基于似然比框架的法庭说话人自动识别系统构建与验证
2022-07-19张翠玲
张翠玲, 丁 盼
(1.西南政法大学刑事侦查学院, 重庆 401120; 2.重庆高校刑事科学技术重点实验室, 重庆 401120)
0 引言
法庭说话人识别是指对案件中的未知语音(也称检材语音)和嫌疑人语音(也称样本语音)进行比较鉴别,来推断二者的同源性,进而为法庭提供线索和证据的一门技术[1]。法庭说话人识别技术是说话人识别技术在司法领域中的应用。随着语音自动识别技术和说话人自动识别技术的飞速发展,这些自动识别技术和方法也被借鉴到司法语音领域,但是与一般应用场景的说话人自动识别技术不同,法庭说话人自动识别由于其应用场景的特殊性,在语音数据、识别方法和框架体系上均具有自身的独特性。
随着语音识别技术进入了深度学习时代,法庭说话人识别技术也迎来了技术革新,即由传统的、以专家主观检验为主的听觉感知、图谱比较和声学-语音学方法向更加高效、省力及客观的自动识别方法转变。由传统的基于人工专家检验的声学-语音学识别发展为专家监督下的法庭说话人自动识别是司法语音领域的技术进步和发展方向。但是,无论使用传统的说话人识别方法,还是自动说话人识别方法,检验识别的程序方法和结果都应满足法庭对证据的科学性要求[2-3]。近年来,基于似然比框架的法庭语音证据评价体系在国际上逐渐得到了普遍认可和实施[4-6],因为以概率评价为基础的似然比框架方法不仅更符合法庭统计推理的逻辑规则,而且可以对证据的价值及其所使用方法系统的准确性和可靠性进行客观的量化评估。
国际上,关于法庭说话人自动识别系统的验证程序与方法已存在部分成果。Morrison和Enzinger基于似然比框架体系制定了统一的系统性能评价规则,并提供了一个反映现实案件条件的法庭语音数据库,组织多个实验室开展了法庭说话人自动识别系统的性能验证测试[7]。参与验证测试的9个自动识别系统采用的算法模型主要包括高斯混合通用背景模型GMM-UBM(Gaussian Mixed Model-Universal Background Model)、i-vector PLDA(Identification Vector -Probabilistic Linear Discriminant Analysis)模型和深度神经网络DNN(Deep Neural Network)模型。验证结果表明,基于i-vector PLDA的系统识别性能优于GMM-UBM系统,而基于DNN模型的系统识别性能最佳[8]。最近,来自十几个国家的司法语音专家就法庭说话人识别的验证方法发表了共识声明,倡导在似然比统一框架内,基于能够反映案件现实条件的语音数据库开展法庭说话人识别的方法系统验证[9]。
在国内,基于似然比方法的法庭说话人自动识别系统的性能评价研究正在不断推进。王华朋等基于似然比框架体系提出了一种基于GMM-UBM模型的法庭自动说话人识别系统改进方法,通过以小型参考背景人群模型代替UBM的方法,降低了识别系统对嫌疑人语音样本数量的需求[10]。除此之外,王华朋和张翠玲使用GFCC(Gammatone Frequency Cepstral Coefficient)特征与主成分分析方法,对基于似然比框架的法庭说话人识别系统的抗噪特性进行了探究[11]。近几年,张翠玲团队使用似然比证据评价体系分别对基于LPCC、MFCC等语音自动识别参数的说话人识别系统性能进行了探索[12-14],并在现实案件条件下对法庭说话人自动识别系统进行了系列验证测试[15-16]。这些研究为国内法庭说话人自动识别系统的改进提升提供了重要参考依据。
