分离真伪时钟的处理器FPGA 原型性能校准方法①
2022-07-26郑雅文吴瑞阳陈天奇汪文祥章隆兵
郑雅文 吴瑞阳 陈天奇 汪文祥*** 章隆兵 王 剑③
(*计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)
(**中国科学院计算技术研究所 北京 100190)
(***中国科学院大学 北京 100049)
(****龙芯中科技术有限公司 北京 100190)
0 引言
近年来,国产高性能处理器自主研发成为国家战略需要,并出现了龙芯、申威、飞腾、众志等自主处理器。随着高性能处理器设计技术的发展,处理器是否达到预期的性能指标成为设计者所关注的问题。硅前性能验证是流片前查找性能问题、优化性能瓶颈的重要手段,可以极大地减少设计流片的试错成本,加快处理器设计迭代[1]。但随着国产处理器设计复杂度和规模不断增大,硅前验证的难度和时间成本也随之加大,占据整个周期的70% 以上[2],成为设计周期中亟待优化的一环。
如何快速而准确地评估性能是处理器硅前验证的主要问题之一。目前基于寄存器传输级(register transfer level,RTL)的主要验证平台有仿真器[3]、硬件仿真加速器[4-5]和现场可编程门阵列(field programmable gate array,FPGA)原型系统[6-8]。随着实际应用变得越来越复杂,用于性能基准测试程序集也变大,如处理器性能基准测试SPEC CPU 2017 相比CPU 2006 动态指令数多了10 倍[9],仿真器上进行性能评估需要数年时间。基于FPGA 的硬件仿真加速器可加速RTL 的全系统仿真速度。硬件仿真加速器平台一般运行主频高达兆赫兹级别,且具有较好的可观测性和调试性,如龙芯3 号处理器在Mentor Graphics 公司的Veloce2 系列硬件仿真加速器运行频率为1 MHz,且可进行波形调试[10]。而FPGA 原型验证平台运行频率能达到数十兆赫兹,远高于硬件加速器,大幅加快了性能评估的速度[11]。FPGA 原型系统平台通常采用大容量FPGA器件母板加丰富外设接口的子板构成,支持全系统功能验证和性能评估。
但RTL 设计在FPGA 原型系统上进行性能评估与真实芯片相比存在误差。由于FPGA 相比专用集成电路(application specific integrated circuit,ASIC)芯片,实现同样的逻辑需要更大的面积,且布线结构更复杂,导致导线延迟变长;另外,由于FPGA 资源有限,大型RTL 设计需要级联几个FPGA进行实现,互联线频率限制了FPGA 运行主频。频率降低使得在FPGA 原型平台上对双倍速率(double data rate,DDR)内存系统的模拟与真实机器不同。FPGA 原型平台上内存的周期性刷新间隔须与真实机器保持一致,但由于RTL 设计的频率较低,导致内存读写访问频度比真实机器低,同主频下刷新频率过高。刷新命令会延后读写命令的发送时机,对内存系统延迟有影响。FPGA 原型系统的内存刷新过多,增加了内存延迟,成为性能误差的主要来源。
本文实现了一种通用的FPGA 原型校准方法,校准了内存系统延迟,搭建了精确的原型性能评估系统,为处理器的迭代改进提供了可靠的硅前性能数据。
1 相关工作
本节介绍了几种常见的处理器FPGA 原型验证平台,分析存在的性能误差问题,并比较基于FPGA原型的相关性能校准方法。
1.1 处理器FPGA 原型验证平台
