机器学习结合分子指纹预测过硫酸盐氧化体系污染物的降解速率常数
2022-07-18潘思远
杨 鹰,潘思远
(中南大学 化学化工学院,湖南 长沙 410083)
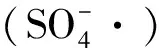

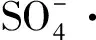
1 材料和方法
1.1 数据集与MF计算
1.2 模型开发
RF是基于一组决策树的集成方法[15],是分类和回归模型中最常用的算法之一.RF算法采用随机性的方式开发树结构,每棵树都有一组随机变量,这会促成较大的多样性,从而生成更好的模型.
XGBoost是一种基于梯度提升决策树的方法.该算法是在相同的Gradient Boosting框架下开发的,具有高效、灵活和可移植的特点.XGBoost 提供了一种并行树强化(即生成提升树且并行操作),可以快速准确地解决许多数据科学问题.
在训练过程之前,需要确定超参数(Hyperparameter)的值.调整超参数是优化任何 ML方法性能的必要步骤.表1总结了RF和XGBoost超参数的名称、作用以及它们的取值范围.由于存在较多超参数,其值的变化范围很广,因此无法枚举每个值以找出最佳值.因此,我们采用了PSO算法[16],该算法来源于鸟群觅食行为研究,粒子模拟鸟类,每个粒子都代表一种可能的解决方案,从而使实现超参数最优值的可能性被最大化[17-18].
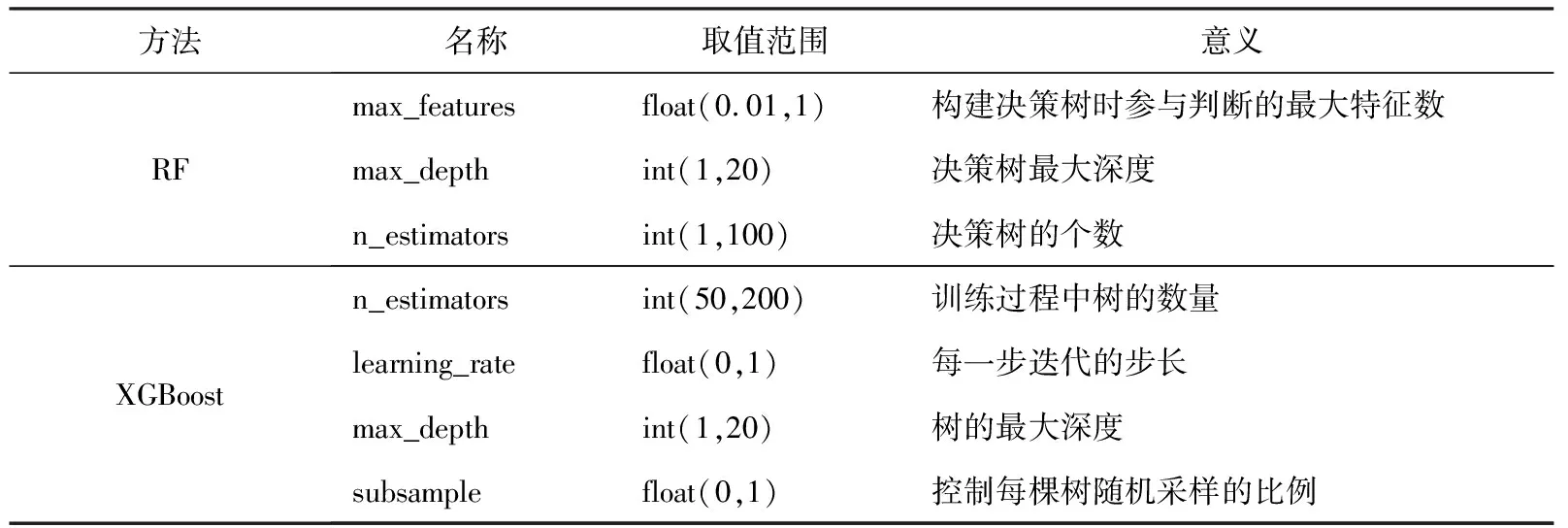
表1 随机森林(RF)和极端梯度提升(XGBoost)模型的超参数
1.3 模型验证
模型校验在回归模型的开发中至关重要.本研究采用两种验证方法用于评估生成的QSAR模型的性能,包括使用训练集的内部验证和使用测试集的外部验证.这些方法在评估所构建模型的稳定性和可靠性方面起着关键作用.建立的QSAR模型使用决定系数(R2)和均方根误差(RMSE)进行评估.通常,较高的R2值和较低的RMSE值意味着模型的性能是优秀的.R2和RMSE的计算方法如下:
(1)
(2)
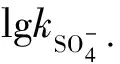
2 结果与分析
2.1 MF半径和长度


图1 MF半径和长度对RF和XGBoost模型的影响
2.2 粒子群优化模型超参数
经过500次优化迭代,得到了RF和XGBoost模型每次迭代的RMSEtest值,如图2所示.