综合来看,国内在法庭说话人自动识别系统的研究方面已经取得了很大进步,但是由于案件场景的多样性和复杂性,还需要对更多的场景数据和模型系统进行验证测试和比较研究。为了客观评价说话人自动识别系统的准确性和可靠性,同时满足自动识别系统模型训练的大量数据需求,本研究选用牛津大学在2017年和2018年发布的开源音视频数据集VoxCeleb1[17]和VoxCeleb2[18]作为自动识别系统的训练数据和测试数据,利用深度神经网络方法提取语音特征,并构建了基于d-vector PLDA模型的法庭说话人自动识别系统,然后基于似然比证据评价体系对法庭说话人自动识别系统的性能进行验证测试。利用开源数据集进行测试不仅可以保证数据的透明性和多样性,而且便于不同系统间的横向比较,有利于推动法庭说话人自动识别技术的进步与发展。
1 法庭说话人自动识别系统的主体框架
1.1 语音特征提取
首先对全部音频进行语音活性检测(Voice Activity Detection,VAD),逐帧判断音频是否属于人声,将所有音频区分为语音段和非语音段。然后,在语音段上提取23维的FBank(Filter Banks)特征,提取的帧长为25 ms,帧移为10 ms。
使用深度神经网络(Deep Neural Network,DNN)提取说话人身份向量时,一般使用FBank作为前端特征。FBank特征的提取步骤与MFCC特征基本一致,需要经过预加重、分帧、加窗、短时傅里叶变换(Short-term Fourier Transform,STFT)、Mel滤波、去均值等操作,MFCC特征的获取则需要在Fbank特征的基础上进行离散余弦变换(Discrete Cosine Transform,DCT)。因此相较于MFCC特征,FBank特征的获取计算量更小,且包含更多信息,特征相关性更高,更适合在深度神经网络模型中作为输入特征使用。
1.2 统计建模
近些年,基于深度神经网络构建说话人识别模型已经成为主流选择。随着技术的不断发展,法庭说话人自动识别中使用的特征参数和模型算法也在不断更新。从高斯混合通用背景模型(GMM-UBM)[19]到分别对说话人和信道空间建模的联合因子分析(JFA)[20],以及使用全局差异空间代替本征空间和信道空间的i-vector向量[21],再到基于深度神经网络提取能够表征说话人特征的embedding,如j-vector[22]、d-vector[23]和x-vector[24-25]等,法庭说话人自动识别技术已经进入了深度学习时代。Variani研究了深度神经网络(DNN)在小型文本相关的说话人验证任务的应用,发现相较于i-vector向量特征,基于DNN的d-vector说话人识别模型在说话人识别方面表现出了更好的性能[23]。
