基于极端梯度提升算法的空调系统故障诊断自适应模型
2022-08-01何金凝徐廷喜黄巍晋欣桥杜志敏
何金凝,徐廷喜,黄巍,晋欣桥,杜志敏
(上海交通大学机械与动力工程学院,上海 200240)
0 引言
近年来我国经济高速发展,能源的需求不断增加。从行业构成来看,建筑能耗约占总能耗的20%[1],其中暖通空调系统相比其他建筑设备消耗的能源最多,占建筑能耗的40%[2]。随着越来越多的云计算数据中心投入运营[3-4],空调系统的可靠性对保障服务器等设备的正常运行具有重要意义,因此数据中心暖通空调系统的故障检测与诊断(Fault Detection and Diagnosis,FDD)变得尤为重要[5-8]。实验研究和调查表明,通过成功开展故障检测与诊断可以减少10%~40%的空调系统能耗[9]。
由于设备磨损、设计不合理或维护不够等因素,空调系统会出现各种各样的故障[10]。按照严重程度可分为硬故障和软故障[11-12],软故障又称渐进性故障,这类故障发展较慢难以被检测出来。制冷剂泄漏作为最常见的软故障,得到广泛的关注和研究[13-14]。ZHU等[15]建立了基于灰箱模型-梯度提升树(Gradient Boosted Decision Trees,GBDT)的融合模型,用以计算数据中心空调系统的制冷剂充注量。王誉舟等[16]采用加权k近邻算法,提出一种多联机空调系统的制冷剂充注量故障诊断策略,适用于多工况和多故障等级的情况。徐廷喜等[17]针对变频空调系统的制冷剂泄漏故障,提出基于支持向量数据描述(Support Vector Data Description,SVDD)算法的检测与诊断方法,准确率较高。
目前针对空调系统的在线FDD研究较少。丁新磊等[18]提出了一种优化误差反传神经网络的故障诊断策略,如果模型的最大输出大于设定的阈值,则将其判定为未知类型的故障,从而实现新故障的检测。刘倩等[19]提出一种结合最大相关最小冗余和随机森林(Random Forest,RF)算法的在线故障诊断策略,在多个在线验证集上均取得了较高的准确率。武浩等[20]针对概念漂移现象设计了一种冷水机组的故障诊断自适应模型,并将支持向量机增量学习应用于制冷剂过量故障的再学习。
