基于外部知识的中文文本检错*
2022-07-20段建勇李杰东王昊
段建勇 李杰东 王昊
1.北方工业大学信息学院;2.CNONIX 国家标准应用与推广实验室
中文文本检错是一项重要任务,在众多应用场景中都需要对各种场景转化而来的文本进行检错以便后续模型的运用。采用人工方式进行文本检错费时费力、效率低。研究者提出了自动检错的方法,但目前的研究多集中在以语义为基础进行检错,缺少对外部知识的引用。本文针对现有检错方法的不足,结合中文文本语句的特点,将输入的中文字符结合其拆字知识,同时将中文的分词结果结合其更小粒度的义原外部知识,将拆字知识和义原知识表示融合为外部知识矩阵,并改进模型结构,利用外部知识来引导模型检错的过程,在Tencent AI Lab 以及SIGHAN 数据集上的实验表明,外部知识能有效的提高模型的检错能力。
中文文本检错任务在很多应用场景中均有体现,例如在输入法的输入、ASR 语音转文字或者OCR 图片识别时,都会产生音形或者字形的文本错误。中文文本检错是针对一句中文文本,使用现有模型对文本中的错别字进行标记,以便后续的模型使用,因此文本检错任务的准确率对于后续的自然语言处理任务至关重要,检错模型的检错能力很大程度会影响后续的模型结果。
早期的文本检错模型主要是基于规则匹配的方法,使用语句中最大的信息熵分类来对文本中的错别字进行识别;亦或使用字符级别的词向量,对于文本中的每个字符进行逐一的概率计算;由于单个字符对于整体的语句语义信息不够丰富,后续的方法多使用N-Gram 打分方式以及结合词典进行检错。
随着神经网络和深度学习的兴起,检错任务可以用深度学习模型进行解决。输入是带有错别字的文本,输出则直接为修改后的文本;亦或使用分类模型先将错别字进行标记,之后再输入纠错模型。
1 相关工作
文本检错任务在自然语言处理中占有重要地位,中文的文本在作为输入时没有确切的基本单位来将文本进行划分,可以是单个字,也可以是组合的词;且对与单个字来说,文本错误多种多样,包括音形错误、字形错误等;从概率上来说,中文文本错误没有连续大篇幅的错误,多出现为单个字或用词不当错误,故而加强模型对中文文本语义信息的抽取,对中文文本的自然语言处理任务是有很大帮助的。在以往的中文自然语言处理任务中,模型的输入多半是以单个字或者分词作为模型的输入,对语义的提取不够完整。