基于Res-UNet 的风电机组功率曲线建模
2022-08-02蒋世宇
蒋世宇,谭 文
(华北电力大学 控制与计算机工程学院,北京 102206)
0 引言
风力发电规模在我国正不断增长[1]。为了实现对风电机组进行故障诊断及状态监测,通常需要采用数据采集与监视控制系统(supervisory control and data acquisition,SCADA)的运行数据对风电机组进行功率曲线建模。
常规建模方法往往直接将机组运行数据组为模型的输入,通过数值上的关系搭建模型。这些数据往往存在噪声较大、异常数据点较多的问题;同时,由于受实际运行中的弃风限电等因素影响,通过这些数据所得到的功率曲线图像往往容易呈现出多条水平带状分布[2,3]。因此在建模前,使用合适的清洗算法对数据进行清洗是必须的过程。在时间跨度大、天气变化大的情况下,不同机组、甚至同一机组的数据差距都较大,这就造成算法中的超参数往往需要反复选取。
文献[4]使用了不同原型函数对功率曲线进行单变量建模。文献[5]对SCADA 数据系统中不同变量的物理意义进行分析,并选取部分变量进行多变量建模。文献[6]根据变量投影重要性指标进行了变量的选取。文献[7]使用了稀疏自编码器自动对输入的多个变量进行了特征提取与降维。文献[8]建立了概率功率曲线模型。上述这些方法均依赖于合适的数据清洗算法,尤其是对于运行时间长、异常数据点多的风电机组。
文献[9]提出对数据进行了网格化处理的方法,结果在去除了异常数据点的同时也去除了部分正常数据点。文献[3]861-863中的聚类算法增大了数据处理的难度与复杂程度。这些方法在使用时,对不同的数据集需重新训练,对不同季度、不同机组的数据集都要求使用新的模型参数。
文献[10]使用了基于图像处理的方法对功率曲线进行建模。由于其使用的网络较浅,在面对时间跨度大、数据点较多的情况时无法正确对功率曲线进行建模。为使模型能够适应风电机组所处的多种状态[11],应当建立合适的训练样本集并建立更深的网络。
