零担货物快递服务公司自动匹配研究
2022-07-16阮永娇孙承臻陈娅鑫
阮永娇,陈 昕,孙承臻,陈娅鑫
零担货物快递服务公司自动匹配研究
阮永娇,陈 昕,孙承臻,陈娅鑫
(辽宁工业大学 汽车与交通工程学院,辽宁 锦州 121001)
研究零担货物快递服务公司自动匹配,研究SVM自动匹配方法,依据零担货物快递服务需求自动匹配出最适合的快递公司,研究方法是基于机器学习,借助已有的人工匹配数据构建的数据集,通过python编程,用训练集训练零担货物快递服务公司自动匹配的机器学习模型,验证集验证自动匹配效果。验证集评估结果表明,SVM自动匹配方法,根据零担需求进行快递服务公司的自动匹配,匹配时间仅为1.89 s,精度达到0.90,自动匹配方法能够高效恰当地为零担需求匹配出适合的快递公司,使得零担货物快递的供需双方高度契合。本文研究可以帮助物流服务公司节约匹配成本,提高匹配效率,增强公司竞争力,同时为机器学习中SVM的应用提供思路和参考依据。
零担货物快递;快递需求;快递公司;自动匹配;SVM
1 零担货运的人工匹配数据分析
在零担货物快递时,需要根据货物自身的特点对众多快递公司的快递价格,平均服务水平和服务范围等多个因素进行考察,匹配出最适合零担货物的快递公司提供快递服务。目前零担货物快递需求与快递公司的匹配主要由人工完成。表1是某公司零担货物快递服务信息的原始数据表。
表1 原始数据表
编号发货省份配送时效发货数量发货品种数出库包裹数称重重量快递公司 0海南省正常送达2211.41韵达快递 1吉林省正常送达1114.043重货-吉林黄马甲 2湖南省正常送达2111.511韵达快递 3上海正常送达2111.41韵达快递 4天津次日达8118.095晟邦-快消 5广东省正常送达8119.56韵达快递 ······································· 10490山西省次日达4311.051建华快递 10491广东省正常送达12413.499韵达快递 10492辽宁省正常送达3114.051重货-辽宁黄马甲 10493北京当日达2210.884万象-自营 10494黑龙江省正常送达1110.32EMS-落地配 10495福建省正常送达4111.577韵达快递 ······································· 20981广东省正常送达1110.57韵达快递 20982北京次日达3110.46韵达快递 20983贵州省正常送达4212.737韵达快递 20984江苏省正常送达2211.43韵达快递 20985黑龙江省正常送达3110.47EMS-落地配 ······················································ 41959湖北省正常送达4210.776韵达快递 41960天津次日达4212.737晟邦-快消 41961山东省正常送达4411.52山东递速 41962北京次日达1114.77万象-自营 41963河北省正常送达1114.468万象-自营 ······················································
原始数据表中,每一条零担货物快递需求对应1条人工匹配记录,8列数据字段中,第1列是数据样本编号、发货省份、发货数量、发货品种数,出库包裹数和称重重量6列数据字段表示零担货运的6个特征数据,其中发货省份代表该零担货物要求发往的省份;配送时效代表货物要求配送的时间包括当日达、次日达和正常送达3种不同的要求;发货数量代表零担货物的发货数量;发货品种数代表零担货运中所发货物的品种数;出库包裹数代表货物打包完成后的包裹数量;称重重量代表包裹的最终称重的重量,单位是kg。最后一列“快递公司”,是根据快递需求,人工匹配的快递公司的匹配结果,包含EMS-落地配、晟邦快消、建华快递、山东递速、万象-自营、韵达快递、重货-吉林黄马甲、重货-辽宁黄马甲8家公司,分析表1数据可知,EMS-落地配服务水平较高,服务范围较广,成本低,但速度相对较慢;晟邦快消和建华快递运送效率高,但发货前等待时间较长;山东递速、重货-吉林黄马甲和重货-辽宁黄马甲运送范围小,集散过程少;万象-自营运送时间短,范围广,但成本较高;韵达快递服务范围较广,成本低,但速度相对较慢且服务水平相对较低。
人工匹配快递公司的方法,是人工从可供选择的公司中匹配出适合的快递公司,在满足零担货物快递需求的前提下,根据公司特点结合零担货物的6项特征值,对各个快递公司的费用、服务水平、服务范围进行比较,筛选出相对比较适合的快递公司,完成零担需求与快递公司的匹配。
