样本均衡与特征选择在员工离职倾向预测上的应用
2022-07-15吴学亮
吴学亮,娄 莉
(西安石油大学 计算机学院,西安 710000)
0 引 言
近年来,随着经济社会的发展,员工流失问题是追求持续增长企业面临的重大挑战。这是一个在研究和实践中都受到广泛关注的问题。为了留住员工,并利用员工的知识促进公司的成长,人力资源部门利用机器学习算法预测员工是否有离职倾向解决此问题。
在现实生活中,数据普遍呈不平衡分布特征,其带来的问题也越加明显。随着分类问题研究的发展,越来越多的研究者开始研究不平衡数据集的极端不平衡分布特征,不平衡数据集的分类算法也越来越全面。针对上述问题,本文对SMOTE、SMOTETOMEK、ADASYN、SMOTEENN和Borderline-SMOTE 5种样本均衡方法进行了研究与分析。
在应用机器学习的过程中,样本数据的特征通常差异很大,其中可能包含不相关的特征或存在紧密依赖的特征。综上所述,本文的贡献如下:
(1)提出了基于LightGBM(Light Gradient Boosting Machine)的员工离职倾向预测模型,可根据给出的信息,评估员工是否有离职倾向并给出建议。
(2)实验过程中,对样本数据进行了详细的特征工程,包括:数据标准化、样本均衡和特征选择。
(3)利用Data Castle提供的数据集,评估了LightGBM方法。实验表明,使用样本均衡和特征选择后再使用LightGBM方法,优于直接使用LightGBM方法。
1 特征工程
1.1 数据标准化
数据采用不同的度量单位,可能导致不同的数据分析结果。通常,用较小度量单位表示的属性值,将导致该属性具有较大的值域,该属性往往具有较大的影响或“权重”。为了避免数据分析结果对度量单位选择的依赖性,需要对样本数据进行标准化或规范化,使之落入较小的共同区间(如:[0,1]或[-1,1])。
对数据进行标准化不仅可以规避数据分析结果对度量单位选择的依赖性,有效提高结果精度;也可以简化计算,提升模型的训练和收敛速度。常用数据标准化(Data Normalization,DN)方法有:最小-最大值标准化、z分数标准化和小数定标标准化。
本文采用z分数标准化,经过处理后的数据符合标准正态分布,即均值为0,标准差为1。转化函数定义如式(1):

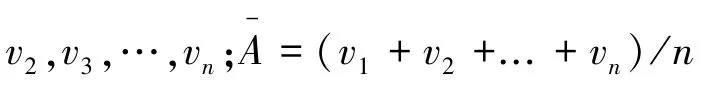
1.2 样本均衡
在现实生活中,为了更好地理解数据集类不平衡问题,本文从二分类问题的角度进行分析。设:br、、χ分别表示样本的失衡率、少数类和多数类。一般情况下,如果关注的是少数类的样本数据且br≤0.2(本文数据集br<0.2),就需要考虑对样本进行均衡处理,如式(2):