基于此,本文选用基于深度神经网络的d-vector说话人识别模型。系统的神经网络结构选用时延神经网络(Time Delay Neural Network,TDNN)[26],一方面因为多层的TDNN具有较强的抽象能力,另一方面在于其能够使网络学习到语音信号的时序性结构信息。d-vector是一种句子级别(utterance-level)的深度说话人识别向量,由深度网络的特征提取层(隐藏层)输出帧级别的说话人特征,并以合并平均的方式得到句子级别表示的向量特征。本文中d-vector的获取是在深度神经网络模型中使用标准前馈传播计算最后一个隐藏层的输出激活值,再将激活值累积起来后得到。选用全连接层中的最后一个隐藏层输出embedding而未使用softmax输出层,其原因在于输出层的减少可以有效缩减DNN模型的规模并缩短运行时间,且最后一个隐藏层的输出特征可以更好地概括未知说话人的特征。
基于深度神经网络的d-vector向量提取过程见图1。
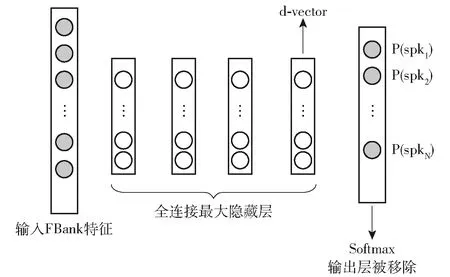
图1 基于DNN的d-vector特征提取
1.3 降维及信道补偿
系统使用概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)进行降维和信道补偿。PLDA是概率形式的线性判别分析(Linear Discriminant Analysis,LDA)[27],它既是一种降维方法,也是一种信道补偿方法,而且其信道补偿能力相较于LDA更优。PLDA自适应可以补偿实际数据与已经训练模型中声学条件不匹配的问题,从而进一步提升识别性能。
在说话人识别中,假设训练语音数据由m个说话人的语音组成,其中每个说话人有n段自己不同的语音。那么,定义第m个人的第n条语音为Xmn。根据因子分析,则Xmn的生成模型为下式(1):
Xmn=μ+Fhm+Gwmn+εmn
(1)
式(1)中,μ表示全部训练语音数据的均值;F可视为身份空间,包含了各种可表示说话人的信息;hm可视为某一具体的说话人身份(即说话人在身份空间中的位置);G可视为误差空间,包含了可表征同一说话人语音变化的信息;wmn表示的是在误差空间中的位置;εmn用来表示随机误差,该项为零均值高斯分布。该模型实际上主要由两部分组成,等号右侧的前两项可视为信号部分,该部分仅与说话人有关,而与说话人具体的某条语音无关,主要用于描述说话人之间的差异。等号右侧的后两项可视为噪音部分,用于描述同一说话人的不同语音之间的差异。上述两个假想变量可以描述一条语音的数据结构,PLDA模型训练的目标就是输入一堆数据Xmn,输出可以最大程度上表示该数据集的参数θ=[μ,F,G,ε],hm可以看做是Xmn在说话人空间中的特征表示,隐藏变量hm和wmn可通过期望最大化(Expectation-Maximum,EM)算法进行求解。EM算法是一种迭代优化策略,可以在数据不完全的情况下实现参数预测[28]。EM算法的每次迭代都分为两个步骤——期望步(E步)和极大步(M步),期望步依靠观测值对隐含变量的分布情况进行计算,极大步依靠隐含变量的分布来估计新的模型参数,通过E步和M步对隐含数据和模型分布的参数进行不断迭代更新,最终收敛得到需要的模型参数。
1.4 识别打分和似然比计算
在识别打分阶段,两条语音的hm特征相同的似然度越大,这两条语音就更可能属于同一个说话人。式(2)为PLDA似然度得分计算公式,x1和x2分别为两个语音的d-vector矢量,Hss代表检材语音与样本语音的embeddings来自同一空间的假设,Hds代表检材语音与样本语音的embeddings来自不同空间的假设,对数似然比的得分score可衡量两条语音的相似程度。score值越大,检材语音与样本语音来自同一说话人的概率越大。
