数据可视化素养量表设计研究*
2022-07-18吴晓伟龙青云易艳红黄务兰
吴晓伟 龙青云 易艳红 黄务兰
(上海商学院 上海 200235)
随着可用数据量的增加,数据可视化变得越来越流行和重要。可视化能够简洁地表示复杂的底层数据,能从数据中提取有用的信息,掌握信息的含义,并直观地表示结果。近年来,国外学者开始对数据可视化素养(Data Visualization Literacy,DVL)进行研究,以期在大数据环境下对数据素养能力的认识进行提升和补充。一个人阅读、理解和解释数据可视化的能力会强烈影响他/她的任务和交流。换言之,数据可视化素养正变得与阅读和理解文本的能力同等重要[1]。最近的一项研究表明,普通人的可视化素养水平较低,在理解和解释数据可视化方面存在局限性[2],可见数据可视化素养教育的重要性。目前,数据可视化素养本土研究相对匮乏,尤其缺乏评价框架和测试量表,这不利于大数据环境下国家对人才培养的要求。本文梳理国内外数据可视化素养研究,结合人力资源领域的KSAO模型,提出基于KSAO模型的数据可视化素养评价框架,并以大学生新生数据可视化素养量表设计为例说明量表设计过程,以期给后续的大学数据可视化教育内容、模式提供参考和指引。
1 数据可视化与数据可视化素养
在构建数据可视化素养框架前,有必要对现有的数据可视化和数据可视化素养方面的概念有所了解。
1.1 数据可视化
18—19世纪,人们就已经掌握了整套统计数据可视化工具,如常用的柱状图、折线图、直方图、饼图、时间线等[3]。1967年Bertin出版了《图形符号学》一书,确定了构成图形的基本要素,奠定了现代信息可视化的理论基础[4]。1982年2月,美国国家基金会首次召开了“科学可视化”命名的会议。科学可视化聚焦于科学、工程领域的可视化分析,数据通常表达的是二维、三维空间或者包含时间维度,目前已经成为可视化分析技术中最成熟分支。同时期,多维统计图形的诞生使可视化表现数据的范围从传统的统计数据扩大到多源、多层次、高维的数据。1995年,召开了专门面向抽象、高维数据的信息可视化会议——IEEE Information Visualization。信息可视化主要处理非结构化、非几何化的抽象数据,如金融交易、社会网络、文本数据等[3]。
进入21世纪,社会进入了大数据时代。数据可视化登堂入室,它综合了科学可视化、信息可视化、可视分析学,其呈现对象可以是任何数据类型,任意数据特性。数据可视化还原甚至增强数据中的全部结构和细节,真正做到视物致知。
1.2 数据可视化素养
数据可视化素养到目前还没有统一定义。2014年,Boy等人第一次提出了可视化素养概念,将其定义为“良好的使用数据可视化(如线图)以有效、高效和自信的方式处理信息的能力[5]。Boy的可视化素养注重从可视化呈现中提取信息,没有考虑用可视化来分析、解决问题。2015年,Börner 认为数据可视化素养是指从数据的可视化表示中产生意义并解释模式、趋势和相关性的能力[2]。Lee认为上述两种定义均有一定缺陷,即:a.词语使用的模糊性,如良好、有效、高效和自信的方式;b.狭义的任务类型,例如解释模式、趋势以及相关性。素养在韦氏字典中被定义为“读写能力”,其有消费和生产两个方面。当素养与其他学科(如信息素养、健康素养和能源素养)相结合的时候,更多的是指从消费角度来理解和使用某些东西的能力。Lee从这个视角出发把数据可视化素养定义为在数据可视化中阅读和解释可视化数据并从中提取信息的能力和技能[6]。
