基于改进BCCSA 和深层LSTM 的空气质量预测方法*
2022-07-22韦诗玥徐洪珍
韦诗玥,徐洪珍
(东华理工大学 信息工程学院,江西 南昌 330013)
0 引言
随着社会的发展和生活质量的提高,人们不再是关注温饱问题,更多地开始关注健康问题。被污染了的空气会给人类健康带来危害,特别是在人口稠密的地区[1]。空气质量是一个十分复杂的现象,会受到许多因素的影响[2]。空气质量能够通过计算空气中的污染物来反映空气污染的严重程度,通常用空气质量指数(Air Quality Index,AQI)来进行定量描述。有效的空气质量预测能够为人们提供及时的空气质量警报,能够使政府部门及时干预高污染事件,能够提醒人们是否适宜进行户外活动。严重的空气污染不仅会影响人们的生活,更会影响人们的生命健康[3]。准确地进行空气质量预测对国家、政府、民众来说都是一件重要的事。
空气质量数据具有明显的季节性,如果忽视这一因素,会导致对空气质量数据的预处理不够充分并且预测精度不够高,所以本文提出季节调整的空气质量数据预处理方法。本文首次将二元混沌乌鸦搜索算法(Binary Chaotic Crow Search Algorithm,BCCSA)应用于空气质量数据的预测,能够更好地优化非线性、非平稳的空气质量数据,并针对BCCSA 存在的不足,提出3 种改进方法用以提高它的收敛速度。本文还将自注意力机制与深层长短期记忆神经网络(Long Short Term Memory,LSTM)相结合来预测经过处理的空气质量数据,能有效挖掘空气质量数据中隐藏的时间序列信息,提高了方法的预测精度。现有的研究大多都是对空气质量进行未来几个小时的短期预测,而本文对空气质量进行了未来24 小时的预测,并且具有较高的精度。
1 相关工作
传统的空气质量预测有数值方法和统计方法[4]。但是数值的方法计算量异常巨大,过高的计算代价成为数据模型最大的劣势;而统计的方法只使用历史污染物浓度和气象数据来建立统计关系,并未考虑物理过程[5]。相对于传统的学习算法,深度学习方法能从海量数据中进行学习,挖掘数据隐藏的信息,解决数据中存在的高维、冗杂等传统学习算法难以处理的问题。因而现在的研究者开始利用深度学习的方法来预测空气质量。
Belavadi[6]等人使用长短期记忆神经网络(Long Short Term Memory,LSTM)与循环神经网络(Recurrent Neural Network,RNN)构建了模型,并且结合了无线传感器网络共同对空气质量数据进行传输、预测。Sun[7]等人提出了一种基于多数据源动态空间面板的时空深度多任务学习空气质量预测模型。该模型将每个污染物浓度视为一个单一的预测目标,并通过多任务学习方法对所有这些单一目标进行联合和同时建模,这与现有的每次考虑一种污染物或为每种污染物建立独立模型的研究截然不同。Wu[8]等人提出了一种变分模式分解(Variational Mode Decomposition,VMD)和LSTM 相结合的模型来预测AQI。
