网络爬虫技术与策略分析
2022-07-26刘晓魁
◆刘晓魁
网络爬虫技术与策略分析
◆刘晓魁1,2,3
(1.安阳师范学院计算机与信息工程学院 河南 455000;2.甲骨文信息处理教育部重点实验室 河南 455000;3.河南省甲骨文信息处理重点实验室 河南 455000)
网络爬虫和网络反爬虫在博弈中不断成长,网络爬虫的存在已经成为网络信息时代一种常态。随着大数据和人工智能技术的出现,网络爬虫也越来越规模化和智能化,对网络爬虫的研究也要越来越明晰且与时俱进。本文对目前网络爬虫的特征、分类、所使用的工作流程和爬行策略进行梳理和比较,为网络爬虫提供较全面的总结,为进一步研究网络爬虫和网络反爬虫提供重要参考。
网络爬虫;爬虫技术;爬虫策略
网络爬虫是自动地抓取万维网信息的程序或者脚本。它是一个双刃剑。一方面,它提高了对网络数据的挖掘和分析检索能力。目前,在国内外,爬虫技术是搜索引擎的关键环节,是分析和获取网络数据非常有效的方式。甚至爬虫算法的优劣直接影响搜索引擎的性能。在开放融合的网络环境下,尤其是伴随大数据技术在互联网领域的广泛应用,爬虫已从搜索引擎应用拓展到了其他各个领域,成为大数据时代最重要的信息收集方式。比如商务智能上的企业市场信息收集;数据研究上的原始资料获取;网络舆情的信息收集等等。基于爬虫技术的就业信息管理平台、基于网络爬虫的上市公司交易数据共享平台、面向订票服务器端爬虫的可视检测等等应用陆续出现。爬虫技术在互联网领域之中的有效应用,对互联网技术的发展提供了助力。
但是对于开放融合网络环境下的资源网站,也存在快速被窃取的风险。Distil Networks发布的《2021 Bad Bot Report》报告指出,在2020年,互联网中有25.6%的流量是不遵守爬虫协议的恶意爬虫,而整个爬虫程序流量占互联网流量的40.8%之多。如图1为2021年互联网恶意爬虫流行报告。对于数据所有者,爬虫的过度爬取会严重消耗网络和机器资源,占用网站服务带宽,甚至导致核心数据泄漏、失窃。还会涉及版权甚至法律等层面的事件。曾经沸沸扬扬的,号称中国最大的用户画像关键数据服务提供商巧达科技,因为一个程序员的爬虫程序,导致整个公司200多人集体被抓。网络爬虫已经成为互联时代不能被忽视的问题。网络爬虫的入门门槛很低,网上有开源的爬虫可以直接使用,也是导致目前互联网爬虫横行的重要原因。
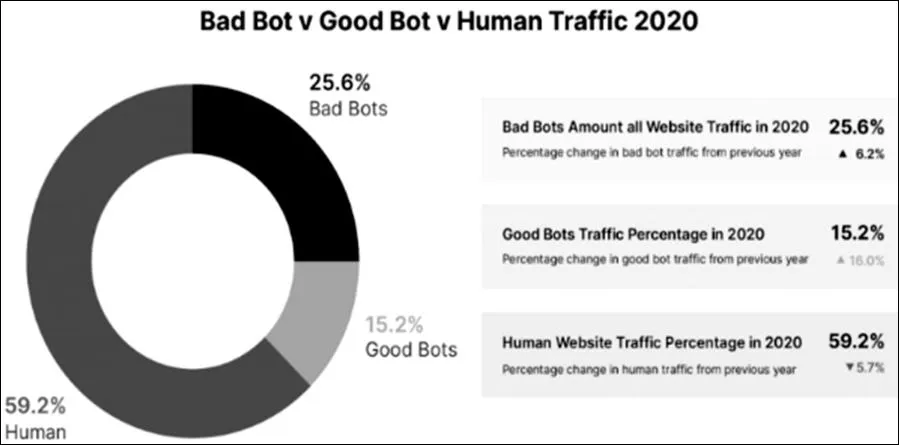
图1 2021年互联网恶意爬虫流行报告
