙茂松等人[22]提出一种义项敏感的义原向量表示学习神经网络模型,得到了HowNet中所有义原的向量表示,有助于对低频词和多义词的处理。Yilin等人[7]提出SAT模型,使用注意力机制在考虑上下文信息的同时考虑词语的义原信息,有效提升了词语的词向量表示。上述工作表明了引入HowNet义原对提升词向量表示的重要作用。
2 模型介绍
本文提出的ASPM中文摘要生成方法可解决现有模型中存在的一些不足,进而提升摘要的生成质量。模型一方面通过引入HowNet义原,并且针对实验数据集手动构建新的义原,使用SAT模型得到能够更加准确表示语义的词向量。另一方面,通过利用Pointer Network来缓解OOV问题。实验表明,模型能有效提升摘要生成质量。
2.1 义原介绍
在自然语言处理中,词、句子、段落、文章都可以被当作语义单位进行划分处理,而义原是最小的不可分的语义单位。HowNet是主要面向中文词汇与概念的大型语言知识库,包含了2 000多个义原的精细的语义描述体系,并为十几万个汉语词语和英文单词所代表的概念标注了义原,结构为词语-义项-义原,其中一个词语可以有一个或多个义项,而一个义项又可以由一个或多个义原来表示,图1为知网中义原、义项、词语结构表示的一个例子。
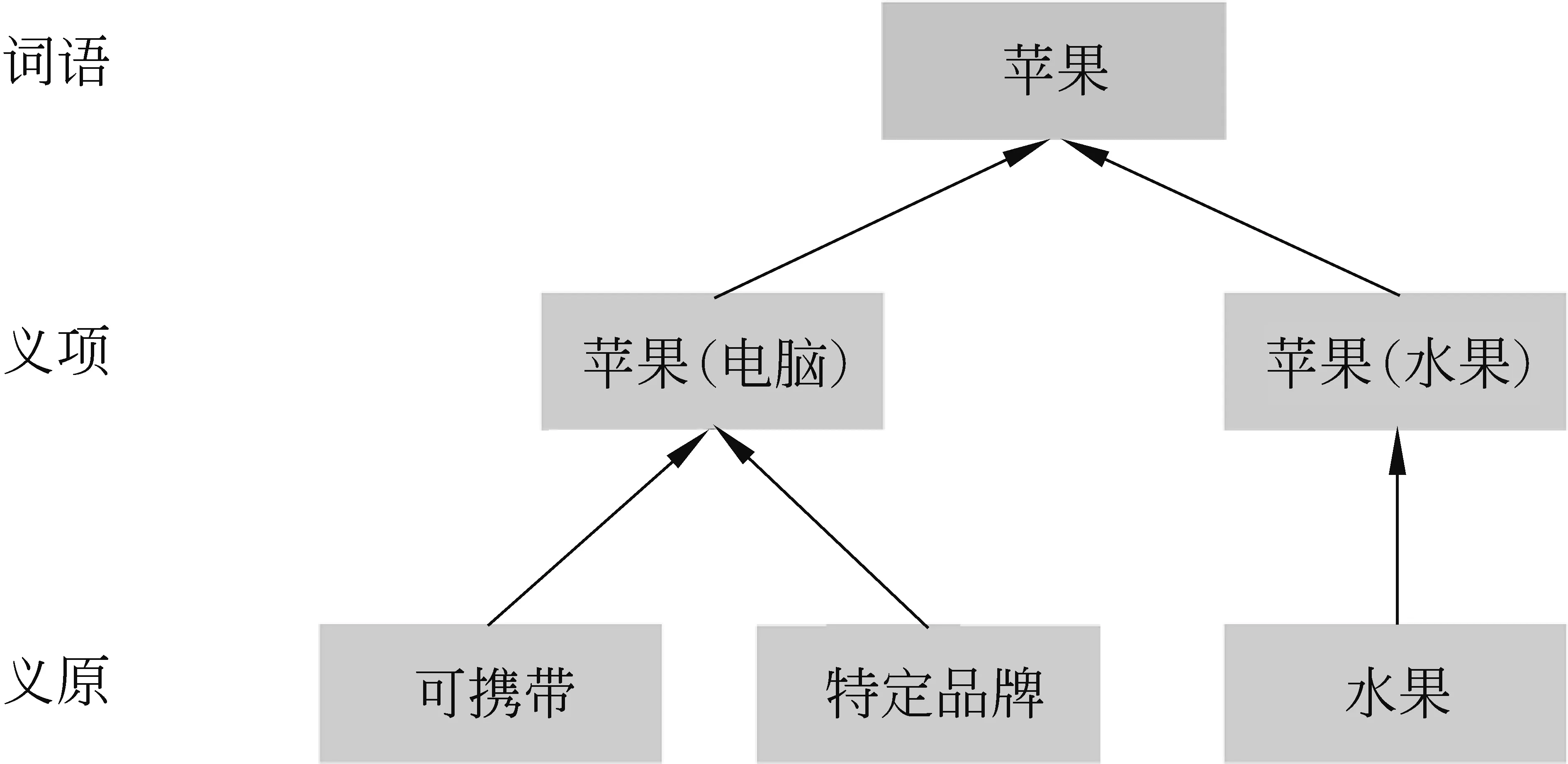
图1 词语-义项-义原结构图
其中,苹果这个词语有两个义项,分别为苹果(电脑)、苹果(水果)。而苹果(电脑)这个义项又可以通过义原“可携带”与“特定品牌”来组成,苹果(水果)可以由“水果”这个义原来组成。通过使用义原对词语的不同义项做进一步标注,就可以精准地刻画词语的语义信息。因此,可以考虑将融合义原知识的词义表示用于文本摘要任务中,使得模型能够更好地理解文本的语义信息,生成更加高质量的摘要。