上述方法虽然可以满足暖通空调系统故障诊断的实际需求,但FDD模型应具有一定的自适应能力,使其不受工况、环境和时间等因素的影响。因此,本文提出一种基于XGBoost集成算法的数据中心空调系统故障诊断模型,并引入了“数据价值评定函数”这一标准,所构建的诊断模型具有跨工况和跨故障的故障诊断能力,且能够自主的更新数据集和模型。
1 故障诊断及自适应方法原理
1.1 XGBoost算法
近年来,基于数据驱动成为故障诊断领域最热门的方法,在机器学习中集成学习的精度更高,其可分为并联式(Bagging)和串联式(Boosting)两种。本文构建了基于串联式集成学习XGBoost的故障诊断模型,XGBoost算法在代价函数中加入了正则项并进行了二阶泰勒展开,预测精度大幅提高,图1所示为该算法的原理。
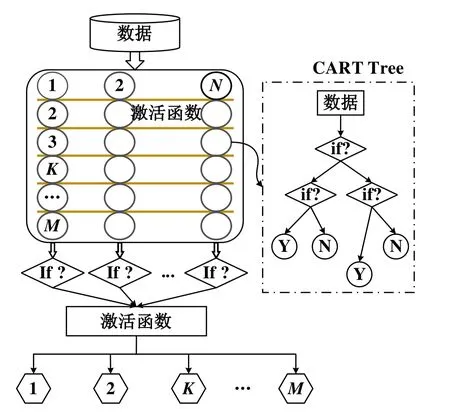
图1 极端梯度提升算法原理
串联式集成学习的模型是由多个基模型叠加而获得,如式(1)所示:

XGBoost的目标函数,包括误差损失函数和惩罚函数两部分:
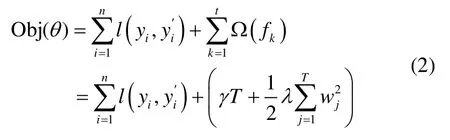
式中,yi为预测目标的实际值;l(yi, yi')为数据样本xi的训练误差;Ω(fk)为第k个基模型的惩罚;n为训练样本总数;t为训练的弱分类器数目;T为叶节点数目;γ为树节点惩罚系数;λ为正则惩罚系数;wj为叶子节点的值。
误差损失函数按照泰勒公式展开至二阶:
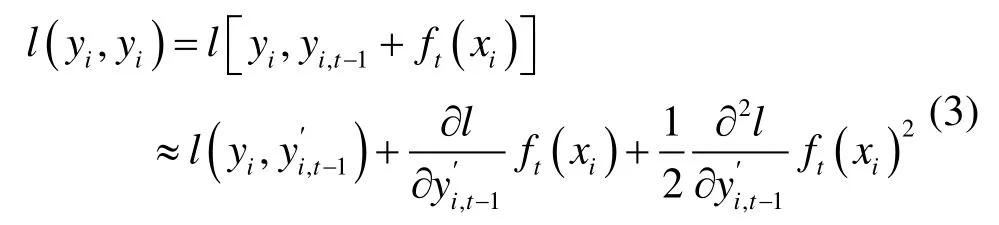
移除误差函数中的常数项后,目标函数可化简为式(4):
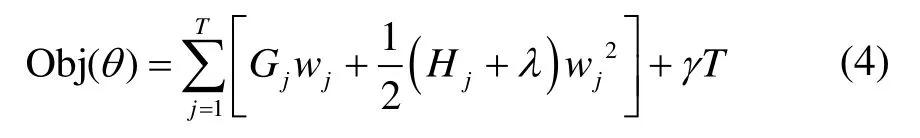
式中,Gj和Hj分别为叶节点权重一次项和二次项梯度之和。为了使模型的目标函数取值最小,对目标函数求导并令其等于零,求解得到式(5)和式(6)。此时,该目标函数可作为树的节点打分函数:
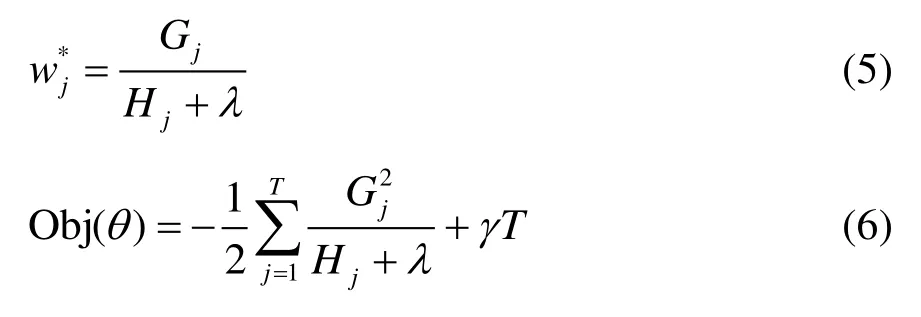
1.2 K-Means聚类算法
聚类算法有很多种,K均值聚类算法(K-Means Clustering Algorithm,K-Means)最为常用。该方法简单快速,主要逻辑步骤为:1)选取k个点作为初始聚类中心;2)计算每个样本点与各个聚类中心的距离,找到离该点最近的中心并对其进行归类;3)遍历完所有样本后,每个样本都被归为一个聚类簇,重新计算每个簇的重心并将其定为新的聚类中心;4)反复迭代上述步骤,直至聚类中心变化的距离小于设定阈值,则收敛结束。