2019年,Börner整理了近年来的数据可视化素养研究成果,提出了数据可视化素养框架体系,该框架由需求洞察(Insight Needs)、数据类别(Data Scales)、数据分析(Analyses)、可视化呈现(Visualizations)、图形符号(Graphic symbols)、图像变量(Graphic variables)、交互方式 (Interactions) 等7个维度构成,每个维度包括了数据可视化所需的各种知识要素,其来源于广泛的文献研究[7-8]。Börner的框架内容体现了数据可视化流程——任务解析、数据理解、寻求可视化方法、可视化实现、发现知识的五个阶段[9]。
综合上述文献研究,我们把数据可视化素养定义为一种既能从可视化呈现中提取数据、信息和知识又能运用可视化处理数据、指导决策和完成任务的能力。具有良好数据可视化素养的大学生应能根据任务需要在数据域与可视化域之间进行切换,能充分利用和发挥可视化胜于读、写、计算的优势。
近年来,研究用户的数据可视化素养已经成为数据可视化研究的热门主题。比如Boy等人提出了基于项目反应理论的可视化素养评估方法,试图了解大众对数据可视化理解的现状[5];Börner让273名博物馆访问者观看了20种不同可视化效果的数据来确定青少年和成人对可视化呈现的熟悉程度[2];有的还提出了学习不熟悉的可视化的各种方法,以提高用户的可视化素养[10-11]。一些研究人员定性地调查了用户在努力理解数据可视化时的认知活动,建立信息可视化感知的扎根模型[12]。知名的可视化国际会议也认识到这一主题的重要性。如EuroVIS 2014研讨会:走向可视化素养;IEEE VIS 2014研讨会:走向开放的可视化素养测试平台;IEEE VIS 2015中的一个小组讨论:VIS,下一代:跨越研究者——从业者鸿沟的教学[6]。从已有研究可以发现,当前研究存在三方面不足:a.评估量表没有完全体现数据可视化素养中的“数据”要素构成。量表主要集中在可视化技能测试,对数据和数据分析的题项几乎很少涉及。b.作为一种素养测试,还要体现素养对人的通用能力的提升作用,这需要专门的测试题项。c.没有认识到数据可视化素养是分层、分阶段的。数据可视化素养除了通识素养(社会必备的基础素养),还有按学历层次、按专业、按职业的特定素养。本文认为可以把人力资源管理中的KSAO模型结合数据可视化概念来建立数据可视化评估框架,再根据特评估对象特征设计相应的量表,能很好弥补当前研究不足。
2 基于KSAO模型的数据可视化素养评价框架
2.1 评价框架的维度构成
数据可视化素养量表可以参考人力资源领域中广泛应用的KSAO模型进行设计。KSAO模型用知识、技能、能力、其他个性特质来描述岗位资质[13]。具体来说知识是执行工作所需要的专业知识、管理知识、行业知识等,这些可以通过学校教育、行业培训获得;技能是在工作中运用某种工具或者操作某种设备以及相关的技巧和经验,可以通过课堂训练,日常实践来掌握;能力是指人的通用能力,如逻辑思维能力、学习能力、观察能力、解决问题的能力、基本的表达能力等;其他主要是指有效完成某一工作需要的其他个性特质,包括对员工的工作要求、工作态度、工作意识、个人个性以及其他的特殊要求。
