基于卷积神经网络的乳粉掺杂物拉曼光谱分类方法
2022-08-02邵帅斌刘美含石宇晴郝朝龙
邵帅斌,刘美含,石宇晴,郝朝龙,韩 宙,张 伟*,陈 达*
(1.中国民航大学安全科学与工程学院,天津 300300;2.中国民航大学 民航热灾害防控和应急重点实验室,天津 300300)
一直以来,乳制品因其优越的矿物质组成、生物利用度、可消化性和生物价值而受到消费者青睐。乳制品是人体摄取蛋白质、维生素、氨基酸和矿物质等营养物质的极佳来源,其中婴幼儿、哺乳期妇女和老年人更是乳制品的重要消费者。迄今为止,乳粉作为受欢迎的乳制品,占乳制品消耗总量的80%以上。因此,乳粉质量安全一直是全球人民共同关注的问题。随着国民对乳粉需求量的增加,在乳粉中添加营养强化剂是提高乳粉营养价值和增加经济利润的常见做法。然而一些不良厂商为降低生产成本,掺入过量杂质(如多余的葡萄糖、淀粉、小麦粉、麦芽糖糊精、滑石粉、乳清粉)校正蛋白含量或密度值,极大降低了乳粉的营养价值,甚至可能对人体健康造成严重危害。“大头娃娃”“三聚氰胺”“皮革奶”“激素门”等频繁发生的婴幼儿配方乳粉安全事件表明,相关部门虽然为乳制品的管理制定了法规政策,但由于硬件设备、监管力度和执行力度有限,无法达到满意的乳粉质量安全管控效果。GB 10765ü2010《婴儿配方食品》规定,乳粉中的杂质含量必须小于1.2%,但是现行GB 5413.30ü2010《乳和乳制品杂质度的测定》检测方法并不能满足数以百万吨的乳粉掺杂筛查需求。因此,如何对乳粉掺杂问题进行快速、准确的科学评估仍是亟待解决的重大食品安全问题。
在实践中,乳粉安全检测的方法主要分为定向筛查和非定向筛查两种。其中定向筛查主要是针对已知掺杂物进行定量分析,通常用于判断所检测化合物是否超标。目前,常见的定向筛查方法有高效液相色谱法、气相色谱-质谱联用法、生物化学分析方法等,虽然灵敏度高,但需要繁琐的样品前处理过程,对检测人员和仪器有较高要求,不适于乳粉安全的大规模快速检测应用。由于定向筛查方法仅针对已知危害物质制定,无法识别未知化学掺杂物,在乳粉掺杂筛查的应用范围有限。针对定向筛查的缺点,非定向筛查技术应运而生。非定向筛查结合动态识别或大数据库分析策略,能够从复杂、变动的乳粉数据中准确提取真实性本征信息,有效地解决了传统筛查技术无法全面覆盖掺杂物质的问题,成为掺杂筛查领域的最新技术发展趋势。