而Jie Yang 在中文命名实体识别(NER)任务中,首次提出了针对LSTM 模型的Lattice结构,将中文的字和分词结果结合在一起作为模型的输入,对文本的语义抽取提高到了字和词融合的级别,提高了模型的实体识别能力;在中文表示挖掘方面,有基于笔画级别的中文字表征,将中文的笔画特征融入到嵌入表示中去,但是笔画特征对于中文来说过于抽象,相同的笔画顺序也可以表示不同的文字,例如太和犬;且笔画特征对于中文文本并不含有语义信息,就像字母对于英文一样,并不含有有效的文本语义信息;在针对音形表示方面,针对中文的特征在模型中融合了汉语拼音和混淆集,混淆集是针对中文错字的字形错误的集合,是一种合理的选择;同时针对音型错误,引入拼音特征,但是拼音并不是象形文字与生俱来所具有的特点,音形和象形文本表示本来就是两种语言流派,且拼音的引入或许会有声母韵母声调等潜在错误。同时采用特征工程的方法是最接近外部知识的,但是特征工程的知识面太窄,获得的信息不够灵活丰富。
将中文文本检错任务视为序列标记任务,给出一条含有错别字的中文文本序列作为模型的输入,输出每字符为True 或False 的标记序列;由于中文文本语句的歧义性以及语义表示的不确定性,在模型的输入端,若以中文字符为最小输入单位,很难提取文本的语义信息,原因在于中文文本的单个字在文本序列中并不包含太多的语义信息;而若以中文的词为模型最小输入单位,其一在文本分词时,不同的语义理解导致分词结果不具有唯一性,不同的分词结果完全符合逻辑但却表示完全不同的语义信息;其二中文的词含有的语义信息过于丰富,存在多义词问题;针对以上问题,以Lattice 结构作为模型的输入,同时获取中文的字和词的语义信息。
同时挖掘中文文本更深层次特有的文本外部知识来强化模型的检错能力,中文的字有其特有的偏旁结构,偏旁通常含有能够表示该字类别的含义,例如江河湖海的三点水偏旁,偏旁属于文字的聚类特征,而除偏旁之外的拆字信息通常被忽略,拆字知识能够体现字与字在聚类特征条件之下所表达出的不同语义信息;同时中文的词义过于宽泛,存在多义词等因素,而中文词所含有的外部知识——义原(OpenHowNet),则体现了相同的词在不同的语句中特有的属性。将中文的拆字特征知识以及义原知识结合进模型,能够显著提高模型的检错能力。
2 模型结构
针对以上抽取中文文本语义信息的特点,本文提出了针对中文Lattice 结构输入的外部知识混合矩阵,提取字的拆字知识矩阵;针对中文的词,提取义原知识矩阵;将拆字知识向量和义原知识向量拼接融合到Transformer 模型的Attention 模块中,加强模型对中文文本检错的能力。
模型结构如图1 所示。
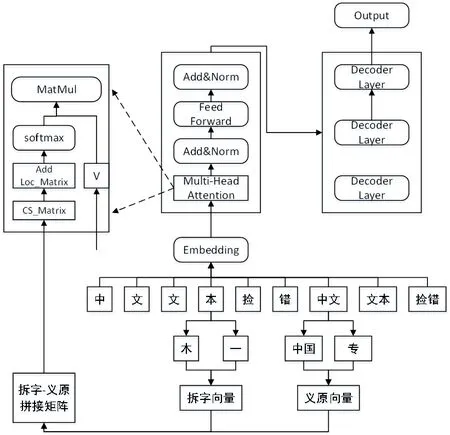
图1 模型结构图Fig.1 Model structure
2.1 拆字(Chaizi)知识
偏旁部首是中文特有的字结构,偏旁含有丰富的隐藏信息,如金字旁的字多表示为金属,三点水偏旁多和水相关,拆分中文单个字的偏旁特征能够提取出中文字的聚类特征,但是在自然语言处理的词嵌入(Embedding)表示中,嵌入本身就有聚类的含义,此时再采用偏旁特征只是对词嵌入表示的强化,因此将字除偏旁之外的拆字特征一并融合进模型,提取字所含有的所有拆字语义特征,在聚类的基础上体现字与字之间信息的差异化。