KSAO模型和素养内涵具有很好的契合度。经济合作与发展组织(OECD)认为素养不只是知识与技能。它是在特定情境中,通过利用和调动心理社会资源(包括技能和态度)、以满足复杂需要的能力。素养的内涵要体现四种关系:素养与知识、素养与基本技能、素养与情境、素养与表现[14]。KSAO中的K、S对应了前两者关系,而A、O对应了后两者。KSAO模型结合专业素养特点,能全面描述素养的评价内涵,已被应用在学生和教师的数据素养评价中[13-15]。同样,根据数据可视化定义和参考相关的研究成果,结合KSAO模型中各模块内涵,则可以得到基于KSAO的数据可视化素养评价框架,如表1所示。表中的指标具体释义将在后面的量表设计中展开。

表1 基于KSAO的数据可视化素养评价框架
2.2 基于KSAO的数据可视化素养评价框架优势
基于KSAO的数据可视化素养评价框架有以下四个方面的优势:其一,具有科学性。各模块指标概念界定清晰,能充分反应可视化素养的成长路径,即意识——知识——技能——能力。通过“其他特质”模块,加入数据可视化意识、数据可视化安全以及社会法律道德维度,体现了数据可视化作为一种素养必备的社会伦理观、道德观。其二,具有通用性。指标内容充分考虑了现阶段国内外的数据可视化素养的研究成果,选取和汇总了国内外文献中具有广泛性、权威性的评价指标。其三,具有可操作性。研究人员能够根据测试人员社会背景、知识结构,依据框架各维度要求,便捷地设计相关量表题项。其四,具有很好的指导性。KSAO来源于人力资源评价,体现了企业对入职员工的基本知识和技能要求。按照KSAO框架设计出来的数据可视化素养量表可以较好评估当前学生可视化课程设置是否符合社会、行业和企业的要求,能对现有的教学内容、教学模式给与针对性指导。综上,基于KSAO的数据可视化素养评价框架与基于数据可视化流程的Börner框架相比,评价内容更全面,更具有实操性。
3 大学新生数据可视化素养量表设计和分析
本文以大学新生为例来说明数据可视化量表如何设计。量表要依据数据可视化素养评价框架,同时要结合大学新生测试群体的知识结构进行开发。为更好了解大学新生的状况,本研究邀请了10位专家对题项内容把关。其中2位中学老师从事数学和信息技术的教学工作,高校老师中2位教授,3位副教授,主要从事计算机基础、大数据分析、大数据可视化、电商运营等方向的教学和科研。3位行业专家来自大型电商平台的营销部门、政府舆情管理部门。最终量表是否合适,还要进行内容效度和信度分析。由于数据可视化远没有读写、算术那样成熟和普及,有些名词术语还没有统一,故在测试前,应对量表中涉及的专业词汇向测试对象解释说明。
3.1 与数据可视化相关的基础知识题项设计
3.1.1数据知识
数据是理解和实现可视化分析的基础。数据可以分为四类:定类数据、定序数据、定距数据、定比数据[4]。不同类型的数据适用不同的统计运算和数据分析。在数据可视化中,一般把上述四类简化为三类:定类数据、定序数据、数值型数据(包括定距数据与定比数据)。
在Börner框架中,除了常规的统计分析外,对于数据分析还要能用时序分析发现数据的发展趋势,通过空间分析解析数据的空间分布,通过主题分析揭示文本内容的主要构成,通过关系分析发现映射数据之间的相关性以及网络结构[7]。
数据知识方面要求测试者具备常用的统计学,还需对地理学、语言学、网络科学等学科技术有所了解。数据类型与数据分析的理解能力是数据可视化素养的核心构成要素,决定了能否正确选择合适图形符号、图形变量进行可视化呈现,这是数据可视化素养与只强调读取可视化信息的可视化素养区别。