传统拉曼光谱非定向筛查技术需要合适的数据预处理手段才能获得光谱特征,增加了有效信息泄漏的风险,同时也极大增加了算法复杂度。因此,亟需发展一种预处理与计算一体化的拉曼光谱建模方法,以此提升拉曼光谱在乳粉安全筛查中的应用范围。近年来,卷积神经网络(convolutional neural network,CNN)以其高效的特征提取能力获得业内的广泛认可。它是人工神经网络和深度学习技术结合产生的一种新型人工神经网络方法,已经广泛应用于特征提取相关研究。目前,将CNN应用于拉曼光谱检测技术的研究引起了学者们的兴趣。Guo Zhiqi等提出一种利用人血清拉曼光谱结合深度学习模型诊断乙型肝炎病毒感染的新方法,并通过多尺度融合卷积运算保留和融合多尺度特征。Zhu Jiaji等提出一种表面增强拉曼散射与CNN相结合的方法,能够快速现场鉴定茶叶中农药残留。此外,CNN在雌激素粉末拉曼光谱分类、土壤近红外光谱分类、水果品质检测、熟食中的异物检测和农作物品质及遥感图像分类方面也表现出优异的分类性能。针对原始数据少,网络学习效果差等问题,李灵巧等利用深度卷积生成对抗网络对数据进行扩充,提高了网络的特征学习能力,但是该方法虽然扩充了数据集,但是扩充后的数据集并不能充分代表原始数据集,可能会影响网络对真实样品的分类能力。
本研究提出一种基于CNN的乳粉掺杂物拉曼光谱分类方法,该方法可以直接将原始拉曼光谱数据作为网络的输入,借助其内嵌的卷积与池化层处理能力,在准确提取不同掺杂物光谱的原始数据特征的同时,构建相应的CNN模型,实现对未知乳粉掺杂物的精准高效识别。在建模过程中,利用拉曼光谱仪快速采集足量乳粉样本的光谱数据,以此为CNN的输入,并重点讨论初始超参数对模型训练的影响。与此同时,针对现有光谱预处理方法的缺陷,以离散小波变换为基础,选择基线校正和降噪处理相结合的预处理方式,研究光谱预处理对网络模型的影响。结果表明,CNN同时兼备光谱预处理与多元校正计算的一体化能力,其模型预测结果有效满足实际分析需求,极大降低了乳粉掺杂拉曼光谱分析的技术难度,并有望拓展到其他食品的掺杂识别应用中。
1 材料与方法
1.1 材料
标准品:60 种市售脱脂乳粉;掺杂物:麦芽糖糊精(分析纯) 上海麦克林生化科技有限公司;特级小麦粉益海嘉里金龙鱼粮油食品股份有限公司;滑石粉 济南良丰贸易有限公司;植脂末、乳清粉 雀巢(天津)有限公司;一级淀粉 宁夏来裕淀粉有限公司。
1.2 仪器与设备
XW-80A涡流混合仪 上海沪西分析仪器厂有限公司;BIOS-105T-304GS型二维位移平台 日本Sigma Koki公司;便携式拉曼光谱仪由实验室自主研发。
1.3 方法
1.3.1 样品制备
将掺杂物分别混合入脱脂乳粉中,每个样品20 g,使用涡流混合仪振动5 min,以确保乳粉和掺杂物均匀混合,制备6 种掺杂物质量分数0.3%的标准掺杂样品。
1.3.2 光谱数据采集