但是随着经济的发展,零担快递需求数量和快递公司数量不断增大,这使得人工匹配的工作量增加,匹配时间加长,从而导致匹配工作效率下降、匹配的准确率下降,所以急需自动匹配方法。
2 机器学习SVM自动匹配方法
2.1 机器学习方法分析
机器学习主要研究如何借助已有的数据,学习人类的学习行为。应用最广的机器学习方法有线性模型、决策树、神经网络、贝叶斯分类器、聚类、支持向量机等[1]。线性模型适用于具有线性相关性的相关问题[2];决策树适合于多目标逐一分层讨论问题;神经网络适合各因素间相互影响的分类问题,同时由于激活函数的特性多用于二分类问题;贝叶斯分类器使用范围较广但准确率较低,聚类用于求解分类问题的聚类中心[3]。
支持向量机(support vector machine,SVM)适合于线性非线性的选择分类问题,是机器学习中的一个重要模型,广泛应用于数据分析、模式识别和数据挖掘等多个领域,并能够推广应用到函数拟合等其他机器学习问题中[4]。
2.2 SVM自动匹配方法
快递公司自动匹配问题,可供匹配选择的快递公司有多个,已经不是简单的二分类问题,同时影响匹配结果的特征共有6个,这6个因素随机分布,且彼此之间相互影响较低或者彼此互不影响。SVM方法在解决小样本、非线性及高维的分类问题时具有优势,SVM模型分类效果好,可以有效处理高维空间数据。因此,本文采用SVM方法研究快递公司自动匹配。其具体算法如下:
Step1:将A公司已有的人工匹配数据计划分为训练集(X1,Y1)和测试集(X2,Y2)。
Step2:选取核函数(x,y),构造相应的凸二次规划问题:
为明确各试样调制系数随电压的增长速率,对特定激励超声频率的各阶模态调制系数曲线进行一元线性回归分析,即根据若干实测点确定调制系数y与低频电压x的关系,回归函数记为
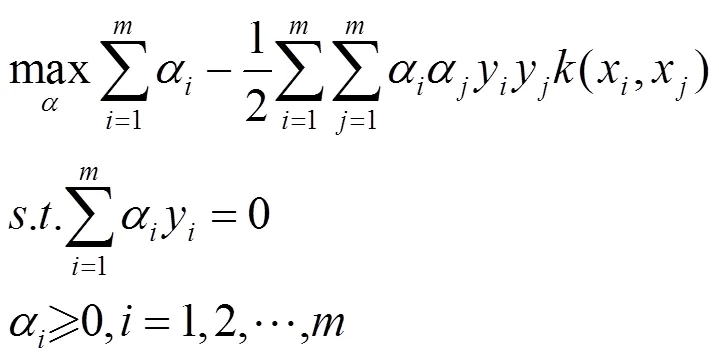

Step5:得到支持向量机模型:

SVM机器学习算法训练流程如图1所示。
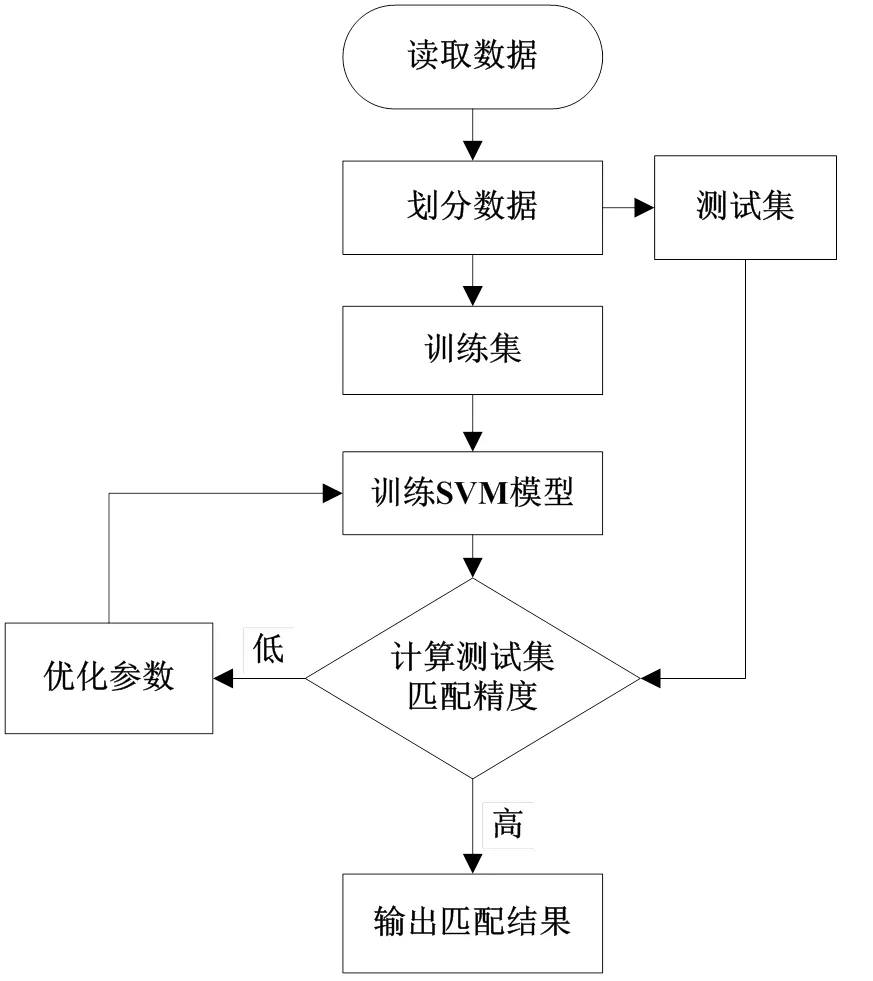
图1 算法训练流程
3 自动匹配python实现
自动匹配python实现,是根据A公司零担货物快递服务信息的原始数据表,借助已有的人工匹配数据构建SVM模型学习的数据集,利用留出法将数据集划分成互斥的训练集的和测试集,然后通过训练集训练SVM模型,利用测试集对自动匹配模型进行评估。
3.1 数据集独热编码
数据集中,发货省份和配送时效2个属性只需要用不同数字进行区分,不同省份的数字之间没有大小关系,需要进行独热编码处理,独热编码是借助不同的数字表示离散属性的不同表现状态。利用独热编码处理数据时,处理后的离散属性没有大小的含义,只是代表了一种属性表现形式。利用python编程将数据集中发货省份和配送时效2个属性进行独热编码处理,独热编码具体结果如表2、表3所示。
表2 发货省份独热编码表
原数据集属性值独热编码值 山西省0 西藏自治区1 重庆2 陕西省3 新疆维吾尔自治区4 吉林省5 四川省6 广东省7 辽宁省8 青海省9 北京10 河北省11 天津12 湖北省13 浙江省14 贵州省15 云南省16 福建省17 宁夏回族自治区18 广西壮族自治区19 上海20 内蒙古自治区21 安徽省22 山东省23 江西省24 海南省25 河南省26 江苏省27 湖南省28 黑龙江省29 甘肃省30
表3 配送时效独热编码表
原数据集属性值独热编码值 当日达0 次日达1 正常送达2
3.2 训练集与测试集的划分
在进行机器学习模型训练时,需要将数据集划分为互斥的训练集与测试集,为了更好地检测匹配模型的泛化能力,本文采用留出法进行数据集划分,将数据集划分为2个互斥的组合,其中一个作为训练集,一个作为测试集。训练集对模型进行训练,测试集用来对模型进行评估,划分结果如表4、表5所示,其中表4为训练集,大小为33 570×6,表5为测试集,大小为8 393×6。
表4 训练集数据表
训练集编号原数据集编号发货省份配送时效发货数量发货品种数出库包裹数称重重量 001202211.41 111401114.043 22902111.511 34718118.095 452208119.56 ························ 1539719200712118.593 15398192011403110.47 15399192021103212.107 1540019203713110.51 15401192062702115.575 ························ 33566419575021226.568 33566419581504210.776 33567419602704411.52 33568419611911114.77 33569419622801114.468