(来源:https://www.imperva.com/blog/bad-bot-report-2021-the-pandemic-of-the-internet/)
1 当前网络爬虫的特点
1.1 当前网络爬虫的特点
网络爬虫已经与互联网相伴相生、密不可分。伴随着大数据和智能化技术的发展,当前网络爬虫越来越向规模化和智能化方向发展。网络爬虫不只是会对开放融合环境下的海量数据进行数据爬取和存储,还会通过对数据的抽取、标注、去重、去噪、关联、转换等清洗过程,将数据转换成结构化的标准数据,为了得到更有价值的数据,可以进一步对数据进行分析和挖掘。融合贯通开放融合环境下的互联网数据孤岛,最终呈现出更加宏观和专业的数据挖掘可视化成果,可以作为决策和判断的重要依据。各种专业的爬虫网站和平台不断涌现;各种语言开发的爬虫工具也层出不穷。无恶意的普通爬虫和不遵守爬虫协议的恶意爬虫分散在互联网中,几乎占据所有网络流量的2/5强。如果没有任何限制,网络爬虫的发展几乎是一发而不可收的。
1.2 网络爬虫面临的法律背景
在相应的法律建设方面,几个重要事件对网络爬虫产生了巨大影响。首先是自2017年6月1日起开始施行的《中华人民共和国网络安全法》,为网络空间主权和国家安全、社会公共利益提供了整体的法律基础,同时也在保护公民合法权益,促进经济社会信息化健康发展提供了保障,也为网络爬虫的发展提供了方向指引。特别是在个人信息的搜集方面,无论是有意的搜集还是恶意的爬取,都将面临法律层面更加严格规范的监管甚至是裁决。另外,我国首部关于数据安全的法律《数据安全法》,已定于2021年9月1日正式施行,为爬虫限制了明确的法律边界,可以说对网络爬虫的影响意义深远,标志着我国数据安全领域将进入有法可依的时代。我们也相信网络爬虫技术也会在合法合规的环境下会更加健康的发展。
2 网络爬虫技术的分类
虽然随着网络爬虫技术的发展,其手段不断翻新。可以根据所采取的主要技术手段将现阶段网络爬虫分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫和深层网络爬虫4种类型。
2.1 通用网络爬虫
通用网络爬虫常见于大型搜索引擎中,通常爬取互联网中目标资源的范围较广、涉及的数据量很大,对爬虫服务器的性能要求非常高。通用网络爬虫一般由爬取对象初始网络地址、爬取URL队列、页面爬取模块、爬取内容数据库等构成。