拉曼高光谱采集系统由二维位移平台、便携式拉曼光谱仪和集成控制模块组成。拉曼光谱仪激发源波长785 nm,激光器总输出功率100 mW。光谱仪采用64h1 024像素的面阵CCD检测器,波数范围200~2 200 cm,实验中设置光谱仪积分时间为600 ms,采集区域面积为(11h30)mm,控制二维位移平台步长为0.3 mm,每种掺杂样品采集1 100 组拉曼光谱数据,共采集6 600 组拉曼光谱数据。此外,利用光谱仪分别采集6 种标准掺杂样品(质量分数0.3%)的拉曼光谱,每种标准掺杂样品采集100 组拉曼光谱数据,用于检验方法的可靠性;额外采集600 组不同掺杂物含量的乳粉样本作为独立验证集,以验证算法的有效性和可靠性。
1.3.3 光谱数据预处理
脱脂乳粉的原始拉曼光谱存在荧光背景和噪声,使用传统拉曼光谱分类方法时,荧光背景和噪声会干扰掺杂物的特征提取。为了探究光谱预处理对CNN训练结果的影响,需要选择合适的预处理手段对原始拉曼光谱进行降噪和去背景。考虑到高光谱数据量较大,预处理算法需要有较快的处理速度,因此,本实验采用离散小波变换(discrete wavelet transform,DWT)方法对获得的原始拉曼光谱进行处理。DWT可将光谱分成不同频率的信号,通过信号重构去除低频背景和高频噪声,实现特征光谱信号的保留,具体表达式见式(1)、(2):

式中:表示小波基函数;表示分辨率;表示时域因子;表示时间;WT表示信号的小波变换;表示原始信号;表示滤波器长度。
采用symmlets小波基函数,选择DWT的小波函数sym5和分解尺度7对所有原始光谱进行处理。
1.3.4 CNN搭建
CNN是一个多层非全连接的神经网络,在正向传播过程中可利用卷积层和池化层相互交替学习提取原始数据的特征,反向传播时又可利用梯度下降算法最小化误差函数调整参数,完成权值更新。本研究将改进的AlexNet网络应用于乳粉掺杂物拉曼光谱的分类。为重点训练分类,需要减小特征提取部分的波动,故将网络最后一个全连接层的偏置学习率因子和权重学习率因子全部调整为20;较大的初始学习率有可能使损失函数离最低点较远,故本网络模型统一设置学习率为0.000 1;此外,由于每条光谱数据的最大值和最小值相差较大,数据的特征分布范围较大,导致网络在训练过程中梯度下降缓慢,不利于模型收敛,故使用Matlab软件将一维光谱数据绘制成二维图像,并将二维图像大小设置为227h227后输入网络,进一步缩小数据特征分布范围,加速梯度下降,从而提高训练速度,加快模型收敛。
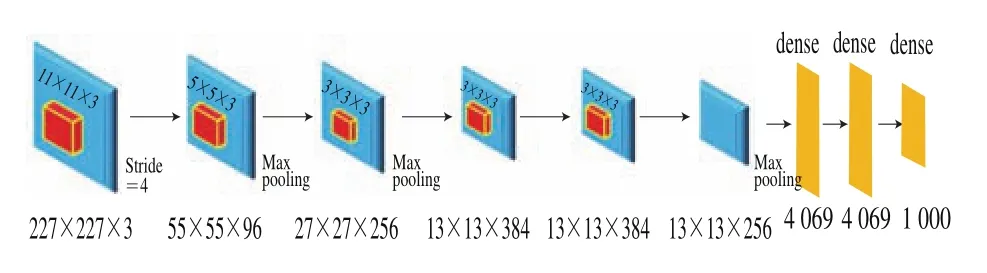
图1 AlexNet网络模型结构Fig.1 AlexNet network model’s structure
1.3.5 模型评估方法
为了评估模型训练结果,选择训练准确率、验证准确率和测试准确率对模型进行性能评估。准确率按式(3)计算:

式中:为判别正确的样本数;为样本总数。
此外,运用混淆矩阵将测试集中每类光谱的预测结果进一步可视化,评估模型对未知光谱的分类性能。
2 结果与分析
2.1 不同掺杂脱脂乳粉的拉曼光谱
如图2所示,除掺杂小麦粉的样品外,其余5 种掺杂样品的拉曼光谱图高度相似,因此利用传统拉曼光谱数据不能有效区分掺杂物种类。
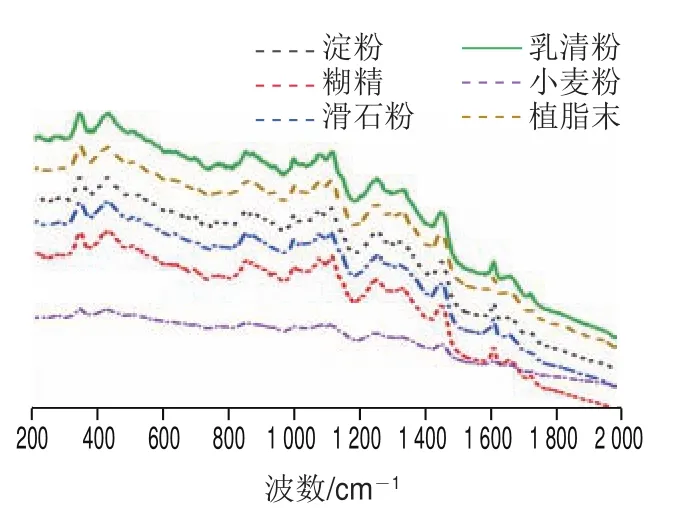
图2 不同掺杂物样品的典型拉曼光谱图Fig.2 Typical Raman spectra of samples with different adulterants
2.2 不同超参数组合对模型训练结果的影响
鉴于掺杂样品光谱图相似程度较高,考虑利用CNN提取不同掺杂样品的拉曼光谱典型特征。然而,CNN不能在训练过程中自主学习小批量尺寸、最大回合数、验证频率等相关超参数,并且没有直接确定网络超参数组合的方法,因此通过手动调参寻求最佳的超参数组合是提高网络验证准确率的有效途径。
本研究通过3 次独立重复性实验,考察分析小批量尺寸、网络验证频率以及最大回合数对网络验证准确率的影响。如表1所示,单独调整网络验证频率对模型的验证准确率影响不大;随着小批量尺寸的减小和对应网络验证频率的增大,模型验证准确率呈增大趋势。此外,模型训练的最大回合数与验证准确率没有线性关系,为确定最优的最大回合数,进一步探究最大回合数对验证准确率的影响。如图3所示,3 次独立重复实验的误差均在0.3%以内,表明网络模型具有良好的稳定性。此外,随着最大回合数从5上升至10,验证准确率先上升后下降,当最大回合数为9时,验证准确率达到最大值(97.58%)。通过超参数优化使网络的分类准确率提高约10%(从89.97%提高至97.58%),最终确定优化方案7为网络最佳训练参数组合。
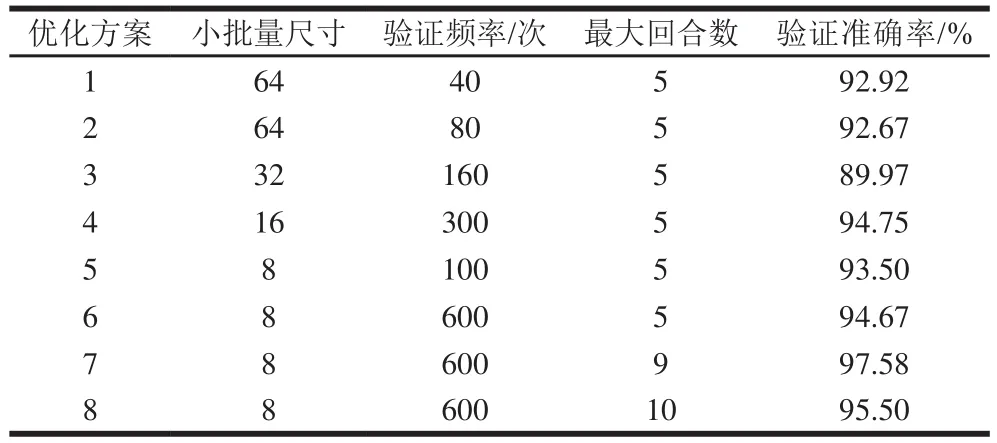
表1 CNN的超参数优化方案对比Table 1 Hyperparameter optimization schemes compared with convolutional neural networks
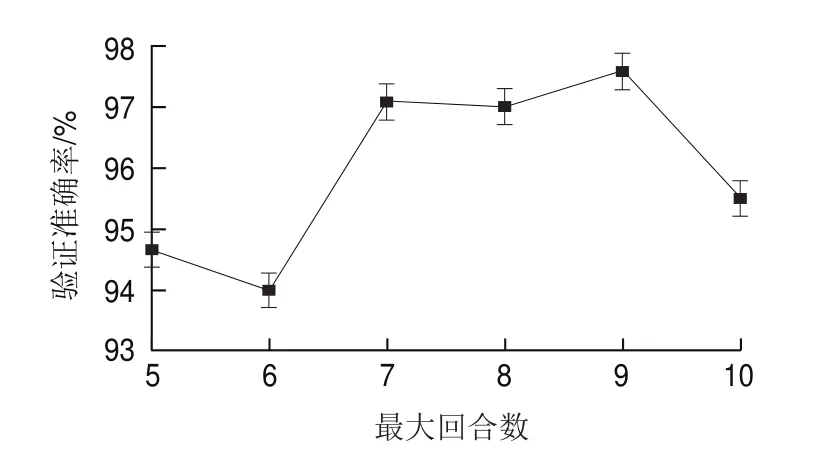
图3 不同最大回合数的验证准确率对比Fig.3 Plot of validation accuracy against maximum number of epochs
2.3 不同光谱预处理对模型训练结果的影响