表5 测试集数据表
训练集编号原数据集编号发货省份配送时效发货数量发货品种数出库包裹数称重重量 031102111.41 18712217.474 210714312.83 3191914114.362 4239012512.894 ························ 4058200881102210.876 4059200931402112.422 4060201021401114.653 4061201032801111.189 4062201122201110.74 ····················· 8388419372911110.335 8389419422202111.423 8390419451911110.78 8391419482701117.22 839241959714212.737
3.3 自动匹配模型训练
用训练集数据进行SVM的训练,借助python编程,从sklearn工具库中直接调用SVM函数进行训练[5]。基于每个样本中包含发货省份,发货数量,发货品种数,出库包裹数和称重重量工6项特征值,选用高斯核即核函数(kernel)为rbf,选用停止训练的误差大小(tol)为0.001,最大迭代次数(max_iter)为-1,可以使得在训练时只要误差大于0.001模型就会进行优化,且不限制优化次数,直至训练的误差小于0.001,程序代码与运行结果如表6所示。
3.4 自动匹配模型评估
通过python编程,针对最终模型通过测试集数据进行评估,机器学习自动匹配模型对测试集8 393条数据进行匹配时所用时间为1.97 s。人工匹配,人查看需求,选快递公司,点击鼠标,最快按1 s一条数据计算人工匹配所需时间,最少需要8 393 s,自动匹配所用时间远远小于人工匹配的所用时间,并且8 393条数据中,自动匹配的正确匹配的数据有7 548条匹配正确,自动匹配的精度可达到0.90。
表1数据是公司1周的人工匹配数据,有41 964条快递需求,可供选择的快递公司有8家,平均1天需要进行匹配的零担需求大约为7 000条,工作人员一天需要进行的查看次数为3.36×105,人工匹配耗费大量的人力资源和物质资源,且匹配时间长,效率低下。采用自动匹配方法,可以实现匹配用时少,匹配效率高,从而实现匹配成本降低。
表6 程序代码与运行结果
代码运行结果 #支持向量机import pandas as pdimport numpy as npfrom sklearn import svmfrom sklearn.model_selection import train_test_splitx=data.iloc[:,0:6]y=data.iloc[:,6]x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 1 , train_size = 0.8 )ajiao=svm.SVC()ajiao.fit(x_train, y_train.ravel())SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',max_iter=-1, probability=False, random_state=None, shrinking=True,tol=0.001, verbose=False)
表7 8393条数据自动匹配与人工匹配对比表
匹配方式匹配正确记录匹配时间匹配精度匹配用时匹配效率匹配成本 人工匹配83938393s1.00多低高 自动匹配75481.97s0.90少高低
4 结束语
本文研究零担货物快递公司的机器学习SVM自动匹配方法,以某公司零担货物快公司人工匹配信息构建数据集,采用SVM机器学习模型方法进行快递公司自动匹配,并用python编程实现零担货物快递需求与快递公司的自动匹配。本文研究表明SVM自动匹配所用时间,远远小于人工匹配所需的时间,匹配精度达到0.90,自动匹配方法可有效提高快递公司匹配效率,降低匹配成本,能有效提高公司竞争力。
[1] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016. 121-139
[2] 张良均, 谭丽云, 刘明军, 等. Python数据分析与挖掘实战[M]. 2版. 北京: 机械工业出版社, 2020: 59-62
