基于机器学习的突发事件微博谣言识别技术研究进展
2022-07-26刘校麟陈蕾
◆刘校麟 陈蕾
基于机器学习的突发事件微博谣言识别技术研究进展
◆刘校麟 陈蕾
(中国人民警察大学 河北 065000)
本文研究基于机器学习的突发事件微博谣言识别方面所取得的成果。对谣言识别技术研究现状、谣言识别算法及相关技术、基于机器学习的微博谣言识别技术进行总结分析。采用深度学习方法已能将微博谣言识别的准确率、召回率、F1值等模型评价标准值提高到0.8以上,从谣言数据的基础特征扩展到传播特征、时间跨度特征甚至时情感特征等影响识别精度的因素特征。机器学习算法已发展日趋成熟,未来若能实现算法的自学习,自动完成特定时间节点的提取分类,实现对谣言快速有效地识别,将成为谣言识别方面的重大突破成果。
突发事件;微博谣言;机器学习;特征提取;谣言识别
1 引言
信息时代网络用户基数在与日俱增,为满足公众在网络上的社交需求,微博、微信、Facebook等社交媒体应运而生,它为人们快速获取信息提供了途径,然而在为人们提供方便的同时,低成本的言论表达也带来的极大的问题隐患——网络谣言在各大网络社交平台肆意传播,尤其是突发事件发生时,网络谣言的随意扩散极易引发社会矛盾,影响民众生活与社会安定和谐,甚至是引起国家安全隐患问题。突发事件谣言的产生是难以预测的,它的传播是快速的,且因其不受时间、空间和地点的限制,加之以代价低、发布随意等特点,使其在突发事件中谣言所带来的负面影响也更广更深。它可能涉及公共卫生、军事政治、社会治安、体育娱乐等领域,因此在网络谣言大面积传播之前对其进行准确识别并加以制止传播就成了急需解决的问题。本文总结了目前在机器学习算法研究与在网络谣言识别方面的应用中已取得成果的研究文献,从数据获取、特征提取、谣言识别等实验流程方面,对微博平台中的网络谣言识别技术进行研究。
为了应对处理微博谣言识别问题,社会各方面都采取了相应的应对措施,例如成立互联网联合辟谣平台、推出微信辟谣助手、成立微博辟谣官方账号等方法,力求将谣言的影响下降到最小,然而仅仅依靠人工识别谣言不仅耗费大量人力物力,识别的结果也不尽如人意,所能鉴别的谣言也有所限制,同时对谣言的鉴别结果也有着较大的误差。目前一些机器学习新算法的出现为解决突发事件微博谣言识别问题带来新的方法及新的思路。本文在分析和总结近年来在网络谣言方面的相关研究现状基础上,对互联网谣言的定义、特点以及网络谣言识别技术的难点、主导技术方向方法、存在的问题等方面进行了系统的阐述,简要分析了当前互联网时代下突发事件微博谣言识别的几种检测方法,并以此为基础阐述了应用于网络谣言识别的几种先进数据驱动算法,希望以此提升网络谣言识别的准确性及适用性,更新和扩充智能突发事件微博谣言识别技术的适用范围及可持续发展等方面做出贡献。
2 基于机器学习的突发事件微博谣言识别技术研究现状