大学新生的数据知识主要参考国内中学数学教材,并对两位中学教师进行了咨询,考虑到可视化图表应用场景,数据知识主要集中在基本的统计知识方面。知识点包括数据类型识别和基本统计知识。统计知识方面主要测试学生对平均数、中位数、众数、极差、方差认识,以及频率、回归分析等掌握,主要采取单项选择题形式,见表2所示。

表2 数据知识题项
3.1.2可视化知识
大学新生的可视化知识主要从熟悉的中学教材、主流的网络媒体以及接触过的可视化工具来习得。通过查阅国内中学教材,可以发现中学课堂教学中已经接触过的可视化图有6种类型:折线图、条形图、饼图、散点图、直方图、茎叶图。分析新浪、网易、人民网3个主流媒体新闻稿中的可视化图表使用频率及主流可视化软件如Tableau、Power BI、ECharts、EXECL中的基本可视化图形类型,我们可以得到常见的可视化图有折线图、条形图、堆叠条形图、饼图、散点图、直方图、面积图、堆叠面积图、矩形树形图、瀑布图、气泡图、地图、热图、漏斗图、盒须图、甘特图等。
可视化呈现是通过可视化编码来实现的,可视化编码是将数据信息映射为可视化元素的技术,这是数据可视化的核心。测试者应对3个方面的知识有基本的了解。其一,要认识到不同的图形实质是不同数据类型的组合。比如折线图是由一个定序数据和一个数值型数据构成。饼图是由一个定类数据和一个数值型数据构成等。其二,要能了解可视化编码中的图像符号和图像变量的含义和作用。图像符号具有分类性质,主要包括点、线、面积、体积4种几何符号,不同符号可以表示不同的数据属性,是数据属性到可视化元素的映射;图像变量通常由位置(平面或空间坐标)、长度、大小(粗细)、形状、方向(角度,斜度)、颜色(色调、饱和度、亮度)、纹理等构成。有的图像变量有分类性质,有的有定量性质。比如可以用形状来表示订单的产品类别、所在地区等类别属性,用长度表示订单利润、销售额等定量值。其三,要对各种可视化图形的应用场景有所了解。参考蚂蚁数据可视化图表场景分类,应用场景主要包括8种情况:比较、趋势、组成、占比、分布、排名、关系、空间[16]。比如折线图可以用来比较、趋势分析,堆叠面积图有比较、趋势和组成分析的应用等。
根据Lee的研究,测试图形选择需综合考虑可视化图表普及性以及测试对象对图表教育的熟悉程度[6]。根据国内情况,并咨询高中、大学学科教师,本文选取折线图、条形图、堆叠条形图、饼图、散点图、直方图、面积图、堆叠面积图、气泡图、瀑布图、热图、矩形树状图作为知识测试题项。题项重点考查测试者对基本图形中的数据类型、图形符号和图形变量的认知。题项描述尽量不出现可视化的专业词汇,用通俗易懂的文字描述,回答采用对错或者单项选择方式。考虑到后面可视化技能测试,为节约篇幅,我们把知识和技能题项合并在一起,见表3所示。

表3 可视化基本知识与读取理解技能题项
3.2 与数据可视化相关的技能题项设计
3.2.1可视化图形的读取和理解技能
Bertin提出用3个层次来解释图形:初级、中级和综合。初级是从可视化图表中简单地提取信息。中级涉及趋势和关系的检测。综合层面是对整体结构的比较及基于数据和背景知识的推论[4]。Boy提出了6种初中级读取任务:最大值、最小值、变化量、交点、平均值、比较值[5]。Börner数据可视化素养框架中把任务分为7种:分类/聚类、排序、分布(包括特异值)、比较、趋势(过程和时间)、成分、相关性/关系,这些任务以中高级任务为主[7]。结合可视化应用场景,本文采用9种基本测试任务:检索、比较、占比、排序、分布(异常)、分类、关系、趋势、预测。其中检索、比较、占比、范围、分布属于初级,关系、趋势属于中级,预测属于高级。表3是对常用图形给出了相关的知识与技能的测试题项,要求测试者进行对错或者单项选择。