本文以室内温度和室外温度为自变量,利用K-Means算法对新数据进行聚类。
1.3 数据价值评定函数
数据集的更新要考虑历史数据和新数据之间的权衡关系。当出现了新故障的数据,显然这种数据非常重要,在保证样本数量均衡的前提下应尽量保留;即使没有出现新故障,新的数据也可能比历史数据更有意义。本文所提出的数据价值评定函数,是从现有模型对数据的诊断概率和数据平衡度两个方面来考虑的。
如果历史模型对新数据的诊断错误,或虽诊断正确但模型输出的结果概率较低,则需要将该条新数据保留。样本保留的权值由式(7)计算求得,采用指数运算避免数值下溢,并对新数据集中所有新样本的权重进行归一化处理。
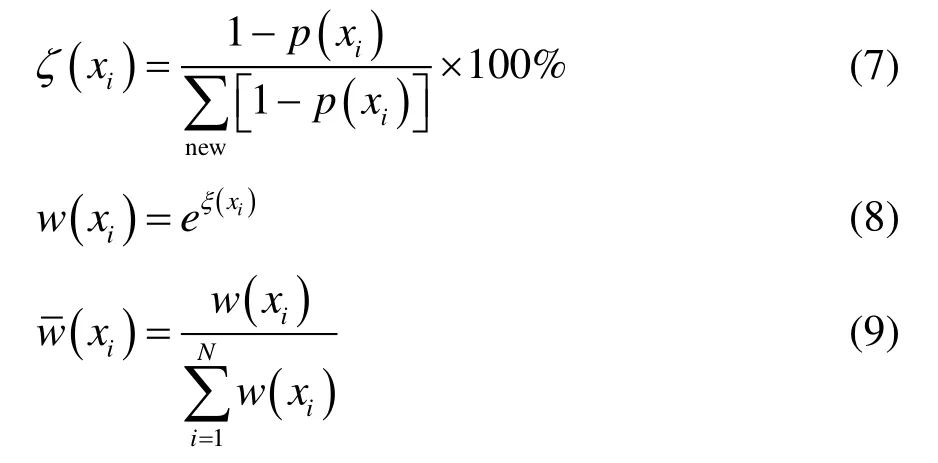
式中,p(xi)为模型对第i个样本预测正确的概率。
在此基础上,使用K-Means聚类算法对新数据进行聚类;在每个类别中,按照上述的数据保留率来筛选等量的数据。
因此,本文所提出的数据价值评定函数可以用式(10)来表达。利用数据价值评定函数,可以确定出新数据集中价值度较高的数据,并将这部分数据作为数据子集用于数据集的更新。
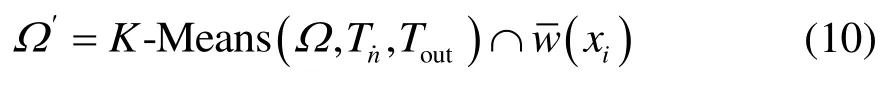
2 实验对象
本文的实验对象是数据中心风冷型变频空调系统,是由制冷系统“四大件”蒸发器、压缩机、冷凝器和膨胀阀以及连接管路等部分组成,图2所示为该系统的原理。系统的额定制冷量为25 kW,制冷剂为R410A。
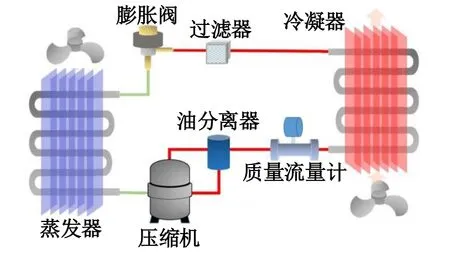
图2 数据中心空调系统原理
实验在焓差实验室中进行,均在空调系统的制冷模式下,名义工况为室内温度37 ℃、室外温度35 ℃。根据室内外干球温度的不同,实验分为10种工况,具体见表1。其中无故障实验涵盖了全部工况;制冷剂泄漏实验包括5个故障等级,分别为10%、15%、20%、30%和40%,每个泄漏等级涵盖了2~4种工况;由于膨胀阀故障的实验成本较高,因此仅模拟了一种工况。

表1 实验的工况分布
其中,将高温工况(室内37 ℃,室外35 ℃)和低温工况(室内30 ℃,室外20 ℃)、制冷剂泄漏15%、膨胀阀故障作为新的数据,分别用以验证模型是否具有跨工况、跨故障等级和跨故障类别的故障检测与诊断能力,这些将在第4节进行介绍。
