融合弱监督目标定位的细粒度小样本学习
2022-07-15贺小箭林金福
贺小箭,林金福
华南理工大学计算机科学与工程学院,广州 510006
0 引 言
近年来,深度卷积神经网络(convolutional neural network,CNN)在图像识别任务上取得了巨大进步。通过大量的标注数据,CNN可以获得丰富的图像表征,从而提升下游任务(识别、分类等)性能。但当训练样本很有限时,深度卷积神经网络通常会遇到过拟合和泛化性能差等问题。而人却可以仅从一幅或几幅图像中学习到全新的类别,例如一个孩子在看过一幅或几幅猫的图像后,便可以形成“猫”的概念。小样本学习的任务就是从少量的数据中学习如何识别全新的类别。
进一步地,细粒度图像识别旨在对属于相同类别的不同子类的图像进行分类,例如各种鸟类、各种狗类和各种汽车的识别。区分一个子类与另一子类的特征通常是细微的和局部的,这使得细粒度图像分类比常规图像分类更具挑战性。因此大多数现有的细粒度分类方法需要大量的训练数据来学习一个更鲁棒性的分类器。但是由于标注细粒度图像需要专业知识,例如标注各种鸟类可能需要求助鸟类学家等,而且许多细粒度方法还需要有边界框标注等。这些都给细粒度图像标注带来巨大成本。此外,许多濒临灭绝和稀有物种的图像很难收集。因此在数据量极其有限的情况下识别出细粒度图像是一个极具实际应用价值的问题,但是这方面的深入研究目前还很少。
小样本学习正是用来解决数据量有限情况下图像分类的一种技术。许多小样本学习方法主要关注于学习图像的全局表征,在常规的小样本分类任务上取得了不错的性能,但是却无法很好处理细粒度的小样本分类任务,可能是因为全局的表征无法捕获细粒度图像分类所需的局部的和细微的特征。此外,许多细粒度图像分类方法严重依赖于大量的标注数据,例如边界框标注和目标部位标注等细粒度级别的标注。在小样本的场景下,基本没有提供细粒度的标注,导致这些细粒度分类方法同样无法直接使用。因此,提出一种可以同时处理常规小样本学习和细粒度小样本学习的方法具有重要意义。
已有工作表明,通过目标定位可以提高常规图像的分类性能(Oquab等,2015;Wei等,2017,2018)。受此启发,本文认为通过弱监督目标定位获得图像的区分性区域,对于常规的小样本分类和细粒度的小样本分类都会有帮助。因为目标定位直接提供了最具区分性区域的特征。弱监督目标定位旨在仅通过图像标签级别的标注实现目标定位。但是现有的许多弱监督目标定位的方法无法完整地定位目标。例如,CAM(class activation map)(Zhou等,2016)用全局最大池化和全连接层代替分类网络的最后几层获得类激活图。但CAM仅关注那些最有利于分类性能提升的区域而不是整体,无法直接用于细粒度小样本学习。为了弥补这一缺点,本文提出一个基于自注意力的互补定位模块(self-attention based complementary module,SACM)。如图1所示,所提出的模块是轻量级的,主要包括显著性掩膜生成模块和分类器模块。显著性掩膜生成模块基于通道自注意力,为输入的特征图产生显著性掩膜,与其互补的非显著性掩膜通过设定的阈值产生。显著性掩膜对应图像最具区分性区域,互补的非显著性掩膜对应擦除最具区分性区域。显著性掩膜和互补非显著性掩膜彼此作用于特征图,得到显著性特征图和互补非显著性特征图。分类器通过将这两个互补的特征图分到同一类来捕获更多有利于分类的特征,从而产生更加完整的类激活图。图中全局平均池化(global average pooling,GAP),本文提出的SACM模块不需要训练多个分类器,也不需要额外的步骤产生类激活图且轻量级可以应用于许多网络。

图1 自注意力互补定位模块结构Fig.1 The structure of self-attention complementary module
