一类基于定向Q-Learning的后5G无线网络上下行多业务并发功率分配方法
2022-07-23还婧文杨少石袁田浩孟阔毕嘉辉唐玉蓉
还婧文,杨少石,2*,袁田浩,孟阔,毕嘉辉,唐玉蓉
(1.北京邮电大学信息与通信工程学院,北京 100876;2.泛网无线通信教育部重点实验室,北京 100876;3.中国移动研究院,北京 100053)
1 引言
为了满足未来无线通信系统面向多类型业务的灵活需求,文献[1][2]提出使用灵活双工技术来增强系统性能,这在赋能垂直行业的公网、专网联合部署环境中尤为重要。然而,当两个基于动态时分双工(Dynamic Time Division Duplexing,D-TDD)技术的相邻小区具有相反的传输方向并且共享相同时频资源时,可能会发生严重的小区间干扰,这种现象被称为交叉链路干扰(Cross-Link Interference,CLI)。它包括下行链路(Downlink,DL)到上行链路(Uplink,UL)的干扰和UL到DL的干扰。
5G赋能垂直行业的一个重要场景是工业物联网,其中多种不同类型的业务(如语音业务、数据业务和视频业务)在不同传输方向上并发成为常态。在后5G时代的无线网络中,使用D-TDD技术进行灵活的业务自适应传输有助于提高系统的传输资源利用率,但这也会导致复杂的CLI问题。如何进一步优化无线资源管理算法,有效缓解CLI问题带来的负面影响,是一个迫切需要研究的重要问题。
此外,对于不同的业务需求,优化的目标函数一般不同,这将增大无线资源分配问题的复杂性。为此,基于体验质量(Quality of Experience,QoE)对5G网络的资源管理技术进行性能评估[3]得到业界的广泛认可。平均意见分(Mean Opinion Score,MOS)是一种使用最广泛的QoE指标[4]。通过为不同类型的业务提供通用测量尺度,MOS使跨不同特征的业务进行综合业务管理和资源分配成为可能[5]。
Q-Learning可以通过与环境交互获得的即时回报生成接近最优的解决方案。通过优化当前奖励实现长期优化目标对于动态变化的复杂无线网络的资源管理至关重要。在用户数动态变化时,新用户加入后如何更有效地分配基站及用户的发射功率是后5G研究中的一个难点。针对此问题,有研究者提出了认知学习的思想,该思想允许新用户从提前接入小区的用户那里学习,以改进学习过程[6]。