给定一个以字为单位的中文文本语句sentence={c
,c
,c
,……,c
},将中文文本进行分词,分割后的词组语句word_sentence={w
,w
,w
,……,w
};同时将sentence 中的每一个字都进行拆分,c
={x
,x
,x
……,x
},其中x表示拆分的字符;拆分之后,查询出拆分字符的向量表示做加和求平均运算(此处不做Attention 运算的目的就是为了体现基于聚类条件下的字与字之间细微的差异化,若做Attention 运算,拆字之后的特征权重将向偏旁倾斜,拆字特征知识运算得到的结果无非就是另一种基于字符的嵌入表示),加入拆字特征之后的c
嵌入的计算公式为:c
=(x
+x
+x
+…+x
)/chaizi.len
2.2 义原(Sememe)外部知识
义原(Sememe)是中文词级别的属性特征,中文所有的词均可以由2187 个义原特征来进行表示,义原是词级别的更小粒度的语义分割,将词和义原外部知识进行结合能够有效去除相同的词在不同的语义环境中的歧义以及多义词问题。
在word_sentence 中分词结果得到的每一个词,均可以在OpenHowNet 中匹配到基于词的最小粒度——义原,即w
={y
,y
,y
,…,y
},其中y 表示词的义原;义原知识的计算方公式如下所示:w
=(y
+y
+y
+…+y
)/sememe.len
由于义原的嵌入向量和中文分词之后的词向量文件并不相同,且两者抽取的词嵌入的维度所表达的特征也并不属于一类,计算之后的义原向量和词向量并不能直接进行融合,因此在将拆字特征知识的字嵌入向量和义原外部知识的词嵌入向量进行纵向拼接为外部知识矩阵时,矩阵维度为Lattice 结构的语句长度乘以嵌入维度。
综上所述:基于上文给定sentence
={c
,c
,c
,……,c
},将中文文本进行Lattice 结构处理,生成的Lattice结构输入表示为字符和分词结果的拼接输入表示lattice_sentence
={c
,c
,c
,……,c
,w
,w
,w
,……,w
},Lattice 结构的输入长度为lattice_sentence.len
=sentence.len
+word_ sentence.len
,将生成的字符计算向量和义原计算向量拼接生成ChaiZi_Sememe 矩阵(下文简称CS 矩阵),CS 矩阵的表示如图2 所示。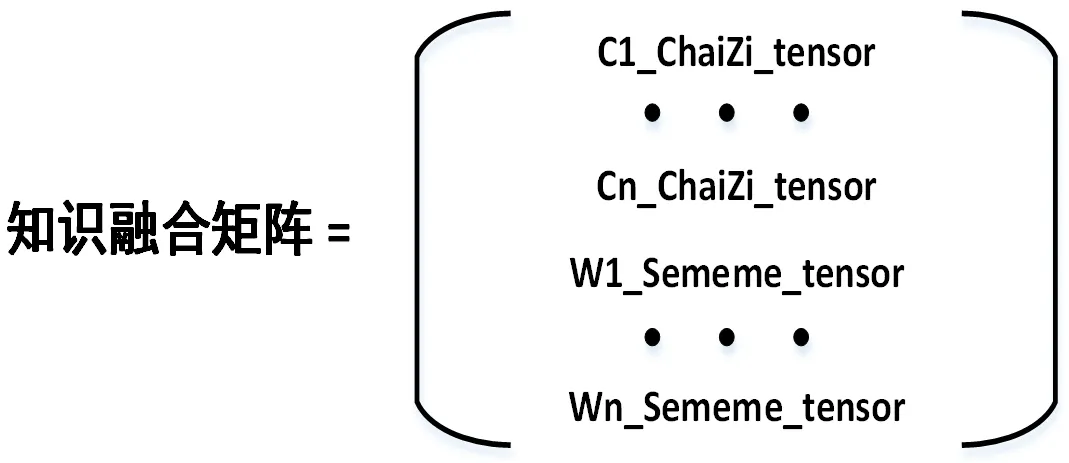