本文分析了可以表征风电机组实际运行过程的训练图像样本的生成方法,提出基于残差块的Res-UNet 模型对功率曲线进行建模;分析了该模型在深度网络上的优越性及训练数据集对不同工况的覆盖;将模型在不同机组数据集上的计算精度与常规模型进行了比对。
1 训练样本生成
因模型以功率曲线的图像作为输入,所以训练时需要大量的样本,包括分布在功率曲线周围的大量数据点以及功率曲线本身。由于所需大量不同特性的机组数据在实际中往往难以获取,所以需要生成足以模拟其图像特征的训练样本。
1.1 点密集样本
点密集样本如图1 所示。图1 中,平行四边形所围区域对应正常工况下的数据点,矩形为带状分布数据点,圆形区域代表随机噪声。
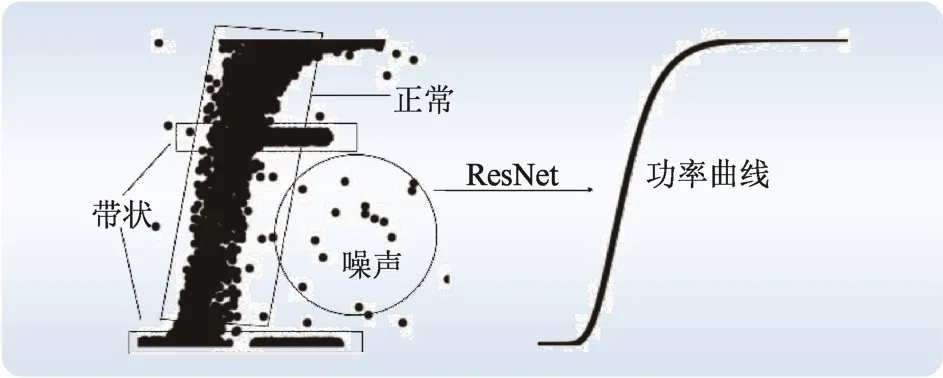
图1 点密集样本示意图Fig. 1 Schematic diagram of point dense samples
文献[4]2139-2140使用了一列具有随机参数的双重指数函数(DE)以及调节双重指数函数(ADE)来模拟实际功率曲线建模;且根据参数不同,可以生成任意多的功率曲线样本。根据建模中参数变化范围,选用的函数表达形式如下:
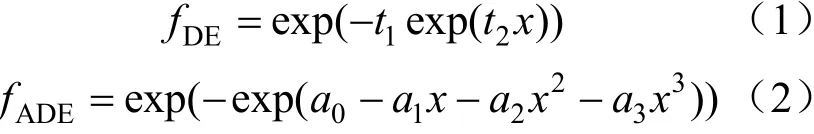
式中:t1~U[10,50];t2~U[-15, -8];a0=5;a1~U[-20,20];a2~U[-15, 10];a3=15;U[a,b]表示在a和b之间的均匀分布。
文献[2]97-99给出了正常工况下数据点所具有的形式。根据文献[3]860-861中对异常情况下数据点的分类,使用如下公式进行数据点的生成:
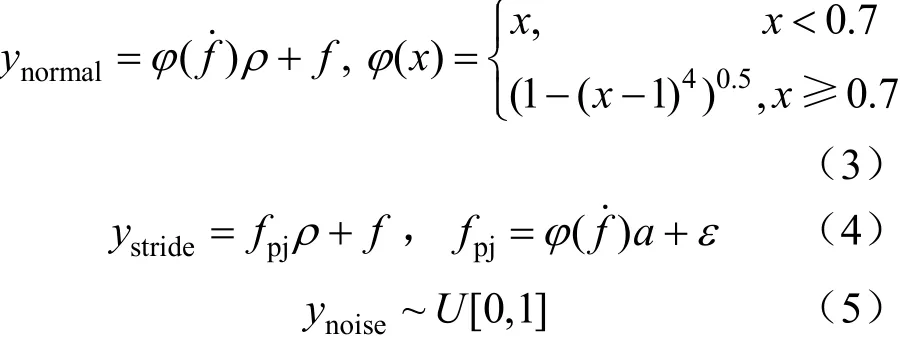
式中:ρ~N(0,1);f表示由式(1)或式(2)给出的函数;f˙为其归一化后的导数;a~U[0.1, 0.3];ε为任意小于0.01 的数。
如图1 所示,将由式(3)~(5)生成的数据点绘制成散点图作为网络的输入,同时绘制与之对应的功率曲线作为输出。
1.2 点稀疏样本
数据采集设备功能缺陷以及传输通道检修、设备故障停机等因素,会造成风电监测数据的缺失[12]。为使模型在数据点较少的情况下依然具有较良好的效果,需要对输入样本进行图像增强处理,构造点稀疏样本。具体流程如图2 所示。