FPGA 原型平台常用于处理器RTL 的全系统验证。Intel 搭建了几款x86 架构处理器的FPGA 原型验证平台。由于处理器的设计复杂度较高,在FPGA 上运行频率不高,且越复杂的设计频率越低。Intel 基于Virtex5 LX330 FPGA 搭建了Atom 处理器的全系统原型验证平台,处理器主频可达50 MHz[12]。基于Xilinx Virtex4 LX200 FPGA 搭建了Pentium 处理器的全系统平台,处理器主频为25 MHz[13-14]。Intel Nehalem 乱序处理器由于设计规模变大,采用了包括Virtex4 和Virtex5 的多片FPGA 平台,可运行在520 kHz[15]。
随着处理器设计规模逐渐变大,为每款处理器项目定制一个原型平台费时费力,而通用性FPGA原型验证平台集成了一片或多片高容量高性能FPGA 芯片以满足各种片上系统(system on chip,SoC)的验证需求,运行频率可达兆赫兹级别,例如S2C[6]、高性能专用集成电路原型系统(high-performance ASIC prototyping systems,HAPS)[7]、Protium[8]系列。为了支持全系统模拟,这些平台都提供了丰富的外部设备接口,例如HAPS 上的内存系统可以通过内存子卡进行搭建。
无论是定制的还是通用型的FPGA 原型平台,最高频率只有兆赫兹级别,而处理器芯片实际运行频率通常在吉赫兹级别,因此面临FPGA 运行主频比芯片低的问题。这使得FPGA 原型系统上外部设备频率与处理器系统频率的关系与芯片不能完全一致,例如FPGA 上内存频率与处理器核频率的比例可能远高于真实机器的比例。并且,由于在FPGA上RTL 设计的内存控制器的最高频率受限于设计时序和FPGA 优化,只能连接可工作在较低频率的内存,而一般内存有最低工作频率限制。处理器与内存频率差对功能验证的影响不大,但却给性能评估带来了误差。
1.2 相关性能校准方法
校准内存系统延迟的主要方法是构建内存系统的时序模型。文献[16-18]构建了内存的时序模型并与内存厂商美光公司提供的RTL 参考模型进行校准。但由于需要模拟内存控制器的时序,时序模型要包含事务调度器、内存状态跟踪器、内存访问调度器等单元,使得构建精确的时序模型变得复杂。为了简化时序模型,文献[19]使用统计得到的固定拍数作为内存延迟的模拟,但这种模拟方法不够准确,且对于不同平台内存延迟不完全一样[20],而且这种方法只能通过在原本访存通路延迟基础上增加拍数来模拟内存延迟,而SoC 上RTL 内存控制器由于频率降低,反而需要减少拍数进行时序模拟。因此,除非实现与内存控制器完全一致的时序模型,否则无法对设计的内存控制器进行性能验证。
文献[21]通过在RTL 内存控制器后连接高速的内存控制器知识产权核(intellectual property,IP),避免了模拟内存控制器时序的需要,而且消除了内存的最低工作频率的限制。但该文献存在两方面问题:(1)不支持常见的内存读写命令背靠背传输。该文献的实现不支持图1(a)所示的背靠背内存读写传输,只支持每次读写事务串行完成的情况,如图1(b)所示。而这种背靠背传输由于能增大访存带宽,在内存访问中很常见。(2)对内存系统只进行了功能验证,未进行性能校准。本文改进了其实现,使得支持常见的内存访问传输,并且与真实机器进行了性能校准。
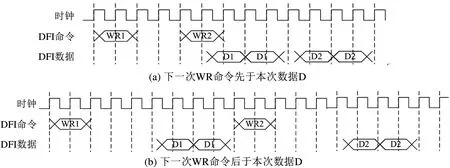
图1 两种内存写传输
2 FPGA 原型的性能误差分析与校准方法
2.1 基于FPGA 原型的处理器性能评估方法
2.1.1 处理器FPGA 原型平台
图2 为基于FPGA 原型平台搭建的通用处理器原型系统结构,该原型系统由FPGA 里的处理器、FPGA 上的DDR4 内存子卡和外接的桥片板卡组成。FPGA 里的处理器包括处理器核、末级缓存、内存控制器、互联总线以及总线控制器等模块;FPGA上的内存子卡连接内存集成到系统中;板卡由HyperTransport 总线与FPGA 上的处理器相连,提供其他外设接口,用于连接硬盘、网络等设备。