总的来说,现有的很多针对多小区场景下的功率分配方法仅仅围绕干扰消除展开,并没有考虑用户业务类型需求不同的情况。因此,本文对多小区无线网络中上下行多业务并发场景下的功率分配方法进行研究。首先,给出了宏小区用户和微小区用户的语音、数据以及视频业务的系统模型、业务模型以及评价指标。其次,基于Q-Learning对多业务并发时的基站和用户发射功率进行分配,基于Q-table的更新方式提出了三种定向学习方法。最后,将设计的三种定向学习方法与无定向学习能力的原始Q-Learning算法进行比较分析。仿真结果显示本文提出的方法在保证系统合理的MOS值和拥塞率时,降低了算法收敛所需的迭代次数,提升了算法收敛性能。
2 系统模型
本文所考虑的系统模型如图1所示,包含两个小区(宏小区和微小区)。宏小区的传输方向为DL,信号由宏基站(Macro Base Station,MBS)发送给宏小区用户(Macro-cell User Equipment,MUE)。微小区的传输方向为UL,微小区用户(Small-cell User Equipment,SUE)将信号上传至微基站(Small Base Station,SBS)。宏小区和微小区的用户数分别为K和L。
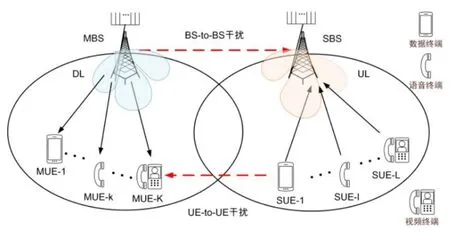
图1 系统模型示意图
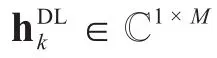
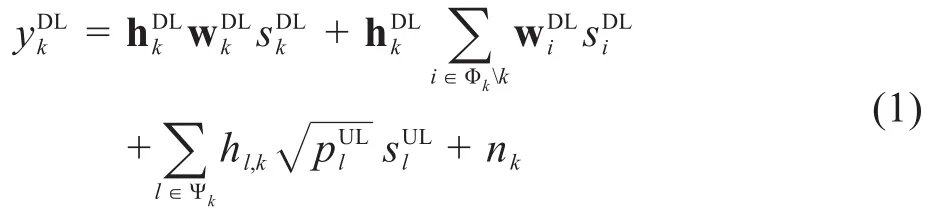
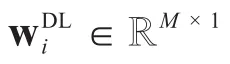
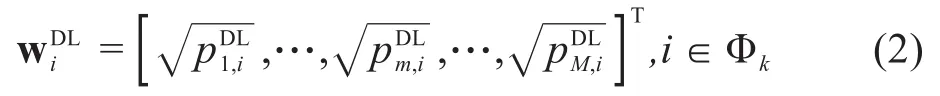
另一方面,SBS以第l个SUE为目标用户时的接收信号为:
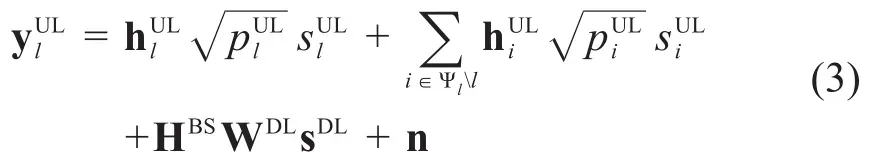
下面根据接收信号模型对信干噪比(Signal to Interference plus Noise Ratio,SINR)进行推导。第k个MUE的SINR为:
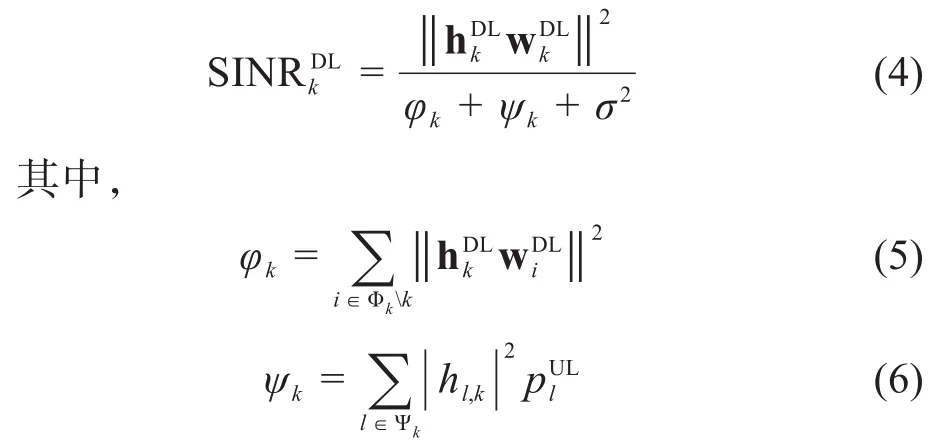
相似地,SBS以第l个SUE为目标用户时的SINR为:
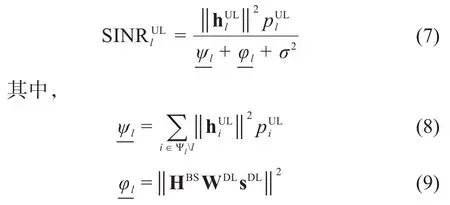