通用网络爬虫实施的过程如图2所示。首先确定初始网络地址,然后爬取初始网络地址页面内容存储到数据库中,并将新发现的URL地址加入URL列表中。然后判定是否满足停止条件,如果不满足停止条件,就在URL列表中选择下一个URL地址,并使用新URL地址爬取网页内容,然后从新网页中获取新的URL地址放到URL列表中,URL列表中的顺序一般是按照时间默认自动延续追加的,最终会穷尽到无法获取新的URL地址或者满足停止条件结束。

图2 通用网络爬虫工作流程图
2.2 聚焦网络爬虫
聚焦网络爬虫,顾名思义是聚焦到特定主题目标网站或页面的特定信息进行爬取的网络爬虫。一般是由初始网络地址、页面爬取模块、爬取内容数据库、无关链接过滤、URL优先级排序等构成。相对于通用网络爬虫增加了无关链接过滤和URL优先级排序环节,更加高效和具有针对性。
聚焦网络爬虫实现过程如图2所示。首先确定初始网络地址,然后爬取初始网络地址页面内容存储到数据库中,并将新发现的URL地址经过无关URL链接过滤,如果不符合过滤条件将新发现URL地址加入URL列表,并重新进行URL优先级排序,然后判断是否符合结束条件,如果经过无关URL链接过滤符合过滤条件就将新发现URL地址遗弃,并直接判断是否符合结束条件。如果不满足停止条件,就在URL列表中选择下一个URL地址,并使用新URL地址爬取网页内容,最终穷尽到无法获取新的URL地址或者满足停止条件结束。
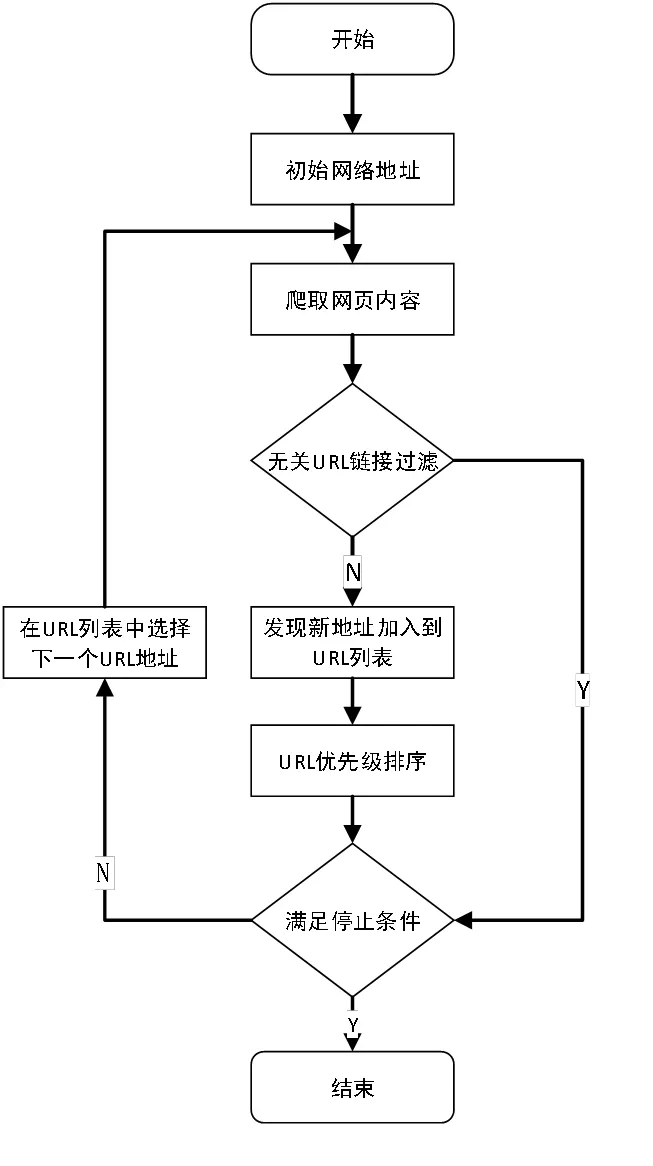
图3 聚焦网络爬虫工作流程图
2.3 增量式网络爬虫
增量式网络爬虫是指对已下载网页采取增量式更新的爬虫。它只爬取新产生或发生更新的页面。
这与聚焦网络爬虫存在相似的地方是,聚焦网络爬虫中的无关URL链接过滤环节,对应在增量式网络爬虫中更加明确增加了爬取对象的本地页面数据库和本地URL集可以进行参照和对比。不用重新下载已经下载并且没有发生变化的页面,虽然爬行算法的复杂度有所增加,对爬虫服务器的性能要求比较高,本地存储的成本也有所增加。但是这不仅保持了爬取网页内容的及时更新,而且明显降低了爬虫工作量。
增量式网络爬虫的工作流程是首先确定初始网络地址,然后爬取初始网络地址页面内容存储到数据库中,并将新发现的URL地址与本地URL集可以进行参照和对比,如果URL未经爬取或者其对应内容已经爬取但是存在更新,就将新发现URL地址加入URL列表,并重新进行URL优先级排序,然后判断是否符合结束条件,如果不满足停止条件,就在URL列表中选择下一个URL地址进行循环爬取,最终穷尽到无法获取新的URL地址或者满足停止条件结束。
增量式网络爬虫实现过程如图4所示。
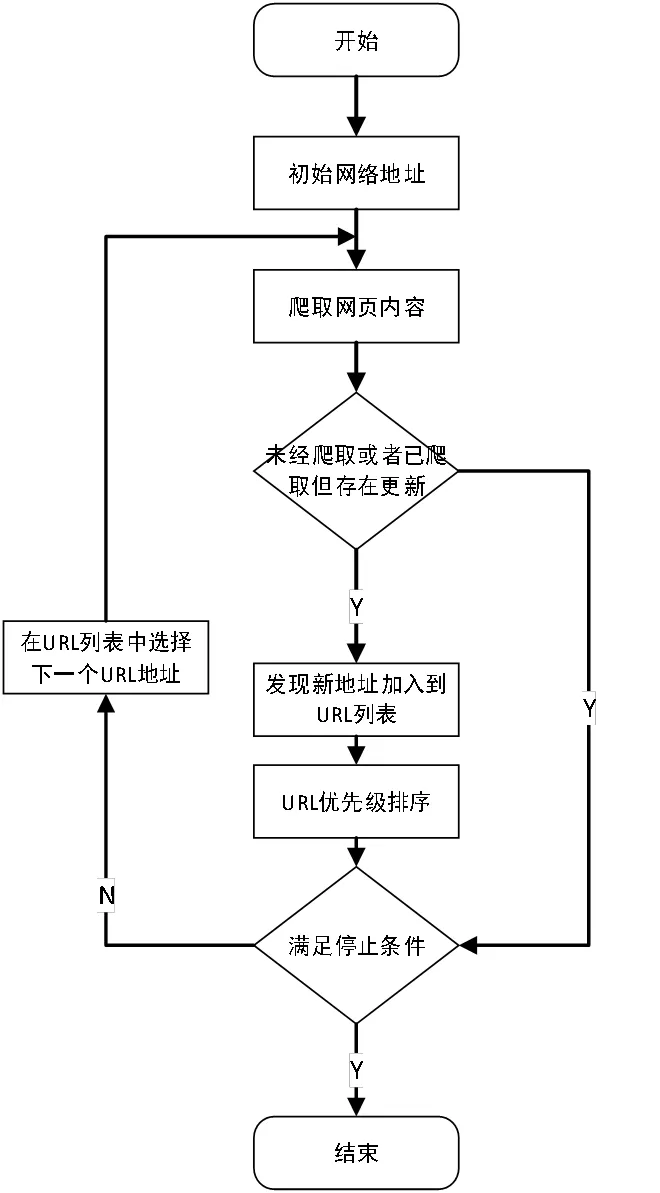