许多小样本学习方法(Snell等,2017;Vinyals等,2016;Hariharan和Girshick,2017)通过求图像全局特征(单一高维向量)的平均值获得图像对应类别的原型,进而利用欧氏距离或余弦距离进行最近邻分类。这种方法尽管高效,但容易受到噪声影响。而且这种基于全局表征的度量方式也不适用于细粒度图像分类。为了解决这个问题,本文提出特征描述子表示与语义对齐距离。特征描述子表示假设每个特征描述子是独立的,用筛选得到特征描述子集合作为图像的表征。相比使用一个高维向量作为表征,特征描述子表示更加细粒度,能更好地捕获和利用图像丰富的局部特征,因此特征描述子表示是一种表达能力更强的数据表征。此外,为了适应特征描述子表示,受朴素贝叶斯最近邻(naive Bayes nearest neighbor,NBNN)(Boiman等,2008)和DN4(deep nearest neighbor neural network)(Li等,2019a)的启发,提出了一种语义对齐距离来度量两个特征描述子表示的相似度。由于特征描述子表示是根据图像的类激活图信息筛选得到的,对应着图像语义的最相关部分,因此提出的语义对齐距离可以直接度量两个图像最具区分性区域的相似度。与DN4不同,本文利用弱监督目标定位信息对图像的特征描述子集合进行筛选,在保留目标语义信息的同时,抑制了背景噪声,而且筛选可以进一步减少特征描述子个数,一定程度上提高了NBNN的执行效率。本文提出的融合弱监督目标定位的细粒度小样本学习方法是一个二阶段网络,融合了弱监督目标定位网络和小样本图像分类网络。
本文的主要贡献包括:1)提出一个轻量级的弱监督目标定位模块SACM,利用通道自注意力,通过擦除互补的方式获得更完整的类激活图,可以很容易地应用到许多现有的分类网络。2)基于特征描述子表示,设计了一种语义对齐距离来提升细粒度小样本分类的性能。基于筛选的特征描述子表示,提出的语义对齐距离可以对齐两幅图像之间的内容。3)进行了大量的性能分析实验。提出的方法在小样本数据集和细粒度小样本数据集上都取得了有竞争性的性能。泛化性实验也进一步验证了提出方法可以同时很好地解决小样本学习和细粒度小样本学习任务。此外,可视化也证实了提出的模块可以更加完整地实现弱监督目标定位。
1 相关工作
1.1 元学习和度量学习
小样本学习方法主要包括基于元学习的方法和基于度量学习的方法。基于元学习的方法利用元学习范式,Santoro等人(2016)训练一个跨任务元学习器,可以快速准确地更新模型中的参数。Finn等人(2017)训练了一个与模型无关的元学习器,并找到适应各种具有相似分布任务的初始参数,通过设置学习得到的初始化参数以及对应的参数更新方式,只需很少的训练样本就可以快速推广到新任务。Ravi和Larochelle(2017)提出一种基于长短期记忆网络(long short-term memory,LSTM)的元学习模型,学习分类器参数的更新规则和分类器参数的一般初始化。此外,参数生成方法(Qiao等,2018;Lifchitz等,2019;Gidaris和Komodakis,2018)学习直接生成分类器的权重,而不是学习如何更新网络的参数。该类方法的本质是利用卷积神经网络最后一层的激活输出和全连接层的分类权重在分布上的相似性直接预测分类权重。基于度量学习的方法是一种通过学习嵌入函数来度量查询图像和支持图像之间相似性的分类方法。在测试期间,使用最近邻方法对嵌入空间中的新类别进行分类,其中相同类别的样本比不同类别的样本距离更近。结合注意机制,匹配网络(Vinyals等,2016)使用余弦距离在嵌入空间训练一个K邻居分类器,并设计插曲(episode)训练模式,使训练阶段更加贴近测试阶段。Snell等人(2017)提出一个原型网络(prototypical networks,Proto-Net)学习每个类别的原型,并通过计算查询图像与原型在嵌入空间的欧氏距离进行分类。与匹配网络和原型网络手动选择固定度量(例如余弦和欧氏距离)不同,关系网络(relation net)(Sung等,2018)使用非线性比较器进行学习,直接比较查询图像与支持图像在嵌入空间之间的度量距离,通过网络直接给出两个图像之间的相似度分数来判断图像的类别。