2.2 融合义原知识的词义表示模型
融合义原知识的词义表示模型SAT可以利用义原准确地捕捉到一个词语在具体上下文中的含义。模型在经典的Skip-Gram模型[23]上进行改进,但是不同于Skip-Gram模型只考虑上下文信息,SAT模型同时考虑了词语每个义项的义原信息以及义项之间的关系,模型的具体结构如图2所示。

图2 融合义原知识的词义表示模型
其中,选取固定大小窗口的上下文词语,将上下文词语编码为一个统一的上下文向量, 这个向量中包含上下文的所有信息。
由于一个词的词义与上下文有很大关系,根据上下文向量可以得到词语不同义项在这个上下文中所占的权重。词语ω的词向量表示可由式(1)~式(4)得到:
(1)
(2)
(3)
(4)
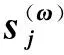
SAT模型选取多个上下文词语,利用上下文信息对目标词义原的关注程度,根据目标词的多个义项得到最符合当前情境的词向量,以此来提升目标词向量的表示能力,取得了很好的效果。
2.3 指针网络模型
指针网络(Pointer Network)模型如图3所示,在带有注意力机制的编/解码器模型中加入一个指针开关,编码器使用一个双向的LSTM将原文本的词嵌入依次输入得到隐藏状态序列hi,解码器使用一个单向的LSTM,在每一个时间步t根据前一个词语的词嵌入得到解码状态向量st。
根据Bahdanau等人[24]提出的注意力机制,由hi和st可以得到输入文本中第i个词的注意力权重如式(5)、式(6)所示。
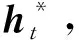
(7)
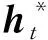
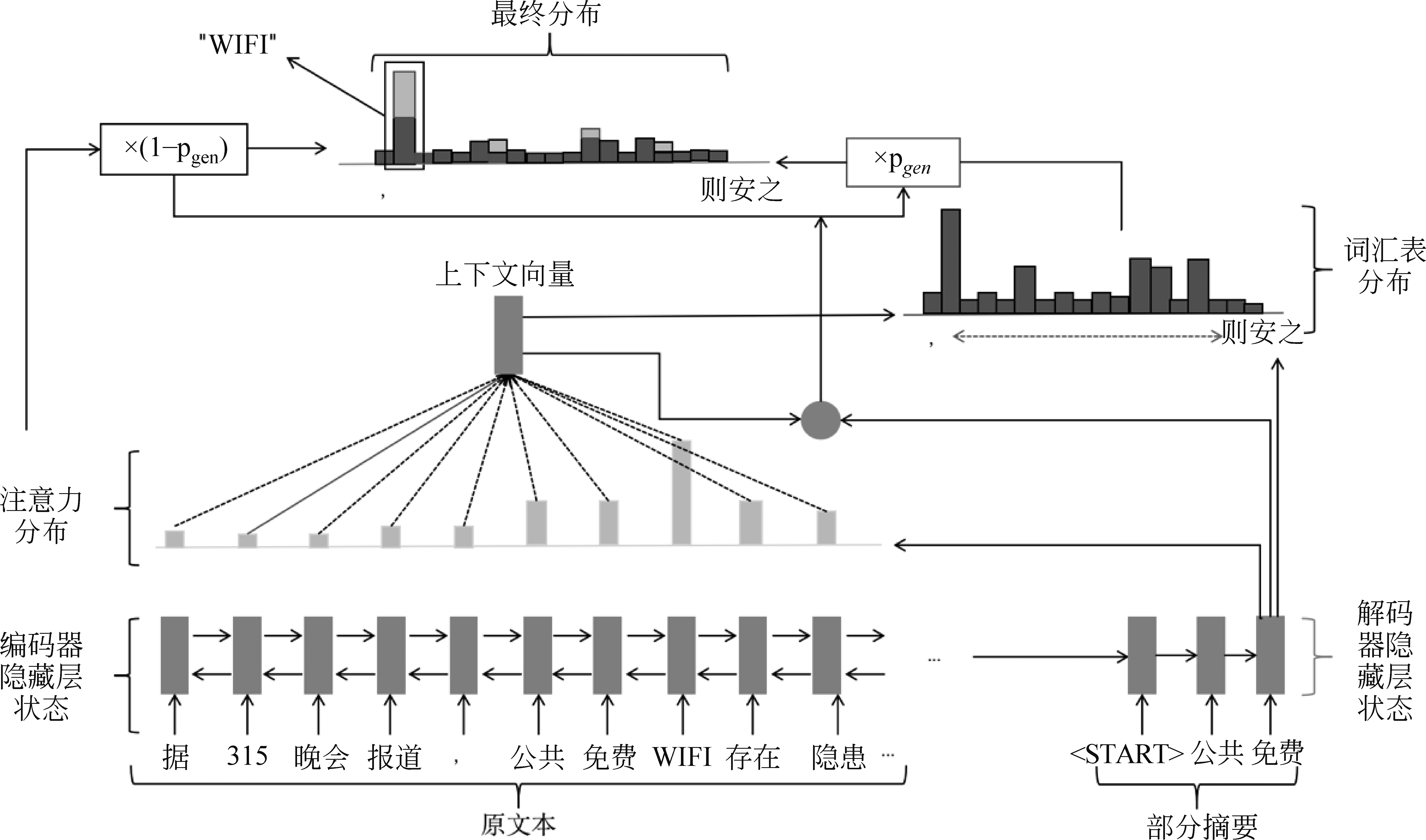
图3 指针网络模型