根据上述推导结果,第k个MUE的速率可以表示为:
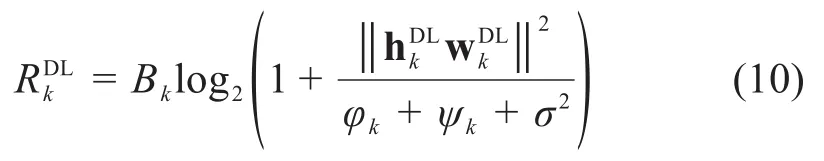
其中,Bk是第k个MUE的带宽。第l个SUE的速率表示为:
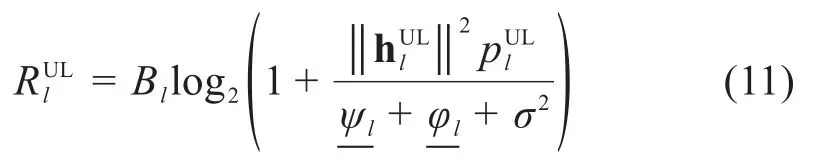
其中,Bl是第l个SUE的带宽。
3 基于Q-Learning的混合多业务功率分配
3.1 业务模型
本文的目标函数要求针对不同的业务将包括数据速率、误包率(Packet Error Probability,PEP)、峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)等在内的评价参数映射到MOS。语音业务、数据业务和视频业务的具体映射关系如下所述。
1.语音业务。确定语音业务质量的传统方法是进行主观测试。这些测试的结果进行平均得出MOS,但此类测试成本高昂,不适用于在线语音业务质量评估。因此,ITU-T提出了一个标准化模型,即语音业务质量的感知评估(Perceptual Evaluation of Speech Quality,PESQ)[7],这是一种能够以高度相关性预测典型主观测试中给出的质量分数的算法。然而PESQ算法在计算上过于昂贵,无法用于实时场景。为了解决这个问题,Giupponi等人提出了一个模型来估计MOS与传输速率R和PEP的函数[8,Fig.2]。本文中,我们以MOSu来表示语音业务的MOS值,其具体数值及与传输速率R的对应关系,可由文献[8Fig.2]中给出的PEP值确定。
2.数据业务。为了估计数据业务的用户满意度,本文使用对数形式的MOS与传输速率的关系[9],它是传输速率R的递增严格凹连续可微函数[8,Fig.3]。
基于系统提供给用户的R和PEP来估计MOS,具体计算公式如下:
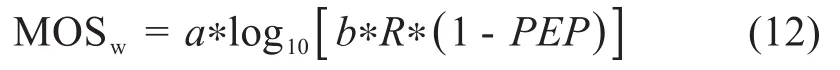
式中,a和b由用户感知质量确定。通过R和PEP来计算MOS。