上述度量方法均采用嵌入空间中的单一高维特征表示每个类别,进而利用欧氏距离或余弦相似度进行图像分类。与这些方法不同,本文采用特征描述子表示来表征一个类别。同时,基于特征描述子表示和NBNN算法,设计了一种语义对齐距离来更好地度量两个细粒度图像之间的距离。
1.2 细粒度图像分类
细粒度图像分类面临着子类别之间差异微小而类内图像差异巨大的问题。目前的主流方法(冯语姗和王子磊,2016;翁雨辰 等,2017;Wei等,2018;Sun等,2021;Fu等,2017)是先定位出细粒度图像中最具区分性的区域,再利用得到的局部特征进行分类。Mask-CNN(Wei等,2018)借助全卷积网络(fully convolutional network,FCN)(Long等,2015)学习一个部位分割模型,为后续细粒度分类网络提供头部和躯干等局部特征,实现细粒度分类。MA-CNN (multi-attention CNN) (Zheng等,2017)通过交叉训练channel grouping 和part classification两个子网络来更好地学习细粒度的特征。channel grouping网络基于特征图通道,利用聚类、加权和池化生成多个部位信息。part classification网络则对channel grouping 网络生成的部位进行分类,使网络学习到更多细粒度特征。针对现有细粒度方法中区域检测和细粒度特征学习彼此对立的情况,Fu等人(2017)提出多尺度循环注意力卷积网络,通过相互强化的方式,对判别区域注意力和基于区域的特征表征进行递归学习。多尺度网络通过交替训练的方式,不断聚焦关键区域,同时不断提高细粒度特征分类的性能。相似地,本文方法遵循两阶段网络的方式,先训练得到一个弱监督目标定位网络,再训练细粒度图像分类网络。不同于常规细粒度图像分类的训练方式,本文提出的细粒度小样本分类网络采用插曲训练机制进行训练。
1.3 弱监督目标定位
弱监督目标定位(weakly-supervised object localization,WSOL)是一种仅使用标签级别标注来实现目标定位的技术。CAM(Zhou等,2016)将分类网络最后几层替换为全局平均池化和全连接层,通过加权融合最后一个卷积层的特征图得到类激活图。但是CAM严重依赖目标的某些特征,导致CAM方法只能定位目标的一部分区域。为了解决CAM过度依赖某些显著性的特征,Zhang等人(2018a)提出基于对抗擦除学习(adversarial complementary learning,Acol)的方法,利用额外的分类器对擦除后的特征分类,使网络学习更多有利于分类的特征。通过融合多个分类器的结果,Acol能得到完整的类激活图,但存在训练多个分类器的缺点,对此,Choe和Shim(2019)提出ADL(attention-based dropout layer)对特征图最具区分性的区域进行擦除,使网络可以学习更多有利于图像分类的特征,但需要额外步骤获得类激活图。与擦除方式不同,Zhang等人(2018b)通过生成引导掩膜,将图像分为背景、前景和不确定区域,向分类网络提供像素辅助监督,利用分阶段的方法,逐步精细化前景区域,进而得到更加精确的定位信息。本文提出的自注意力互补定位模块,利用擦除方式获得更多关键特征,实现了完整的目标定位。本文设计了一个全新的显著性掩膜生成模块来更加准确地获取特征图的显著性区域,无需依赖额外的分类器和额外的向后反馈。
2 细粒度小样本分类方法
融合弱监督目标定位的细粒度小样本分类方法如图2所示,其中w、h和d分别为特征图的宽度、高度和深度。该方法的具体步骤为:1)训练WSOL网络,采用SACM组合VGG16(Visual Geometry Group 16 layer)的卷积层得到WSOL网络并进行训练。2)利用Conv64或ResNet12(residual network)作为特征提取网络获得特征图。3)使用WSOL网络生成的类激活图进行特征描述子筛选。4)将选定的特征描述子馈送到SAM模块以计算语义对齐距离,并实现细粒度小样本图像的分类。
