密集视频描述中单词级遗忘度优化算法
2022-07-17盘晓芳杨大伟
盘晓芳,杨大伟,毛 琳
(大连民族大学 机电工程学院,辽宁 大连 116605)
密集视频描述的主要任务是输出描述多个事件的长语句[1,2]。在视频关键内容检索应用中,由于多数视频描述网络在文本生成任务中提取局部语义信息不足,导致视频描述语句简短且代表关键信息的单词不准确,造成检索错误,因此提高视频描述的准确性和多样性是一项亟须解决的问题。
视频描述网络大多采用长短时记忆网络(Long Short-Term Memory,LSTM)[3]和Transformer[4]进行文本生成。Krishna等[5]首次提出用于生成多个文本描述的视频密集事件描述网络(Dense-Captioning Events in Videos,DCEV),该网络以序列-序列视频描述网络(Sequence to Sequence-Video to Text,S2VT)[6]作为生成文本描述的主要结构,利用LSTM完成文本生成任务。但该网络仅以最后的隐藏层信息代表整个视频,导致视频信息有所缺失,进而影响视频描述效果。LSTM采用循环递归方式,不能并行训练,捕捉局部语义信息有限。为解决LSTM存在的问题,Transformer模型利用注意力机制对语义信息构建全局关系,在处理信息缺失的问题上取得了较好的效果[7-9]。Zhou等[10]提出基于Transformer的端到端的视频描述网络(End-to-End Dense Video Captioning with Masked Transformer,EEDVC),利用注意力机制构建输入与输出之间的全局依赖关系。但在Transformer模型中,视频描述性能依赖特征提取质量,不能构建特征编码和文本生成任务之间的相互促进关系,时态逻辑信息捕捉能力有待提高。Wang等[11]提出并行解码的端到端密集视频描述网络(End-to-End Dense Video Captioning with Parallel Decoding,PDVC),该网络采用Transformer端到端目标检测网络模型(End-to-End Object Detection with Transformers,DETR)[12],通过双路并行方式,使视频特征编码和描述文本生成过程相互促进,增强视频特征与文本交互能力,但注意力机制缺少对局部信息单词的关注,影响视频描述性能。Song等[13]提出视频多样性描述网络(Towards Diverse Paragraph Captioning for Untrimmed Videos,TDPC),在Transformer基础上增加动态视频记忆模块,渐进地将全局视频特征分段输送到解码器中,充分利用段落间的语义信息,并兼顾视频描述的准确性和多样性,但在文本描述过程中,多头注意力会忽略对局部语义信息的捕捉,造成部分单词信息错误和缺失,导致语义错误,影响描述结果性能。
为充分描述密集视频中的多个事件,弥补视频描述过程中对部分单词的忽视,本文设计一种单词级遗忘度优化算法(Word-Level Forgetfulness Optimization Algorithm,WFO)。通过调整单词级遗忘度曲线斜率,使动态视频记忆模块增强对局部单词的关注,提升多头注意力模块中视频特征与文本向量的交互效率,在提高视频描述结果准确性的同时,增加生成文本的丰富性。
1 单词级遗忘度优化算法
1.1 问题分析
密集视频描述针对未剪辑的视频生成段落描述,由多个单词构成的长语句表达视频中的多个事件。因此单词是段落描述中的基本元素,单词选取的不同会使文本描述的语义发生变化从而影响描述结果。针对视频多样性描述算法TDPC进行分析,视频如图1。

图1 视频案例
对图1中的视频案例进行描述如下:
(1)基线描述:a person isundressingin front of a mirror . the person then begins undressing;
(2)真值描述:a personholdsherblanketand walks into the room while holding her phone . she puts the phone down but keeps standing holding the blanket.
案例分析详情见表1。
真值描述语句由25个单词组成,而基线描述仅由14个单词组成,且基线算法TDPC将视频内容中“hold her blanket”(拿着她的毯子)错误描述为“undressing”(脱衣),导致文本描述发生语义错误,对视频内容错误理解。由此可见,在注意力机制选择单词时,会选中非视频内容的语义信息。本文提出单词级遗忘度优化算法,调整Transformer解码器中多头注意力输出的权重和文本序列的组合形式,提高文本生成性能。