图4 增量式网络爬虫工作流程图
2.4 深层网络爬虫

图5 深层网络爬虫工作流程图
深层网络爬虫针对的是隐藏在表单后面,需要提交关键词之后获取到的页面。表单填写是深层网络爬虫最重要环节。
相对于其他网络爬虫,最典型的特征就是具有自己的表单数据源集合。经过表单的分析处理,可以进行表单的自动填充和提交。其实现过程如图5所示。
按照表单填写内容不同深层网络爬虫可以分为两种:一种是基于领域知识的表单填写。需要建立一个关键词库,并根据语义分析填写关键词;还有是基于对网页结构分析对表单进行自动填写,在领域知识有限的情况下往往使用这一种。
3 常见爬行策略
爬行策略通常是指爬取URL列表时爬取顺序的策略。常见的爬行策略主要有深度优先爬行策略、广度优先爬行策略、大站优先策略、反链策略、网页更新策略、用户体验策略、历史数据策略等。爬取顺序对通用网络爬虫来说作用并不明显,但是对其他爬虫非常重要,比如聚焦网络,爬虫爬取的顺序影响到无关URL链接地址过滤和URL优先级排序,严重影响到爬虫的效率和优劣。下面简单分析它们各自的特点。
深度优先爬行策略爬取时会将网页的下层链接依次进行深入爬取,达到边际时返回上一个节点再横向进行链接爬取。具体过程如图6和图7。这里是假设网页W1至W6及链接情况如图6,按照先走左子树约定,其深度优先树状遍历过程如图7。按照深度优先爬行策略,其爬取次序为:W1->W2->W4->W5->W3->W6。
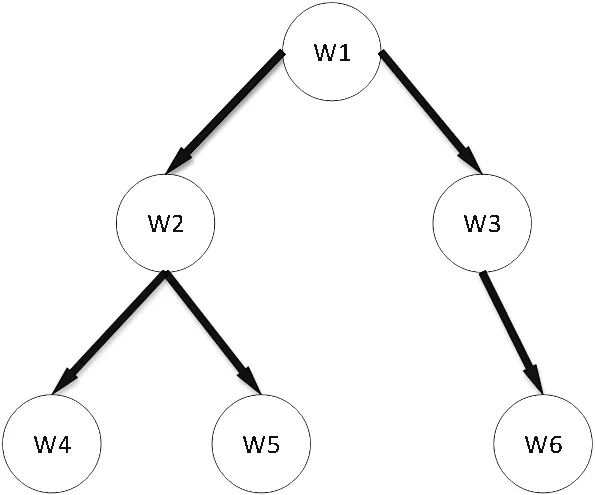
图6 网站链接架构示例图

图7 深度优先树状遍历步骤示意图
广度优先爬行策略,会先爬取同一层次广度的网页,将同一层次广度的网页爬取完成后,再选择下一个层次广度的网页进行爬取。从树结构上看,广度优先遍历就是对树的层次遍历。这种策略理解起来比深度优先策略容易得多。
大站爬行策略是会优先爬取网页数量更多的大站。一般来说越是大站,其内容更丰富,专业性更强,影响力更大,所以对它们优先进行爬取。
反链策略是优先爬取反向链接数更多的网页。这种策略的前提是需要可靠的反向链接数。反向链接基本上能代表着具有其他网页更多的推荐,但是现实中存在大量垃圾站群互相链接,使得有些站点可以获得异常高的反向链接数,所以这种策略很少单独使用。