图3所示为基于XGBoost的故障诊断自适应模型的流程,主要由两个部分组成,分别为故障诊断模型的建立与自适应更新。
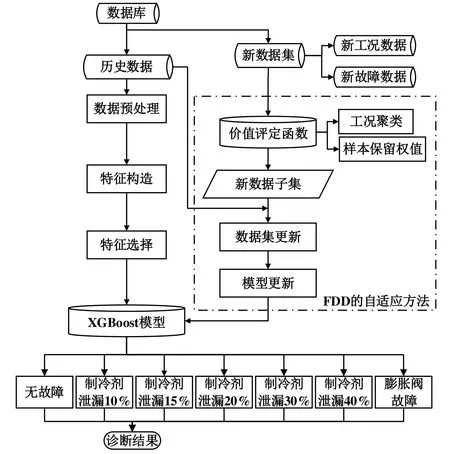
图3 具有自适应特性的故障诊断流程
3 基于XGBoost的故障诊断模型
3.1 数据预处理
在获取实验数据后,需要对数据进行预处理,主要包含三项工作:清除异常值、稳态判别以及物性计算。在清除0、空值等异常值的基础上,采用移动窗口统计法判定当前数据是否处于稳态,窗口长度设为100。计算新采集的数据数值与当前窗口内所有数据平均值的残差,若残差的绝对值大于阈值,则判定为非稳态数据。利用已采集到的变量参数,通过物性计算间接获得制冷系统中的蒸发温度、过热度、冷凝温度、过冷度、压缩机进出口焓、制冷量、性能系数等其他物理参数。
3.2 特征构造与特征选择
为了提高FDD模型的诊断率,本文通过特征构造的方法构造了新的特征变量,以增强数据的表达能力。包括基于物理原理的构造,如上文提到的过冷度、蒸发温度和制冷量等变量;基于经验模型的构造,如拟合压缩机的制冷剂流量、拟合膨胀阀开度等;基于统计方法的构造,如构造核函数等。
利用皮尔逊相关系数计算特征变量之间的协方差矩阵,如果两个变量之间的相关系数的绝对值越趋近于1,则代表这两个变量的线性相关性越强。表2所示为线性正相关系数最大的前10组特征变量。通过删除部分相关性较强的特征变量,来防止特征冗杂并提高模型的计算速度,最终共保留了61个有效的特征变量,用于训练XGBoost模型。
3.3 XGBoost模型的故障诊断结果
将70%的数据作为训练集用于建立XGBoost诊断模型,剩下的30%作为测试集用于验证模型的性能。XGBoost模型经10轮迭代完成收敛,训练精度达97%。在测试集中,诊断结果的混淆矩阵如表3所示。由表3可知,模型总体的故障诊断精度较高。但在制冷剂泄漏故障的不同等级之间,尤其是泄漏程度较低时,存在误诊的情况,如实际为制冷剂泄漏10%的故障中有10组被模型误报为20%,制冷剂泄漏20%的故障中有4组被误报为10%。
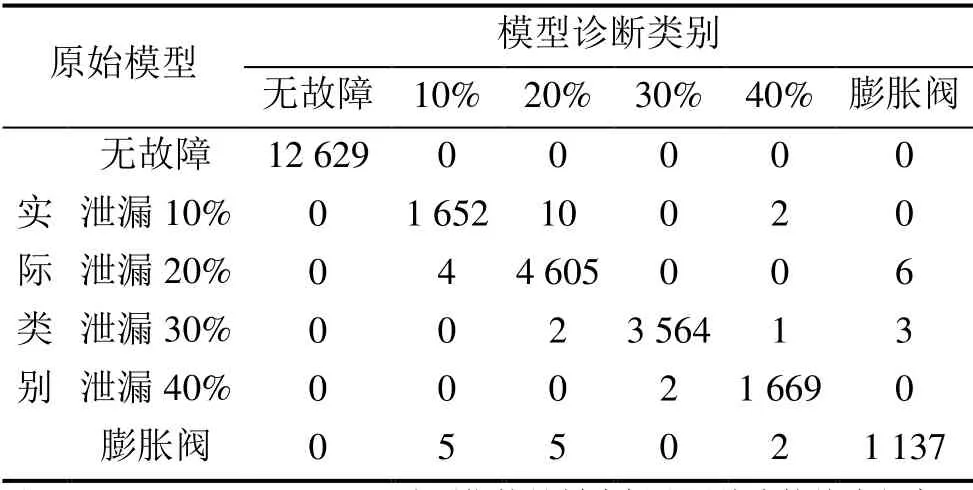
表3 XGBoost模型在测试集的诊断结果混淆矩阵
4 故障诊断的自适应方法
文中首先分析新数据对历史模型的影响,然后利用所提出的数据价值评定函数作为筛选新数据的评价标准,对数据集和模型进行更新,从而使FDD模型具有自适应的能力。