图2 RF和XGBoost模型的粒子群优化结果
随着迭代次数的增加,RMSEtest在快速下降后逐渐趋于平缓,表明结果接近最优解.使用最小RMSEtest值对应的超参数值作为优化结果,列于表2.

表2 通过粒子群优化得到的RF和XGBoost模型的超参数
2.3 模型性能
图3展示了两个模型预测值和实验值的散点图.可以看到,XGBoost模型的拟合和预测性能明显优于RF模型,预测值和实验值沿对角线密集分布,表明XGBoost模型成功地学习了输入和输出之间的关系.XGBoost模型训练集R2和RMSE分别为0.999 5和0.020 9,表明模型优秀的拟合性;测试集R2和RMSE分别为0.837 8和0.316 0,证明模型具有良好的鲁棒性.总结过硫酸盐体系的QSAR模型,其性能参数列于表3.
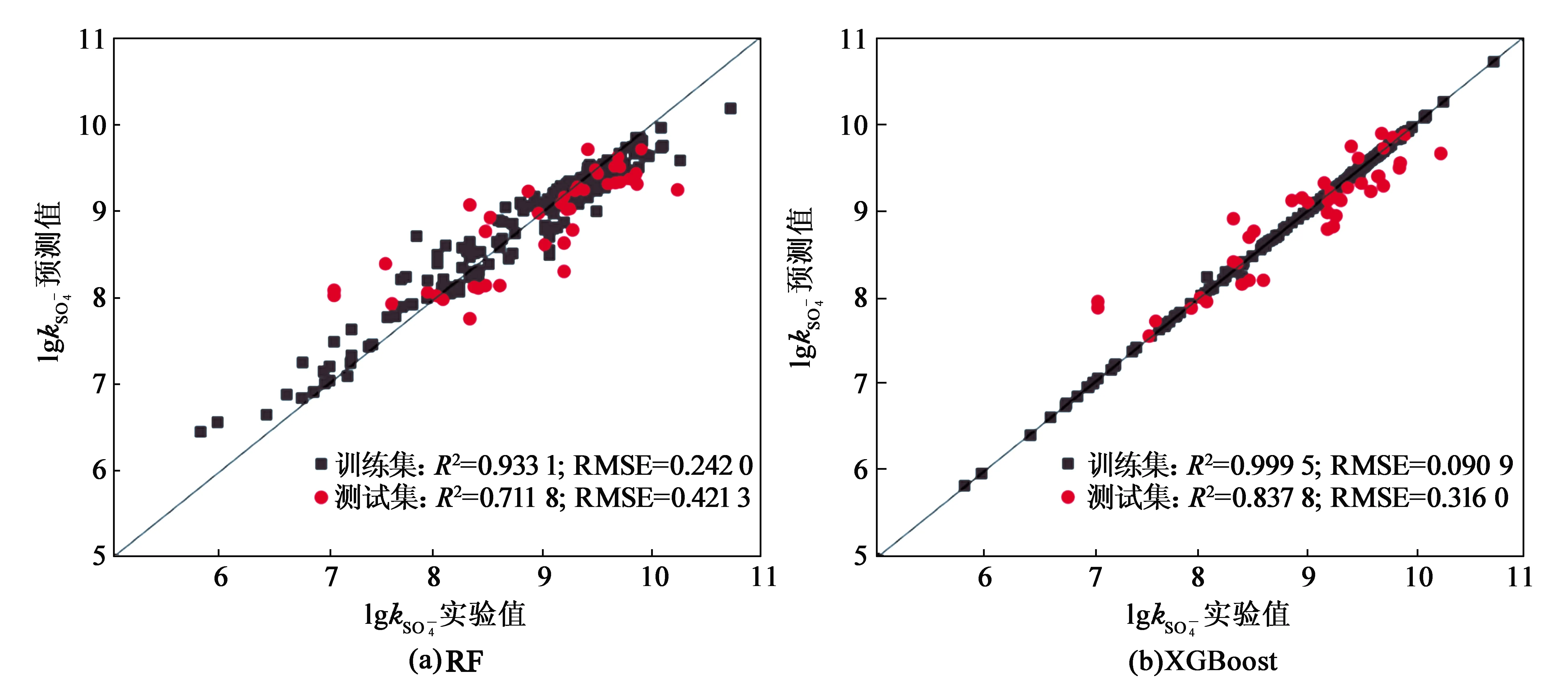