初期所提出方法多以使用文本内容分析+特征词提取训练方式,并设计使用了大量人工制作的特征谣言检测。Yang[1]通过微博客户端程序收集整理传统识别属性、事件发生所在地属性、客户端类型属性等属性,并针对各项属性对事件谣言与非谣言进行分类训练,谣言识别精度达到70%以上,但因其数据集预处理、特征选取采用人工识别方式进行,因故其效率较低、成本较高。贺刚[2]采用SVM分类学习方法对微博谣言识别过程中的特征进行分类,综合提取微博用户粉丝数、年龄、已发布微博博文数量等微博用户特征与符号、连接、关键词分布等文本特征、转发是否、次数与评论量等传播特征构建多个特征模板,有效提高了谣言识别的准确性。程亮[3]采用BP神经网络方法,基于谣言=(事件)重要性×(事件)模糊性×公众批判能力的传播学公式对微博特定事件有关谣言进行识别检测,算法在运行效率与精度上相对于 SVM、KNN方法有显著提高,具有更好的识别效果与更短的执行用时。姜赢[4]利用 LanguageTool 构建基于XML的网络谣言句式匹配规则,对获取的谣言数据进行测试。采用五类网络谣言文本句式特征分析方法,结合 LanguageTool工具构建了一套基于 XML 的网络谣言句式匹配规则。通过对收集到的网络谣言实验测试,得出实验结果,实现网络谣言的自动识别和监测,并大量减少前期人工识别成本的投入。
随着近年来深度学习技术在自然语言处理、网络文本特征分析等领域的出色表现,研究专家希望利用深度神经网络自动学习谣言潜在的深层表征,提取更有效的语义特征。潘德宇[5]提出一种基于卷积神经网络(CNN)的微博谣言检测模型,考虑到提取到的特征对输出结果影响力问题,在经典的文本卷积神经网络(Text CNN)上加入了注意力机制,通过 CNN 中的卷积层学习微博窗口的特征表示,再根据每个特征表示对输出结果的影响力不同通过注意力机制赋予不同的权重来进行谣言事件的检测,该谣言识别模型准确率达到96.8% ,相较于传统的SVM方法有卓越的提升,并且在召回率和 F1 值上也有提升。李莎[6]通过建立一种多模态层次事件网络,对从Twitter 和 Pheme两社交平台上获取的文本数据进行分析识别,并运用 mean-pooling、RNN和 CNN 三种编码策略来提高谣言检测任务的性能。研究结果表明新的多模态多层次事件网络模型比SVM方法有显著提高,提升了谣言识别的性能。SVM方法在识别结果中的成绩不佳,也表明人工构造文本特征的准确性较弱,无法良好运用于数据训练。陈耿[7]运用半监督学习算法ImCo-Forest搭建了微博谣言识别框架,该算法应用能够通过优化数据集测试训练中少数异常类的分布状态,使得把偏差的误分类代价赋予部分感兴趣的少数类,进而增强谣言识别模型的辨识能力。在理想数据集的前提下,ImCo-Forest算法实验所得聚类结果的G值和F值相较SVM方法有极大提高,但其对数据集要求较高,因此在数据训练前要求对数据集进行严格预处理流程。
从当前谣言识别研究发展进程情况分析,传统的谣言检测模型是从谣言的内容、用户、传播深度三方面进行人工构造特征,这种方式往往存在考虑片面、人力成本高等问题。而在使用深度学习处理谣言识别时,通过循环神经网络的学习训练来分析文本深层特征,避免了人工特征构建的问题,且能够发现人工难以察觉的特征,因此具有能够大大提高谣言识别的准确性并降低人工成本的优势。
3 微博谣言识别算法及相关技术
3.1 基于用户观点的微博谣言识别技术