表1 案例分析
密集视频描述网络主要由Transformer编码器和Transformer解码器两部分组成。Transformer编码器负责生成全局视频特征编码向量,由Transformer解码器完成文本生成任务。密集视频中通常有丰富的时态逻辑结构,直接用解码器的多头注意力学习不能很好地捕获视频时态逻辑信息,因此将编码特征输入到解码器之前,增加动态视频记忆模块,利用渐进记忆功能和渐进遗忘功能,更好地利用时态逻辑结构。
定义1:单词级遗忘度:在视频描述领域中,记忆存储文本特征时,根据遗忘度曲线决定文本特征向量中的单词关注度,遗忘度越低,即对当前单词的关注度越高。
动态视频记忆模块中,控制多头注意力权重αt和历史文本特征序列Lt的遗忘度曲线为
(1)
式中:s为构成语句的平均单词个数;y(t)为单词级遗忘度曲线。在遗忘度曲线中,单词距离与单词遗忘度成正比。相邻单词通常与短语概念对应,短语在一句话的表达中起至关重要的作用,因此采用遗忘度曲线分析其对系统性能的影响。单词级遗忘度优化算法结构如图2。
通过调整遗忘度曲线改变单词级遗忘度,从而优化注意力机制,使模型自动感知文本向量中单词的重要程度,不断优化语义信息的有效性。单词级遗忘度数学公式为

(2)
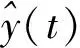
(3)
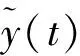

图2 单词级遗忘度优化算法结构
1.2 单词级遗忘度优化算法
单词级遗忘度优化算法整体结构如图3。利用单词级遗忘度调整注意力机制对单词的关注度,进而优化文本描述结果,使生成的描述语句更贴合视频内容。
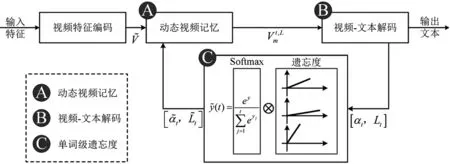
图3 WFO算法整体结构
首先对输入视频特征进行全局编码,视频特征全局编码向量可表示为
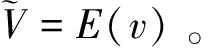
(4)
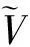
(5)
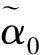
采用B对视频特征编码和文本编码的处理公式为
(6)
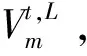
图1中不同斜率的遗忘曲线对视频描述的影响如下:
(1)基线描述:a person isundressingin front of a mirror . the person then begins undressing;
(2)5倍斜率描述:a person is standing in the doorway of the bedroom . the person issnugglingwithablanketand is playing with the blanket;
(3)10倍斜率描述:a person is standing in the doorway of the bedroomholdingablanket. the person puts the blanket on the bed and begins undressing;
(4)15倍斜率描述:a person is standing in the living roomholdingablanket. the person throws the blanket onto the floor and then begins snuggling with a blanket;
(5)真值描述:a personholdsherblanketand walks into the room while holding her phone . she puts the phone down but keeps standing holding the blanket.
调整遗忘曲线斜率后的描述语句中,单词数量均多于基线描述,且基线错误描述为“undressing”,调整后算法能正确描述“holding a blanket”等更贴合视频内容的单词。由此可知改变遗忘曲线的斜率可影响视频描述的结果。
2 实验结果分析
2.1 实验设计
使用一张NVIDIA GeForce 1080Ti显卡,在Ubuntu16.04环境基础上,应用PyTorch深度学习框架进行训练和测试。模型的编码器和解码器层数均为3,输入视频特征维度为512,经过编码器生成视频段落描述,视频特征序列被动态视频记忆模块依次读取,输送到解码器的多头注意力模块中,经过解码器得到最终输出。多头注意力中注意头数设为8,隐藏层尺寸为d=512。在训练阶段使用的batch size为25,测试阶段batch size为100,学习率为1,epoch设为50。选用Charades[14]数据集进行仿真,数据集中视频大约为30 s,将7 473个视频用于训练,1 760个视频用于验证和测试。
2.2 性能指标
为评估视频描述结果的准确性和多样性,使用BLEU@4[15]、METEOR[16]和CIDEr[17]三个指标评估描述准确性,使用Div@n[18]和Rep@n[19]两种指标评估描述多样性。
在准确性的评估指标中,BLEU@4计算描述文本由4个单词构成短语的准确率,且可衡量句子的流畅性,计算公式为
(7)
式中:lc为模型生成描述语句的长度;ls为真值描述的语句长度;Pn为n-gram的精度,在BLEU@4中,n=4。CIDEr是BLEU和向量空间的结合,得出候选句子和参考句子的相似度,对描述语句的准确性起主要的评估作用,计算公式为
(8)
式中:m为用作对比的真值描述语句的数量;gn为每个n-gram与真值描述的相似度;qn为每个n-gram与候选描述的相似度。
METEOR用外部知识源扩充同义词集,同时考虑单词的词性评价句子流畅性,但METEOR测试结果为整个测试集的指标,不能进行单个语句测试,计算公式为
(9)
式中:pen为描述语句中单词顺序的惩罚概率;P为候选文本的准确率;R为候选文本的召回率;α为[0,1]之间的参数,在多样性评估指标中,Div@n衡量生成单词的丰富度,重复词越少,文本越丰富。n为评估时单词的个数,进行段落描述时计算公式为
(10)
式中:hn为描述语句中n元词语的个数;hsum为真值描述语句中n元词语的总个数。
除采用Div@n指标评估描述文本n元词语多样性,同时用重复率指标Rep@n作多样性评价,计算公式为
(11)
式中,hk为生成的文本描述中n元词语出现的次数。
本文设计兼顾准确性和多样性的均衡指标,最终指标计算公式为
w62e-ri}]。
(12)
式中:aim为六个指标(准确性:BLEU@4、METEOR和CIDEr;多样性:Div@1、Div@2、和Rep@4)经过处理后的最终结果;w为各指标的权重;i为模型的个数;N为六个指标中比基线高的指标个数。
考虑对比的便捷性和可靠性,使各个指标相加和为1,根据各指标的定义作为权重w的选取依据。由于BLEU@4、METEOR、CIDEr和Div@n是指标越高性能越好,则使用Log函数将指标范围控制在[0,1]区间内;Rep@n指标越低性能越好,使用e-ri函数将指标范围控制在[0,1]。进行六个指标的权重分配时,准确性和多样性的性能指标均占50%,保证最终评估分数准确性和多样性的均衡性。
为解决六个指标部分指标提升过多导致总体分数高,不能对多样性和准确性六个指标进行兼顾的问题,在归一化基础上乘以比基线高的指标个数N,其中N∈[0,6],解决了单一或小部分指标过高影响最终结果的问题,最后本文利用兼顾准确性和多样性的均衡指标aim评估网络模型,其中aim∈[0,6]。该指标在对比视频描述结果时减少了对比指标的个数,提高对比便捷性。
2.3 仿真分析