图3 RF和XGBoost模型的实验值对比预测值的散点图
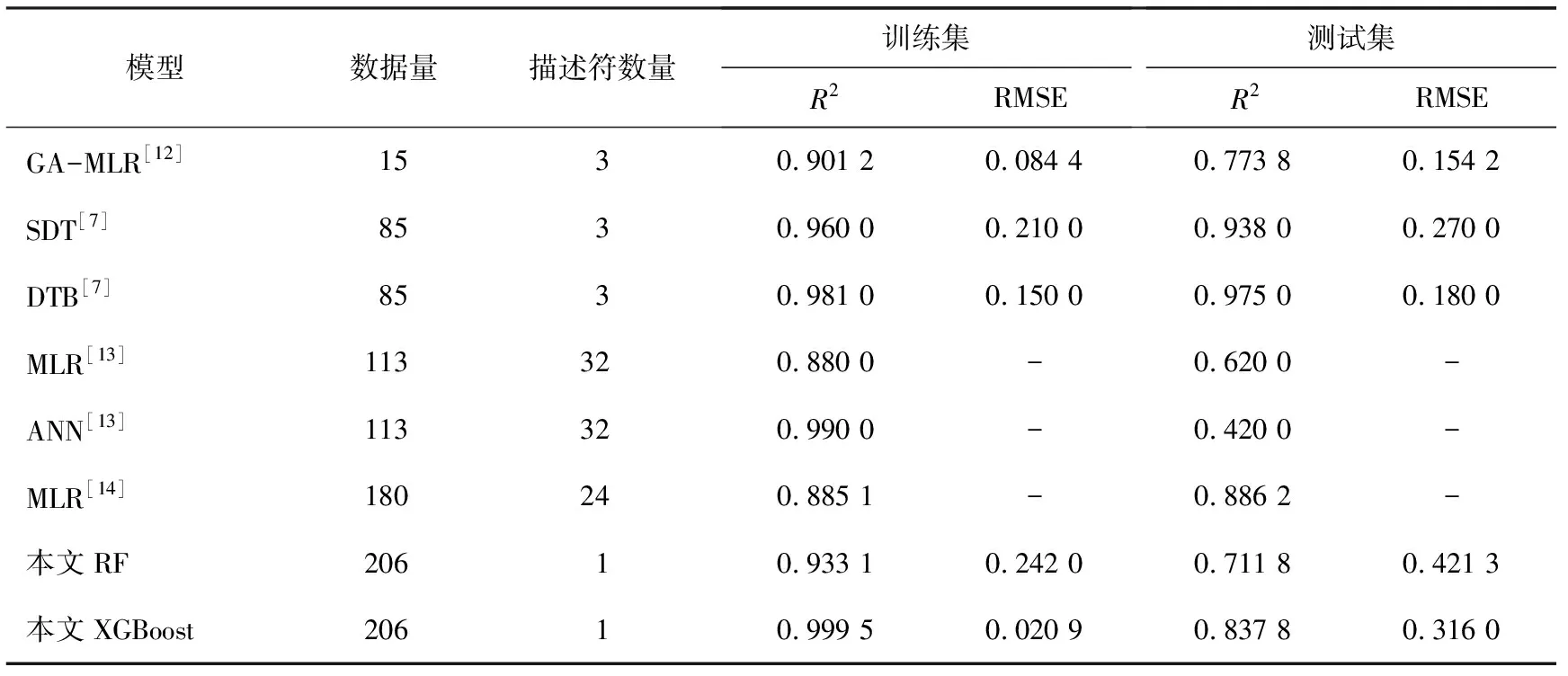
表3 过硫酸盐体系QSAR模型比较
与本研究选择MF作为模型的输入不同,其它的文献模型均使用MD作为输入,这在一定程度上增加了模型建立的成本.通常,随着数据集数量的增加(从15增加到180),为了使模型具有更好的预测性能,需要引入更多的分子描述符(从3增加到32),但由于变量间复杂关系的增加,可能导致模型性能的下降(R2从0.975 0降低到0.420 0).本模型只使用了MF这一种描述符,但是在更大的数据集(206)上,仍然获得了较好的拟合性和鲁棒性,这主要归因于MF对分子结构信息的简结且完整表达.可见,从模型开发效率和预测性能两个方面来说,MF相对于MD是一个更好的选择,基于MF的QSAR模型方法在未来将会显示优秀的发展前景.