4.1 新数据对历史模型影响
如前文所述,选取一些新的故障数据,来验证模型是否具有跨工况和跨故障的检测与诊断能力。
4.1.1 新工况数据对诊断模型的影响
分别将高温工况(室内37 ℃、室外35 ℃)和低温工况(室内30 ℃、室外20 ℃)作为新的工况,用以验证历史模型是否能够对新工况的数据进行准确诊断。
以高温工况为例,将3 375组新工况的数据样本带入历史诊断模型,模型结果的混淆矩阵如表4所示。可知模型总的准确率仅为60.6%,模型并不能够有效识别出低泄漏等级的故障,虽然能够将高泄漏等级的数据检测为制冷剂泄漏故障,但各个泄漏等级之间不具有区分性。历史模型对低温工况新数据的诊断性能要优于高温工况,这是因为在训练集中涵盖了与之相临近的工况。
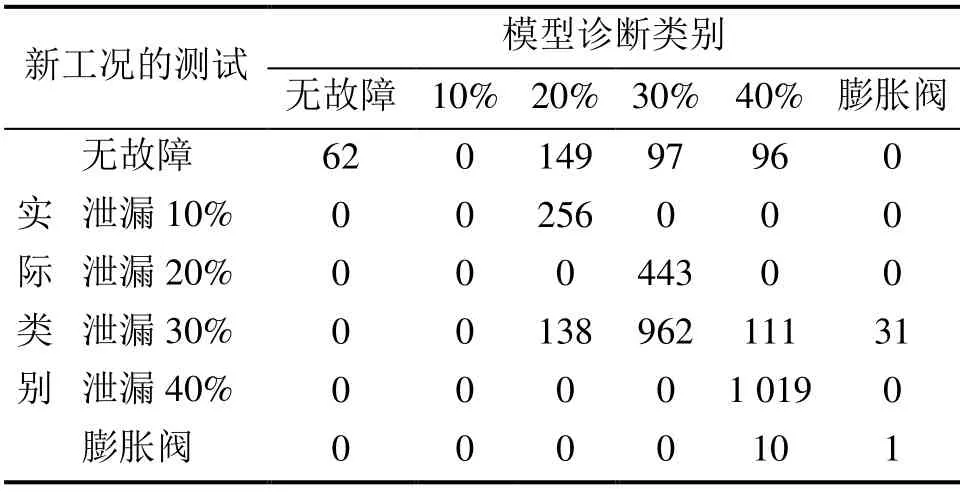
表4 XGBoost模型在高温工况测试集的诊断混淆矩阵
4.1.2 新故障程度数据对诊断模型的影响
将制冷剂泄漏15%作为新的故障程度,用以验证历史模型是否能够对新故障程度的数据进行准确诊断。模型结果的混淆矩阵如表5所示,由于历史模型并没有泄漏15%这一输出项,其将63.3%的数据诊断为制冷剂10%泄漏,26.6%的数据诊断为泄漏20%,共计90.0%。考虑到两者的输出概率均高出平均概率16.7%很多,在实际应用时可以借助人工将该类数据复判为介于两个已知故障等级之间的新故障等级。因此新故障程度数据并不会显著的影响模型性能。

表5 XGBoost模型在制冷剂泄漏15%测试集的诊断混淆矩阵
4.1.3 新故障类别数据对诊断模型的影响
把膨胀阀故障作为新的故障种类,用以验证历史模型(并不包含膨胀阀故障的历史模型)是否能对新故障类别的数据进行准确诊断。模型结果的混淆矩阵如表6所示,由于历史模型并没有膨胀阀故障这一输出项,模型将94.3%的数据漏报为无故障数据,这可能是因为膨胀阀故障的程度并不严重,与无故障工况参数较为接近。因此新故障类别数据对历史模型的性能影响较大。
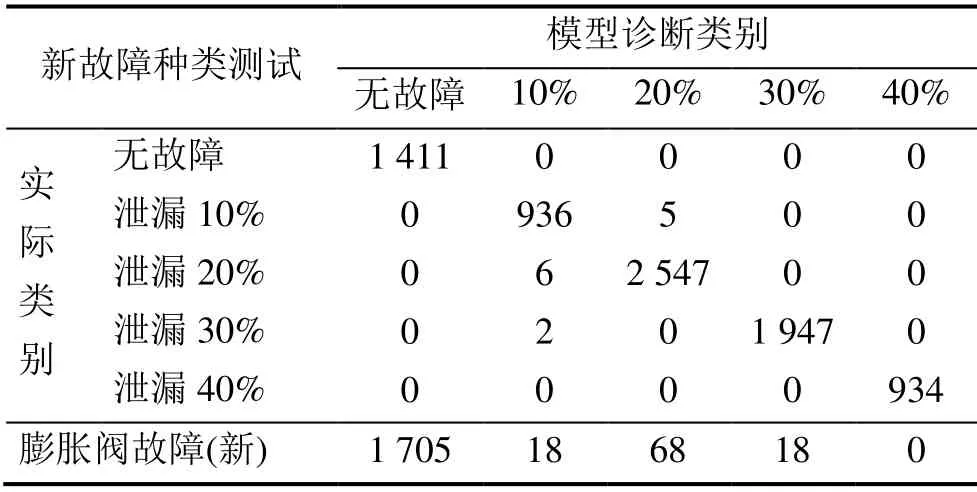
表6 XGBoost模型在膨胀阀新故障测试集的诊断混淆矩阵
4.2 FDD自适应方法
由上文可知,历史模型对跨工况和跨故障的数据诊断效果并不理想,因此应建立一种具有自适应能力的FDD模型,其能够在实时数据中挑选出少量有价值的新数据,用于数据集和模型的更新。