3.视频业务。对于视频业务质量进行评估的现有技术很多,其中ITU对多媒体业务质量进行了主观评估。PSNR作为一种视频业务质量的评价指标,被普遍用来客观地衡量视频的编码性能。然而,PSNR不能准确反映人类对视频质量的主观感知。PSNR和MOS之间具有线性映射关系[8,Fig.2],它为40 dB及以上的PSNR分配的MOS值为4.5,为20 dB及以下的PSNR分配的MOS值为1。上限来自这样一个事实,即PSNR为40 dB的重建视频序列几乎无法与原始视频序列区分,低于20 dB的视频序列会因严重的退化而失真[8]。因此如果使用客观指标(例如PSNR)测量图像失真,可以使用以下逻辑函数来表征MOS和PSNR之间的关系[10]:
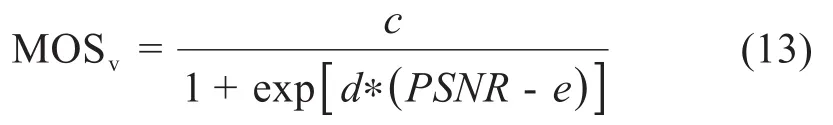
其中,c、d和e是函数的参数,取c=6.6431,d=-0.1344和e=30.4264。本文选择log函数来评估视频的质量。为了表征重建视频的PSNR随传输速率的变化,得到关系如下:
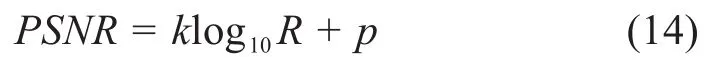
其中k和p是常数。
3.2 优化目标
由于MOS作为所有类型业务的通用质量评估指标[11],允许以集成方式用于为所有类型的业务分配传输资源,因此本文将语音、视频和数据业务评价指标统一化为:
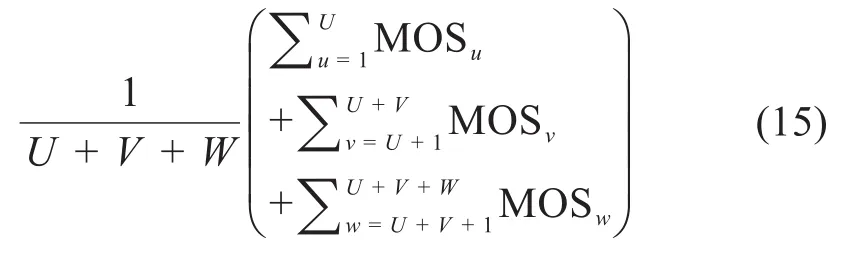
其中,U是语音业务用户的数量,V是视频业务用户的数量,W是数据业务用户的数量。在这种情况下,即使系统性能最大化,也有可能无法满足给定用户的需求,这可能是因为其SINR过低,导致传输资源被分配给其他用户,这与试图为用户提供的公平性相矛盾。为了解决这个问题,本文根据估计的MOS历史值选择公平系数λui、λvi和λwi。假设当前处于分配步骤Z中,系统中某业务有Q个用户,用户的最大MOS值:
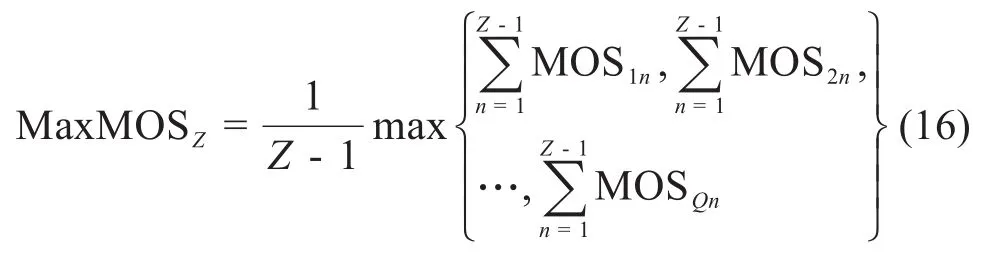
用户的公平系数的计算式如下:
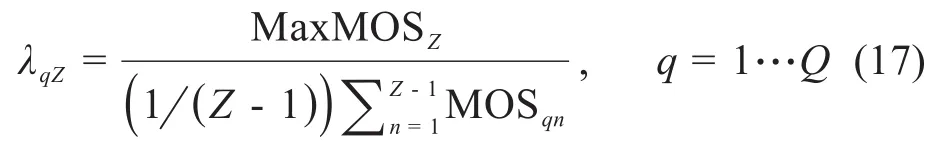
因此,具有最大MOS值的用户公平系数为1。由于分母在区间[1,4.5]内变化,所以其他用户的公平系数在[1,4.5]范围内,给在当前优化步骤之前MOS较低的用户提供更多的资源来确保公平性。通过使用相应算法求解以下优化问题,来获得最佳功率分配方案,以使目标函数最大化,即最大化系统平均MOS性能:

其中,λ表示三种业务的公平系数。公式(19)表示MBS的M根天线对于K个MUE的发送功率之和小于基站的最大发送功率;公式(20)表示SBS给每个SUE分配的发送功率要小于其本身最大的发送功率;公式(21)表示语音业务的用户需满足文献[8Fig.2]所示的四种语音编码器其中一个的速率,即Ru,min的值为6.4 kbit/s、15.2k bit/s、24.6 kbit/s、64 kbit/s;公式(22)(23)分别表示视频业务和数据业务的用户速率需满足的传输速率。
3.3 算法设计
Q-Learning定义一组状态(State)S、一组动作(Action)A和奖励函数(Reward)R,奖励函数表示所选动作对环境的影响。每个代理(Agent)将从A中选择下一个Action。在本文的系统模型中,Agent对应于MBS,它的每根天线均给多个MUE分配下行功率,并告知SBS如何为每个SUE分配上行功率,这些功率的分配对应A。本文的目标函数对应奖励函数,反映了系统的QoE;约束条件对应状态S。MBS在可行域中对功率的有限离散空间进行搜索。本文选择Q-Learning强化学习方法来解决前述功率分配问题。MBS获取环境当前状态S,并相应地在特定策略π下采取行动a,也就是π(s)→a,即时奖励为R(a,s)。然后,使用折扣(discount)因子γ(0<γ<1)来最大化未来奖励,该因子代表未来奖励的重要性。在满足约束的情况下,MBS将寻求一个最优分配,以最大化目标值。
此外,定义系统拥塞率来表示系统学习性能:
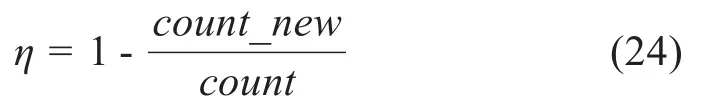
其中,count_new表示新用户加入后成功学习(当Q-table值保持不变时)的次数,count表示新用户加入前原有用户成功学习的次数。
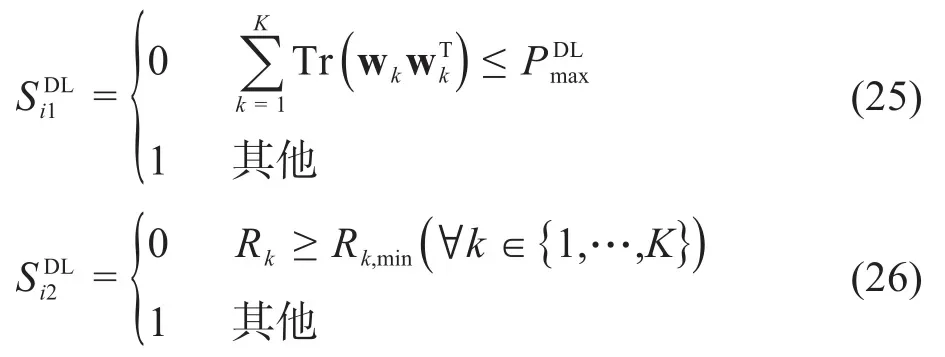
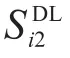
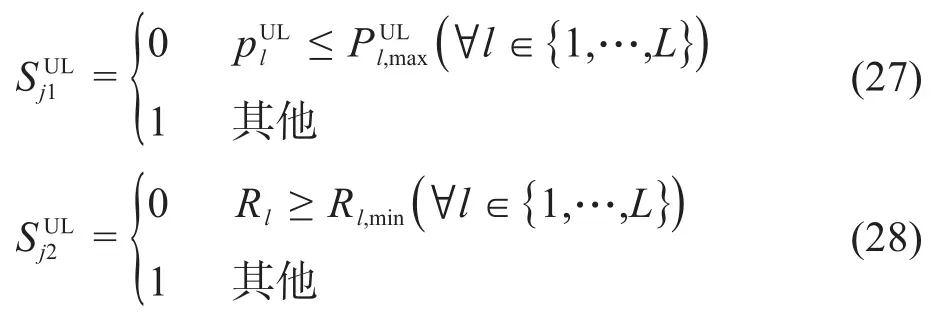
第t次的即时奖励表示为:
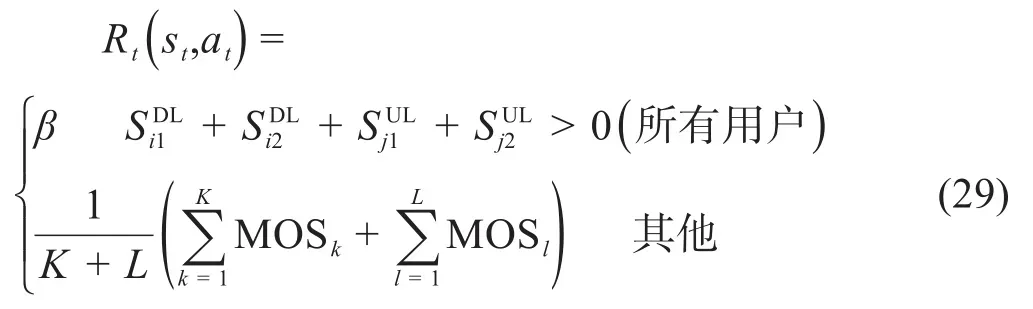
其中,β是一个小于任何其他策略奖励的常数,取0.01表示采取了违反约束的不成功操作。当满足约束时,式中的值为语音业务、数据业务和视频业务的平均MOS值。Q-table更新函数表示为:
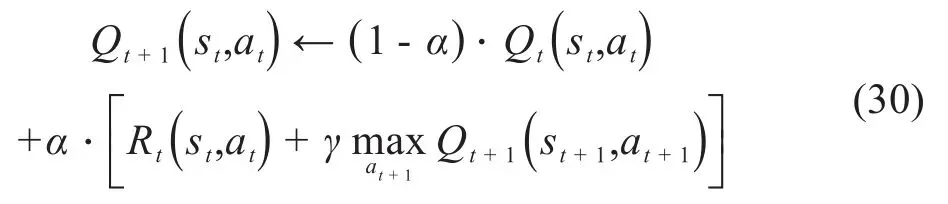
