基于深度学习的音乐推荐系统
2022-07-31白诚瑞
白诚瑞
河北建筑工程学院 河北 张家口 065000
引言
本文提出的推荐算法的基本思路是:首先利用隐语义模型矩阵分解的方法构建出用户偏好模型;接着利用卷积神经网络对音乐音频特征进行提取并融合音乐的多种信息(歌手ID、发表年份等),将音乐隐性特征向量与用户隐性特征向量做内积运算,获取用户偏好得分,根据偏好得分进行推荐列表的TOPN排序,实现对用户的个性化推荐。
1 推荐系统及核心算法
推荐系统中决定推荐性能的好坏最重要的就是推荐算法,目前,常用的推荐算法主要分为3个类型。
1.1 基于内容的推荐算法
以内容为基础的推荐算法在应用时,主要以用户为基础针对物品完成标记,分析所标记的物品和用户关系,参考关联信息构建推荐模型,进而完成内容和物品的推荐。目前这种算法的应用比较广泛,尤其在工业领域的应用效果比较好。
1.2 基于协同过滤的推荐算法
在这种算法应用的过程中,主要是基于矩阵分解,矩阵的构成主要为推荐系统形成的用户行为信息,这种方式在应用时,参考用户之前的喜好状况,从而实现推荐。基于协同过滤的推荐算法大致分为2种,一种是基于item的推荐算法,一种是基于user的推荐算法[1]。
1.3 基于混合模型的推荐算法
在实际推荐中可能存在复杂的应用场景,单一的推荐算法无法满足实际应用需求,此时混合推荐应运而生,可以有效解决单一算法存在的问题与不足,常见的混合推荐算法包括:加权式、切换式、混杂式。
2 研究框架与模型结构
深度学习在近些年逐渐成为人们关注的热点,其中卷积神经网络是一种高效的识别方法,其在目前语音识别、图像识别等领域的应用比较广泛,利用这种方式解决大规模的机器学习问题,和传统机器学习效果相比,这种算法无论是推荐效率还是推荐质量都更好[2]。本文以卷积神经网络为基础,并且将其和多种音乐标签特征进行结合,提出一种推荐效果更佳的推荐算法,与传统的推荐算法相比,这种算法参考了用户的历史数据,并且将其和音乐音频对应的声学特征相互结合,构建对应的卷积神经网络回归模型,并且利用 Embedding 层对音乐标签信息进行挖掘,进而完成个性化推荐。本文进行的研究可以作为音乐推荐算法的补充,能有效解决传统推荐系统中出现的推荐准确率较低、特征分析不够深入等问题,进而更好地满足个性化推荐需求。本文构建的推荐系统整体设计框图如图1:

图1 系统总体设计图
2.1 用户偏好模型建立
取得的数据集内含有用户收听音乐的相关记录,可将其视为隐式反馈,同一个用户对某首歌曲反复播放次数,则可看作该用户对该歌曲的喜爱程度,播放行为可视为隐性评分[3]。经过特定的数据处理后,得到以相对播放次数为依据得出音乐所对应的评分,且稀疏度处于特定水平的一类用户——音乐矩阵。
2.2 音乐潜在特征学习