图2 外部知识融合矩阵Fig.2 External knowledge fusion matrix
2.3 位置信息
在自然语言处理的任务中,语句的位置信息同样也非常重要,在实体命名识别(NER)任务中,通常使用BIOES 编码对目标的结果进行标记,同时结合条件随机场(CRF)去除不合理的标记,BIOES 标签本身就含有输入语句的开始、中间、结束、其他等位置信息,CRF 层能够学到输出的标签序列信息。位置信息的加入使得模型对标签的预测能力有了进一步的提升;而在检错模型的Lattice结构中,其一是字的标签只有True 或者False 两种,标签与标签之间相互独立,标签之间无法体现位置编码;其二是Lattice 结构的语句尾部添加了词,词是多字,并不能由一个数字来编码其在语句中的位置信息,需要有词的开始和结束位置编码才能完整表示词在句子中的位置信息。
在本文中,对输入语句的位置信息进行两次编码,一次是词在句子中的开始(Start)位置编码,一次是词的结束(End)位置编码,对于字来说,开始位置和结束位置是一样的,而词的开始位置编码和结束位置编码则体现词在文本中的位置区间,以此参与Lattice 结构运算。其位置编码表示如图3 所示。

图3 文本的位置信息表示Fig.3 Position information representation of text
根据开始位置和结束位置的位置表示,生成对应的位置矩阵,共4 个位置矩阵,位置矩阵的计算公式如下所示:
Distance
(SS
)=Start[i]
-Start[j]
Distance
(SE
)=Start[i]
-Start[j]
Distance
(ES
)=Start[i]
-Start[j]
Distance
(EE
)=Start[i]
-Start[j]
其中Distance()方法计算的为相对距离,S(Start)表示开始位置序号,E(End)表示结束位置序号;SS 表示使用开始位置的序号减去其余各位置的开始位置的序号,生成的为SS 距离矩阵;SE、ES、EE 的位置矩阵计算方式相同。
将生成的4 个位置矩阵通过Transformer 模型的位置编码计算方式之后做Concat 操作,之后乘以一个可学习的参数W,进过ReLU 函数得到矩阵R(ij),计算公式如下:
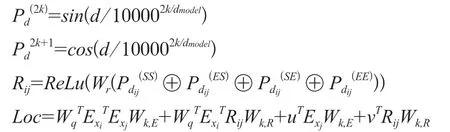
W
,W
,W
∈R
且u
,v ∈R
都是可学习的参数。2.4 Attention 模块