2 提出的方法
2.1 季节调整
经过对空气质量数据进行分析发现,空气质量数据具有明显的季节性特征,例如PM2.5存在冬季高,夏季低的特性。所以本文提出季节调整的空气质量数据预处理方法,对收集的原始空气质量数据进行了季节调整以消除季节对预测的影响。这里的季节调整是一个从时间序列中估计和剔除季节影响的过程,进行季节调整能够更加准确地反映数据本身的基本趋势。为了直观地表现出空气质量数据的季节性,本文定义了季节指数,计算公式如下:

其中,Se 是季节指数,year_A 是历年同季平均数;c 是趋势值,这里的趋势值指的是水平趋势。
本文在进行预测前将原始空气质量数据除以相应的季节指数,以便更好地进行预测。最后再将空气质量预测结果重新乘以季节指数,就得到了真正的AQI 预测值。
2.2 改进二元混沌乌鸦搜索算法
BCCSA 可以解决非线性的现实优化问题,防止结果陷入局部最优。而空气质量数据具有非线性的特点,所以可以用来对空气质量数据进行优化处理,以便后期的预测更加精准。BCCSA 是在乌鸦搜索算法(Crow Search Algorithm,CSA)的基础上发展而来的,它克服了CSA 初始位置不均匀、求解精度低等缺陷。CSA 是一种群体智能优化算法,它的工作原理是乌鸦将多余的食物储存在隐蔽处,并在需要时取回[9]。
BCCSA 虽然在CSA 的基础上进行了改进,但是它依旧存在着一些不足。例如,感知概率(Awareness Probability,AP)和飞行长度(Flight Length,FL)都是固定值,这会抑制算法的性能。因此,本文对原始的BCCSA 提出以下改进,使算法在全局搜索和局部搜索之间保持良好的平衡,并提高收敛速度。
(1)动态调整AP。因为AP 影响乌鸦种群的多样性和个体集群化,AP 的值越小,算法就越偏向于局部搜索。所以本文决定对其进行动态调整,计算公式如下:

其中,iter 是当时的迭代次数,iterMax 是最大迭代次数。
(2)将FL 分段。因为本文动态调整了AP,使得其值越来越小,这虽然能够提高算法的收敛速度,但容易陷入局部最优。而FL 影响算法的局部与全局的搜索能力,FL 的值越大算法就越偏向于全局搜索。因为FL 最初被认为取值为2 时算法性能较好,所以当乌鸦的记忆与乌鸦位置离的很近时,设置FL 为2,否则就将FL 的值扩大。这样使得AP 与FL 互相配合,共同促进算法性能的改善。
(3)引入惯性权重因子。惯性权重因子随着时间变化线性减小,通过改变其值的大小来调整算法的搜索能力[10]。引入惯性权重因子也是为了平衡乌鸦种群的集群化和多样化,从而达到提高收敛速度的目的,也有利于算法寻找最优解。