式中α是学习效率,0<α<1。公式(30)中出现的最大化表示在所有可能的Action中选择使Qt+1最大的at+1。基于Q-Learning的无线网络资源分配具体流程如图2所示。
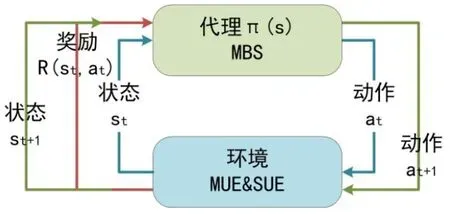
图2 基于Q-Learning的无线网络资源分配流程
本文的算法旨在对系统中新加入的多业务用户进行功率分配,。为使Q-Learning算法满足环境变化,本文引入定向学习能力,也就是说,对新加入用户的三种业务进行针对性的学习方式设计。每个新加入的多业务用户首先了解其周围环境,然后由MBS继续选择与最大奖励相关的Action,通过运行Q-Learning获得所选行动的奖励,最后根据收到的即时奖励更新Q-table。对于解决特定系统问题,具有更多“经验”的节点将教授能力较差的节点,以减少学习时间,同时提高学习性能的思想被称作docitive[12]。本文所提三种学习方式如下所述。
第一种为相同业务类型定向学习,取相同业务类型用户的Q-table均值作为新用户的Q-table;第二种为最近用户定向学习,选取距离新用户最近的用户的Q-table作为新用户的Q-table;第三种为随机选择定向学习,在原始用户中随机选择某个用户的Q-table作为新用户的Q-table。已经存在于网络中的用户使用Q-Learning算法学习Q-table。新用户加入后,利用上述三种方案,获取新用户的Q-table。算法详细过程描述如下:
步骤一:初始化学习效率α、discount因子γ、Q-table;初始化带宽B,MBS、SBS位置;MUE、SUE随机撒点;初始化信道矩阵。为当前所有用户随机分配业务类型。

步骤三:根据π(st),在当前状态st的所有可选行动中选择一个作为at。
步骤四:计算给定参数下生成的速率、MOS值集合。
步骤五:系统移动到下一状态st+1,反馈即时奖励值R(st,at)。
步骤六:在新状态上选择使Q-table值最大的行动at+1。
步骤七:更新Q-table。
步骤八:新用户加入,方法一是取与新用户相同业务类型用户的Q-table取均值赋给新用户;方法二是取与新用户最近用户的Q-table赋给新用户;方法三是从原有用户中随机选择一个Q-table赋给新用户。