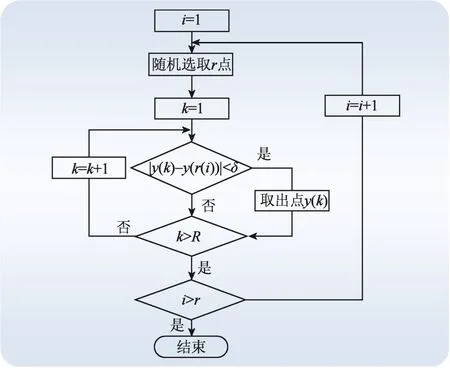
图2 构造点稀疏集流程Fig. 2 Process of points sparse set construction
图2中:r的大小根据所构造的3 种不同数据点及稀疏效果的要求而定;r(i)代表选取的第i点在原数据点中的标号;R表示剩下的原始数据点个数,其随着迭代不断变化;δ参数根据稀疏效果选取,默认值为0.005。
由式(4)可知,即使横坐标变化较大,对应的纵坐标变化也很小;因此,根据该算法构造点稀疏集时,带状数据点筛选参数应使得数据点尽量少,甚至可以只选取一列随机点列。
图3所示为仅选取个别点的效果。从图3 可以看出,带状分布的数据点在图上仍呈现较连续、面积较大的带状区域。
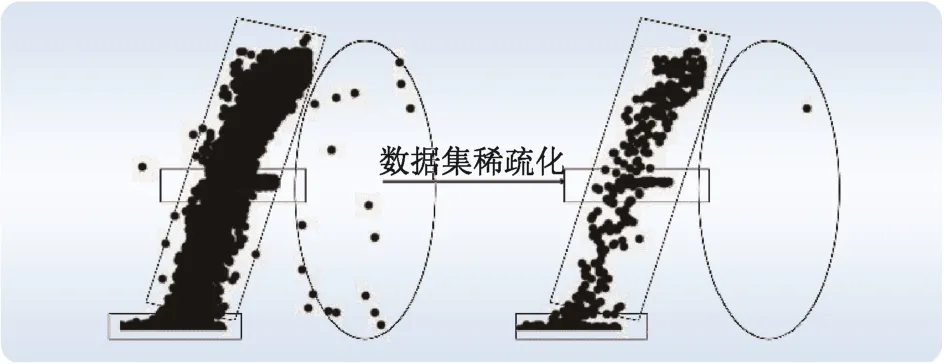
图3 稀疏化效果Fig. 3 Effect of sparsing
2 Res-Unet 功率曲线建模
2.1 U-Net
运用U-Net 将功率曲线从众多数据点构成的图像中分割出来,即得到功率曲线的图像。
图4为U-Net 结构示意图。图4 中,网络的左部为编码器,其各个卷积层将输入图像的空间信息层层抽取并转化为通道信息;图片尺寸越来越小,而通道数相应成比例增加。在网路的超参数选取上,每个卷积层中使用了大小为3×3 的卷积核;设置每层通道数增加一倍,即步幅为2,且每层都有最大池化层以提高网络的鲁棒性。
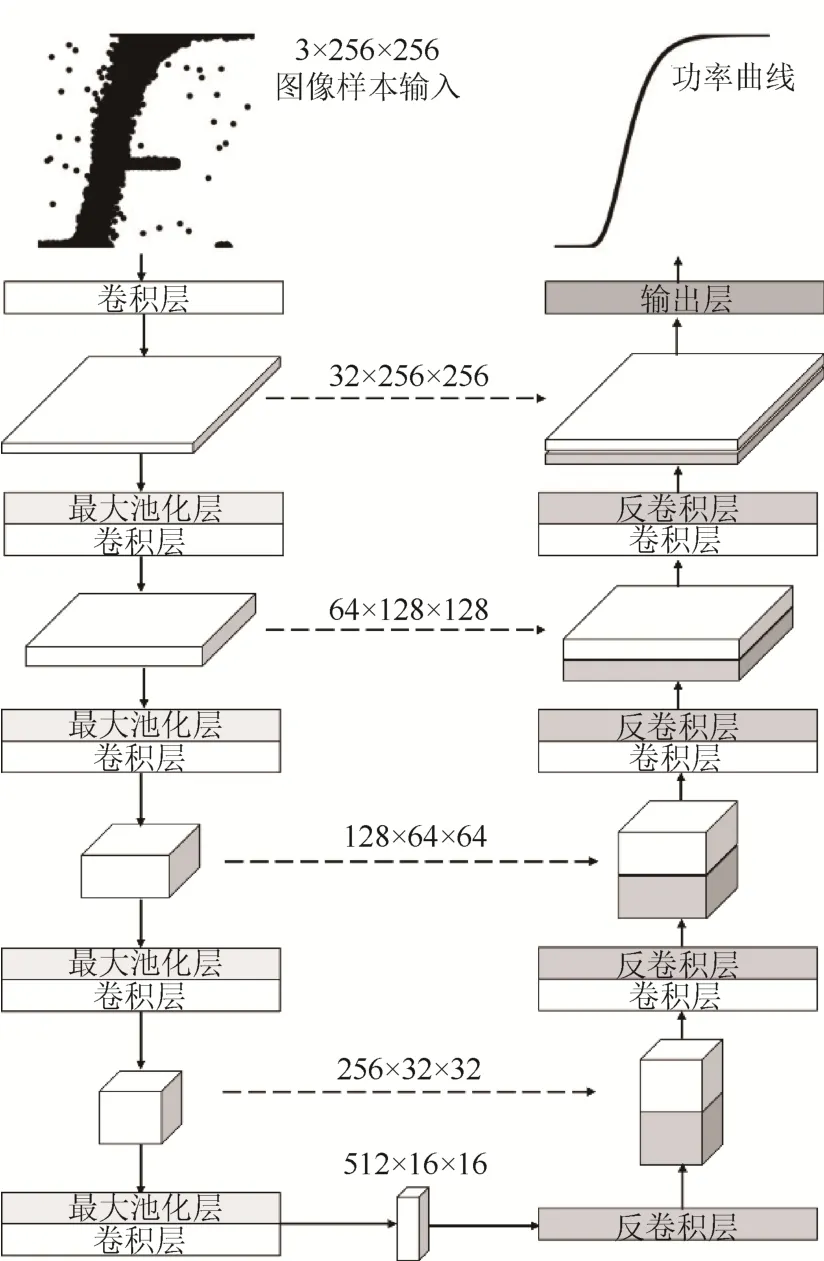
图4 U-Net 结构示意图Fig. 4 Schematic diagram of U-Net structure
网络采用ReLu 函数作为非线性激活函数。网络的右部为解码器,与左部对称。采用同样超参数的卷积层以及转置卷积层,将编码器提取的特征进行解码还原成空间图像,从而得到期望的功率曲线图像输出。
2.2 Res-UNet
图4所示的网络结构不论从深度及输入大小方面来看都较小。