降噪和去背景是进行传统拉曼光谱分类的关键环节,为评估两种预处理及其组合方法对模型的影响,分别将原始光谱数据和3 类预处理后的光谱数据(降噪、去背景、降噪和去背景)输入CNN进行训练,结果如图4所示。与另外3 类数据(原始光谱数据、降噪光谱数据、去背景光谱数据)相比,当光谱数据被同时降噪和去背景处理后,模型的训练准确率和验证准确率均下降15%左右,这可能是因为过多的预处理步骤减少了光谱数据的特征,增加了网络特征提取的难度;对原始光谱数据进行单一预处理后,模型的训练准确率较原始光谱有轻微提高,验证准确率却有所降低。原始光谱数据的网络验证准确率高达97.58%,表明不同乳粉掺杂物的原始光谱特征被网络充分学习,体现了CNN强大的特征提取和分类能力。
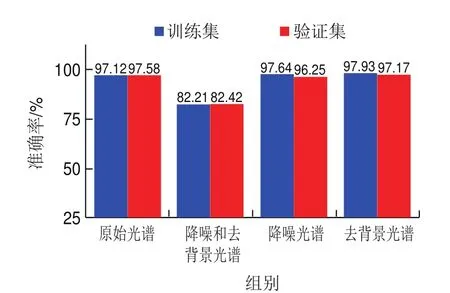
图4 不同预处理后的CNN准确率对比Fig.4 Effect of different spectral preprocessing methods on the accuracy of CNN
2.4 不同网络模型对测试准确率的影响
为探究预处理前后CNN对未知样品的测试准确率,选取600 组标准掺杂样品作为测试集,输入对应的4 种CNN模型,获得每种模型的测试准确率。如图5所示,原始光谱网络模型、混合预处理(降噪和去背景)网络模型、单一降噪网络模型以及单一去背景网络模型的测试准确率分别为96.33%、70.67%、96.17%、93.5%,原始光谱网络模型表现出最强的泛化能力,而混合预处理网络模型与另外3 种模型相比,测试准确率下降约25%。由此可知,网络的训练结果与测试结果一致,表明CNN可准确提取原始光谱的本征信息,而过度的光谱预处理很可能会严重影响CNN的特征提取能力,从而大大降低网络对未知光谱的识别能力。

图5 不同光谱预处理的测试准确率Fig.5 Accuracy of test with different spectral preprocessing methods
进一步研究乳粉掺杂物光谱数据在不同网络模型中的分类结果,利用混淆矩阵将测试集结果进一步可视化,矩阵的横坐标代表预测类,纵坐标代表真实类。由图6可知,原始光谱网络模型可有效辨别乳粉掺杂物光谱,识别准确率均在92.9%以上,单一预处理模型的辨别能力有所下降,混合预处理模型甚至无法分辨淀粉掺杂物光谱。此外,小麦粉数据经过单一预处理后的识别准确率仍保持100%,即使经过混合预处理后仍保持99%的较高准确率;经过混合预处理和单一去背景预处理后植脂末的识别准确率无明显提升,但是经单一降噪处理后其分类性能较原始光谱下降了10.2%;与原始光谱相比,乳清粉光谱数据经单一降噪预处理后分类性能保持不变,但是经单一去背景预处理后分类性能下降了10%,经混合预处理后识别准确率下降了71.5%;与原始光谱相比,滑石粉光谱数据经单一去背景预处理后性能提高了2.8%,经单一降噪以及混合预处理后性能均提高了4.8%;糊精光谱数据经单一降噪预处理后分类性能较原始光谱提高了0.9%,经单一去背景预处理后分类性能下降了3.4%,混合预处理后分类性能下降了31.2%;淀粉光谱数据经单一降噪预处理后分类性能较原始光谱提高了4.8%,经单一去背景预处理后性能下降了7.2%,经混合预处理后分类性能降低至0%。