步骤九:将新状态更新为当前状态,重复步骤三到步骤七,直到Q-table值保持不变。并判断为成功学习。
4 仿真结果分析
仿真参数如表1所示,在仿真过程中宏、微小区的原有用户数保持不变,原有用户的业务类型和新加入系统的用户的业务类型均随机分配,新加入用户数为1。
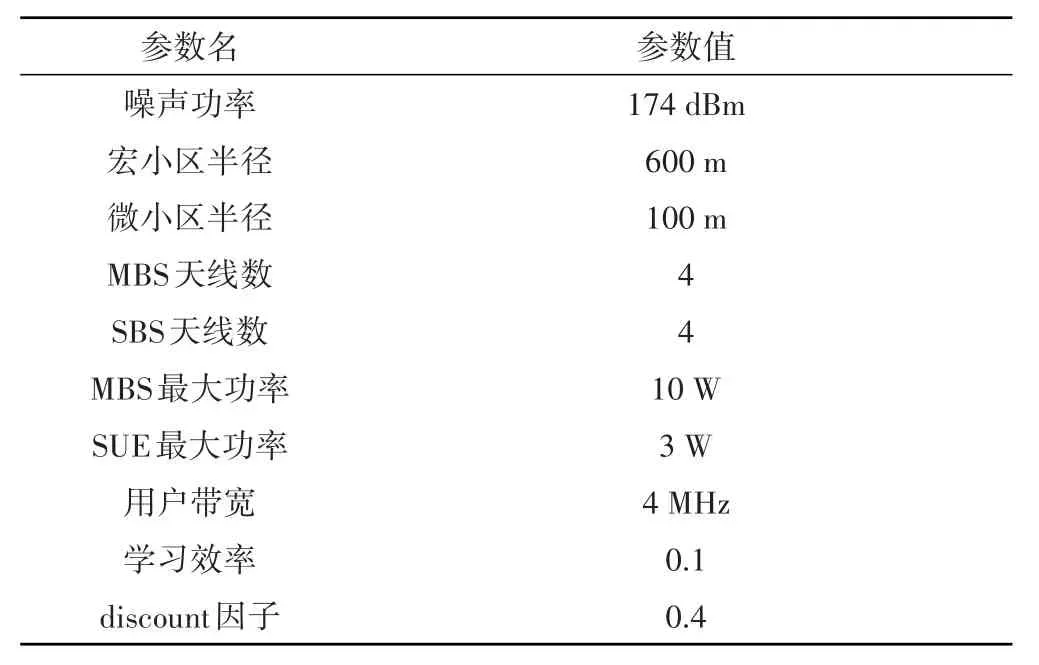
表1 仿真参数
图3所示为当其他系统参数保持不变,令系统原有用户数分别从4,8,12,16,20,24变化(新加入1个用户后总用户数为5,9,13,17,21,25),系统新加入用户业务类型随机分配时,分别以无定向学习、相同业务类型定向学习、最近用户定向学习以及随机选择定向学习四种算法进行平均MOS变化仿真。从图中可以观察到:
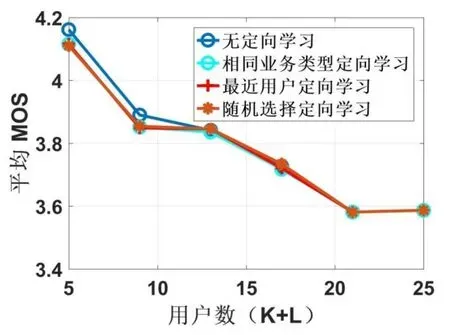
图3 各用户数下的平均MOS
1)随着用户数的增加,四种不同学习方式所实现的系统平均MOS值均在减小,这意味着新用户无论是无定向学习,还是选择相似业务类型的用户进行定向学习,选择最近的用户进行定向学习,随机选择用户进行定向学习,用户数的增加均会造成系统性能的降低。
2)随着用户数的增加,无定向学习能力的Q-Learing算法在用户数较少时(图中看少于13个)可达到的系统性能较引入定向学习能力的算法略高。但是当用户数增加时,几种方式区别不大。考虑到当用户数增加时,无定向学习能力的算法复杂度比所提出的定向学习方法显著增加(如图5所示),这与其系统性能上所取得的微弱优势几乎抵消,而且定义的不同业务公平系数的引入会增加定向学习算法的最终平均MOS值,最终导致用户数增加时各算法性能差别不大。
3)三种不同定向学习能力的Q-Learning算法在系统平均MOS值性能上差别不大,这主要是因为三种算法在新用户刚加入时对Q-table的更新上具有差别,在后续的Q-table值更新上是没有区别的,最终达到的系统性能也不会有明显差别。
4)该仿真结果还表明,我们设计的三种基于Q-Learning资源分配算法均获得了较高的MOS值(始终高于可接受的MOS水平,包括仿真中存在最多的用户数的情况)。
图4所示为当系统用户数逐渐增加时,所定义的系统拥塞率的变化。可以看出:
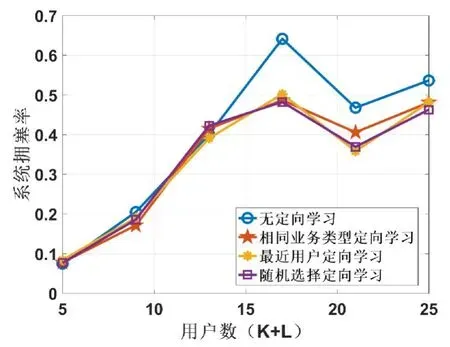