惯性权重因子公式设置如下:
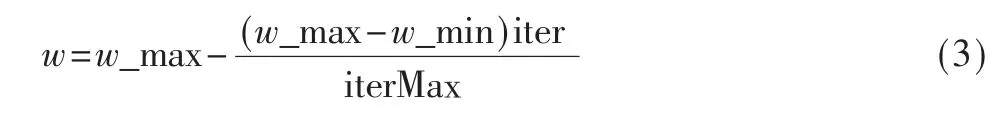
其中,w_max 是惯性权重因子的最大值,w_min 是惯性权重因子的最小值。惯性权重因子的值在[0,1]之间。
具体运用改进BCCSA 算法进行空气质量数据预处理的步骤如下:
(1)初始化参数,设置乌鸦种群数、最大迭代次数等。
(2)使用SineMap 混沌映射函数创建乌鸦位置,创建一个随机的乌鸦位置序列作为乌鸦记忆,将乌鸦位置由实数型向量转为离散的二进制向量,因为空气质量数据有7 个属性,所以使用7 个0~1 之间的随机数初始化第一个乌鸦位置。
(3)评估乌鸦位置的适应度,乌鸦位置的适应度使用的是随机森林模型,按空气质量等级分类做空气质量数据的多类别分类,其中空气质量数据作为训练数据X,空气质量等级作为标签Y,然后拟合X 和Y,将拟合的数据与X 和Y 做三折叠交叉验证,取验证结果的平均值M。
(4)开始迭代,按上文所述设置AP 和FL,引入惯性权重因子w,更新乌鸦位置公式为:
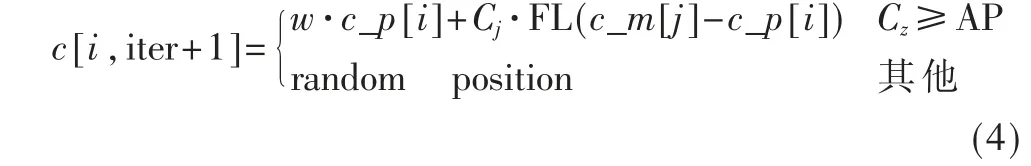
其中,c_p[i]是进行跟踪的乌鸦i 的位置,Cj和Cz为0~1之间的随机数,c_m[j]为被跟踪的乌鸦j 食物的藏匿地点。
(5)检查新位置的可行性,新位置处于0~1 之间,则可行,乌鸦则移动到新的位置。否则,乌鸦停留在当前位置,不移动到新的位置。
(6)使用步骤(3)评估乌鸦的新位置,如果乌鸦的新位置比记忆更好,则乌鸦通过新位置更新其记忆,新记忆即为得到的M 值。
(7)重复步骤(4)~(6),直到达到最大迭代次数为止。
(8)输出每只乌鸦最优适应度值对应的记忆。最终得到的所有乌鸦的记忆即为经过分析、选择的空气质量数据。
2.3 加入自注意力机制的深层LSTM 模型
LSTM 是对具有梯度消失问题的一般RNN 的一种改进。LSTM 内部有3 个门单元,分别是遗忘门、输入门以及输出门,它们的功能分别是:遗忘门决定进入的部分信息是否应该被遗忘;输入门更新旧的单元状态,执行实现之前遗忘门决定遗忘或添加的部分信息;输出门决定要输出单元状态中的哪些部分。如果将3 个门单元全部设置为1,那么LSTM 就变成了一个标准的RNN 模型。LSTM 模型结构如图1 所示。
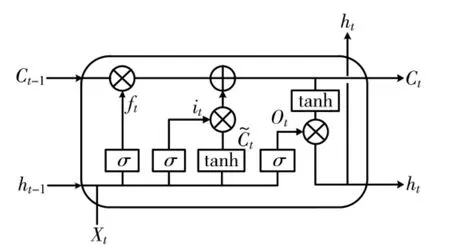
图1 LSTM 结构图
图1中,Xt为t 时刻的输入,ht为t 时刻当前单元的输出,Ct为t 时刻的单元状态,it为t 时刻的输入门限,Ot为t 时刻的输出门限,为前一时刻的单元状态;模型结构中的σ 为Sigmoid 激活函数。
深层的神经网络具有强大的非线性拟合和特征提取能力,由于本文使用的空气质量数据具有非线性、非平稳的特性,选用深层的神经网络模型效果要优于单层的神经网络模型。