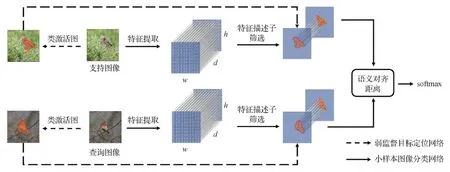
图2 融合弱监督目标定位的细粒度小样本图像分类流程图Fig.2 Flow chart of fine-grained few-shot image classification based on weakly-supervised object localization
2.1 显著性掩膜生成模块
本文提出的自注意力互补定位模块采用擦除方式获得更多的有用的分类特征,产生更加完整的类激活图。为了更加精确地获得显著性区域,设计了一个显著性掩膜生成模块,基于特征图的通道自注意力机制,为特征图生成显著性掩膜。同时通过阈值获得一个互补的非显著性掩膜。特征图先通过全局最大池化、全局平均池化和1×1卷积操作,然后串联3个操作的输出,利用1×1卷积和sigmoid函数得到显著性掩膜。本文的显著性掩膜生成模块的结构图如图3所示。其中,C、W和H分别为特征图的通道数,宽度和高度。
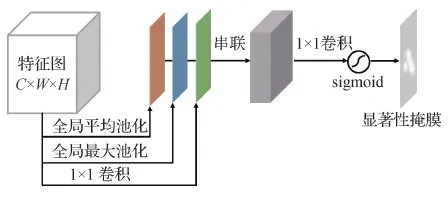
图3 显著性掩膜生成模块Fig.3 Saliency mask generation module
2.2 分类器模块
CAM需要额外的梯度回传步骤来获得类激活图。与此不同,Acol提出了一个新的方式从卷积层中直接获取类激活图。假设训练阶段有C个类别,最后的一层为1×1卷积。假设1×1卷积层的输入特征图为Sk,卷积核的参数为W1×1∈RK×C,K为通道数。直接由卷积层获得类激活图的公式为
(1)
基于Acol中的类激活图产生方法,本文的分类器结构如图4所示。分类器由分类器卷积层、全局平均池化和softmax函数组成。其中,分类器卷积层包括3个3×3的卷积块和1个1×1的卷积块。每个3×3卷积块包含1 024个大小为3×3的卷积核,1×1的卷积块包含1 024个大小为1×1的卷积核。本文方法的类激活图是基于1×1的卷积层得到的。

图4 分类器结构图和产生类激活图的过程图Fig.4 Classifier structure diagram and process diagram for generating class activation map
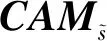
(2)
式中,max操作具体为对于输入的两个大小相同的矩阵,输出矩阵每个位置的元素为两个输入矩阵在对应位置的最大值。
2.3 特征描述子
给定图像X,通过小样本图像特征提取网络(Conv64或ResNet12)输出一个对应的特征图,特征图是一个3维张量,记为E(X)=Rd×w×h。一方面,E(X) 包含d个大小为w×h的特征图;另一方面,E(X)=Rd×w×h也可看成包含了m=w×h个特征描述子,每个特征描述子都是一个维度为d的向量,本文假设每个特征描述子都是独立的。因此,卷积层的输出也可以记为
E(X)={d(1,1),d(1,2),d(1,3),…,d(i,j),…,d(w,h)}=
{d1,d2,d3,…,dm}
(3)
式中,d(i,j)表示该特征描述子在特征图中位于坐标(i,j)的位置。相比于全局表征,利用特征描述子集合表示特征图能捕获更多局部特征信息,更适合于细粒度图像分类。
2.4 特征描述子筛选
利用训练好的WSOL网络获取图像的类激活图,对图像进行特征描述子筛选,得到图像的特征描述子表示。其过程为:1)图像的类激活图按设定的阈值(类激活图的均值)进行二值化,得到二值化类激活掩膜。2)二值化激活掩膜通过最近邻插值,得到尺寸为w×h的筛选掩膜。3)将图像的筛选掩膜作用于特征图,去除所有零向量,得到的特征描述子集合便是图像的特征描述子表示。记为
E(X)={d1,d2,d3,…,dn}
(4)
式中,n表示筛选后剩下的特征描述子的数量。通过筛选,可以去掉背景相关的特征描述子,减少背景噪声影响。同时,保留的特征描述子对应图像内容最具区分性区域的语义。
2.5 语义对齐模块