图2 FPGA 原型系统结构图
2.1.2 性能评估方法
由于RTL 设计在FPGA 上无法达到真实芯片的运行频率,因此FPGA 原型系统上需要整体降低RTL 设计的运行频率,并通过主频换算得到性能评估数据。与真实机器类似,FPGA 上各部分处于不同的时钟域,大致可分为处理器核、内存、总线几个时钟域。假设真实芯片中处理器核频率为1.2 GHz,内存频率为800 MHz,但若FPGA 上处理器核频率降至24 MHz,而内存频率仍为800 MHz,将导致内存访问延迟周期数比真实机器中的要少很多。为了在FPGA 原型系统上准确模拟真实情况,通常将FPGA上的各部分频率比例关系与真实情况保持一致,整体将运行频率按比例调低,调低的倍数为频率缩放倍数。

如式(1)所示,由于RTL 与芯片是同一套设计,所以同一时钟域内的拍数延迟是一致的,因此降频后FPGA 上测得的性能分值可通过等比例缩放得到其模拟的真实机器的性能数据。例如将FPGA 上的核频率调至24 MHz,内存频率为16 MHz,同时缩小50倍,则测试在FPGA 上得到的性能分值通过乘以频率缩放的50 倍得到模拟的真实机器的性能分值。
但上述计算方法只有在理想情况下才能得到准确的性能数据。在实际系统中,虽然FPGA 上频率可以整体调低,但某些系统事件频率没有因此降低,且这些事件对性能有影响。例如时钟中断频率由内核的配置决定,同一内核下FPGA 与真机的时间片长度相等,但由于FPGA 上处理器频率低,同一长度的时间片中用于处理时钟中断的时间更长,使得用户程序的时间片占用率很低,整体测试性能变差。为了在FPGA 和真机上得到同样的用户程序时间片占用率,本文通过降低FPGA 上内核中的时钟中断频率,使得FPGA 上时间片变长,最终使得FPGA 和真机用于时钟中断处理的时间占比一致。对于计算密集型性能测试,降低时钟中断频率对系统调度产生的影响可以忽略不计。但并非所有事件都可以直接降低其发生频率。典型的如内存刷新频率,其由内存属性而定,无法随系统频率降低,且刷新频率对内存延迟有影响,使得内存敏感的测试程序仍存在较大的性能误差,对内存系统的校准成为整体性能校准的主要工作。
2.2 FPGA 内存系统误差分析
内存系统[22]通常由内存控制器、端口物理层(physical,PHY)和内存组成。内存用电容存储数据,由于电容存在漏电,需要不断对存储电容进行周期性充电操作才能保存正确的数据,这种周期性数据读写即内存的刷新操作。由于内存刷新速率与工作频率无关,与内存本身属性有关,因此内存控制器发送刷新请求的频率应根据内存属性要求的刷新频率,否则可能导致数据出错。因此,虽然FPGA 上的内存系统运行频率较低,但由于与真实机器使用同样的内存,刷新频率与真实机器一致,经过主频换算,会出现刷新频率比同主频下真实机器更高的情况。由于内存控制器在发送刷新请求时会阻塞读写访存请求,并且刷新请求使得后续访存请求需要重新激活,因此刷新频率变高会增加访存延迟,导致性能下降。
图3 反映了刷新请求对访存请求的影响。当写请求被刷新命令阻塞时,当次写到下一次写需要经过当次写完成、预充待刷新行、刷新该行、重新激活下一次写和发送下一次写等阶段。其中,WL指写延迟,BL指突发传输长度,tWR指写恢复时间,用于计算当次写完成时间;tRP指行预充电有效周期,用于计算预充完成时间,tRFC指刷新周期,用于计算刷新完成时间;tRCD指行有效到列有效时间,用于计算重新激活的时间。而未被阻塞情况下可直接在当次写发送后的tCCD延迟之后发送下一次写。对比正常写请求,以DDR4(假设速度为2133 bps,即tck=0.938 ns)为例,两次刷新间周期tREFI是7.8 μs,WL=14tck,BL=8tck,tWR=15 ns,tRP=15 ns,tRFC=350 ns,tRCD=15 ns,tCCD=4tck,一次刷新阻塞访存请求带来的性能损失大约为