在基础Transformer 的Attention 计算中,矩阵Q、K、V 的结果均是来自输入的字符嵌入和随机矩阵的点乘得来,这样计算的好处是模型在不同的向量空间得到不同的计算结果矩阵,使得泛化能力更强,但是Q、K、V矩阵的结果来源依然均是由最初的输入字符Embedding和随机矩阵的乘积结果;在计算权重矩阵的过程中,其计算矩阵结果来源过于单一,使用外部知识替换该计算矩阵可以将模型的输入Embedding 和外部知识很好的结合起来参与模型的计算。
将上文计算的位置信息Loc 矩阵和CS 知识矩阵进行融合,用以替换公式Transformer 中的矩阵A;此处可以选择直接加和CS 矩阵,也可以将CS 矩阵乘以可学习的W 矩阵之后,再和位置矩阵进行相加操作。之后替换Transformer 中Attention 的QK 运算结果,最终融合位置矩阵和外部知识的矩阵为A(ij),参与Attention Score 运算公式如下:

3 实验与分析
3.1 数据集
数据集包含两部分,分别是出自Tencent AI Lab 的27万余条数据和SIGHAN-2015 比赛数据集的1000 余条,需要自行处理为序列语句和序列标签。同时实验为了验证模型的可靠性,将两个数据集分开,Tencent AI Lab 的数据作为TrainSet 和DevSet,而SIGHAN 的1000 余条数据作为TestSet 经行测试,避免了同源数据集可能导致的问题。
实验数据集划分如表1 所示。
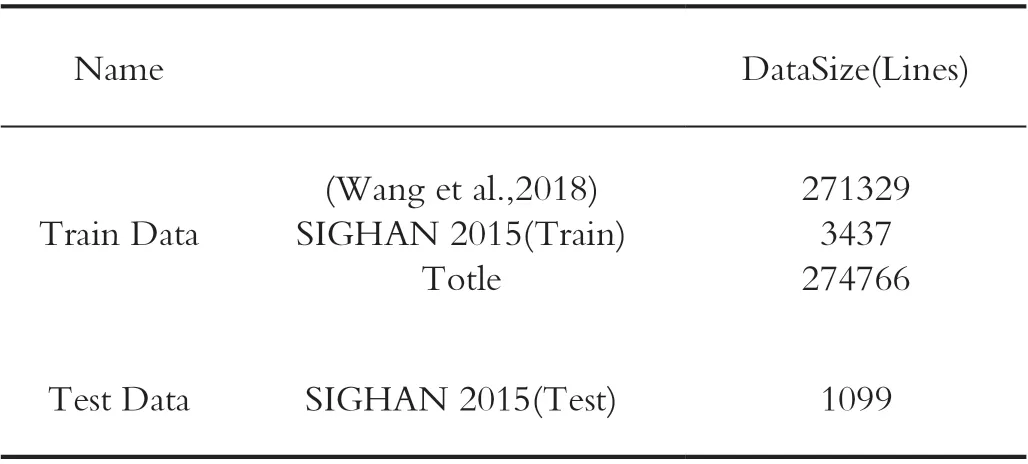
表1 CMRC2018 数据集实例Tab.1 Example of CMRC2018 dataset
3.2 实验参数
模型实验参数设置如表2 所示效果最好。
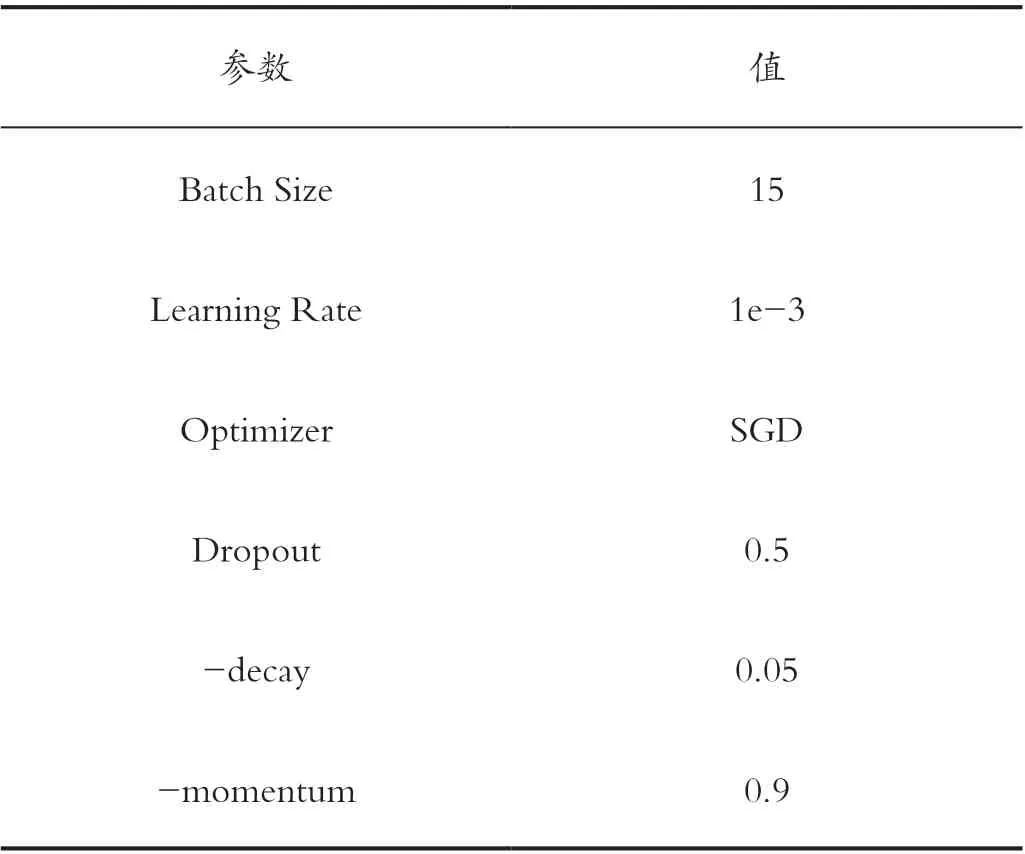
表2 实验参数设置Tab.2 Experimental parameter setting
3.3 评价指标
模型的检测指标包含准确率(Precision)、召回率(Recall)、F1 值(F-Measure),F1 的指标能够综合反映模型效果的好坏。模型训练的EarlyStopping 标准为训练中五次迭代未超过0.01,则停止训练。
3.4 结果与分析
模型以GRU 中文文本检错结果作为本文的BaseLine,其在News Title 数据集上取得了较好的结果。本文实验使用Transformer 模型,加入拆字和义原特征共5 组实验,以拆字特征知识和义原知识拼接矩阵融入Attention 运算为主实验,以此来验证模型的有效性。
3.4.1 对比实验
在实验设计中,将拆字知识嵌入和义原外部知识嵌入进行纵向拼接,生成对应的CS 外部知识(ChaiZi_Sememe)矩阵,输入Attention 模块中为主实验,同时在未确定拼接矩阵是否有效果的前提下,在矩阵运算过程中乘以一个可学习的矩阵W,对比了可学习参数W×CS矩阵的效果,主实验及对比BaseLine 实验结果如表3所示。