为了增加功率曲线建模的精度,需要考虑增加模型的复杂程度。如果考虑增大图片的分辨率使得每个像素可准确表征SCADA 数据中的每一个点,或者不断增加网络的深度,那么不仅会造成训练时间、计算消耗上的指数级增加,还容易出现梯度消失等问题。
为了解决上述问题,使得网络可以准确提取样本与功率曲线图像之间的关系,使得模型可以作用于不同风电机组,在U-Net 的基础上引入残差网络结构[13],如图5 所示。
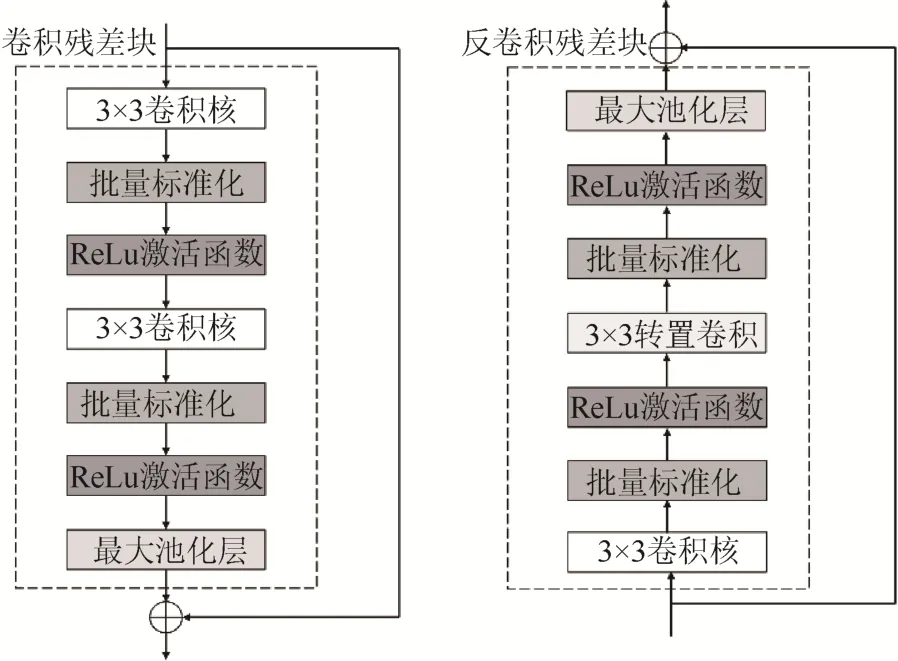
图5 残差块运算流程Fig. 5 Operation process of residual block
残差块之间直接连接的优点是:在误差反向传播时,不仅传递了梯度,还包括了运算之前的梯度;相当于加大了梯度,减小了梯度消失的可能性。同时,在进行卷积运算过程中,每一层的卷积仅仅提取了图像的一部分信息;这意味着如果需要训练更深的模型来提高精度,则层数越深丢失的信息反而越多,只能提取一小部分特征;若块与块之间直接连接,则意味着在每个块中加入了上一层的全部信息,从而使得深层的网络依然能够获取图片的全部信息,进行完整的特征提取,从而获得更高的精度。
将图4 中的卷积层以及转置卷积层替换成图5 所示卷积残差块、反卷积残差块。需注意,进行加法运算的张量大小应该相匹配。如果残差块中设置了大于1 的步幅,右侧连线处也相应添加总步幅相同的卷积或转置卷积层。卷积块与反卷积块之间的长连接既可以接在池化层也可以在其后。本文将池化层一并纳入残差块。
残差块的引入使得网络每一次训练都是建立在之前已有的训练结果的基础之上,即块之间的直接连接等价于一个较小的网络。训练过程中,小网络的参数会被优先训练好,之后进一步训练整个网络。
图5中还引入了批量标准化,实现形式如下。
固定每个批量(Batch)中的均值与方差:
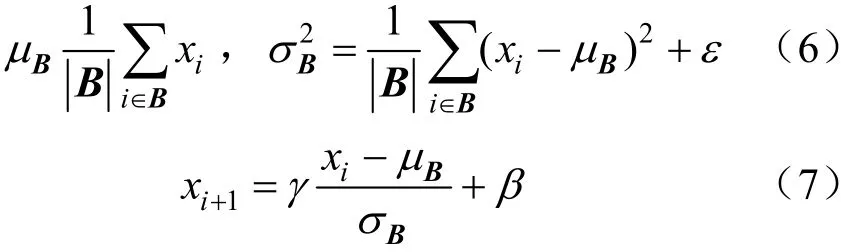
式中:γ和β分别代表需要学习的均值和方差,其本身等价于一个线性变换,即产生了随机偏移和随机缩放。其目的是:在每个小批量中加入噪音,使得模型尽可能记住样本所具有的特征,加快收敛速度,并且不改变精度。