语义对齐模块(semantic alignment module,SAM)用于计算两个图像最具区分性区域的相关性。基于朴素贝叶斯最近邻分类器的启发,本文假设特征描述子表示E(X)={d1,d2,d3,…,dn}中每个特征描述子都是独立的。特征描述子独立性假设可以利用卷积神经网络的平移不变性。例如,目标平移后其响应的位置发生改变,但是对应的特征描述子表示变化不大。然而使用单个高维向量表示,其对应的维度信息便会改变,这不利于表征的稳定性。针对细粒度图像识别,基于图像的特征描述子表示,本文提出了一种新的度量方式,称为语义对齐距离。其计算过程为
(5)
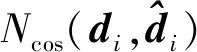
(6)
通过累加查询图像的特征描述子表示中所有的特征描述子的最近邻余弦距离,得到查询图像到支持图像的语义对齐距离D(qk,sk)。
基于特征描述子的独立性假设,查询图中每个特征描述子通过最近邻余弦距离,都能在支持图像中搜索到与之匹配的特征描述子。这保证了查询图像与支持图像之间的关键内容在语义上达到对齐。此外,基于特征描述子表示的方式,每个特征描述子比之前的单个高维特征向量表示方式,其搜索的空间变大,这相当于在一个“多样本”的情况下进行分类,进而提高了度量对噪声的容忍性。
对于C-wayK-shot设置下的小样本图像分类任务,查询图像(x,y)属于支持图中第k∈{0,1,2,…,C-1}类的概率为
(7)
对于每个插曲中的N幅查询图,其损失函数为
(8)
3 实验和分析
3.1 数据集
实验所用的数据集包括小样本数据集和基准细粒度数据集。
1)miniImageNet数据集。作为ImageNet的微型版本,miniImageNet数据集包含100个类,每个类包含600幅彩色图像。实验时按64、16和20个类别分为训练集、验证集和测试集。
2)Few-Shot Fine-Grained 数据集。选择了3个基准细粒度数据集进行细粒度小样本学习任务实验。包括Stanford Dogs(Khosla等,2011)、Stanford Cars(Makadia和Yumer,2015)和CUB 200-2011(Caltech-UCSD birds)(Wah等,2011)。Stanford Dogs包含120个类别,20 580幅彩色图像,实验时按70、20和30个类别分为训练集、验证集和测试集。Stanford Cars包含196个类别,16 185幅汽车彩色图像,实验时按130、17和49个类别分为训练集、验证集和测试集。CUB 200-2011包括200个类别,6 033幅鸟类彩色图像,实验时按130、20和50个类别分为训练集、验证集和测试集。
3.2 实验设置
实验的软硬件配置为Intel(R)Core(TM)i7-5930K @ 3.50 GHz 12 CPU,64 GB内存,GeForce GTX TITAN X GPU,显存大小11 GB。服务器系统为Ubuntu 16.04 LTS 64位,深度学习框架为Pytorch。
3.2.1 WSOL网络
与CAM一样,以VGG-16作为分类网络的骨干。具体地说,即用本文提出的SACM模块代替VGG16的最后一个池化层和3个完全连接的层,得到本文的WSOL网络,在miniImageNet、Stanford Dogs、Stanford Cars和CUB 200-2011数据集的训练集上进行端到端训练。为了公平比较,输入图像统一设为224×224像素(本文模块为全卷积结构,可处理任意大小的输入)。采用SDG(stochastic gradient descent)为优化器,初始学习率设为1×10-3,学习率每20 000个epoch减少一半,互补非显著掩膜生成的阈值设定为0.9。
3.2.2 小样本分类网络