(2)
通过PLDA计算出两条语音的得分后,将得分值通过逻辑回归算法转换为似然比LR,然后对系统识别性能进行评估。具体流程见图2。
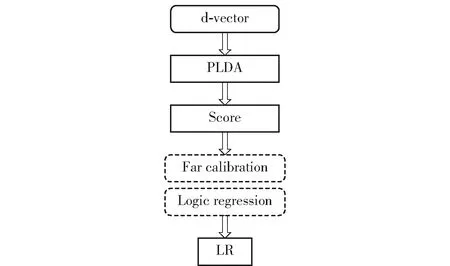
图2 d-vector说话人识别系统的似然比计算
2 验证流程
2.1 语音数据集
VoxCeleb1[17]和VoxCeleb2[18]数据集中的音频全部采自YouTube上的视频,音频获取方式为首先提取视频中的音频,然后按照说话人进行切分,数据集与文本无关。说话人性别相对均衡,发音人年龄、种族、口音、职业等较为多元。数据集语音的来源视频一般包含多个人声,且拍摄情况相对复杂,涵盖了发布会采访、室外体育场、安静工作室的采访,面向广大听众的演讲、专业拍摄的多媒体节选以及在个人手持设备拍摄等场景。数据集中的语音带有一定程度的真实噪声,包括环境噪声、室内噪声、笑声、重叠语声、回声以及录音设备噪音等。
VoxCeleb1数据集共包含1 251位名人的 153 516 条语音片段,数据集总时长为352 h,包含690位男性和561位女性。其中,男性发音人占总发音人的55%,语音片段的平均时长为8.2 s,最大时长为145 s,最短时长为4 s,音频无静音段。数据集中包含训练集1 211人和测试集40人,分别对应148 642和4 874个音频段,每人平均有116个音频段,每人最大音频段数量为250条,每人最小音频段数量为45条。
相较于VoxCelex1数据集,VoxCeleb2数据集内容更加丰富,其数据规模约为VoxCelex1数据集的5倍。该数据集中共包含6 112位名人的1 128 246条语音片段,数据集总时长为2 442 h,男性发音人有3 761人,占总发音人的61%。语音片段的平均时长为7.8 s,每位发音人平均有185个音频段。数据集中包含训练集5 994人和测试集118人,分别对应1 092 009个和36 237个音频段。两个数据集中的音频采样率为16 kHz,采样精度为16 bit,声道类型为单声道,音频存储格式为“PCM.wav”。VoxCeleb1和VoxCeleb2数据集的详细情况见表1。

表1 VoxCeleb1数据集VoxCeleb2数据集情况汇总表
综合来看,这两个数据集在环境特性(录制场景、背景噪声等)方面和说话人特性(口音、言语风格[29]等)方面,基本上反映了司法实践中检材语音和样本语音的实际情况。但在信道种类和采样率方面,二者仍有一定的局限。在实际案件中,较常见的涉案原始音频信道设备有固定电话、手机、微信、标采设备和录音笔信道等,语音采样率一般有8 kHz、16 kHz、22.05 kHz、24 kHz、44.1 kHz等。因此,相较于实际案件语音的录制条件,这两个数据集包含的语音信道条件仍不够多样。除此之外,实际案件中样本语音常见的“讯问”言语风格语音并未体现在该数据集中,虽然数据集中的“自由交谈”和“朗读”言语风格语音已能较好地模拟大部分实际案件语音的言语风格,但仍可能对系统识别的准确性带来一定影响。
2.2 测试方法