对通过数字信号对音乐音频具备的特征进行提取,可有效解决对原始数据进行直接处理时需开展的庞大且复杂计算的问题,且得到的特征更为鲜明,可更便捷地对其进行处理及运用。对音频特征进行分析时能够运用的方法较为多样,常见的有声谱图、梅尔频谱等[4]。所以本文对数据集中音频资源进行了梅尔频谱图的提取,并作为后续训练中的输入内容。同时,还可以使用Embedding层融合歌手和音乐的其他信息进行音乐信息挖掘。
2.2.1 Embedding 部分。本文通过Embedding层对各类标识信息进行融合,该层可以显著增强模型的可扩展性,对获得的信息进行嵌入训练,提高特征系统的完整性。利用one-hot编码实现对特征值的表示。如果模型对应的特征域为,通过该编码对特征包含的第j个特征值所对应one-hot向量进行表示。
嵌入层内,每一特征均有与之对应的嵌入矩阵,将Embedding向量通过多层感知机学习后拼接在一起,得到下一层的输入。
2.2.2 音频数据处理。一般来说,我们首先处理连续的音频信号,对其预加重、分帧以及加窗;然后通过FFT处理所有短时分析窗,这样就得到了相应的频谱;接着将频谱基于 Mel标度滤波器组可以得到Mel频谱;接着对上述Mel频谱取对数,就可以完成整个提取过程[5]。
在本文的研究之中,我们引入了python 工具包之中的 Librosa 进行了处理与分析,主要对音乐音频进行了详细的分析。基于 Librosa 工具包中的处理函数specshow(),其中横轴代表时间,纵轴代表频率,最终得到一个256×256 梅尔频谱图。
2.3 偏好预测
本文使用用户音乐偏好得分作为用户对音乐的喜爱程度表示,首先预测新音乐M的潜在因子向量,然后将与用户潜在因子向量的内积作为用户对音乐M的偏好得分。计算过程如下式所示:
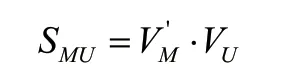
3 实验
3.1 数据集
3.1.1 来源。本文运用的音乐元数据全部都是通过百万歌曲数据集(MSD)取得的,与用户收听情况相关的各项数据,全部都是通过MSD所包含的子集Echo Nest Taste Profile Subset取得的。
3.1.2 数据处理与数据形式。本文在获取对应的数据以后,首先对数据展开稀疏化处理。考虑到整体的时间成本,本实验在取数据时仅对某一声道中提取任意3s的音频且表现为wav格式,取得音频数据后对其进行分割处理以保证不同数据的格式具有较高的一致性[7]。
3.2 评价指标及推荐方法
3.2.1 系统评价指标。本文基于评分精准性与列表准确性两个维度展开评价。
3.2.1.1 预测评分准确性。常见的用于度量预测评分准确性的标准有:平均绝对误差MAE、归一化平均绝对误差NMAE、平均平方误差MSE和均方根误差RMSE等。在本文的研究过程中,我们引入上述4个指标展开评价。
3.2.1.2 推荐列表准确性。本文研究的推荐算法能够做到多位用户形成TopN推荐,也就是说对所有的用户,都可以实现音乐排名,进而确定排名靠前的N首音乐形成一个列表,分别进行推荐[8]。为了对该列表的精确度进行检验,在本文的研究中我们分别通过准确率、召回率、F1值评价推荐质量,检验实验的精确性。