3.2.2可视化呈现能力
可视化呈现能力是数据域到图形域的转换能力。题项设计主要侧重考察测试者能否找到合适的图形与任务场景中的数据进行匹配。从可视化基础知识可知,不同的可视化呈现由不同数据类型构成,应用的场景也是完全不同的。比如要观察定序数据(时间)和数值型数据变化时常用的图形是折线图和面积图,如果选择散点图就不适合,因为散点图用于观察2~3个数值型数据之间的关系,若选择用条形图、饼图、气泡图就更不能完成任务要求了。咨询高中教师,根据大学新生对图表的熟悉程度,设计如下题项:Q64、若想了解中国自2000年以来每年GDP变化趋势,用哪个图形呈现比较好;Q65、若想了解中国各省市自治区2019年GDP情况,用哪个图形呈现较好;Q66、如果想了解一个人体重和高度是否存在一定的关系,用哪个图形呈现较好;Q67、如果想要描述一个家庭全年各种支出占比情况,用哪个图呈现较好;Q68、比较男女同学语文、数学、外语三科平均分情况,用哪个图呈现较好;Q69、描述2000年后,每年居民收入、支出、存款趋势,用哪个图呈现较好;Q70、要了解全班同学每分钟跳绳个数情况,用哪个图呈现较好。Q64-Q70题项,分别了解测试者对常用的折线图、散点图、条形图、堆积条形图、饼图、面积图、堆积面积图、直方图的应用能力,涵盖了比较、占比、排序、分布(异常)、分类、关系、趋势等任务场景。题项回答用单项选择或者对错形式进行。
3.2.3数据可视化软件应用能力
数据可视化软件大致分两类:一类是不需要编程能直接使用的,另一类是作为工具库,需通过编程使用。对于非专业人员,如果能掌握一些主流的非编程数据可视化软件对数据可视化能力提升会有助推作用。数据可视化软件应用能力设计两个题项:Q71、RAWGraphs、ChartBlocks、Tableau、Excel、Power BI、QlikView、Echarts、Plotly、Google Charts、AntV这些可视化软件,你听说过的有几款( ),如果你还知晓的是其他数据可视化软件,请列出它们( ),你平时需要图表制作时,常用的软件是( );Q72、你对知晓的可视化软件的熟练程度( )。题项Q71主要询问测试者对主流数据可视化软件知晓程度,该题项采用选择题回答,同时给予测试者开放的回答,知晓软件越多,说明测试人员对可视化工具越熟悉。题项Q72采用五级里克特量表对熟练程度进行回答。
3.3数据可视化相关的通用能力题项设计
各种素养的训练最终是为了提高通用能力。数据可视化素养培育和提升最终会在学生的空间感、反应速度、逻辑思维、学习能力、观察能力、解决问题能力、表达能力这些通用能力上得到体现。题项Q73-Q75主要考察测试者是否能把数据可视化与日常学习、与人沟通、困难问题解决进行结合,提高任务完成的效率。具体如下:Q73、平时,在学习(课堂教学、课后作业、论文写作)中是否用图形、图像这些可视化工具;Q74、当你解决问题遇到困难时,是否会用一些图形、图像或者可视化工具来帮助打开思路;Q75、当你和别人沟通有问题时,是否会借助一些图形、图像或者其他可视化工具。测试者采用几乎不、非常少、一般、比较多、经常五级里克特回答。