残差块的加入可以使得训练的网络更深,输入样本的分辨率更大。在文献[10]中所使用的U-Net为5 层,但事实上可以根据需要加深网络,以提高精度。
通过实验,发现样本图像中功率曲线特征较明显,所以考虑使用式(8)中的均方误差作为损失函数,并使用随机梯度下降法进行优化。
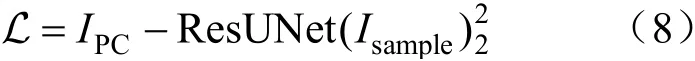
2.3 功率曲线图像映射
由Res-UNet 网络所得到的输出为256×256 的矩阵图像,如图6 所示。
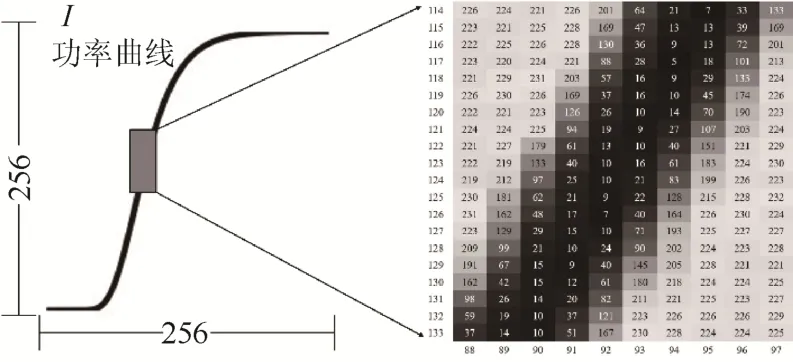
图6 功率曲线图像风速矩阵Fig. 6 Matrix wind speed of power curve image
为了能得到功率曲线的数值表达,需要对图像进行映射。取矩阵图像256 列中RGB 值小于100 的列,考虑建立n次多项式满足:
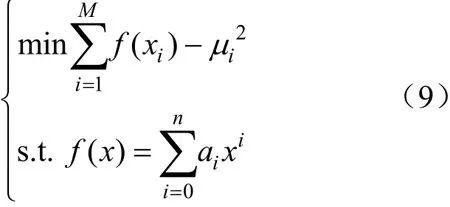
多项式阶次n可以自由选取,而式(9)中的M为选出的列数,μi为每列中黑色区域较明显部分的平均值。
由于黑色部分RGB 值较小且相邻数值的大小变动不大,所以选取点的过程为:首先选出该列最低值,从该位置开始上下移动;如果上下之间的RGB 值变动大于30+ε则不再继续,选取点过程结束。ε为一较小整数,可根据实际适当选取。
龙格现象容易出现在多项式次数较高的情况下。在功率曲线的切入风速前及额定风速后部分,曲线存在剧烈抖动。而据参考文献[10],这2 部分功率应保持定值即零功率和额定功率;即使在实际机组的SCADA 数据中,该部分也仅在噪声干扰下略微变动。由于额定功率基本出现在225~230 行内,零功率基本出现在30±2 行内,可求出零功率和额定功率为使用牛顿法求出f-frated的根xrated及f-fzero的根xzero,最终得到的功率曲线为:
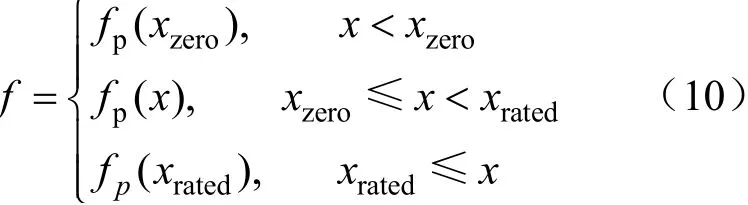
如图7 所示,使用Res-UNet 得到的经过映射后的曲线具有良好的精度。由于选用了分段函数的形式,避免了在风速较低及较高时出现的抖动,曲较平滑。