采用插曲训练机制训练小样本图像分类网络。每个训练插曲包含随机抽取的C个类别,每个类别除包含K幅支持图像外,设置C-way 1-shot包含15幅查询图像,C-way 5-shot包含10幅查询图像。即对于5-way 1-shot任务,每类有5幅支持图像和15幅查询图像,因此每个插曲共5×1=5幅支持图像和15×5=75幅查询图像。类似地,对于5-way 5-shot任务,共5×5=25幅支持图像和10×5=50幅查询图像。另外,将所有输入图像尺寸调整为84×84像素。在训练阶段,随机采样300 000个插曲,选择Adam作为优化器,初始学习设置为5×10-3。学习率每10万个插曲减少一半。在测试阶段,采用600个插曲的均值,95%的置信区间作为性能指标。
3.3 小样本数据集miniImageNet实验分析
首先在miniImageNet数据集上进行小样本图像分类准确率的比较,实验结果如表1所示。当采用ResNet12作为嵌入网络时,本文模型在5-way 1-shot和5-way 5-shot任务中取得了最好的成绩,特别是在5-shot任务中获得最好结果,比DN4(Li等,2019a)高出3.29%。此外,当同时使用Conv64作为嵌入网络时,本文模型在5-way 5-shot任务上实现了最高的精度,比CovaMNet(covariance metric networks)(Li等,2019b)、DN4和Sal-Net(saliency-guided networks)(Zhang等,2019)的性能分别提高了4.40%、1.03%和0.04%。使用Conv64嵌入网络在5-way 1-shot任务中也获得了非常有竞争力的准确性,与R2D2(recurrent replay distributed DQN)(Bertinetto等,2019)、CovaMNet和DN4相比,分别提高了3.82%、2.13%和2.08%。在5-way 1-shot任务中,Dynamic-Net(Gidaris和Komodakis,2018)和Sal-Net执行非常复杂的训练步骤,以获得优异的结果。前者也采用两阶段模型,但是需要对小样本图像分类的嵌入网络进行预训练,而本文方法则不用。后者利用最新的显著性检测模型生成显著性掩膜,从而定位关键对象,但是其需要像素级别的标注数据。相反,本文方法仅需要图像级别标注。实验结果表明,对于常规的小样本图像分类任务,本文方法在5-way 1-shot和5-way 5-shot设置下都优于先前的方法。
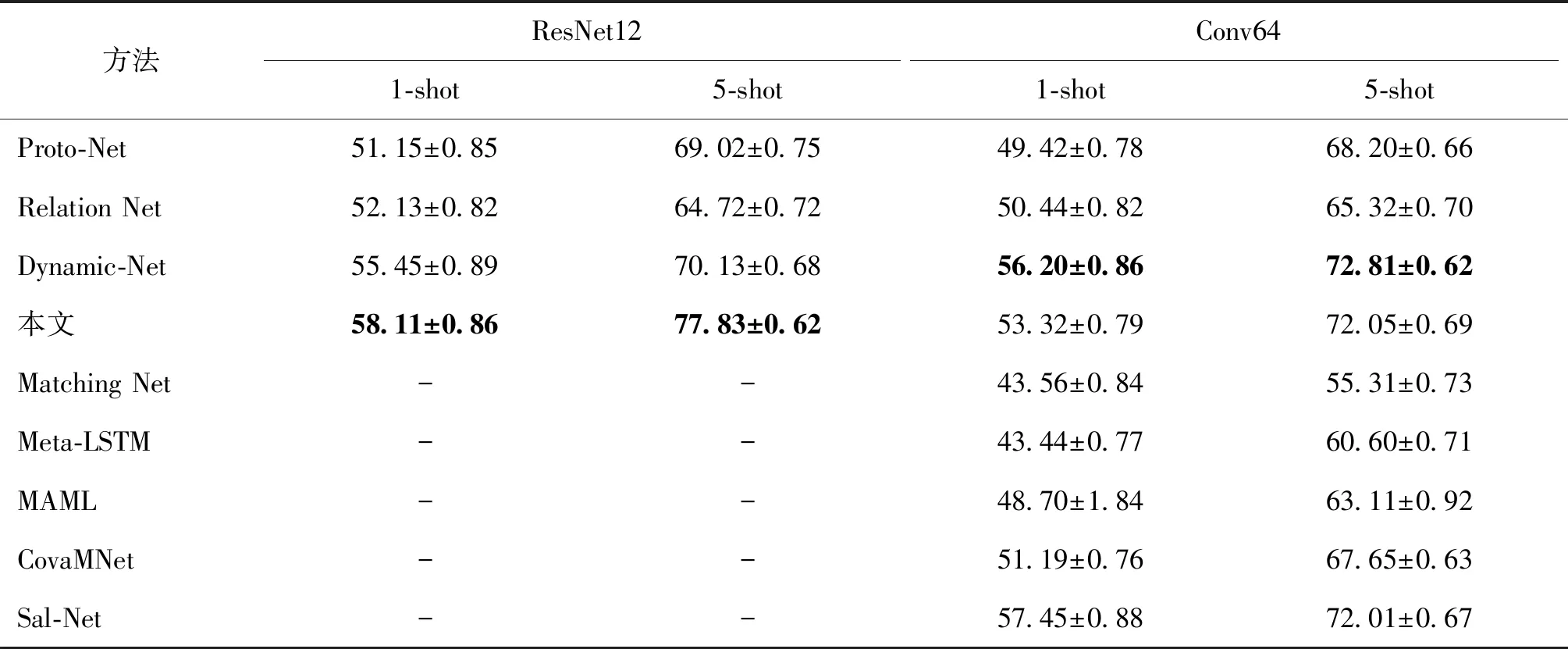
表1 在miniImageNet数据集上小样本分类精度Table 1 Few-shot classification accuracies on miniImageNet /%
3.4 细粒度小样本数据集实验分析
与一般的小样本分类任务相比,细粒度数据集由于类间差异小、类内差异大,因此细粒度的小样本分类更具挑战性。实验在3个主流的细粒度小样本数据集上全面评估本文的方法。同时,与DN4、CovaMNet、GNN(graph neural networks)(Garcia和Bruna,2018)、Proto-Net(Snell等,2017)、MattML(multi-attention meta learning)(Zhu等,2020)和LRPABN(low-rank pairwise alignment bilinear network)(Huang等,2021)等方法进行比较。如表2所示,本文方法在5-way 1-shot任务和5-way 5-shot任务下,在3个细粒度数据集上均实现了最佳性能。更详细地讲,本文方法在Stanford Dogs数据集上,在1-shot和5-shot设置下分别比第2名提高了4.18%和15.79%。在Stanford Cars数据集上,在1-Shot和5-Shot方面均达到了最先进的性能,与第2名相比分别提高了16.13%和5.83%。对于CUB 200-2011数据集,本文方法在1-shot设置下获得竞争准确性,在5-shot设置下获得最佳性能。实验结果表明,弱监督目标定位有助于提高细粒度小样本图像的分类性能。本文提出的融合弱监督目标定位的细粒度小样本分类方法能够极大提高细粒度图像的分类性能。