在本文的方法中,选择了3 个层次的深层LSTM。把第一层的每个时间步的输出作为第二层的时间步的输入,把第二层的输出作为第三层的输入。
近年来,许多研究都开始加入注意力机制。自注意力机制是注意力机制的特殊形式,被广泛运用于机器翻译等领域。注意力机制就是人们有选择地将注意力集中在视觉空间的某个部分[11],以提高工作效率。然而,在除少数情况外的所有情况下,这种注意力机制都与循环网络结合使用[12]。而自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
本文在深层LSTM 之后加入了自注意力机制,使得最终的预测更趋向于关注数据的关键信息,从而提高预测的精度。自注意力机制通过为相关的数据赋予一定的权值,然后把相应数据的加权求和作为目标数据的估计。
由于本文使用了深层的LSTM 模型,容易出现过拟合的问题,因此加入了在一定程度上具有正则化效果的Dropout 方法来缓解过拟合的发生。Dropout 方法的本质是使某些神经元以一定的概率失活。
3 实验设计和数据选择
3.1 实验数据
本文选取了2020 年1 月1 日~2020 年12 月31 日 北京市的空气质量数据作为实验数据。本文采用中国空气质量在线监测分析平台(http://beijingair.sinaapp.com/)中北京市的每小时空气质量数据,其中包括AQI 和细颗粒物(Fine Particulate Matter,PM2.5)、可吸入颗粒物(Inhalable Particulate Matter,PM10)、二氧化硫(Sulfur Dioxide,SO2)、二氧化氮(Nitrogen Dioxide,NO2)、臭氧(Ozone,O3)以及一氧化碳(Carbon Monoxide,CO)这6 种大气污染物的数据。选取其中75%的数据作为训练集,25%的数据作为测试集。本文使用前24 小时的北京空气质量数据来预测后24小时 的AQI。
本文对空气质量数据进行计算,得出AQI 的季节平均分别为:春57.52、夏62.36、秋55.29、冬67.18。再将其与全年平均值相除,得到相应的季节指数。表1 显示了各空气质量数据的季节平均值。表2 显示了北京市空气质量数据的季节指数。其中大于100%的部分代表超出平均值,小于的部分代表低于平均值。从表2 中可以明显看出PM2.5、PM10、SO2、CO、NO2这5 种污染物存在夏季低冬季高的特征,而O3表现出的特征正好相反,这是由O3本身的特性造成的。
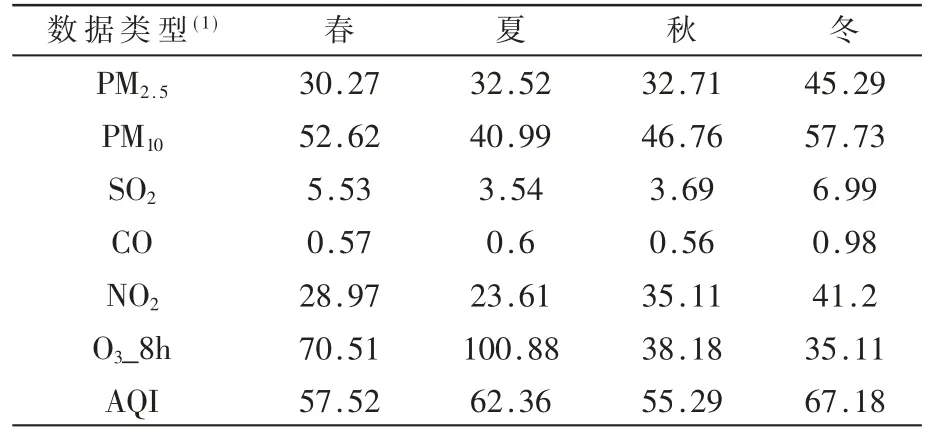
表1 北京市2020 年各空气质量数据的季节平均值
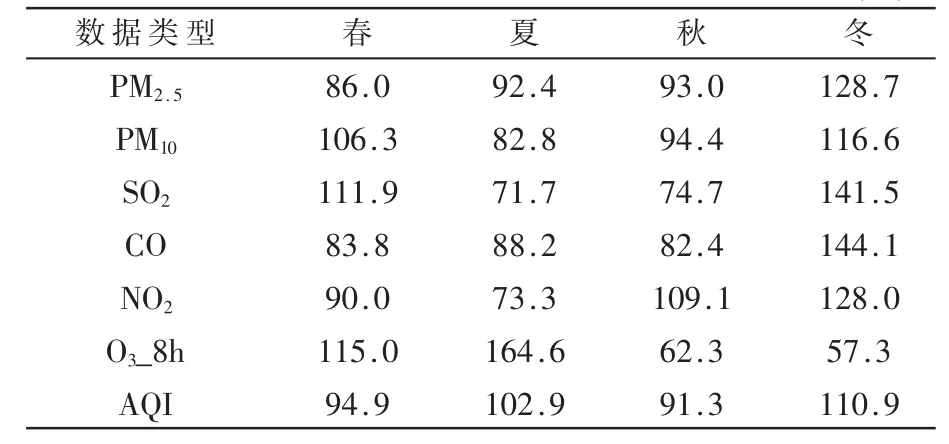