首先使用大规模语音数据进行说话人识别背景模型(大模型)训练,然后对系统性能进行验证测试。测试中使用的数据集有3种,分别为自适应训练集、校准集和测试集。使用训练集对PLDA模型做有监督的自适应训练,该操作可以补偿测试集语音的言语风格、方言特征、信道条件和录制环境与大模型不匹配的问题,且通过对自适应训练的数据进行监督,可以进一步提升PLDA模型打分的稳定性和准确性。校准集通过标定数据(已标注说话人身份的数据)对PLDA模型的打分结果进行校准,进而提升系统识别的准确性。测试集用于自动说话人识别系统性能的验证评价。
大模型的训练数据为VoxCeleb2数据集中 6 112 人的语音数据。系统自适应训练集为VoxCeleb1数据集中500人的语音数据,用于对PLDA模型做有监督自适应训练。校准集来自VoxCeleb1数据集中测试集以外的40人语音数据,通过数据标定进行得分误匹配补偿算法模型的训练,对PLDA分类得分进行校准。系统测试集选用的是VoxCeleb1数据集中自带的40人测试集语音数据,将测试集包含的所有语音进行全交叉检验,得到两两比较的似然比值,然后计算系统验证的评价指标。
2.3 系统验证性能指标
2.3.1 对数似然比代价函数
对数似然比代价函数(Log likelihood ratio cost,Cllr)[30]作为系统准确性评估参数,是在似然比框架体系下评价法庭说话人识别系统性能的标准评价指标,其表达式见公式(3):
(3)
式(3)中,Ns和Nd分别是同一话者和不同话者测试对的数量,LRs和LRd分别是同一话者和不同话者测试对比较的似然比。Cllr值是系统的整体表现。Cllr值小于1,说明系统是有效的;Cllr值越接近于0,系统的准确性越高。
2.3.2 等误率
等误率是说话人识别领域最常用的评价指标。在说话人识别中,系统的错误识别情况有两种:一是将不同来源的语音错判为同源,即错误接受;二是将相同来源的语音错判为非同源,即错误拒绝。系统的错误接受率和错误拒绝率相等时为等误率(Equal Error Rate,EER)。等误率EER的值越小,代表系统的性能越好。
2.3.3 Tippett图
Tippett图(可靠性函数图)是基于似然比框架的法庭说话人识别系统验证的标准图示[31]。Tippett图的横轴是以10为底的对数似然比(log10LR),纵轴是同一说话人和不同说话人比较所占的比例(也可称为概率累计分布)。Tippett图中向右延伸的曲线代表同一说话人之间的比较,向左延伸的曲线代表不同说话人之间的比较。两条延伸曲线的交叉点对应的概率代表等误率(EER)。两条曲线分得越开,交叉点越低,识别的效果越好。
3 结果与讨论
3.1 不同采样率语音数据的验证结果
3.1.1 8 kHz采样率语音数据的识别结果
由于现实案件中待检语音材料来源于手机通话录音的情况较为常见,为了检验自动识别系统在案件条件下的性能表现,首先将用于训练系统识别背景模型和评测系统的语音采样率降为手机通话录音常见的8 kHz。然后按照2.2所示的测试方法,使用6 112人的8 kHz采样率语音训练说话人识别的背景模型,从选定的VoxCeleb1训练集中抽取300人和500人的语音数据进行PLDA模型自适应训练,选择测试集之外的40人语音数据作为校准集,使用VoxCeleb1数据集中自带的40人测试语音数据作为测试集进行测试评价。使用留一法将测试集中每位说话人的语音进行交叉比较测试,该过程共产生了179 700个语音比较对,其中同一话者语音比较对为4 200个,不同话者语音比较对为175 500个。