图3 刷新阻塞访存请求示意图
由于难以准确统计被刷新阻塞的访存指令的次数,且由于访问延迟变长,各种队列的阻塞加剧,产生其他级联反应,因此在FPGA 原型系统上无法准确估算访存延迟。
2.3 分离真伪墙上时钟的内存系统校准方法
2.3.1 内存系统校准方法
如图4 所示,FPGA 内存系统延迟不准是由于系统中存在两个墙上时钟,即真墙上时钟和伪墙上时钟。这里对两个墙上时钟进行定义:真墙上时钟是真实时间下的时钟,与真实机器时钟一致,也是内存刷新频率依据的时钟;伪墙上时钟是由于FPGA运行主频降低产生的墙上时钟,比真墙上时钟慢的倍数为频率降低的倍数,为处理器、内存控制器等运行的时钟。由于运行于伪墙上时钟的内存控制器需要按真墙上时钟的频率向内存发送刷新,以至刷新命令相比访存命令频率过高,访存命令更容易被阻塞导致整体延迟变大。而真实机器上由于刷新命令和访存命令都是按真墙上时钟发送,因此与FPGA的情况不同。这使得FPGA 上内存延迟与真实机器相比有误差。

图4 内存校准方法示意图
本文的校准方法是将内存控制器发送的访存命令和刷新命令都调至伪墙上时钟频率,使得访存命令被刷新阻塞的情况与真实机器一致。但内存所需的刷新频率是按真墙上时钟计算的,将刷新频率调至伪墙上时钟会降低内存的刷新频率。由于内存不及时刷新会导致保存的数据出错,因此需要增加一个运行在真墙上时钟下的内存控制器IP 用于向内存发送刷新请求。这使得内存系统有两个内存控制器级联,RTL 实现的内存控制器连接处理器核,处于伪墙上时钟域;新增的内存控制器IP 处于真墙上时钟域,并连接内存。两个内存控制器之间通过转接桥将原有内存控制器的请求转发到新增的内存控制器,并由转接桥进行跨时钟域转换。
2.3.2 内存系统校准实现
(1) 整体结构
如图5 所示,本文实现的FPGA 原型内存系统包括RTL 设计的内存控制器、双速率动态存储物理层接口(DDR PHY interface,DFI)[23]到高级扩展接口(advanced extensible interface,AXI)[24]的转接桥、内存控制器IP、DDR 内存。相比于原本结构,改进后的内存系统将原本的PHY 换成了新设计的伪PHY(pseudo PHY),其中核心部件为DFI-AXI 转接桥,用于连接RTL 设计的内存控制器和高速内存控制器IP。其中,RTL 设计的内存控制器运行在伪墙上时钟域,而高速内存控制器IP 和内存运行在真墙上时钟域,二者之间通过DFI-AXI 转接桥内的异步先入先出队列(first in first out,FIFO)进行跨时钟域信号转换。

图5 校准内存系统结构图
通过上述设计,RTL 设计的内存控制器产生的内存刷新请求也等比例地调整为伪墙上时钟所对应的频率关系,因而各访存事件与其产生的性能影响与真实机器保持比例一致。另一方面,由于内存真正的刷新请求是由工作在真墙上时钟的高速内存控制器IP 发出的,与真实机器的内存刷新周期相同,因此功能正确性不受影响。
(2) DFI-AXI 转接桥的实现
DFI-AXI 转接桥将内存控制器发送的DFI 接口标准[23]读/写请求转换成AXI[24]接口标准的请求,并转发给内存控制器IP。DFI 协议与AXI 协议有以下3 个方面的主要区别。