3.4 数据可视化相关的其他特质题项设计
3.4.1数据可视化意识
数据可视化意识主要是指测试者能够意识到可视化图表已在大数据社会下被广泛使用,可视化呈现在新闻报道、社会媒体、公共场所、政府工作、企业运营中随处可见,可视化已经和文字、声音一样成为基本的信息来源渠道。同时能意识到,要读懂和理解可视化图表需要一定的知识和技能训练,数据可视化能力和读写、算术一样,只有通过学习与实践才能提升。设计题项Q76-Q78如下:Q76、我感觉到可视化呈现,如折线图、柱状图、直方图、饼图、散点图、气泡图、树形图、地图等在新闻、媒体、公共场所中越来越随处可见;Q77、通过可视化呈现,我可以像文字、声音一样获得信息;Q78、读懂可视化呈现需要像读写、算术一样进行训练和学习。题项回答用“完全同意”“同意”“不一定”“不同意”“完全不同意”五级里克特量表进行选择。
3.4.2与数据可视化相关的安全和法律道德安全和法律道德主要考察测试者面对可视化图形、图像时是否有较高的网络安全意识和知识产权意识。设计题项Q79、Q80如下:Q79、当你用图形、图像在和别人交流或在网络上发布的时候,是否意识到图形、图像蕴含大量的数据信息,有安全隐患;Q80、当你在下载和应用别人的图形、图像作品时候,是否认为它们有知识产权的保护,要注意法律问题。题项回答均采用五级李克特回答。
3.5 内容效度和信度检测
本文用专家调查法对量表进行内容效度检测,内容效度一般用内容效度比、效度系数指标来整体衡量[17]。内容效度比(Content Validation Ratio)用CVR来表示,当CVR为负值时候,说明认同题项内容合适的专家不足一半,一般要把CVR<0题项删除或者重新出题。CVR值越靠近1,说明量表的效度越好。效度系数用B来表示,B值越接近0,表明各个专家对题项效度的认识越趋向一致,指标体系的有效性就越高。
表4是本文邀请的10位专家对量表内容效度打分情况,考虑到篇幅只显示了部分。表中Q34题的CVR值是-0.4,值小于0,此题需重新出题。Q34题是对面积图的可视化知识进行测试,专家认为要突出面积图中的面积概念,故改为“11月用电量大于1月份用电量,是否意味着11月区间面积要大于1月区间面积”。表4的其他所有题项的CVR值均大于0,说明专家对这些题项认同度高。量表整体CVR=0.91,量表内容效度能很好符合框架各维度的含义,另外,效度系数B=0.08,专家认知基本趋于一致。
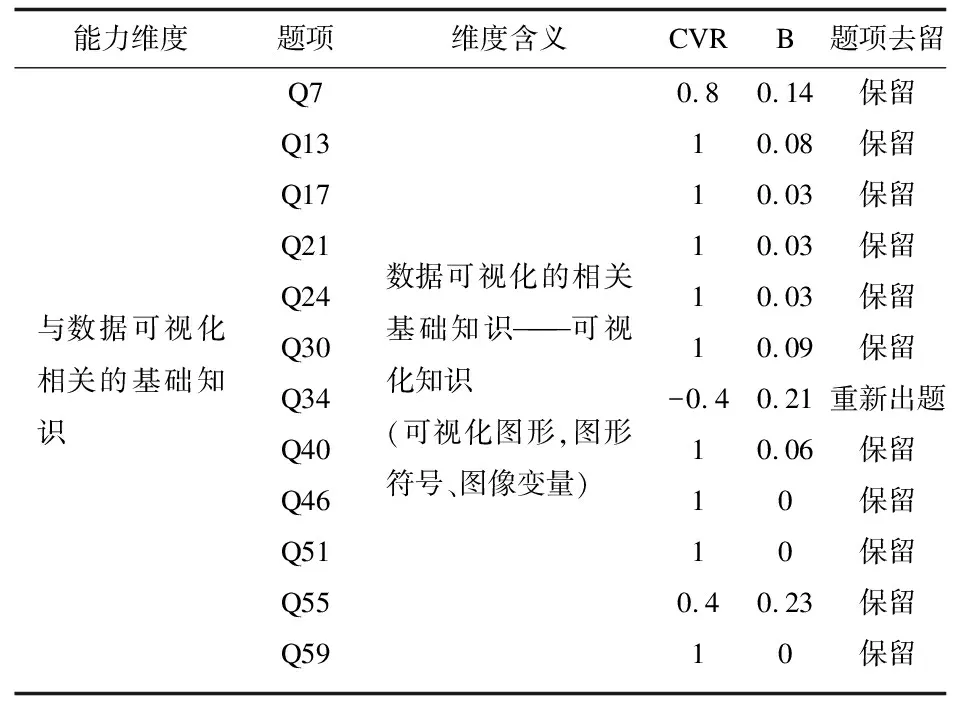
表4 数据可视化素养量表内容效度分析(部分)
同时,对该校2021级信管专业新生进行测试,获取量表的克隆巴赫信度系数,总体Alpha系数为0.891,大于0.6,说明量表具有较好的信度。
4 总 结
本文提出了基于KSAO模型的数据可视化素养框架,依托此框架,结合大学新生的特点,开发数据可视化素养量表,该量表具有较好的内容效度和信度。后面将用此量表对学校新生进行测试和评估,通过总体和各维度得分分析,可以获得当前大学新生的数据可视化素养现状,能对未来的数据可视化教学给与指引。面向大学新生的量表设计思路给各种场景的数据可视化能力测试提供了一种路径。我们可以按照专业特点、学生分类、职业分类和数据可视化素养框架进行结合开发各种有针对性的量表。根据量表的测试分析,可以为后续的数据可视化课程体系、培训内容、教育模式、教学方法给提供有价值的指导。