表2 北京市2020 年各空气质量数据季节指数(%)
3.2 实验结果和分析
3.2.1 改进的BCCSA-LSTM 方法预测结果
进行季节调整后的空气质量数据经由改进的BCCSA预处理之后,输入到深层的LSTM 模型中进行学习、预测。
图2 为本文所提方法预测的AQI 值与真实的AQI值的比较。可以看出,预测曲线可以很好地拟合真实曲线,表明模型预测效果较好。
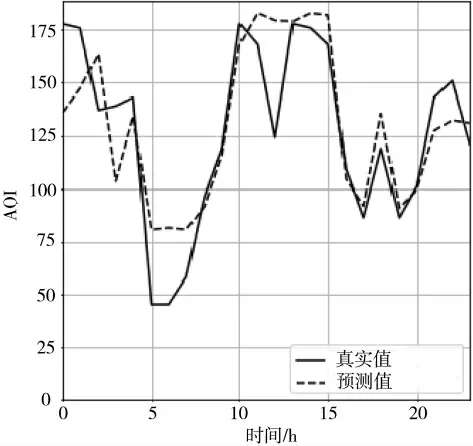
图2 BCCSA-LSTM 方法预测的AQI 值
3.2.2 方法评价
因为对于空气质量数据预测方法没有唯一的一个评价标准,本文为了更加全面、准确地对方法进行评价,使用了较常用的3 个评价指标,分别是平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R2)。
其中,MAE 代表预测值与真实值之间平均误差的大小;RMSE 代表预测值与实际值之间的差值;R2用来反映因变量变化可靠程度的一个统计指标。总之,MAE 和RMSE 两个指标是越小表示方法性能越好,而R2的值越接近1,表示方法精度越高。
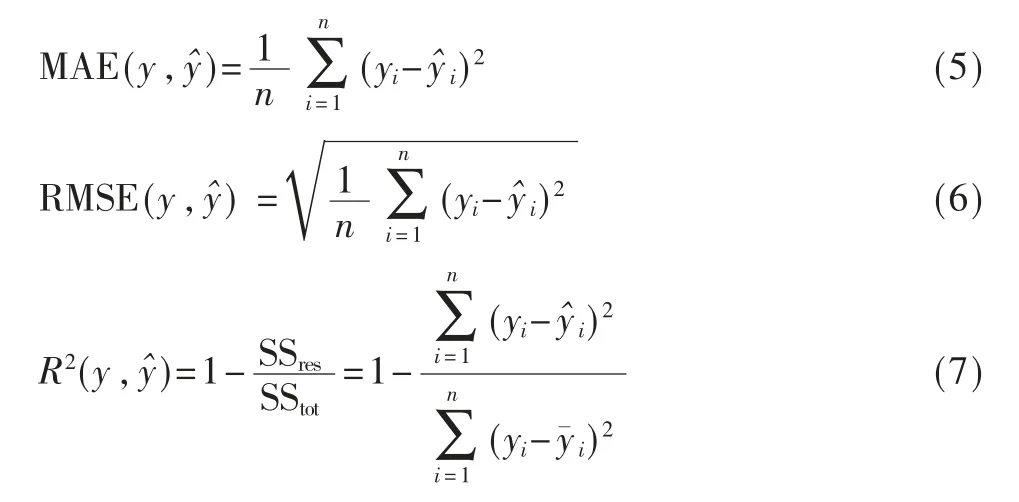
为了验证所提出的方法在预测方面的优越性,本文将所提方法与Zhao 等人[13]提出的长短期记忆神经网络加全连接层(LSTM-FC)方法、门控循环单元加全连接层(GRU-FC)方法、BCCSA-LSTM 方法、Wu 等[8]提出的变分模式分解、样本熵和LSTM(VMD-SE-LSTM)方法、Niu 等人[14]提出的基于互补集成经验模态分解的灰狼算法优化的支持向量回归(CEEMD-SVR-GWO)方法、Yan 等人[15]提出的基于主成分分析(PCA)的CEEMD-PCA-LSTM 方法以及支持向量机(SVM)方法这7 个基准方法对进行季节调整后的空气质量数据的预测结果进行比较。其中,本文方法设置训练次数为2 000,批处理数量为256,步长为24,实验结果如表3 所示。

表3 各种预测方法的预测结果
3.2.3 改进BCCSA 的运行时间
本文对BCCSA 所做的改进有利于算法寻找最优解,达到提高收敛速度的目的。令最大迭代次数为50,所提方法与原始的BCCSA 相比,运行时间结果如表4 所示。此外,实验是在Python 3.8.2 和TensorFlow 2.3.0 环境中进行的,该环境运行在macOS Catalina 10.15.6上,具有64 位2.30 GHz Intel Core i7 1068NG7 CPU 和16.00 GB RAM。

表4 BCCSA 与改进的BCCSA 运行时间比较
可以看出,改进的BCCSA 收敛速度提升了5.36%。
3.3 结果分析