(8)
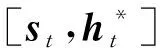
(9)
其中,wh*、ws、wx和bptr为模型可学习参数,根据计算而得的pgen来决定根据词汇表生成一个词还是从原文中拷贝一个词。进一步可以得到预测词ω的概率P(ω),如式(10)所示。
(10)
从式(10)中可以看出,当pgen=0时,加号左边项为零,此时词语需要从原文中进行复制。当pgen=1时,1-pgen=0,公式加号右边项为零,此时词语根据词汇表进行生成。
2.4 融合义原的摘要生成模型
融合义原的摘要生成模型如图4所示。考虑到义原可以准确地捕捉一个词在上下文中的具体含义,ASPM以词为单位对数据进行处理,利用SAT模型在考虑上下文信息的同时考虑了词语的义原信息,并且针对中文数据集LCSTS中的一些多义词构造新的义原对这些词进行标注,使得模型更具有针对性,得到词语在当前上下文中精确的词向量表示。将得到的词向量表示作为指针网络的输入,可以解决OOV问题,得到更高质量与高可读性的摘要。
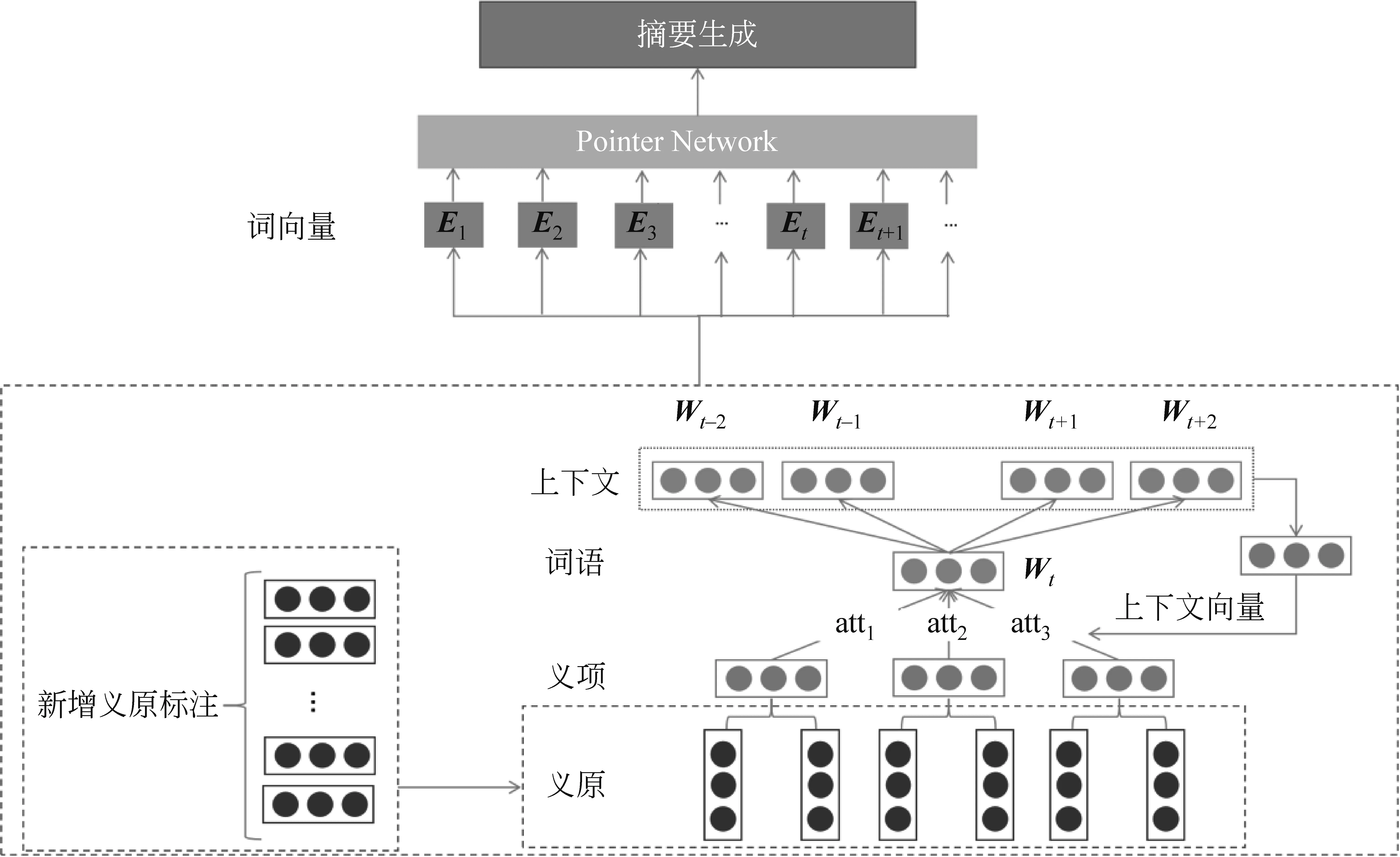
图4 融合义原的摘要生成模型
覆盖机制在损失函数中加一个惩罚项来抑制生成摘要中某一个词连续重复生成。考虑到LCSTS数据集为大规模短文本摘要数据集,ASPM未引入覆盖机制,而是通过限制解码器输出长度来避免摘要中出现大量关键词重复问题,这样做可以减少实验影响因素,以及加快模型的训练速度。ASPM中新增的义原针对LCSTS数据集中的四类词语进行了标注,如表1所示。

表1 新增义原标注
其中市类、局类、人名类词语,由于其类型的特殊性,参考SAT模型中的相应类别标注进行新增词语-义原的标注。其他类词语由于其词语的多样性,原有义原集合已不能满足要求,因此添加新的义原到原有义原集合中。通过查阅知网义原标注相关资料,新增的义原遵循“特征描述宜粗不宜细”的原则,对词语的标注遵循“涵盖词语在当前的主要意思”的原则,以此来保证与原有词语-义原标注的一致性。