图4 各用户数下的系统拥塞率
1)该结果可以用于确定对系统拥塞率有要求时的用户数目的选择范围。基于此图所示结果,如果要求网络以预定义的拥塞率运行,则引入定向学习的解决方案始终能接受更多的用户数。
2)无定向学习的拥塞率较定向学习更高些。这是由于无定向学习算法中当新用户加入时,原有用户的Q-table会清空,继而随着新加入的用户重新分配资源,会加大算法的复杂度,导致拥塞率增加。
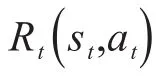
图5所示为用户数增加的过程中几种算法的效率(或计算复杂度)对比,分别展示了新用户加入后不同算法的迭代次数。可以得到如下结论:
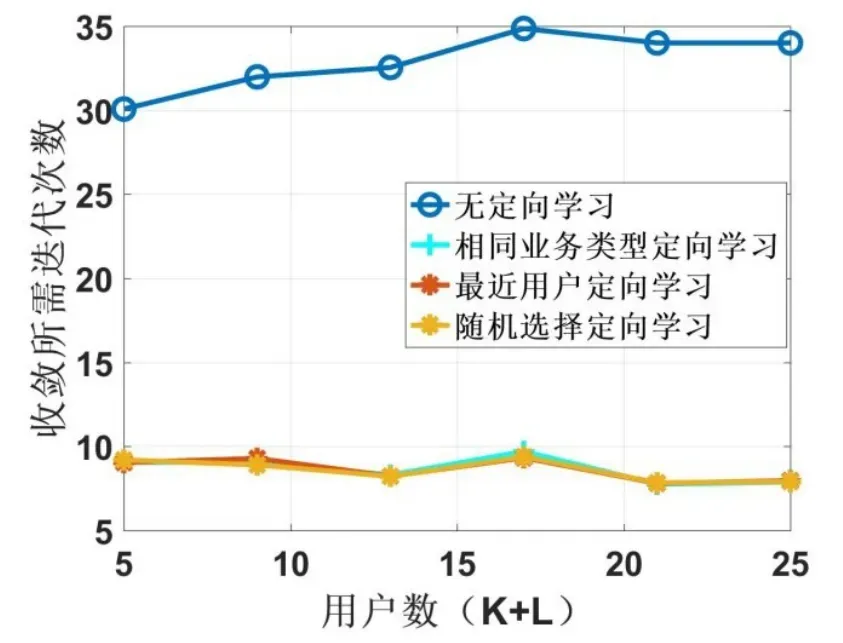
图5 各用户数下的迭代次数
1)本文所提三种定向学习算法能够将算法的平均收敛迭代次数减少约2/3。
2)本文所提三种定向学习算法的复杂度几乎相同,只是选择学习的方式不同。这是由于定向学习通过有经验的用户将对周围环境的感知准确地转化为新用户的Q-table,并减少实现收敛所需的迭代次数。可以看出,与加入定向学习能力前的无学习能力算法相比,实现收敛所需的迭代次数减少达65%。
5 结论
本文针对后5G无线网络对上下行多业务的并发需求,利用MOS作为多业务用户的QoE评价指标,将多业务资源分配的优化目标统一化,给出了解决上下行多业务并发系统性能优化的目标函数,并提出了一类具有定向学习能力的Q-Learning方法对多业务用户基站侧和用户侧发射功率分配进行优化。由于当系统中加入新用户时发射功率需要重新分配,本文在原始Q-Learning算法的Q-table更新方式上进行了三种改进,分别取与新用户相同业务类型用户的Q-table取均值赋给新用户;取与新用户最近用户的Q-table赋给新用户;从原有用户中随机选择一个Q-table赋给新用户。将所设计的三种定向学习算法与无定向学习能力的Q-Learing算法进行了比较分析,可知在平均MOS值方面,所有用户进行定向学习与无定向学习算法系统性能差别不大;在算法的系统拥塞率方面,定向学习算法低于无定向学习;在算法所需迭代次数方面,定向学习算法可将迭代次数大大降低。综上所述,改进后的算法在用户数动态变化的场景下,在保证合理的系统MOS值和拥塞率的同时降低了迭代次数,提高了算法收敛性能。