4.2.1 自适应方法之数据集更新
如前文所述,为了筛选出新数据集中价值度较高的数据用于数据集的更新,本文提出了数据价值评定函数这一方法。现以新工况的数据集为例,阐述通过数据价值评定函数更新数据集的工作流程,并验证该方法的有效性。
以高温工况(室内37 ℃、室外35 ℃)的无故障数据作为新工况的数据集S1,数据集S2是包含了高温工况和其他4种工况的无故障大数据集,两个数据集的详细描述如表7所示。
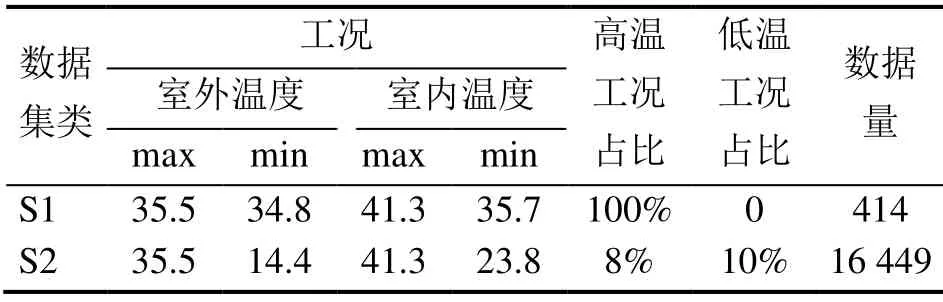
表7 S1和S2数据集的详细信息
将新工况下无故障的S1数据集带入历史模型,414组数据样本中仅有93组被成功诊断为无故障,模型的准确率为22.5%。剔除被成功诊断的数据后,利用K-Means聚类算法对剩下的数据样本进行聚类,设类总数为2,迭代求解得到两个聚类中心:室外35.07 ℃室内39.79 ℃和室外34.95 ℃室内37.60 ℃。然后计算新数据样本的诊断概率作为样本保留权值,从每类中分别选取5条数据价值度最高的数据样本,作为新数据子集来更新数据集。
分别用未更新的历史模型和更新后的模型对数据集S1和S2开展故障诊断,表8所示为诊断结果的混淆矩阵,可知更新后的模型对两个数据集的诊断性能大幅提升,准确率均在99%左右。说明经数据价值评定函数所选取的新数据子集,仅利用10条新数据就能够满足数据集更新的自适应需求。

表8 历史模型和更新模型对S1、S2的诊断混淆矩阵
4.2.2 数据价值评定函数的鲁棒性分析
本文所提出的数据价值评定函数从两个方面出发,一方面考虑模型对新数据的诊断概率,一方面考虑了聚类后的信息熵和数据平衡度。下面将建立4个模型,来验证这两个角度的重要性。
模型1是利用数据价值评定函数筛选10个数据来更新模型;模型2是在聚类后从每类中随机选取5条数据更新模型,而不按照样本保留权值排序选取;模型3是仅根据诊断概率选取最低的10条数据更新模型,而不进行聚类;模型4是在数据集中随机选取10条数据来更新模型。
首先利用数据集S1,在4种方式下完成数据集和模型的更新,用更新后的4个模型分别对数据集S2开展故障诊断。结果见图4和表9,对比可知模型1的诊断性能要明显优于其它3种模型。即在筛选相同数量的少量新样本子集时,本文所提出的数据价值评定函数方法是最为有效的。工况聚类有利于在数据分布分散时能够均衡的筛选数据;数据的保留权值有利于找到历史模型最为陌生的数据集,两者相互结合能够筛选出价值度较高的数据。