表1中“市”这个类别中的词语“大同”,“义原标注”列第一个数字“2”表示“大同”这个词语有两个义项。第二个数字“2”表示第一个义项由两个义原组成,分别为“和谐”、“现象”。第三个数字“4”表示第二个义项由四个义原组成,分别为“专”“中国”“县”“地方”。其他几个类别义原标注与此类似。
3 实验分析
3.1 数据集
实验使用的数据集为LCSTS数据集,该数据集是由哈尔滨工业大学智能计算研究中心从新浪微博中收集构建而成的大规模中文摘要公开数据集。数据集中包含了200多万篇短文本及其摘要。数据详细信息如表2所示。

表2 LCSTS数据集划分
其中,第一部分包含2 389 925个中文短文本及摘要,实验把这部分数据当作训练集对模型进行训练。
第二部分包含10 666个短文本及摘要,人为进行打分标注,其中分数范围为1~5分,分数越高表明短文本与摘要的相关性越高,实验使用这部分数据集中分数为3~5分的8 685个高相关性短文本与摘要作为模型训练的验证集。
第三部包含1 106个短文本及摘要。与第二部分一样人为进行打分标注。实验使用这部分数据中分数为3~5分的725个高相关性短文本与摘要作为测试集。
LCSTS数据集三个部分包含的短文本-摘要对之间没有交集。
在实验过程中,通过观察测试集上ASPM所生成摘要与参考摘要,找出其中有主语及量词差异的摘要。通过观察对应的短文本-摘要对,对少数存在事实性错误的参考摘要进行了修改。如表3所示,增加事实性描述“缴费超15年后”。

表3 修改摘要示例
3.2 评测指标