图4 缩小斜率曲线的仿真结果对比
改变遗忘度会影响文本描述结果,遗忘度曲线斜率倍数小于10-8倍时,评价指标趋于稳定,基本无变化。过于减小遗忘度曲线斜率对远距离的单词遗忘率低,而不能增强对当前单词的关注度,导致整体性能降低。放大斜率曲线的仿真结果对比如图5。
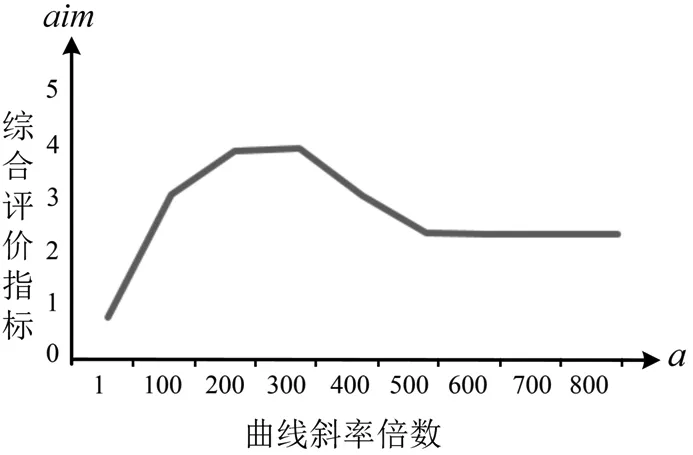
图5 放大斜率曲线的仿真结果对比
当遗忘度曲线斜率倍数大于1时,视频描述性能显著提高。当遗忘曲线斜率倍数大于600倍时,评价指标趋于稳定,在过于增大遗忘度曲线斜率时,虽对近距离单词关注度增强,但文本向量中临近单词的衰减率变化较快,导致注意力机制不能充分利用视频文本特征,影响视频描述结果。
遗忘度曲线斜率倍数在[10-8,600]区间内描述性能较好。为验证此结论,从遗忘度曲线相对斜率为1开始,按5的倍数依次增加,适当调整遗忘度曲线可以对注意力机制中段落描述中单词的遗忘度进行优化,最终提高视频描述效果。细分斜率曲线的仿真结果对比如图6。
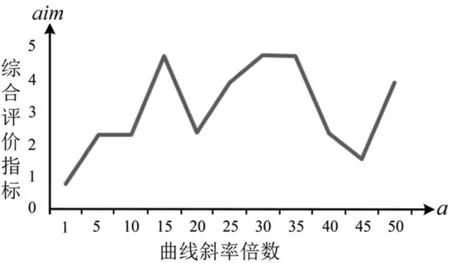
图6 细分斜率曲线的仿真结果对比
2.4 算法对比
为验证单词级遗忘度优化算法的提升效果,选用调整后的遗忘度与原始网络TDPC算法进行对比,结果见表2。