表2 3个细粒度数据集上的细粒度小样本分类精度Table 2 Classification accuracy of fine-grained few-shot learning on three fine-grained datasets /%
3.5 泛化性实验
为了验证小样本学习模型的泛化性能并证明本文方法可以同时很好地处理小样本学习和细粒度小样本学习任务,在完全不同的数据集上对模型进行评估。与训练数据集完全不同的新数据集会出现显著的数据分布偏移(Li等,2020;Recht等,2019),导致模型的性能显著下降。训练类和测试类没有交集,但是由于它们来自同一数据集,因此它们仍具有相同的数据分布。实验中,在miniImageNet上训练模型,在细粒度数据集上进行测试以评估泛化能力。为了公平比较,所有模型的嵌入网络均为ResNet12,实验结果如表3所示。可以看出,在3个新数据集上,本文模型优于Proto-Net(Snell等,2017)、Relation Net(Sung等,2018)和K-tuplet loss (Li等,2020),表明本文方法具有良好的泛化能力。结合小样本分类实验和细粒度小样本分类实验结果可知,本文方法可以同时很好地处理小样本学习和细粒度小样本学习。
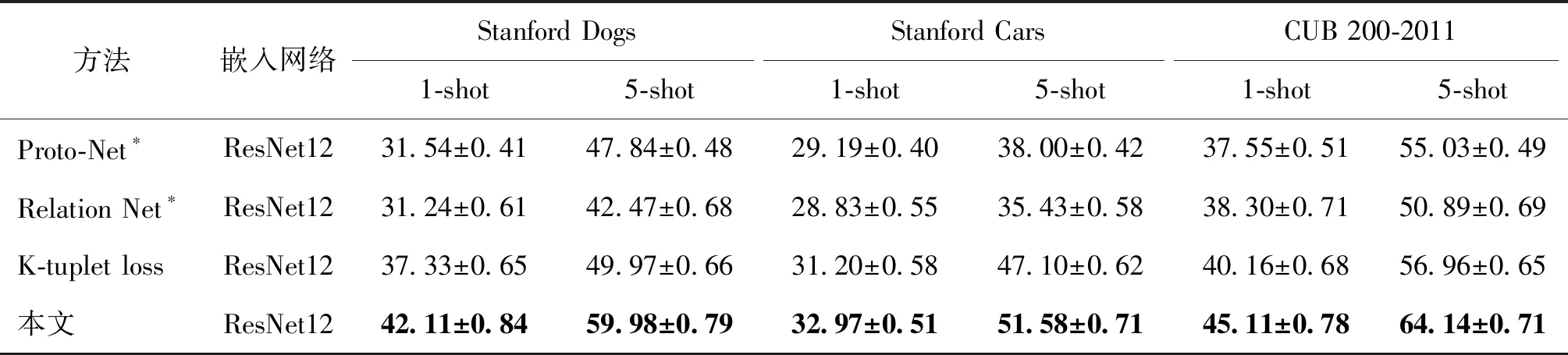
表3 模型泛化性能下的分类精度Table 3 Accuracy comparison of model generalization performance /%
3.6 弱监督目标定位实验分析
CUB 200-2011数据集是WSOL任务的基准数据集,包含200 种鸟类,有5 994幅训练图像和5 794幅测试图像,对每幅图像都提供了本地化的边界框。实验时,在训练集上训练模型,但是没有使用任何边界框作为监督信息。在元测试阶段,为每个输入图像预测边界框和标签。使用Top-1定位精度(Top-1 Loc)、Top-1分类精度和已知真实(ground truth,GT)类别下的定位准确度(GT-Known Loc)作为评价指标。当基准真实框与预测框之间的交并比超过50%时,GT-Known Loc为正确。当Top-1分类结果Top-1 Clas和GT-Known Loc都正确时,Top-1 Loc才为正确。为了公平比较,采用VGG-16作为分类网络骨干,实验结果如表4所示。可以看出,本文方法在Top-1 Loc acc和Top-1 Clas acc上的表现均优于对比方法。
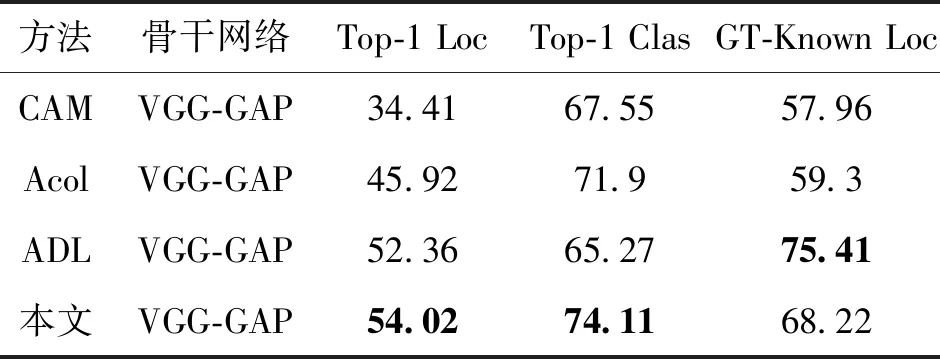
表4 在CUB 200-2011数据集上的弱监督目标定位精度比较Table 4 Comparison of WSOL accuracy on CUB 200-2011 dataset /%
图5是在细粒度小样本数据集CUB 200-2011上本文方法与CAM方法的目标定位的可视化对比。可以看出,与CAM方法相比,本文方法可以定位到更加全面的对象区域。

图5 弱监督物体定位性能对比Fig.5 Comparison of weakly-supervised object localization performance((a)CAM;(b)ours)
4 讨 论
4.1 消融实验
4.1.1 嵌入网络的影响
通过实验探究嵌入网络Conv64和ResNet12对小样本学习和细粒度小样本学习的影响。Conv64是具有4个卷积块的浅层网络,每个卷积块包含64个3×3卷积核、批归一化层(batch normalization)和最大池化层(max pooling)。ResNet12是一个基于4层残差块的深层网络,每个残差块由3个卷积层构造。二者在不同数据集上的实验结果如表5所示。可以看出,与Conv64相比,ResNet12在1-shot和5-shot设置下,在所有数据集上的性能都有显著提升。表明了ResNet12比浅层网络Conv64能提取到更多特征,获得语义更加丰富的嵌入空间。