微博平台是一个多用户参与、开放的网络平台,谣言的传播与谣言的评论并存,因此,用户对微博谣言的评价以及用户观点都可以客观的反映谣言的正确性,亦可作为微博谣言识别的重要依据,并且用户评价可从另一个不同的角度为微博网络谣言分类提供有效的特征变量,相比一些简单的文本关键词特征,用户评价、用户观点更加有说服力。
在微博网络谣言中,每一条评论的语句都有多个词组,这些初始关键词就是整体数据模型的第一层输入,也即单元化基础特征变量;整个评论中又分为多条评论语句,多个关键评论语句形成数据模型的第二层输入。利用分层处理方法,首先对每一条评论进行离散化分词,并使用特征工程将其转化为特征向量,然后利用特征工程,对每一条特征向量进行分析,之后即可得出整条微博的特征信息,最后将这些特征信息送入数据模型分类器进行谣言的识别以及分类。
3.2 基于情感分类的微博谣言识别技术
网络微博谣言带有很强的煽动性,希望得到广泛的传播与关注,因此微博谣言往往会带有强烈的情感色彩,网络谣言关键词的情感倾向,往往是通过情感词语表达出来的。目前,对于网络谣言文本的分类方法主要有两种,一种是基于情感词典,另一种是根据在大规模数据集上的统计情况进行分类,即数据驱动的方法,这种方式往往依托于传统的语言文本分类。基于情感词典的分类技术主要是通过统计正负情感词的数量来完成情感倾向的判断[8],基于数据驱动方法的情感分类与情感词典分类的方式类似,但可以提高对情感词的关注程度,往往可以取得较好的识别效果。
3.3 基于用户观点和情感分类的谣言融合识别技术
在微博谣言中,单一的特征往往只能获得特定方面的含义,如谣言文本、谣言类型等,对谣言的分类与识别相对比较片面,基于用户观点和情感分类的融合谣言识别技术主要是借鉴了集成学习的基本思想[9],分别在不同的数据集中训练子分类器,可以提取谣言中不同方面的特征,然后根据各自特征信息,互相弥补各子分类器之间的不足,包括数据训练过程中的过拟合或欠拟合状态。
目前,应用较多的基于用户观点和情感分类的融合谣言识别算法有以下几类:
1)平均法,将谣言识别弱分类器的输出结果取平均值,即可得到最终的预测结果,最简单的就是算数平均,也可根据不同分类器的权重进行相应的加权平均。
2)投票法,对于谣言分类问题,投票法采用“少数服从多数”的方法,即从多个弱分类器的分类结果中,取分类数出现次数最多的结果作为最终的分类结果。
3)学习法,学习法是指在原来自学习器的基础上再加上一层融合性质的学习器,也即将每个弱分类器的分类结果作为训练的一部分,重新训练一个专门用来处理融合操作的综合分类器,增加其鲁棒性。
4 基于机器学习的微博谣言识别技术
4.1 微博谣言识别的一些常用机器学习算法
目前对于基于机器学习算法的微博谣言的识别方式大致可以划分为两类:一类是基于传统机器学习算法的识别技术,另一类是基于深度学习算法的识别技术,如图1所示。

图1 基于机器学习的微博谣言识别技术分类图
在基于传统机器学习算法的微博谣言识别技术方面,一般选用支持向量机(SVM),决策树(DT),随机森林(RF)等常用的分类算法来识别微博言论是否为谣言。然而,随着微博谣言识别的特征变量所涉及的因素及特征信息越来越多,传统机器学习算法在检测分类特征变量选取以及识别性能方面不仅费时,面对复杂多变的微博谣言信息,其时效性也不尽如人意。