8 kHz采样率语音数据的系统识别结果见表2。

表2 8 kHz采样率语音数据的系统识别结果
表2的识别结果表明,未使用PLDA自适应训练集的系统Cllr值经校准后为0.874,等误率EER的值为0.194。使用300人语音的PLDA自适应训练集模型系统的Cllr值未进行校准的情况下为0.632,校准后达到了0.273,校准后的系统相较于未使用PLDA自适应训练集的系统性能提升了约69%,系统整体的EER值为0.070,比未进行PLDA自适应训练的系统降低了约64%。将PLDA自适应训练集规模扩大为500人后,经校准的识别系统的Cllr值为0.269,EER值为0.065,与未使用PLDA自适应训练集的系统相比,识别性能提升了约69.2%,系统的EER值降低了约66%,识别效果在本组测试中达到最佳。此外,经过校准系统的Cllr值明显小于未校准系统,这说明校准是一个非常重要的步骤。只有经过校准的系统,才能更好地反映系统的实际性能。
2.市场化程度。不管是对于城镇发展还是产业发展来说,要素资源的合理配置都起到重要作用,而资源如果要实现合理配置、达到理论上帕累托最优的状况,就必须推进市场化程度的提升。市场化水平的提高不但可以提升经济活力和发展效率,促进产业转型升级、使得劳动分工合理、加速劳动力的流动,而且也会使私有资本更多地参与到基础设施和公共服务领域的投资,对城市功能的完善起到重要的推动作用。
8 kHz采样率语音数据的系统验证Tippett图见图3~5。图中,向右上升的曲线代表同一说话人语音的比较结果,向左上升的曲线代表不同说话人语音的比较结果。
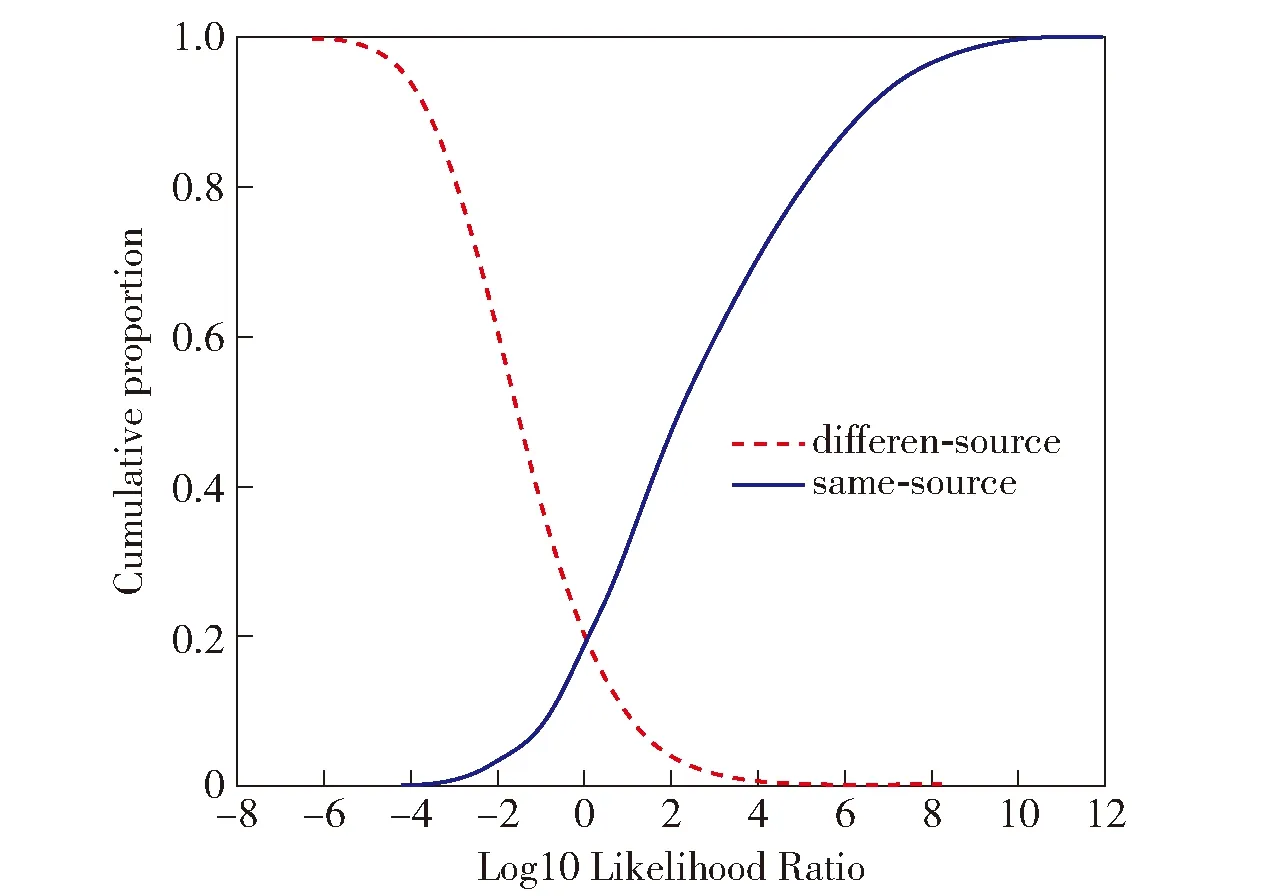
图3 未进行PLDA自适应训练的系统识别结果(8 kHz采样率语音数据)

图4 300人语音数据PLDA自适应训练集的系统识别结果(8 kHz采样率语音数据)

图5 500人语音数据PLDA自适应训练集的系统识别结果(8 kHz采样率语音数据)
从测试结果看,基于8 kHz采样率语音的d-vector PLDA模型系统的识别效果良好,但仍有提升的空间,经校准后的说话人自动识别系统的识别性能更优,且进行PLDA自适应训练能有效提升系统的识别性能。
3.1.2 16 kHz采样率语音数据的系统识别结果
近年来,便携录音设备的发展为高质量录音的获取提供了极大便利。随着公安部门声纹数据库建设工作的推进,规范、统一的标准采集设备已经成为收集语音样本数据的必备工具。一般来讲,标准采集设备默认的语音采样率为16 kHz。为了模拟涉及该类录音案件的说话人识别情况,将用于训练系统识别背景模型和评测系统的语音采样率设置为16 kHz, 然后按照2.2所述方法对系统识别性能进行评测。表3为基于16 kHz采样率语音的d-vector PLDA说话人模型的系统识别结果。
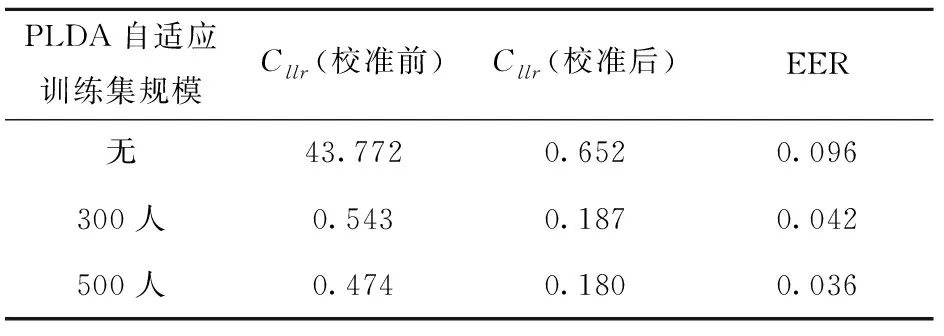
表3 16 kHz采样率语音数据的系统识别结果