表2 密集视频描述算法对比
通过调整单词级遗忘度,可以优化注意力机制,增强段落描述中部分单词的关注度,提高视频描述的准确性和多样性。视频案例可视化结果如图7~图9。

图7 视频案例1
对图7中的视频案例进行描述如下:
(1)基线描述:a person is standing in the bathroom holding a glass of water . the personputstheglassdownand looks at themselves in the mirror;
(2)遗忘度优化:a person is standing in the bathroom holding a mirror and looking at themselves in the mirror .
the person then walks to the sink andwashestheirhands;
(3)真值描述:a person adjusts a bathroom mirror , then puts a book next to a toilet . finally the personwashestheirhandsin the sink.
对图8中的视频案例进行描述如下:
(1)基线描述:a person is walking through the hallway with a blanket wrapped around them . the person puts the blanket on the floor andleaves;
(2)遗忘度优化:a person is standing in the doorway of the entryway grasping a towel . the person puts the towel on the table and beginsdressing;
(3)真值描述:a person is tidying their wardrobe . they then pick up a garment from a chair anddressthemselves with it.

图8 视频案例2
对图9中的视频案例进行描述如下:
(1)基线描述:a person is drinking a glass of water . the person thenwashestheirhandsin the sink;
(2)遗忘度优化:a person is drinking a cup of coffee while standing in front of a sink . the person thenpourssomewaterinto a glass and takes a drink;
(3)真值描述:a person in the bathroom drinks from a cup of water . the person thenpoursthe rest of it in the sink and then sets the cup next to the faucet.

图9 视频案例3
图7视频中的正确描述有“washes hands”(洗手),基线TDPC算法没有准确描述这一动作,但通过调整遗忘度之后,本文可以描述出“washes hands”这一事件,且增加“walks to the sink”(走向水池)等细节事件描述,提高了描述的准确性和多样性;图8视频中正确描述有“dress”(穿),基线TDPC算法没有描述出这一细节,但通过调整遗忘度之后,可以准确描述出“dressing”;图9视频正确描述应有“pours”(倒),基线TDPC描述成“washes”(洗),与原视频表达内容有偏差,但遗忘度调整后,正确描述出“pours”。对比原始TDPC算法描述结果,采用单词级遗忘度优化算法,调整单词级遗忘度后,对视频描述结果的准确性和多样性提升效果明显。
3 结 语
本文针对密集视频描述文本生成过程中,由于部分单词错误和缺失造成语义错误的问题,提出一种单词级遗忘度优化算法(WFO)。通过对描述文本中每个单词的遗忘度进行调整,模型自动感知文本向量中重要程度不同的单词,提升视频描述性能。与TDPC相比,本文方法增强了文本描述性能效果,适用于密集视频描述和视频关键内容检索等领域。在未来工作中,将进一步优化文本生成策略,提升视频描述的多样性和准确性。