近年来,深度学习算法在各个领域都表现出较好的效果,这也为微博谣言识别提供了一种新的解决思路。深度学习能够通过大量的训练数据自动提取数据中更有效的特征信息,并挖掘深层次谣言特征信息,不仅能够节省人力物力,在识别时效性、准确度方面也表现得较为优秀。目前,运用比较普遍的几种深度学习算法包括深度学习神经网络,循环神经网络以及相关的衍生长短周期记忆网络,门控制循环单元和卷积神经网络等。
4.2 基于机器学习的微博谣言识别技术建模原理
在机器学习实现微博谣言识别的实验中,通过采取针对某一事件的数据爬取、数据集预处理、数据特征提取、数据集分析识别这四项实验步骤,来得到最终的谣言识别结果。而根据所采取机器学习算法构架的不同,对数据集预处理的要求也不尽相同,其对数据特征提取的特征因素也存在差异。具体实验流程如图2。
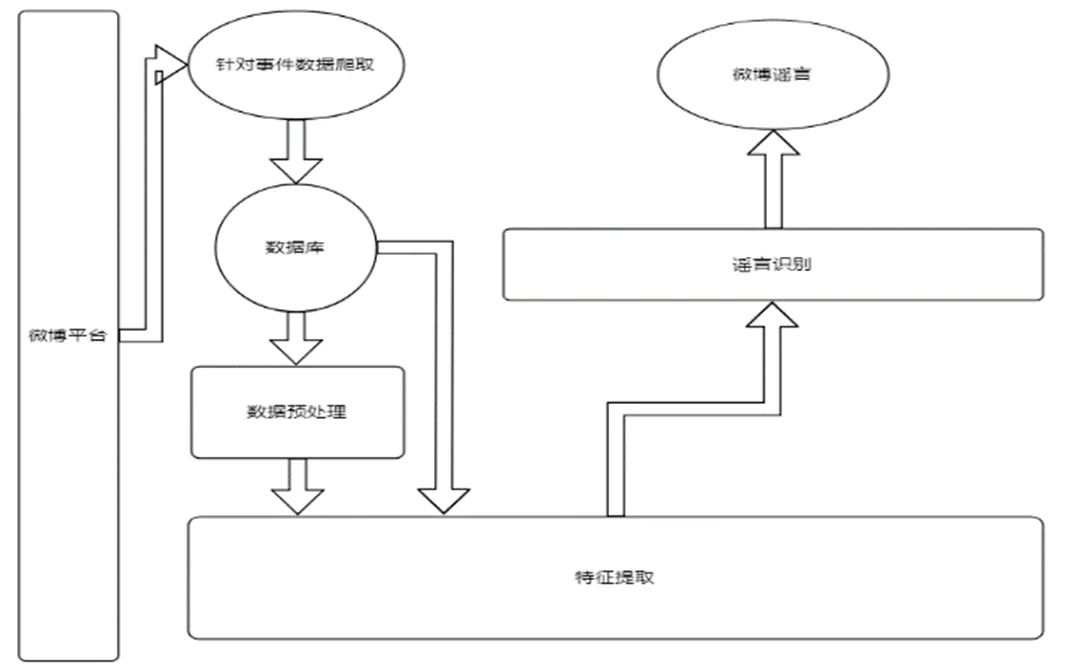
图2 微博谣言实验流程图
数据收集:爬取微博上对某一特定事件的网民博文与评论等文本信息,根据不同算法还可收集网页URL、用户基本信息、博文传播量的边缘数据;具体的数据收集方法可采用新浪API或是微博爬虫等手段。
数据预处理:在所获得的批量化的数据集中,往往存在大量无效数据,一般采取去重、剔除无关该事件文本等方式来对原始数据集进行预处理,提高数据集纯度,方便在后期数据特征分析阶段得到更加准确的实验结果。
特征提取和特征分组归类:特征分析是选取出最能够区分谣言与非谣言的特征以提高识别准确性。就谣言各项属性分类可细分为谣言内容特征、用户属性特征、谣言传播特征、谣言发布时间特征等。而就谣言文本内容属性分类可细分为关键词特征、符号特征、链接特征等相关特征。特征分类方式的不同对后续数据集分析的结果会有不同影响,应当就符合研究选定分析方法的分类方式进行特征分类。初期机器学习通常按照先验知识来确定区分谣言的特征,而深度学习方法则采取神经网络自动学习(CNN、RNN等)实现分类的特征。
数据集特征分析验证和谣言检测识别:通过结合各种机器学习算法对训练集数据特征进行学习再使用训练模型对测试数据集进行识别分析。对实验分析结果是否准确往往结合准确度(Precision)、召回率(Recall)和 F 值(F-Score)这三项数据对模型进行评判。
5 研究面临挑战与未来展望
目前谣言分析识别的研究取得较快发展,采用深度学习方法已经能将微博谣言识别的准确率、召回率、F1值等模型评价标准值提高到0.8以上,对谣言数据的特征分析也从符号、关键词等基础特征扩展到传播特征、时间跨度特征甚至时情感特征等影响识别精度的因素特征。但对微博谣言识别仍然有许多困难和挑战,比如有些微博博文的真实性尚未得到有效证实,无法判断是否是谣言。在面对这种存在歧义的情况时,如何将它与谣言以及是时区分开,就成了谣言识别的一项尚待解决的问题。多数研究员实验中的谣言数据是在突发事件结束后获取到的,虽能确保其有较高的识别准确性,但在实际应用中与现实问题存在差异,只有在网络谣言产生并传播的初期对其进行有效的识别判断,才能及时阻止谣言的传播,而早期谣言具有难以察觉、难以分辨的特性,因此早期网络谣言实时识别一项极具挑战的实际问题。而在完成了微博谣言识别判断的过程后,仍存在对所识别谣言的取证工作。在谣言传播的载体问题上,谣言的载体形式也在发生不断变化,不再仅仅是以文本为载体,更出现了通过图片甚至是视频形式传播的谣言。这就要求在未来的谣言识别实验中加入针对图片、视频等数据的内容分析与判断。