图7 建模结果Fig. 7 Result of modeling
3 案例分析
实验计算设备:主机AMD Ryzen 9 5900HX CPU,NVIDA GeForce RTX3080 Laptop GPU,内存为32 GB。
实验数据条件:实验中所用数据集及风场信息如表1 所示。除安徽及内蒙锡盟的数据集外,其余数据集覆盖了4 个季度。本实验数据集的特点是,时间跨度大且数据点个数多、噪声大。
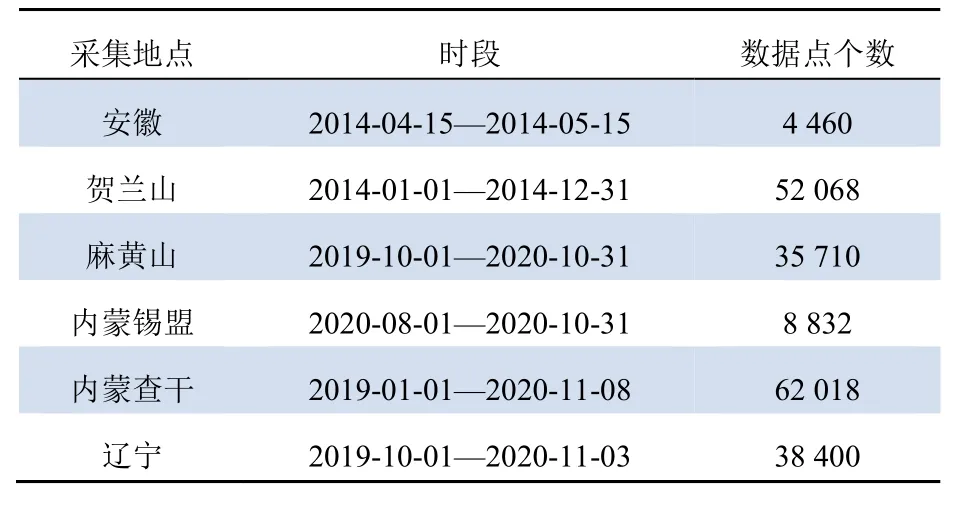
表1 数据集信息Tab. 1 Description of datasets
将Res-UNet25的建模结果与文献[4]及文献[10]进行对比,结果如图8 所示。
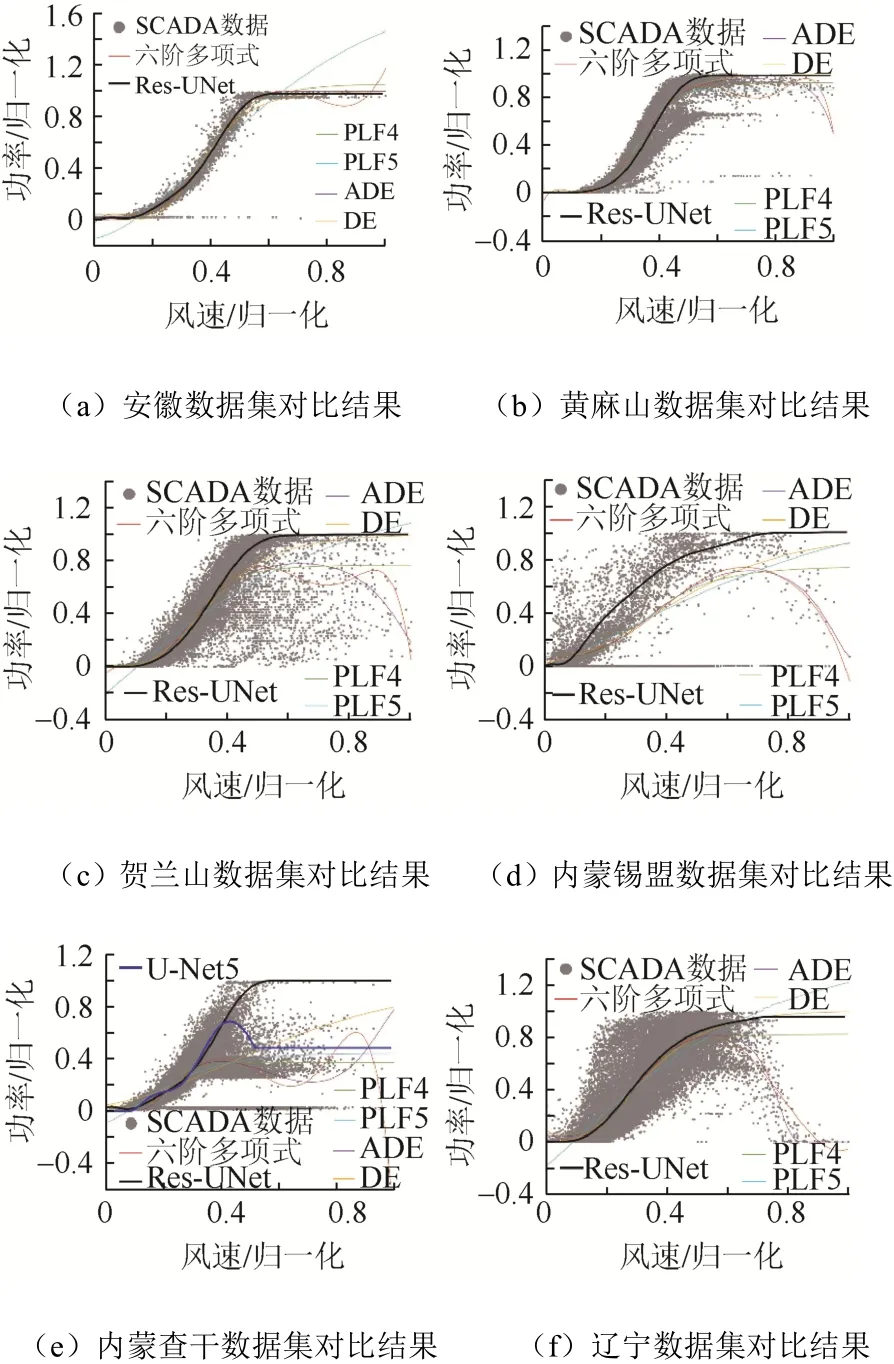
图8 多种方法建模功率曲线Fig. 8 Power curves of modeling via various ways
从图8 可以看出,在数据集中的数据点个数多、异常数据点密集且未经过数据预处理的情况下,根据高次多项式以及经验公式得到的功率曲线无法良好地拟合数据点。
Res-UNet 模型不依赖数据的预处理,且由于采用分段函数的形式,在额定功率风速段能保持定值。
当限功率运行点的数量较多时,使用5 层的网络也无法得到表征机组正常工况下的功率曲线,如图8(e)所示。25 层的Res-UNet 层数增加、网络变深,具有更强的拟合能力,即使在限制功率运行的数据点较多、异常数据点分布较广的情况下依然能够提取正常工况下的特征,得到正确表征机组额定功率运行下的功率曲线。
为验证与传统方法相比,Res-UNet 在不依赖对数据集进行数据处理方面的优势,分别采用文献[5]中的高斯过程以及文献[14]中的LSTM 模型对原始数据集及经过处理的数据集进行建模,使用式(11)平均绝对值误差百分比(mean absolute percentage error,MAPE)来计算功率曲线建模的数值精度。验证结果如表2、图9 所示。
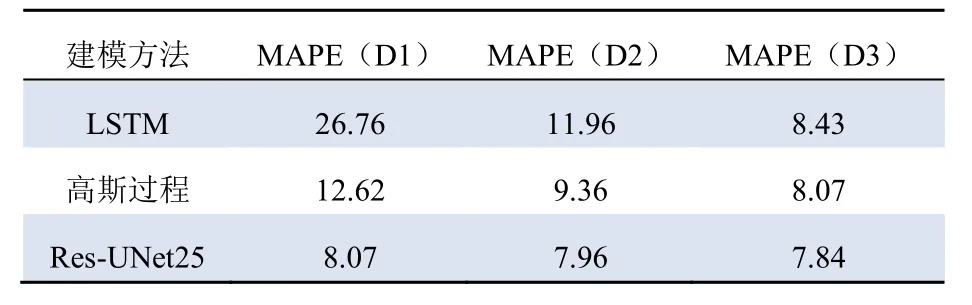