3.2.2 结果分析。利用训练集数据对CNN网络模型进行训练,训练结果发现,当训练的迭代轮次不断增加时,模型的损失误差在开始时快速下降,随着迭代次数增加,减少的趋势逐渐变缓,当epoch接近10时,误差开始趋于平稳。为了验证模型的有效性,接下来从不同角度对实验进行分析评价。
3.2.2.1 潜在因子维数 k 以及迭代次数的选择。在整体实验期间应用均方根误差 RMSE,基于此判定预测评分的准确性。对于不同的特征维度k 与训练轮次 epoch而言,最终获取的模型预测评分 RMSE如图2所示。

图2 不同k及epoch下预测评分的 RMSE
由此可见,潜在因子k为15,训练轮次epoch 为 20 时,实验可以取得较好的评分预测效果。
3.2.2.2 不同推荐模型的推荐结果对比分析。本文使用 MSE、RMSE与 MSLE算法,针对模型训练效果展开全面评价。并且使用了 Frunk-SVD、User-CF与CB等算法模型进行对比分析,最终获取不同推荐列表长度对应的准确率、召回率、F1值。
各方法及本文方法均使用Keras实现,优化器使用 Adam,测试集实验结果如表1所示:
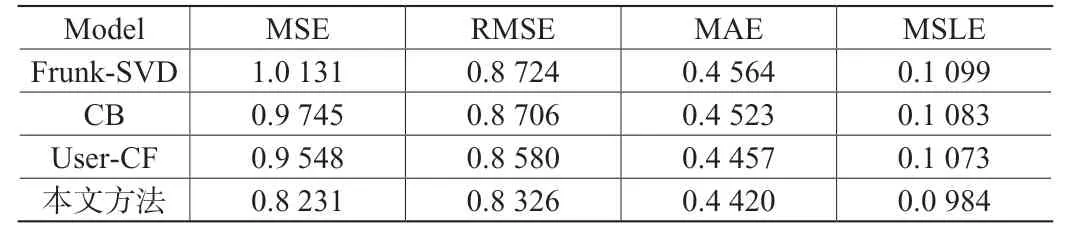
表1 误差对比表
这种方式主要包含了音频信息和其他的标识信息,通过对4个误差指标的分析,其指标全部低于其他模型,表明潜在因子向量在预测的过程中实际效果优于其他模型。在推荐任务的评价上,本文使用召回率、F1值和准确率作为评价标准。利用TopN推荐策略形成需要的推荐列表,在N取值不同时,其最终结果也存在差异,最终获取的结果如图3到图5所示。
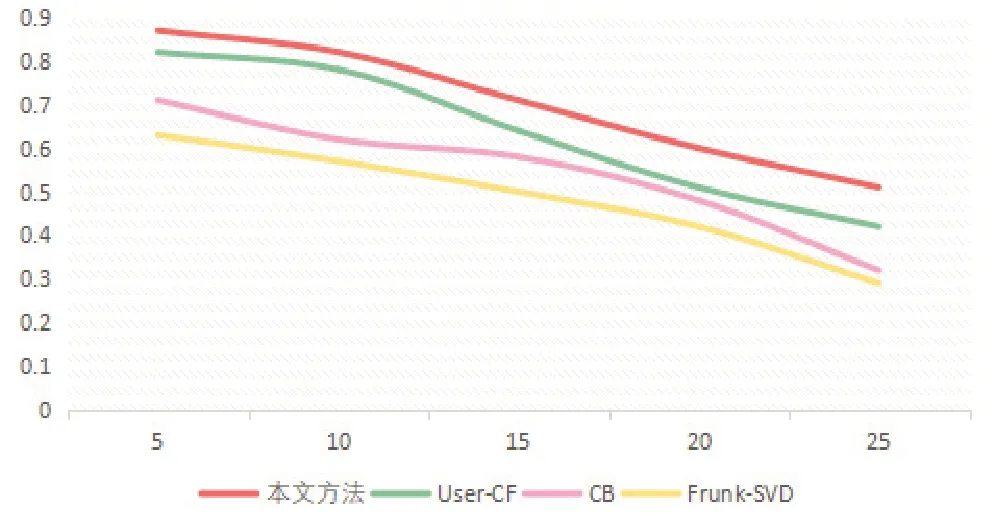
图3 准确率结果
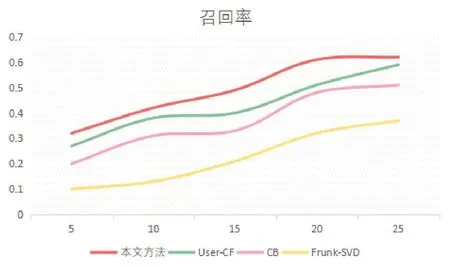
图4 召回率结果

图5 F1值结果
从图中能够看出,当推荐列表长度相同的时候,F1值、准确率与召回率均优于其他模型,这是因为传统的推荐算法模型仅使用了较为稀疏的评分矩阵,并且没有充分利用音乐的其他的相关属性[9]。因为深度卷积神经网络可以较好地学习数据的特征,本文的推荐算法在其中加入了深度学习相关内容,同时结合了音乐标签的相关属性,从而使得推荐效果得到较好的提升。
4 结束语
本文主要进行的是多特征融合的音乐推荐算法的研究,研究的主要内容是利用深度神经网络模型融合多种音乐标识信息,和传统的推荐算法模型进行结合,利用深度神经网络的优势,充分学习音乐音频特征并融合多种音乐标签信息,提升了推荐的效率与效果。为了验证本文提出的推荐算法的可行性,从推荐准确率、召回率、F1值等方面对实验结果进行全方面的评判分析。最后实验结果表明,本文的推荐算法使得最终的推荐结果相对于Frunk-SVD、User-CF 以及 CB 等传统的推荐算法模型有较好的优化。