网页更新策略是增量式网络爬虫经常采用的策略,是根据网页更新的速度和同类网页更新频率等进行区别和分类。当爬取网站的频率与网站更新的频率越接近,无效损耗越小。网页更新策略又可以通过采用的技术手段分为历史数据分析、用户体验分析和聚类分析三种。历史数据分析是根据网页历史更新的数据来预判网页更新爬取的周期。用户体验分析,是从用户体验的角度优先爬取用户搜索引擎关键词查询排名靠前的网页,需对网页多个历史版本的内容更新、搜索质量进行分析,这两种策略都需要历史数据作为依据,对新网页无效。网页的历史信息的保存和分析,都给爬虫服务器带来更多的负担和消耗。聚类分析是把具有类似属性的网页聚类进行抽样来确定对每个聚类的爬行频率。这比用户体验分析和历史数据分析的效率要高很多,对系统的损耗也更小,但是,因为是抽样检测,聚类操作,准确度可能会有所降低。聚类分析就是网页更新策略在效率和性能之间一种比较平衡的方法。
4 结语
面对信息大爆发、爬虫横行的状况,必须分析掌握爬虫的工作机制和原理,才能更好使用和处理网络爬虫,面对网络爬虫带来的威胁做出全面深入的发爬虫策略,形成一套更加科学的爬虫防范机制。本文对目前网络爬虫的特征和分类,所使用的工作流程和爬行策略进行了梳理和比较,为网络爬虫提供较全面的阶段性总结,为进一步研究网络爬虫和网络反爬虫提供了重要的参考。
[1]2021 Bad Bot Report [EB/OL]. https://www.imperva .com/resources/reports/Bad-Bot-Report 2021.
[2]刘清. 网络爬虫针对“反爬”网站的爬取策略分析[J]. 信息与电脑(理论版),2019(03):23-24.
[3]张渊博. 网站反爬虫策略的分析与研究[J]. 电子元器件与信息技术,2021,5(01):14-15.
[4]胡俊潇,陈国伟. 网络爬虫反爬策略研究[J]. 科技创新与应用,2019(15):137-138+140.
[5]李岚清,王恒,晏晓峰. 网络资源自动采集技术研究[J]. 电子元器件与信息技术,2020,4(05):56-58.
[6]文成香,李璋林. 网络爬虫针对“反爬”网站的爬取策略研究[J]. 数码世界,2020(06):270.
[7]张晔,孙光光,徐洪云,等. 国外科技网站反爬虫研究及数据获取对策研究[J]. 竞争情报,2020,16(01):24-28.
[8]李慧敏,孙佳亮. 论爬虫抓取数据行为的法律边界[J]. 电子知识产权,2018(12):58-67.
国家自然科学基金资助项目(61806007,U1804153);河南省科技攻关项目(182102310039);教育部产学合作项目(202002057009);“甲骨文信息处理”教育部创新团队(2017PT35);河南省特色骨干学科(甲骨文信息处理)