[3] David Forsyth. Applied Machine Learning[M].Springer Nature Switzerland AG, 2019: 14-20
[4] 莫凡. 机器学习算法的数学解析与Python实现[M]. 北京: 机械工业出版社, 2020: 146-153.
[5] Wes McKinney著, 徐敬一译. 利用Python进行数据分析[M]. 2版. 北京: 机械工业出版社, 2018: 377-380.
Research on Automatic Matching of LCL Express Service Company
RUAN Yong-jiao, CHEN Xin, SUN Cheng-zhen, CHEN Ya-xin
(School of Automobile and Traffic Engineering, Liaoning University of Technology, Jinzhou 121001, China)
Automatic matching of LCL express service company and the SVM automatic matching method are researched. The purpose is to automatically match the most suitable express company according to the service demand of LCL Express. The research method is based on machine learning. with the help of the existing artificial matching data to build the data set. Through python programming, the training set is used to train the machine learning model of the automatic matching of the LCL express service company, and the verification set is used to verify the automatic matching effect. The evaluation results of the verification set show that the automatic matching time of express service company based on the LCL demand is only 1.89 s, and the matching accuracy reaches 0.90. The automatic matching model can efficiently and appropriately match the express service company for the LCL demand. The supply and demand of LCL Express service are suitable. This study can help logistics service companies to save matching costs, improve matching efficiency, and enhance their competitiveness. Meanwhile, it can provide ideas and reference for machine learning application in the era of artificial intelligence.
LCL express; express requirements; express service company; automatic matching; SVM
10.15916/j.issn1674-3261.2022.03.003
U16
A
1674-3261(2022)03-0151-05
2021-06-27
辽宁省先进装备制造业基地建设工程中心项目(LNTH2020122E);辽宁工业大学研究生教育改革创新项目经费资助(YJG2021003)
阮永娇(1997-),女,山东临沂人,硕士生
陈 昕(1972-),女,辽宁铁岭人,教授,博士。
责任编辑:陈 明