表3的结果表明,未进行PLDA自适应训练步骤的系统经校准后的Cllr值为0.652,EER值为0.096,虽然具有一定识别效果,但识别性能仍有待提升。使用300人语音PLDA自适应训练集的系统Cllr值在校准前和校准后分别为0.543和0.187,EER值为0.042,校准后的系统性能有大幅提升。该系统与未进行PLDA自适应训练的系统相比,识别性能提升了约71%,EER值降低了约56%。基于500人语音PLDA自适应训练集的系统校准前和校准后的Cllr值分别为0.474和0.180,EER值达到了0.036,与未使用PLDA自适应训练集的系统相比,该系统的识别性能提升了约72%,EER值降低了62.5%,整体识别效果为本组最佳。
将本系统与8 kHz采样率语音条件下的系统识别性能进行比较后可知,在未使用PLDA自适应训练集的情况下,基于16 kHz采样率语音的d-vector PLDA模型系统识别效果相对于基于8 kHz采样率语音的系统提升了约25%,EER值降低了约51%;在使用300人语音PLDA自适应训练集的条件下,本系统相较于基于8 kHz采样率语音的系统识别性能提升了约32%,EER值降低了约40%;在使用500人语音PLDA自适应训练集的条件下,本系统的识别性能提升了约33%,EER值降低了约45%。整体而言,基于16 kHz采样率语音的d-vector PLDA模型系统的识别效果相较于基于8 kHz采样率语音的系统具有显著提升。
综上所述,基于16 kHz采样率语音的d-vector PLDA模型系统的识别性能优异,系统的识别性能与语音采样率的高低具有很强的相关性。一般来讲,基于高采样率语音训练测试的模型系统识别效果优于基于低采样率语音的模型系统,因此在进行模型训练时应尽量使用高质量语音,从而保证系统的识别效果。除此之外,校准可以提升系统的识别性能,且PLDA自适应训练集的使用对系统识别效果的提升具有正向作用,该结论与前述结果一致。
16 kHz采样率语音数据的系统验证的Tippett图见图6~8。

图6 未进行PLDA自适应训练的系统识别结果(16 kHz采样率语音数据)

图7 300人语音数据PLDA自适应训练集的系统识别结果(16 kHz采样率语音数据)

图8 500人语音数据PLDA自适应训练集的系统识别结果(16 kHz采样率语音数据)
3.2 基于不同规模训练集的系统验证结果
表4的系统识别结果表明,不同规模的PLDA自适应训练集对系统识别性能影响程度不同。将语音采样率固定在8 kHz时,分别使用100~500人的语音进行PLDA自适应训练,校准后的说话人识别系统Cllr值分别为0.340、0.298、0.273、0.271和0.269,全部处于0.25~0.35的区间内,平均值为0.290 2;系统的EER值分别为0.095、0.076、0.070、0.068和0.065,平均值为0.074 8,整体识别性能良好。基于上述结果可知,系统的识别效果随着PLDA自适应训练集规模的扩大而提高,且基于500人语音(本组最大规模)PLDA自适应训练集的系统识别性能最佳,相较于使用100人语音(本组最小规模)进行PLDA自适应训练的系统,其识别性能提升了约20.9%,EER值降低了约31.6%,系统间的识别性能差距较为明显。PLDA自适应训练集规模达到300人时,系统识别性能已趋于稳定,并达到相对较好的识别效果,但较大规模的PLDA自适应训练集对系统识别性能的提升效果更为显著。

表4 基于不同规模PLDA自适应训练集的系统识别结果