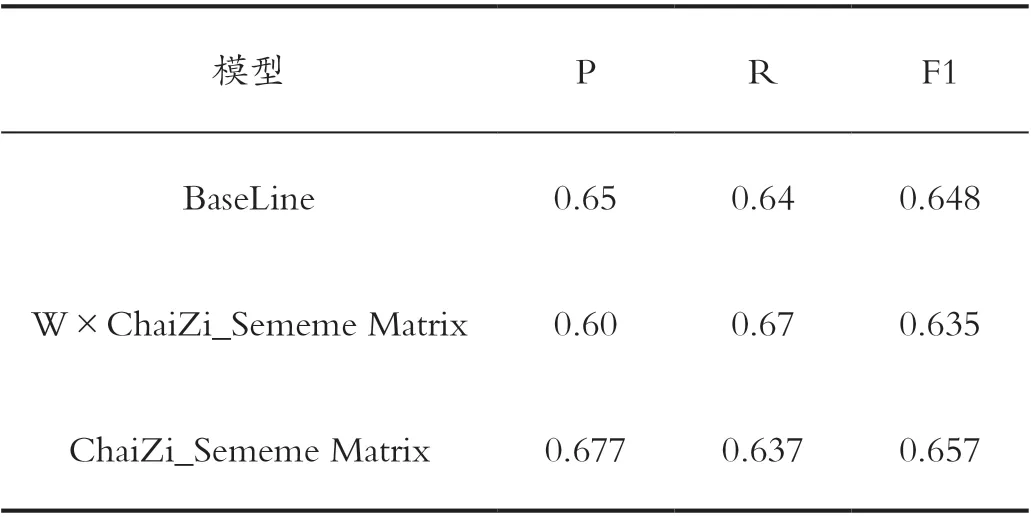
表3 对比实验结果实验结果Tab.3 Comparative experimental results
实验结果表明,在加入参数矩阵W 之后,模型的结果并未有大的提升,而只使用特征矩阵参与Attention 运算之后,相比BaseLine 的检错模型结果,F1 值有了0.9%的提升,综合效果最好。外部知识矩阵的语义来源是最初的字和词,说明外部知识在检错过程中起到了辅助作用。
3.4.2 消融实验
消融实验以Transformer 模型为基础共3 组实验,验证加入特征的有效性;3 组的实验结果表明,加入义原或拆字特征的检错结果都要比BASE 模型效果高出许多。
综上所述,从表4 实验结果来看,引入外部知识提升模型的检错能力是有效的;同时中文单独的一个字在文本中是没有太多的含义的,引入字级别外部知识提升效果不如词级别,也验证了中文文本的语义特征主要是中文的词构成。同时,在知识融合方面,输入端的嵌入表示能力并不差,知识融合的效果在模型内部取得的提升更为显著。
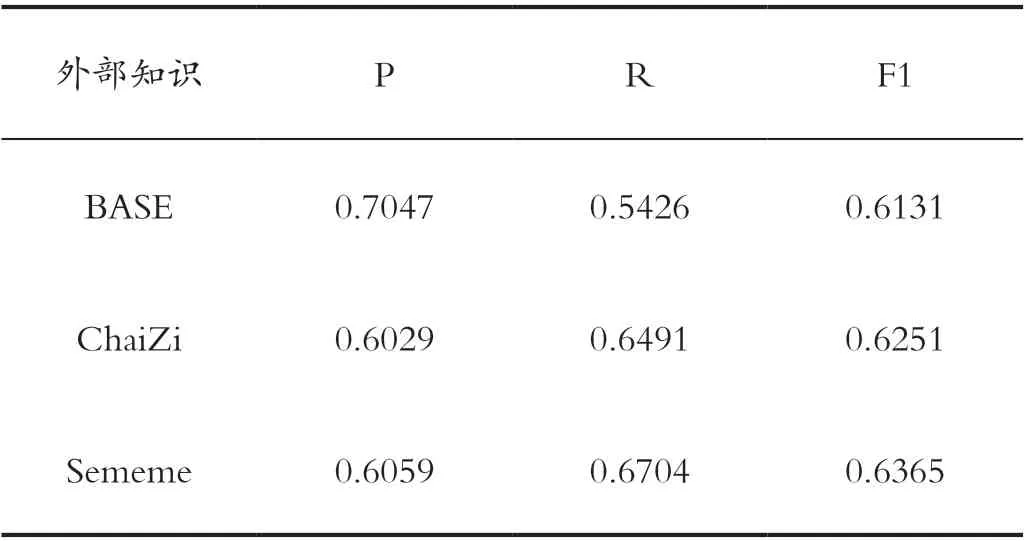
表4 Transformer 消融实验结果Tab.4 Results of Transformer ablation experiment
4 结语
本文针对中文文本检错的特点,提取出中文文本特有的外部知识—拆字知识和义原知识,通过拼接知识矩阵,将Transformer 模型中Attention 机制相同来源的计算矩阵进行修改,提升了模型的中文检错能力,取得了最好的检错结果。
同时,本文对该外部知识的引用存在过于粗糙的问题,后续可以继续深入细化研究,训练出拆字的独立嵌入表示,结合新的模型,进行下一步研究。
引用
[1] ZHANG Yue,YANG Jie.Chinese NER Using Lattice LSTM [C]//Melbourne:Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics,2018.
[2] LI Zi-ran,DING Ning,LIU Zhi-yuan,et al.Chinese Relation Extraction with Multi-Grained Information and External Linguistic Knowledge[C]//Firenze:Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics,2019.