表5 不同嵌入网络下小样本分类精度Table 5 Influence of the embedding network on few-shot classification accuracy /%
4.1.2 SACM模块和SAM模块的影响
为了探究各种模块在所提出方法中的作用,进行了消融实验,结果如表6所示。其中,w/表示包含,w/o表示不包含。首先,w/ SACM和w/o SACM用来探究特征描述子筛选的作用,欧氏距离(ED)和SAM用于探究语义对齐距离(SAM模块)的作用。ED分类器的实现与原型网络相似。在原型网络中,通过拍平嵌入空间中的特征图获得一个高维向量来表示该全局表征。w/ SACM + SAM在不同的设置下都优于w/ SACM + ED,尤其是使用ResNet12作为嵌入网络时,在5-shot设置下获得了约25.11%的改善,在1-shot设置下获得了约14.37%的改善,表明所提出的语义对齐距离可以提高小样本分类任务的性能。其次,根据w/ SACM + SAM和w/o SACM + SAM可知,使用SACM模块进行特征描述符筛选,可以显著提高细粒度小样本分类的性能。但是w/ SACM + ED和w/o SACM + ED表明SACM无法与ED很好地配合。消融实验表明,本文方案中的各个模块都是有效的,且融合使用时能起到最大的作用。
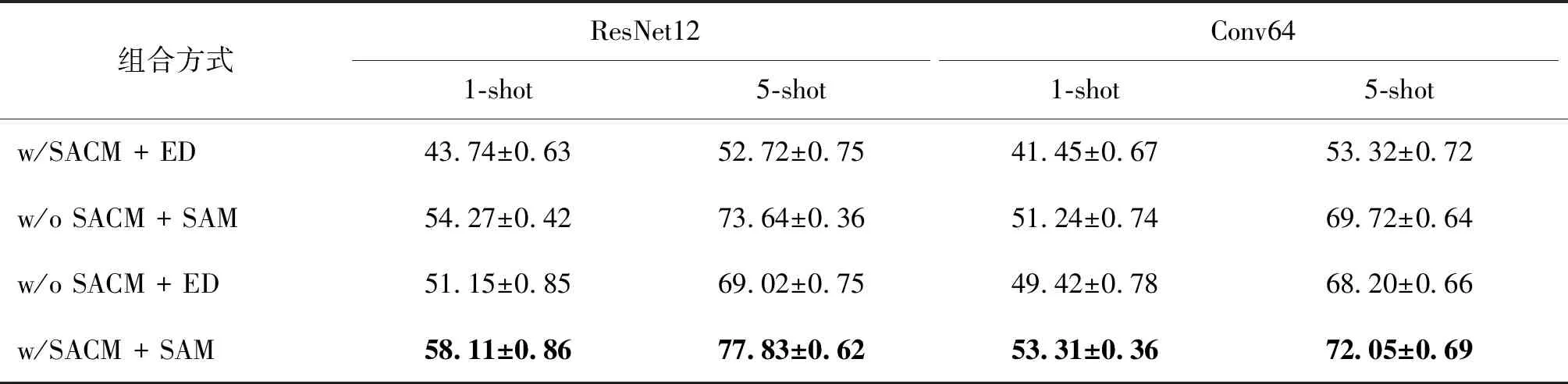
表6 本文方法不同模块下的分类精度Table 6 Accuracy comparison of each module in this scheme /%
4.2 可视化实验
为进一步验证本文方法的性能,将小样本数据集和细粒度小样本数据集的输入对应的类激活图可视化,并与主流的WSOL方法CAM进行比较,在miniImageNet和Few-Shot Fine-Grained数据集上的可视化结果如图6和图7所示。可以看出,与CAM相比,无论在miniImageNet还是细粒度小样本数据集中,本文模型都可以更完整地定位出关键对象。值得一提的是,两个模型都可以识别出之前未见过的全新类别(尤其是细粒度数据集)。这可能是因为测试阶段这些全新的类别始终包含与训练集相似的区域(例如细粒度图像),分类器会将新样本分类为训练集中与之最相似的类别,并以该区域为图像产生类激活图。

图6 在miniImageNet数据集上的弱监督目标定位可视化Fig.6 Visualization of weakly-supervised object localization on miniImageNet dataset((a)original images;(b)CAM;(c)ours)

图7 在Few-Shot Fine-Grained数据集上的弱监督目标定位可视化Fig.7 Visualization of weakly-supervised object localization on Few-Shot Fine-Grained datasets((a)original images;(b)CAM;(c)ours)
5 结 论
为了能同时处理好小样本图像分类和细粒度小样本图像分类任务,本文提出了一种融合弱监督目标定位的细粒度小样本图像分类方法。首先,设计了SACM模块实现弱监督目标定位,更重要的是进行特征描述子的筛选,得到适用于细粒度分类的特征描述子表示。接着,基于NBNN算法,提出了语义对齐距离模块SAM,通过在每个选定的特征描述子上执行余弦最近邻算法,实现查询图像和支持图像之间语义内容的对齐。对比实验表明,本文方法在小样本图像分类和细粒度的小样本图像分类任务上均优于最新方法。而且,结合泛化性实验,充分表明了本文方法可以同时处理常规的和细粒度的小样本图像分类。
本文提出的融合弱监督目标定位的细粒度小样本学习方法是一个二阶段网络模型,需要分两阶段训练。在未来的工作中,将尝试把弱监督目标定位网络和细粒度小样本图像分类网络融合到同一个网络中,提出一个可以完全端到端训练的细粒度小样本图像分类模型,进一步优化和提高细粒度小样本图像分类模型的准确率。