将语音采样率固定为16 kHz时,分别使用 100~500人语音PLDA自适应训练集进行说话人识别验证,系统的Cllr值经校准后分别为0.233、0.197、0.187、0.184和0.180,平均值为0.196 2;EER值分别为0.056、0.046、0.042、0.036和0.036,平均值为0.043 2。整体而言,系统识别效果较为理想,且基于500人语音(本组最大规模)进行PLDA自适应训练的系统识别性能达到最优,相较于使用100人语音(本组最小规模)PLDA自适应训练集的系统,其识别性能提升了约22.7%,EER值降低了约35.7%。综合看来,系统的识别性能与使用的PLDA自适应训练集规模呈正相关,且PLDA自适应训练集规模达到300人时系统识别效果已相对较优,与前述结果一致。
图9和图10为不同语音采样率条件下基于不同规模PLDA自适应训练集的系统识别Cllr值和EER值变化折线图,可更为直观地展示系统识别结果变化趋势。

图9 基于不同规模PLDA自适应训练集的系统识别Cllr值折线图
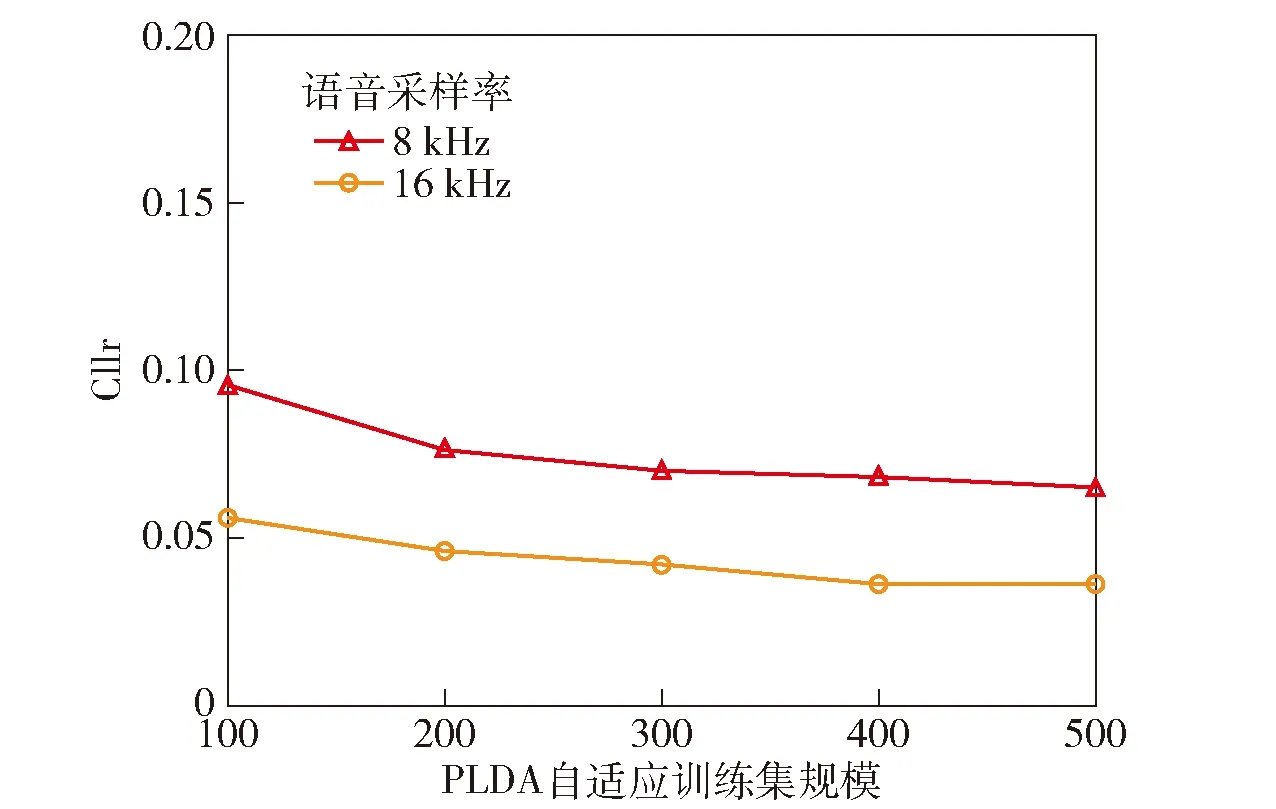
图10 基于不同规模PLDA自适应训练集的系统识别EER值折线图
综上所述,使用较大规模的PLDA自适应训练集对系统识别性能的提升效果更加明显。本测试中,随着PLDA自适应训练集规模的增大,系统识别性能更趋稳定,且PLDA自适应训练集规模达到300人时,系统的识别效果已相对较优,可以达到实用需求。使用500人语音进行PLDA自适应训练的系统识别性能最佳,但仍有进步空间。下一步,可继续扩大PLDA自适应训练集的规模对系统识别性能进行评测。另外,还需要使用更多不同言语风格和质量条件的语音进行测试,以进一步评估系统在多种案件现实条件下的准确性和可靠性。
4 结论
本文选用开源语音数据集VoxCeleb1和VoxCeleb2作为系统评测语料,在基于不同采样率语音数据和不同规模PLDA自适应训练集的情况下,使用似然比证据评价体系对基于d-vector PLDA模型的法庭说话人自动识别系统进行了识别性能的验证与比较研究。研究结果表明,在典型的8 kHz采样率的语音训练测试条件下,系统识别性能良好。而高采样率语音训练测试的模型系统识别效果优于低采样率语音的模型系统,较大规模的PLDA自适应训练集对系统识别性能的提升更有帮助,但需要综合考虑自适应训练集的采集成本。总体而言,基于深度神经网络模型构建的说话人自动识别系统识别性能良好,具有较高的应用价值和潜力。
此外,本系统在该类场景数据的识别性能较为理想,但并不代表该系统在其他实际案件语音条件下的验证测试中都能够达到同样效果。司法实践中,每个案件的场景或多或少都有一定差别,如信道设备、环境噪声、言语风格等,导致其数据质量和特点也会有所差别。因此,必须进行系统验证,才能科学客观地评价法庭说话人自动识别系统的准确性和可靠性。在科学研究中,应该尽可能对丰富多样的、能够反映实际案件条件的语音数据进行验证。在司法实践中,还要基于被检案件的具体语音条件进行验证。而对于不同的方法系统,开展基于现实案件语音条件下的系统性能验证具有双重价值,一方面可以及时发现与解决自动识别系统在现实应用中存在的问题,改进和提升系统的识别性能;另一方面能够表明不同典型场景数据条件下所使用系统方法的准确性和可靠性,为司法实践提供客观的量化依据。