实验使用ROUGE(Recall-Oriented Understudy for Gisting Evaluation)得分[25]作为评价指标,该指标通过将模型自动生成的摘要与参考摘要进行对比,通过统计二者之间重叠的基本单元的数目,来评价摘要的质量。ROUGE-N的计算方法如式(11)所示。
(11)
其中,{RefSum}表示参考摘要,Cmatch(N-gram)表示候选摘要和参考摘要同时出现N-gram的个数,C(N-gram)表示参考摘要中出现N-gram的个数。
3.3 实验结果与分析
本实验在Ubuntu16.04、Tesla V100的环境下进行,实验模型在Python3.6.9、Pytorch1.3.0的条件下进行训练。词汇表大小为50 000。模型超参数的设置为词嵌入维度为128,隐藏层单元数为256,批量大小为64。使用Adagrad[26]优化器优化模型参数,初始学习率大小为0.3,衰减系数为0.9,学习率每两个epoch进行一次更新。实验在生成摘要时采用Beam大小为4的Beam search[27]来寻找解码时的最优结果。通过对参考摘要长度的统计,生成摘要的最大长度限制为15个词。
论文使用如下4个模型在LCSTS数据集上进行实验。
RNNContext: RNN Context为LCSTS数据集创建之初使用编码-解码结构网络进行实验的模型,其中编码器使用RNN将输入序列转换为输入向量隐藏状态,解码器使用RNN再将这个向量隐藏状态转换为输出序列。实验使用基于汉字的方法(character-based)和基于词的方法(word-based)对数据进行处理。
PointerNetwork: Pointer Network模型为编码-解码结构与指针网络的融合,其中编/解码器均使用LSTM对序列进行处理,它可以通过一个指针开关来决定当前预测是直接从原文本中复制一个词还是通过词汇表生成一个词。考虑到LCSTS数据集为短文本数据集,因此本实验中Pointer Network没有增加覆盖机制,而是通过限制解码器生成字数来减轻重复词的出现。实验使用基于词的方法对数据进行处理。