从表3 可以看出,与方法LSTM-FC、GRU-FC、BCCSALSTM、VMD-SE-LSTM、CEEMD-SVR-GWO、CEEMDPCA-LSTM 和SVM 相比,本文提出的方法在MAE、RMSE和R2这些方法评价指标方面显示了更好的结果。通过与传统的LSTM-FC 方法相比,本文提出的方法在训练集和测试集上都具有更好的预测能力。
分析表3 中的数据可以得出以下结论:本文所提出的方法可以有效挖掘空气质量数据中隐藏的信息,进而对其进行精准预测。本文所提方法与基准方法中性能最好的VMD-SE-LSTM 方法相比,本文所提方法的MAE和RMSE 评估指标都要更好,在训练集中,MAE 下降了约38.40%,RMSE 下降了约35.82%,R2提高了约3.93%;在测试集,MAE 下降了约23.84%,RMSE 下降了约6.46%,R2提高了约1.49%。
另外,本文所提方法与基准方法中的BCCSA-LSTM相比,性能大幅提高,不论是在训练集还是在测试集中,评估指标都要更加优秀。在训练集中,MAE 和RMSE 分别降低了25.45%和43.19%,R2提高了4.52%;在测试集中,MAE 和RMSE 分别降低了12.09%和19.94%,R2提高了2.83%。总体上,本文所提方法比BCCSA-LSTM 方法性能要好。
将本文提出的方法与LSTM-FC、BCCSA-LSTM、VMD-SE-LSTM、CEEMD-PCA-LSTM 相比,模型的精度得到了显著的提高,这表明自注意力机制有助于预测空气质量数据。综上所述,本文提出的改进的BCCSA 和带有自注意力机制的LSTM 的混合深度学习方法可以更加有效地预测空气质量。
4 结论
针对现有研究存在的问题,本文提出了一种基于改进BCCSA 和带自注意力机制的深层LSTM 的空气质量预测方法。首先提出季节调整的预处理方法对原始空气质量数据进行季节性分析和消除季节因素的影响;然后创新性地将BCCSA 方法应用于空气质量预测,并提出3种改进BCCSA 的方法,对空气质量数据进行进一步优化处理,提高算法的收敛速度;最后在深层LSTM 中加入自注意力机制,以提高模型的预测精度。实验结果表明,与7 种基准方法相比,本文的方法对预测未来24 小时的空气质量具有更高的精度。
本文提出的方法能为空气质量预测以及相关防治提供一种有效的方法,使得公众能够得到较为准确的未来24 小时的AQI 预测值。虽然本文提出的预测方法能较为有效地预测AQI,也在一定程度上提高了方法的收敛速度,但是依旧存在一些局限,并且本文只使用了AQI和空气污染物作为实验数据,在今后的研究中,会把影响空气质量的气温、风速等气象因子作为辅助数据,一起用来预测AQI。本文只使用了北京市的空气质量数据,为了进一步证明所提方法的有效性,今后还会使用别的城市的空气质量数据,以验证方法的泛用性。