1)地址表示方法不同。DFI 协议的地址是内存寻址地址,包括通道选择地址、bank 组地址、bank 地址、行地址、列地址,而AXI 协议传输的地址是物理地址。因此,DFI 接口上的地址信号不能直接用于AXI 接口的地址信号发送。
2)接口信号不同。DFI 协议接口信号根据功能可分为命令、地址等控制信号、读数据信号、写数据信号;AXI 协议接口信号可分为读地址、读数据、写地址、写数据、写响应通道信号。
3)时序控制不同。AXI 协议各类信号相对独立,没有时序的要求;DFI 协议的控制信号与数据信号之间有时序要求,由内存参数控制。
DFI-AXI 转接桥将DFI 接口上的信号根据协议进行译码;对译码得到的读写访存请求,根据AXI协议转换成地址、数据位宽、数据等信号;将待发送到AXI 接口上的信号通过异步FIFO 转换到内存频率并发送。
转接桥可分为命令译码单元、地址合成单元、读/写地址及数据状态机、读/写地址及数据异步FIFO 等模块。其中,命令译码单元负责识别DFI 接口上的读写访存相关命令,过滤不需要继续传递的命令。地址合成单元将内存寻址地址重构成物理地址。根据DDR 协议,一个完整的访问需要先激活某一行,再对该行的某一列进行读写。由于同时可能有很多行被激活,因此需要将所有被激活的行存下来,只要遇到相应的bank 列读写命令,则将已激活的该bank 行地址取出,与访存命令的列地址重新拼合成物理地址。命令译码单元产生的控制信号控制读写状态机将地址、数据等信息通过异步FIFO 传递到AXI 接口。异步FIFO 将低频的伪墙上时钟域信号转成高频的真墙上时钟域信号,使得输出的AXI 接口信号与内存控制器IP 频率匹配。
为了支持读写背靠背请求的传递,本文采用了将地址和数据状态机分离的设计方法,对命令地址和数据通道分别进行处理,使得可传输请求带宽更高。与文献[21]以一次传输事务为单位的状态机实现方法不同,分离后地址和数据状态机可以分别接收不同传输事务的地址和数据,无需上一次的数据传输完成后再进行下一次的地址传输,地址、数据可以按序接续发送,实现了读写请求背靠背传输的支持。
(3) 内存延迟的校准
内存延迟的校准主要根据DFI 协议对读请求的数据返回延迟进行校准。根据DFI 协议,写请求没有握手,读请求需要在指定内存参数拍数内返回读数据,所以内存控制器到内存的延迟只受读数据返回延迟的影响。因此,FPGA 和真机采用同一套内存配置参数,只要在FPGA 上满足在同一内存参数指定拍数内返回读数据,就能达到内存控制器访问内存的延迟拍数与真实机器一致的校准目标。
在内存参数指定的拍数内,内存控制器IP 需要完成访问内存并返回读数据。如果内存控制器IP需要刷新内存,将会延长返回延迟。为了保证在指定拍数内控制器IP 一定能返回读数据,将RTL 设计的内存控制器的运行频率适当调低,内存频率调高,使得内存参数要求的返回延迟变长,进而保证即使在内存刷新的情况下也能在该拍数内返回读数据。而一般FPGA 上内存控制器运行频率较低,所以不需要额外降频也能满足返回拍数要求。
3 实验与结果分析
本文基于龙芯3 号处理器搭建的FPGA 原型平台进行实验。通过实验对比了内存校准前后的FPGA 原型平台上RTL 设计的性能分值,并与该设计流片后的真实机器的性能分值进行对比。
本文使用Synopsys HAPS-80 S52 作为FPGA 原型平台。HAPS-80 S52 原型验证平台提供了2 个Xilinx Virtex UltraScale XCVU 440 FLGA 2892 FPGA芯片和丰富的接口用于扩展。使用HAPS-80 S52 搭建了原型系统,连接了DDR4_HT3 作为内存子卡,外接自定制板卡提供南北桥和I/O 资源。