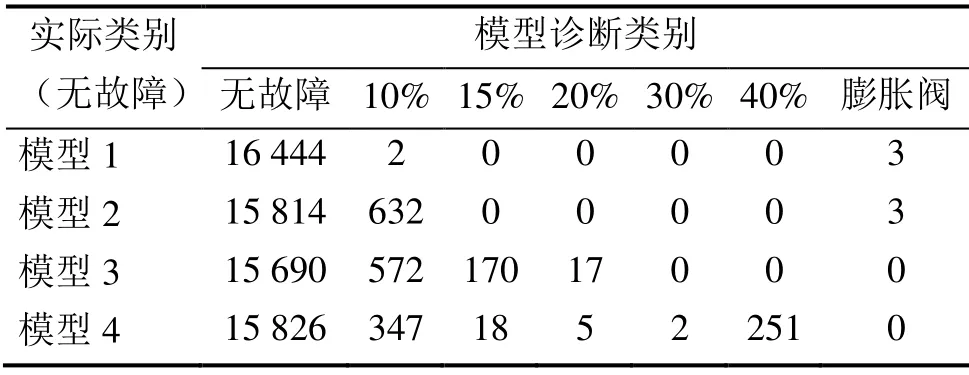
表9 4种更新模型对数据集S2的诊断混淆矩阵
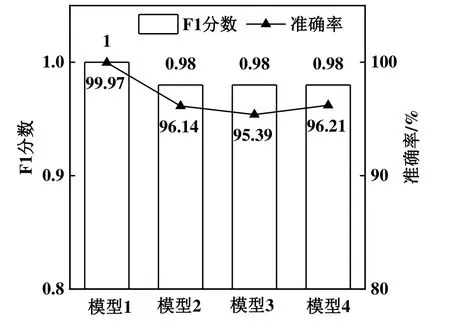
图4 4种更新模型在数据集S2上的F1分数和准确率
4.2.3 自适应方法之模型更新
得到了价值度更高的新数据集后,需要定期对FDD模型进行更新。模型更新同样也包括两种情况:1)利用新故障的数据来更新模型;2)利用新工况的数据来更新模型。本文FDD模型采用的是XGBoost算法,其由N个基模型串联而成,每个基模型包含M个CART树。
若新数据为新故障的数据,即引入了第n+1种故障,XGBoost模型仅需额外添加一支二分类器,并将该分类器的结果与历史模型的诊断结果通过SoftMax激活函数进行归一化,由此可以避免重新训练整个模型,减少计算量和计算时间。若新数据为新工况的数据,将经数据价值评定函数筛选得到的新数据集与原类别相同的数据进行混合,更新历史模型中对应该类别的子模型。
5 结论
本文针对数据中心空调系统,建立了一套基于XGBoost算法的故障诊断自适应模型,首先利用数据价值评定函数对数据集进行更新,通过更新模型的相应局部分支对模型进行更新,使所提出的故障诊断模型具有自适应的能力,得出如下结论:
1)基于XGBoost算法所构造的故障诊断模型具有较高的精度,诊断正确率高达99.83%;但历史模型对跨工况和跨故障新数据的诊断效果并不理想:对于新的高温工况数据,历史模型的诊断准确率仅为60.6%;若把膨胀阀故障作为新的故障种类数据,有94.3%的数据会被漏报为无故障;
2)为使FDD模型具有自适应能力,采用数据价值评定函数对数据集进行更新;考虑到历史模型对数据的诊断概率以及数据的信息熵平衡度两方面,仅筛选出少量最有价值的新数据,就能使新模型的诊断性能大幅提升;
3)为使FDD模型具有自适应能力,根据XGBoost集成算法的特点,仅更新模型的局部分支就能够实现模型的迭代更新,避免重新训练整个模型,提高了模型的更新速度;
4)构建的XGBoost故障诊断自适应模型能够实现数据集的自主更新和模型的迭代更新,弥补了现有FDD方法中无法对跨工况和跨故障数据进行实时诊断的不足。