SPM: 与ASPM模型相比,SPM(Sememe-Pointer Model)未添加针对LCSTS数据集构造的义原。作为对比实验,可以对比得到不针对LCSTS数据集添加义原以及添加新的义原后模型生成摘要质量的提升。
ASPM: ASPM模型在SPM模型的基础上,针对LCSTS数据集中词语多样性问题构建专门的义原对这些词语进行解释,使得词语-义原标注可以进一步涵盖数据集中的多义词,训练得到更能理解词语语义的词向量,进一步提高模型摘要生成的准确度。不同方法的摘要对比结果如表4所示。
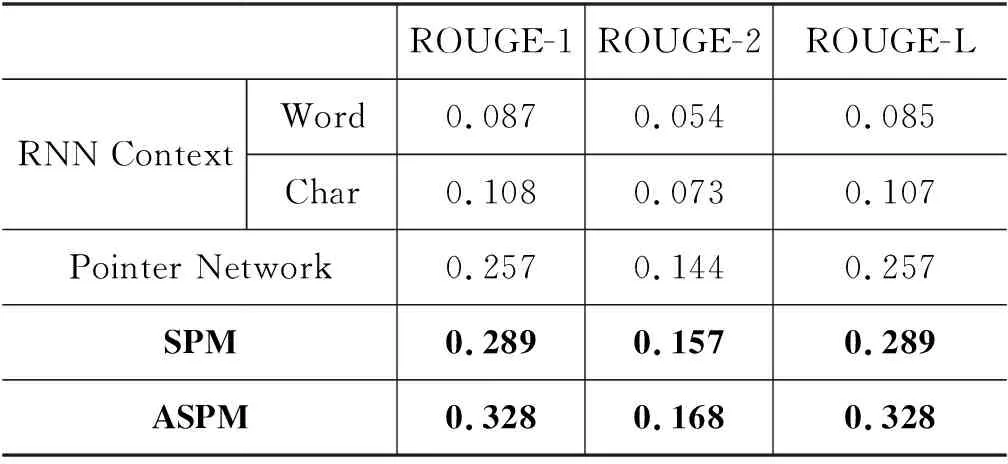
表4 实验结果对比
从表4中可以看出,RNN Context中基于汉字的方法对数据进行处理ROUGE分数要优于基于词的方法,这是因为基于词的方法由于OOV问题,导致生成摘要中包含太多UNK,而基于字的方法可以轻松解决这个问题。Pointer Network模型通过指针开关来选择从原文本中复制一个词还是通过词汇表生成一个词,即可以使用基于词的方法对数据进行处理,从而让模型能够得到更多的语义信息,同时解决了RNN Context中OOV问题,相比RNN Context模型,ROUGE分数有很大的提升。
而SPM模型在Pointer Network模型的基础上引入义原向量,在原有模型基础上对多义词进行消歧,使得模型更好地对语义进行理解,生成的摘要更加贴合于参考摘要,因而获得更高的ROUGE分数。