表2 MAPE 对比Tab. 2 Comparison of MAPE %
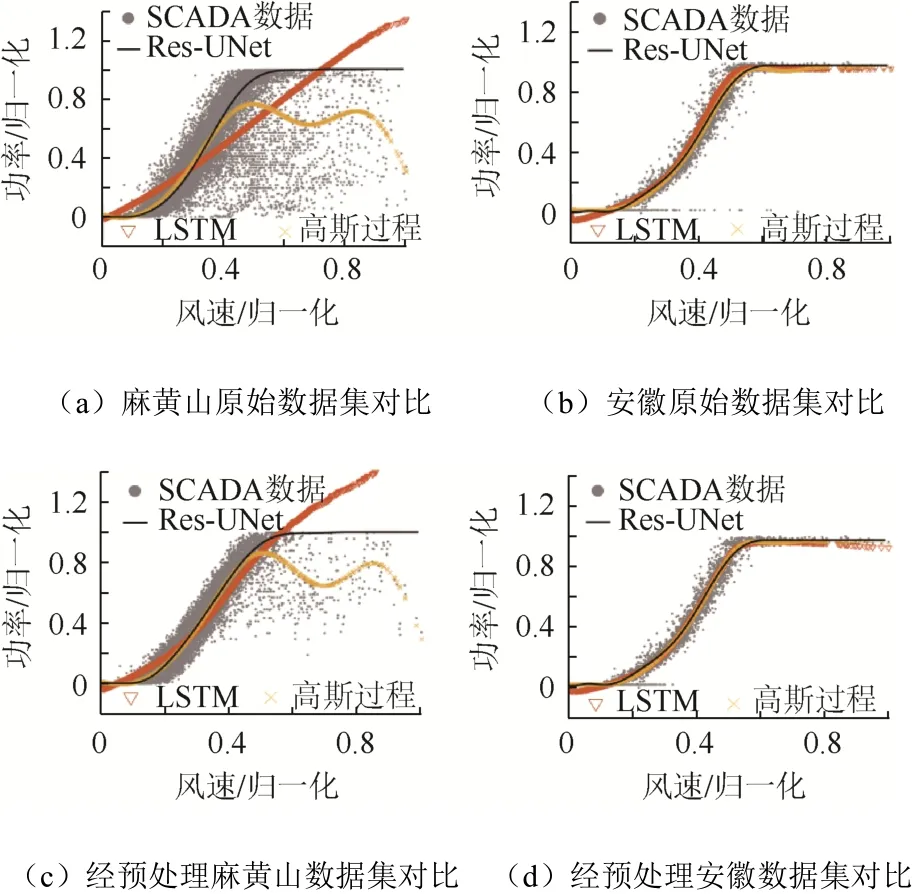
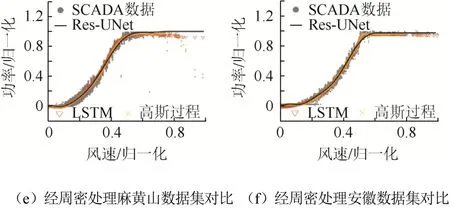
图9 3 种建模方法对比Fig. 9 Comparison of three ways of modeling
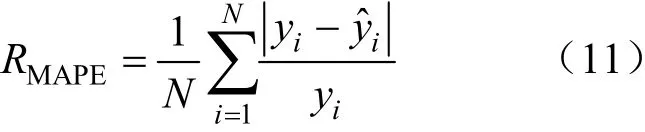
式中:N为数据点个数;yi为实际功率值;模型功率曲线对应值。
表2中使用大小为35 710 的麻黄山风场数据集,与图9(a)(c)及(e)相对应;其中D1 表示原始数据集,D2 表示使用文献[15]中的方法对数据进行了简单预处理,D3 表示使用文献[9]的方法去除了绝大部分异常数据点后的数据集。图9(b)(d)及(f)则使用了数据集大小为4 460 的安徽实验风场数据。
从图9(b)(d)(f)可以看出,当数据集较小、时间跨度短且异常数据点少时,3 种方法均可在未经过数据处理的情况下取得较理想的建模效果。
LSTM 模型预测出的功率在曲线末段偏离额定功率,呈现下降趋势。这是由于LSTM 模型倾向于将前时刻的真实值作为下一时刻的预测值,而该数据集在额定功率段数据点较少且随着风速增大功率下降,于是导致了预测的偏差。
从图9(f)可以看出,即使经过了周密数据处理,由LSTM 得到的曲线在末段仍然偏离额定功率;而Res-UNet 的输出使用了式(10)分段函数的形式,使得曲线在该段能够保持额定功率,曲线平滑不发生偏移。
数据集D1 时间跨度大,异常数据点多。此时,在未经过数据处理的情况下,LSTM 与高斯过程建模的结果精度较低。由于异常数据点的影响,LSTM 模型对前时刻正确数据点输入进行了错误的修正,导致结果偏离正确的值。
从图9(a)可以看出,LSTM 由于错误修正使得输出结果几乎平分了异常数据点与正常数据点。在对D1 进行简单数据预处理后得到数据集D2 上,异常数据点数量明显减少,因此LSTM 建模精度上升,MAPE 从26.76%下降至11.96%。