综上所述,当下机器学习算法领域已发展完善,且深度学习和人工智能领域在近几年也有重大研究突破,因此在解决微博谣言方面,又有了更多的解决方案和可能实现的新思路。而随着大数据时代的到来,研究员们在解决谣言识别问题上尝试新的算法,跟进算法领域新的研究方案。未来如果能够实现算法的自学习,并能够自动完成特定时间节点突发事件发生时微博中有关事件的数据特征提取分类,实现短时间内快速有效的谣言识别,降低人工成本,会成为谣言识别方面的重大突破成果。从单一事件的谣言识别到全网络全时段全事件的谣言监控,从个别社交平台谣言监控到多平台多方位谣言监控,那将极大改变目前网络谣言识别的现状,改善网络环境。
随着净化网络环境力度的加大,如何做到遏制微博谣言,避免网民因谣言受到非理性的错误引导,进而危害社会,为此面向谣言的识别研究就显得非常必要。本文从机器学习解决突发事件的谣言方面切入,阐述了研究的背景与突发事件谣言识别的意义,对国内有关机器学习应用于网络谣言识别的研究,做出回顾总结,结合网络谣言分析识别的一般流程,归纳相关研究的不足及日后主攻方向。在面对突发事件时,及时识别网络谣言是一个极具艰辛的任务,如何顺应大数据时代发展,实现算法自学习并在谣言产生初期完成其有效识别,还需研究专家不断实验探索,实现人工智能在谣言识别方面的应用。
[1]Yang F,Liu Y,Yu X,et al. Automatic detection of rumor on Sina Weibo [C]// ACM SIGKDD Workshop on Mining Data Semantics.ACM,2012:1-7.
[2]贺刚,吕学强,李卓,等.微博谣言识别研究[J].图书情报工作,2013,57(23):114-120.
[3]程亮,邱云飞,孙鲁. 微博谣言检测方法研究[J].计算机应用与软件,2013,30(2):226-228.
[4]姜赢,张婧,朱玲萱,等.网络谣言文本句式特征分析与监测系统[J].电子设计工程,2017,25(23):7-10+15.
[5]潘德宇,宋玉蓉,宋波.一种新的考虑注意力机制的微博谣言检测模型[J].小型微型计算机系统,2021,42(02):348-353.
[6]李莎,张怀文,钱胜胜,等.多模态多层次事件网络的谣言检测[J].中国图像图形学报,2021,26(07):1648-1657.
[7]陈耿,黄取治.半监督学习的微博谣言检测分析[J].电脑知识与技术,2021,17(15):12-13+19.
[8]首欢容,邓淑卿,徐健.基于情感分析的用户评论过滤模型研究 [J].数据分析与知识发现,2017,1(7):44-51.
[9]邓胜利,付少熊.网络谣言特征分析与预测模型设计:基于用户信任视角 [J].情报科学,2017,35(11):8-12,22.