实验原型系统基于龙芯3 号处理器搭建,由1个乱序4 发射64 位GS464 系列处理器核、1 级AXI交叉开关总线、片上共享高速缓存、2 级AXI 交叉开关总线、内存控制器以及IO 控制器等模块构成的FPGA 原型,并由HyperTransport 总线连接桥片提供其他外设接口用于连接串口、硬盘、网络等设备。
为了尽量减少性能测试程序的运行环境差距,在FPGA 原型系统与真实机器上均采用Linux 4.19.73内核,测试程序使用同一二进制,均测试单核单线程性能。并且,FPGA 与真机使用同一套RTL 设计和配置。如表1 所示,真实机器与FPGA系统上RTL 处理器主频和内存控制器频率的比例关系一致,FPGA 系统上的性能分值经过频率换算后与真实机器进行比较。另外,真实机器和FPGA原型平台的各级cache 和内存大小一样,两者使用同样的内存参数。
表1 真机与
本文使用lmbench 3.19 中的访存延迟测试lat_mem_rd[25]、访存带宽测试stream[26]程序、处理器性能基准测试集SPEC CPU 2006[27]作为性能测试程序集,SPEC CPU 2006 测试使用train 输入集进行测试。
图6 显示了对各级访存层次的访问延迟的测试,在越过每级访存层次的容量时都会有访问延迟的陡增,分别显示了各级cache 和内存的访问延迟。对比各级访问延迟发现,对于各级cache,FPGA 校准前后误差均不大。但FPGA 校准前对内存访问延迟的模拟误差较大,为18.26%,校准后基本接近真实机器的访问延迟,误差仅为-0.72%。这表明经过校准,内存访问延迟基本准确。
如图7 所示,FPGA 校准前由于内存延迟偏大,因此测得内存带宽比真实机器低20%以上;经校准后FPGA 原型系统运行stream 测试程序与真机相比误差均小于2%。测试本身存在一定的波动范围误差。实验结果反映了本文提出的内存校准方法是有效的。

图7 FPGA 校准前后stream 测试结果比较
如图8 所示,FPGA 校准前SPEC CPU 2006 测试部分误差较大,误差最大的测试459.GemsFDTD 高达40%,其余测试如433.milc、437.leslie3d、470.lbm误差在20%以上,429.mcf、410.bwaves、450.soplex误差在10%以上,平均误差为7.49%。经校准后FPGA 上运行SPEC2006 测试误差最高仅为2%,大部分误差小于1%,平均误差为0.36%。由于测试本身有一定的波动范围误差,因此校准后FPGA 原型平台可以获得较准确的SPEC CPU 2006 性能分值。

图8 FPGA 校准前后SPEC CPU2006 测试结果比较
实验结果表明,经过校准后的FPGA 原型系统对于计算密集型和内存敏感型的测试都能获得较为准确的性能数据。
4 结论
本文基于分离真伪墙上时钟提出了一种通用的FPGA 原型系统性能校准方法,解决了FPGA 原型系统上内存延迟不准和用户程序时间片占用率过低的问题,使得在FPGA 原型设计平台上性能评估时误差在2%以下。本文提出的方法理论上适用于任何真墙上时钟和伪墙上时钟并存的系统校准,具有一般性意义。并且,本文提出校准方法的实现与设计耦合度很低,因此对于不同设计及平台不需要重新进行性能校准,具有通用性。校准后的FPGA 原型验证平台为硅前性能分析提供了更快速准确的解决方案,相对于硬件仿真加速器达到数十倍的速度提升,成本数十倍降低,使得性能评估可以运行更大的测试程序,获得更完备且可信的评估结果。
虽然本文实现了在FPGA 原型平台上对计算、访存密集型测试的准确评估,但降低时钟中断频率实际上会对IO 访问延迟带来影响。后续工作将进一步评估降低时钟中断频率对IO 访问密集型测试性能产生的影响,进一步完善FPGA 原型性能验证平台。