2.4 SHAP解释模型

图4 SHAP方法解释XGBoost模型的最重要的10个MF位点
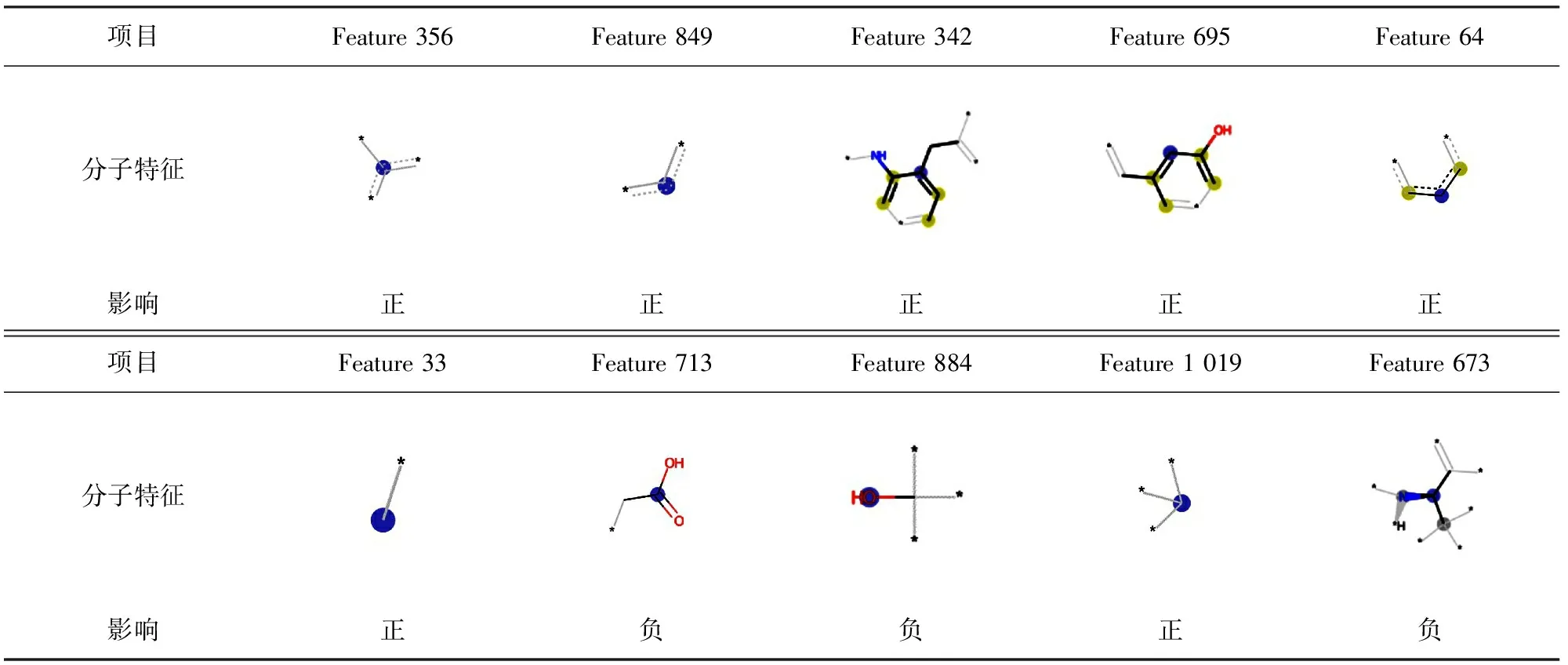
表4 图4中前10个特征以及代表的原子组和对反应速率常数预测的影响
3 结论