表2总结了4 种网络模型对乳粉掺杂物分类性能的影响,结果表明预处理后的光谱只能有限提升个别乳粉掺杂物的分类性能,对于大部分掺杂物,预处理极有可能降低CNN的特征学习能力,不利于乳粉掺杂物的精准高效识别。
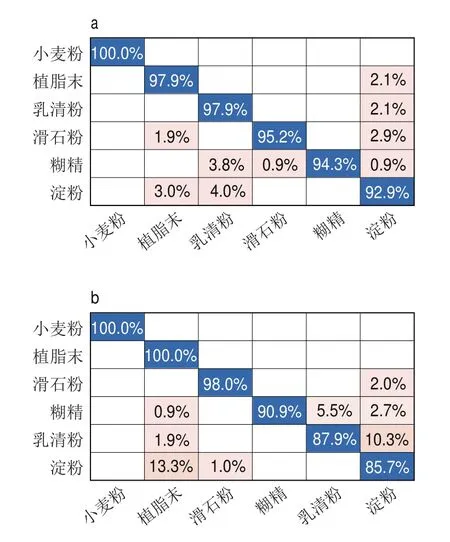
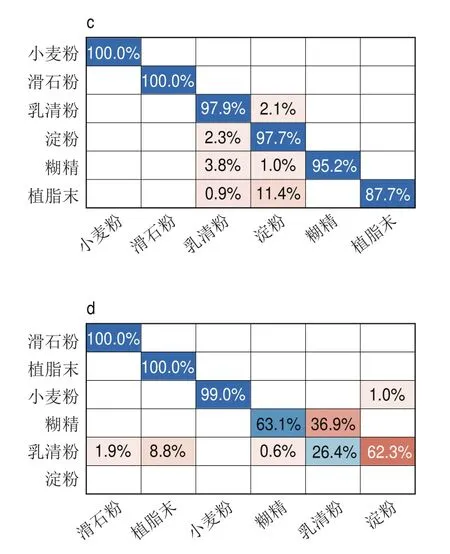
图6 不同光谱预处理的测试集混淆矩阵Fig.6 Confusion matrix of test set with different spectral preprocessing methods

表2 不同网络模型对乳粉掺杂物分类性能的影响Table 2 Classification performance of different network models for six milk powder adulterants
2.5 市场样品分析
使用600 组不同掺杂物含量的乳粉样本计算该方法的分类准确率,验证该方法的有效性。如表3所示,CNN模型的分类准确率高达95.5%,可满足乳粉工业的市场检测需求。其中CNN模型对小麦粉和糊精样品的识别准确率高达100%,对滑石粉、乳清粉和淀粉样品的识别准确率分别为99%、97%和92%,完全可以满足乳粉掺杂物鉴别需求;但模型对植脂末样品的识别准确率较低,可能的原因是植脂末样品的拉曼光谱特征不明显,从而使模型对其特征光谱的提取能力不足。后续研究可通过增加训练集数据和提高模型训练次数解决以上问题。
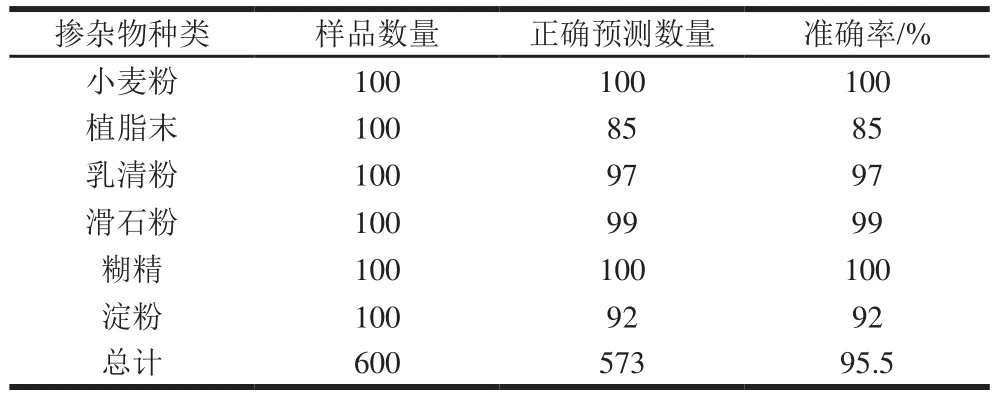
表3 网络模型对标准掺杂样品的预测结果评价Table 3 Prediction results of standard adulterants by the CNN model
3 结 论
以乳粉掺杂物拉曼光谱数据为研究对象,建立能够精准识别掺杂物的CNN模型。分析结果表明:CNN不但能够简化传统光谱预处理和建模过程,并且对标准样品的分类准确率高达95.5%,可满足大批量的乳粉质量安全筛查需求;CNN的性能与超参数组合方式呈非线性相关,需手动调试才能达到最优分类性能。本研究创新性地将一维光谱数据转变为二维图像输入CNN,减小了数据的特征分布范围,提高了模型收敛速度,可应用到其他CNN分类建模研究。