使用高斯过程建模时,由于仅仅考虑了观测数据带有白噪声,而文献[15]的预处理方法可近似看成低通滤波器,这使得高斯过程在数据集D1、D2 上建模效果差距不大。
在数据集D3 上,3 种方法建模精度均较高;但LSTM 与高斯过程建模在额定功率段无法保持定值输出,在曲线末段偏离额定功率。Res-UNet的训练样本输入考虑了各种情况的异常数据点,使得网络在数据集未经过处理的情况下仍然可以得到高精度的建模结果:在各种原始数据集以及各种数据处理方法情况下,其MAPE 建模精度几乎保持不变,优于LSTM 以及高斯过程建模得到的结果。
Res-UNet 在训练过程中引入了点稀疏样本,使得其在输入数据集很小、数据点分布稀疏的情况下依然有效。图10 所示为使用安徽实验风场数据集中100 点、500 点、1 000 点及全部数据点建模得到的结果。从图10 可以看出,Res-UNet 在各种情况下得到的建模结果几乎是一致的,表明即使在输入的数据集较小,数据点较稀疏的情况下Res-UNet 依然可以得到正确的建模结果。
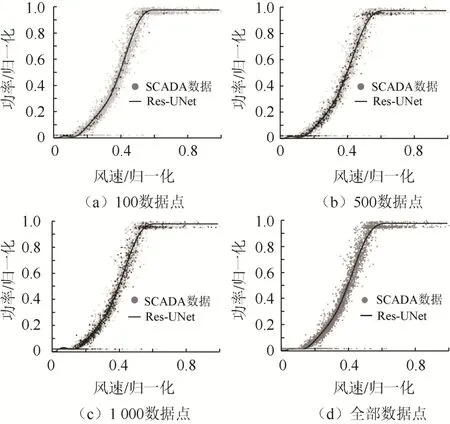
图10 稀疏数据集输入Fig. 10 Input with sparse datasets
综上所述,基于Res-UNet 的功率曲线建模方法是一种有效可行的建模方法,其不依赖对数据的处理,对不同数据集无需重复训练,可以满足实际应用中对功率曲线精确度、运算高效性和普适性的需求。
4 结论
通过考察风电机组数据散点图与功率曲线之间的关系,建立了以算法生成的模拟风电机组数据的散点图为输入、以风电机组功率曲线图像为输出的Res-UNet 模型,并通过像素映射求出了功率曲线数值表达。
(1)该方法不依赖事先对SCADA 运行数据繁复的清洗、处理,面对噪声大、样本多的数据集依然有良好的效果。
(2)残差块的引入使得算法可以快速搭建更深的模型,这有利于通过处理时间跨度大、异常数据点多的数据集成功得到合适的功率曲线。
(3)对于不同的数据集,Res-UNet 不需要重复训练,适用于不同季度、不同机组的数据,具有高效性、普适性。