ASPM模型通过针对LCSTS数据集中的特定多义词构造义原,添加约575个的词语-义原标注,得到义原向量后与Pointer Network融合取得了高于SPM模型的ROUGE分数,更加表明了添加义原向量对模型理解语义的重要性。同时对深度学习模型在其他数据集上得到更加精确的语义与生成可读性更高的摘要,起到了一定的促进作用。
图5为ASPM模型与Pointer Network模型训练过程中的epoch-loss曲线图,从图中可以看出ASPM模型的准确率要高于Pointer Network模型,特别是在第8轮epoch之后,效果更加明显。这说明使用义原向量可以帮助模型更好地理解语义,使得生成的摘要更加准确,更具有可读性。
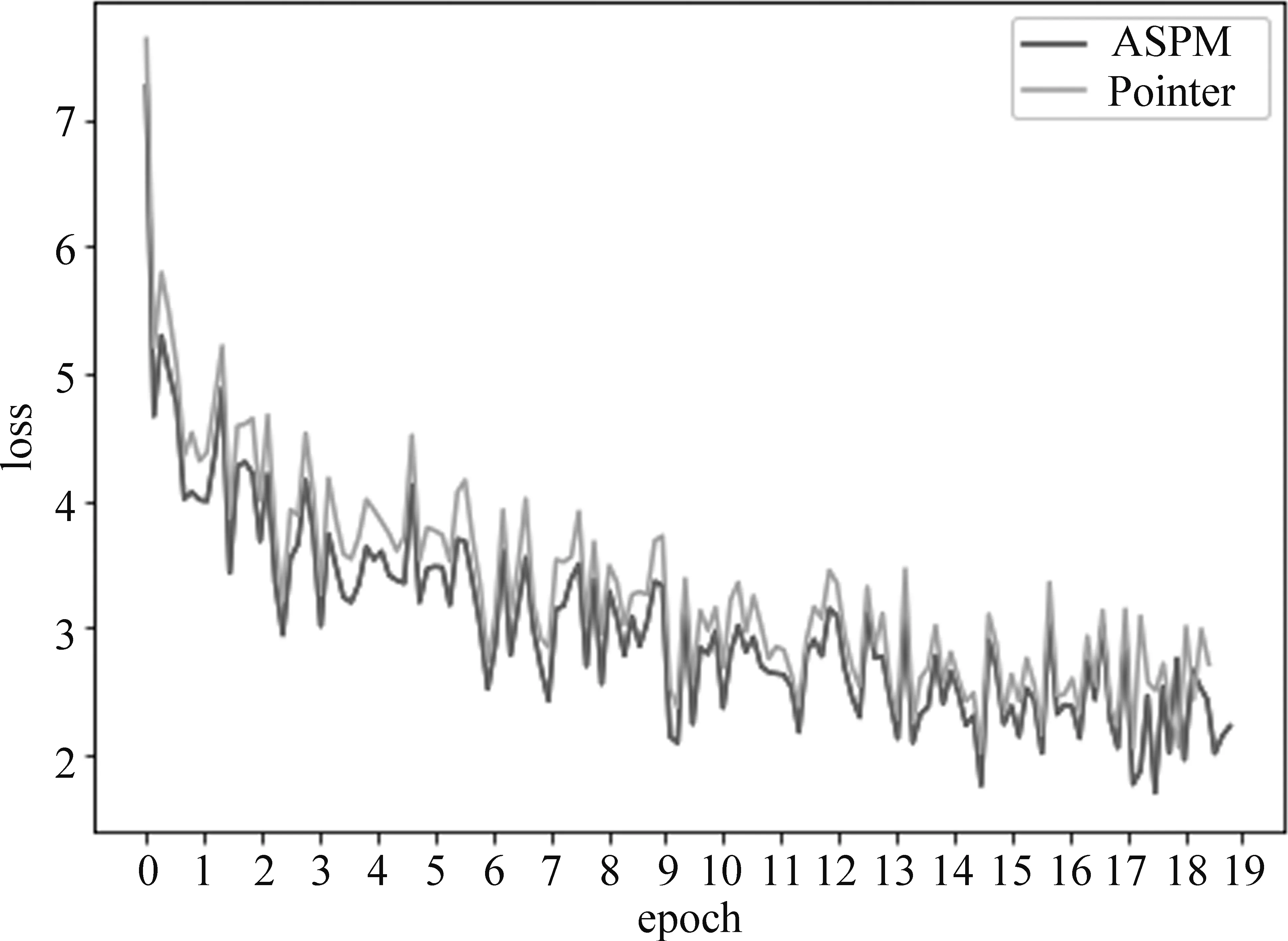
图5 实验loss值
表5为实验选取的测试集中Pointer Network模型与ASPM模型分别生成摘要的一个例子,从表中可以看出,Pointer Network模型生成的摘要已经可以表达出文本的大意,但是还缺乏对时间的表示。而ASPM模型生成的摘要则捕捉到了时间信息,很好地总结了文本所要表达的意思。

表5 摘要生成实例
4 总结与展望
本文提出一种融合义原的中文摘要生成模型,在Pointer Network模型的基础上引入义原向量,使得模型既可以解决以词为单位对数据进行处理时出现的OOV问题,又可以更好地理解语义。并且通过增加新的义对LCSTS数据集中的四类约575个词语进行标注,训练得到更加精确的词向量表示,帮助模型生成更高质量与高可读性的摘要。实验结果表明,本文的针对数据集构建义原向量的方法可以大大提升以词为单位进行数据处理的摘要生成模型的效果。这对以词为单位进行数据处理的摘要生成模型的发展以及针对不同数据集的处理有一定促进作用。
本文没有研究添加义原的不同类型对模型生成摘要的影响,因此模型还有一定的提升空间,针对不同数据集添加何种类型的义原更有助于提升生成摘要的质量是下一步研究的目标。