目前,已有多种方法用来克服类不平衡问题。其中,最常用的技术是采样方法,用于实现从数据集类的不平衡分布到平衡分布。采样方法可分为两种:欠采样和过采样技术。欠采样技术是指去除多数类中的少数数据点,而过采样方法是生成属于少数类的合成数据点,以获得所需的平衡比率。本文重点介绍过采样技术,主要包括:SMOTE、ADASYN、SMOTETOMEK、SMOTEENN、Borderline-SMOTE。
1.3 特征选择
特征选择可以消除不相关或冗余的特征,从而减少特征数量,提高模型的准确性,或减少运行时间。此外,选择具有真实相关特征的简化模型,可以使研究人员更容易理解数据生成的过程。常见的特征选择方法可以分为3类:过滤、包装和嵌入方法。本文在LightGBM算法的基础上,考虑特征的互补性,对特征进行选择和剔除。
对于包装方法,其主要组成部分是搜索策略和学习算法。包装模型中的搜索策略可以分为全搜索、启发式搜索和随机搜索。由于计算成本,完全搜索会耗尽所有可能的子集并找到最佳子集。与完全搜索不同,启发式搜索策略将会权衡搜索效率的最优性。顺序后向选择(Sequential backward selection,SBS)和顺序前向选择(sequential forward selection,SFS)是两种最常用的启发式搜索打包方法。但是,这两种方法都有一个单调的假设,即添加的特征不能被删除,并且被删除的特征不能再次添加,这使其易陷入局部最小值。随机搜索总是使用进化方法作为其众所周知的全局搜索能力。与确定性算法相比,进化搜索方法不仅能有效捕捉特征冗余和交互作用,而且不受单调假设条件的限制。进化搜索方法,可以避免陷入局部最优,并且可以找到小部分特征。然而,基于随机搜索的打包方法存在计算量大的缺点。
遗传算法(Genetic Algorithm,GA)是受自然进化过程启发而开发的一种启发式优化技术,其种群的成员以基因序列的染色体形式表示。在特征选择问题中,每个基因用0或1来表示,对应问题空间的一个属性或参数。本文选择基于LightGBM算法进行员工离职倾向预测,其结果的准确率作为适应度函数评估指标。遗传算法的基本思想是适者生存理论。每个新种群生成的算法,可通过选择、交叉和变异等3个主要步骤达到更高的适应度水平。
2 LightGBM算法
2.1 算法原理[8]
LightGBM是在传统的梯度提升树(GBDT)上使用直方图算法(histogram-based algorithm),在一个待分裂的结点上,为每一个特征构建直方图。具体实现过程是:先对特征值进行分箱处理,然后根据分箱值构造一个直方图;遍历结点中的每一个样本,在直方图中累积每个的样本数和样本梯度之和;当一次数据遍历完成后,直方图就累积了需要的统计量。
对于每个特征,根据构建的直方图,遍历每一个值从而寻找最优分裂特征及值。同时使用带深度限制的Leaf-wise叶子生长策略,经过一次数据可以同时分裂同一层的叶子,具有易进行多线程优化、易控制模型复杂度、不易过拟合的特点。
2.2 算法优势
为了更准确的残值建模和预测,LightGBM算法在基于直方图的GBDT算法中引入了基于梯度的单边采样(Gradient-based One-Side Sampling,GOSS)和独占功能捆绑(Exclusive Feature Bundling,EFB)两种技术。其中,GOSS方法可在小样本情况下实现高精度预测,可减少计算成本,性能优于随机抽样方法且不会损失太多的训练精度。而EFB可将互斥的特征捆绑在一起解决高维特征的降维问题。
在GBDT算法中,信息增益由方差增益计算获得。而LightGBM算法采用的是GOSS算法,根据训练实例的梯度绝对值降序,对训练实例进行排序,并且生成3个特征子集:、A和。其中,特征子集由前100%的实例与较大的梯度得到,特征子集A由(1-a)×100%组成的实例与较小的梯度得到;特征子集是进一步随机采样b×|A|得到。估计方差增益V()定义如式(3):
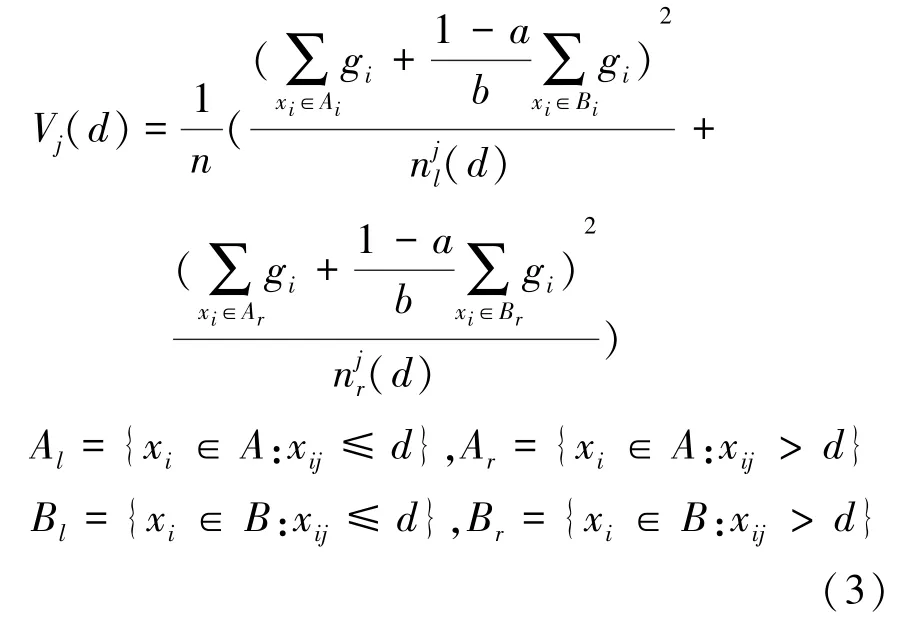
3 实验结果与分析
为了验证5种样本均衡方法和遗传算法对数据进行处理的有效性,在配置为Intel Corei7、SSD128 G、HDD 1TB、RAM 24 GB、Windows操作系统的环境中进行了相关实验。实现代码工具利用Conda 4.11.0完成;GA种群规模为100,迭代次数是50,交叉率是0.5,变异率是0.4;LightGBM算法参数为默认值。本文实验使用scikit-learn版本为0.24.1、LightGBM版本为3.3.0。
3.1 数据集描述
本文数据取自Data Castle平台发布的数据集,从中选取1 100条数据用于实验。其中,在职记录922条,离职记录178条。样本的失衡率即离职率为:0.161 8。原始数据中有31个条件属性,1个决策属性。通过业务选择过滤了3个条件属性,利用已有的条件属性构造出了6个新的条件属性。
3.2 评价指标
本实验采用准确率、精确率、召回率和值作为评价指标。准确率()是指对于给定测试数据集,分类器正确分类的样本数与总样本数之比;精确率()是预测的正例结果中,确实是正例的比例;召回率()是所有正例的样本中,被找出的比例;1值是综合评价指标,1值越接近1,表明模型预测越准确。准确率、精确率、召回率和1值是由混淆矩阵计算得到。分类结果混淆矩阵见表2。准确率、精度率、召回率和值的计算方法如公式(4)公式(7)所示。

表1 分类结果混淆矩阵Tab.1 Confusion matrix of classification results

3.3 模型评估
为了达到验证的目的,在验证数据集时使用了分层(10)折交叉验证。每个数据集被随机分成折,其中1折为训练集,剩余的为测试集。分层折交叉验证是评估建模结果最有效和广泛使用的验证和能力评估技术之一。通过分层折交叉验证获得了不同样本均衡算法和是否使用遗传算法进行特征选择的最佳评价指标。实验结果见表2与图1所示。

图1 实验运行结果对比Fig.1 Comparison of experimental results
由表2可知,样本处理方法为“SMOTEENN+GA”时,效果最好,其准确率达到95.82%、精确率达到97.42%、召回率达到96.28%、值达到96.66%。实践证明,采用样本均衡和遗传算法的特征选择,可以有效提高模型的性能。

表2 样本采用不同处理方法性能对比结果 Tab.2 The performance comparison of different processing methods %
4 结束语
本文描述了研究预测员工离职的必要性,并在构建模型时使用了样本平衡、特征选择和机器学习算法,强调样本均衡和特征选择算法的重要性。模型选用SMOTEENN、遗传算法和LightGBM的组合,与单独的LightGBM分类器给出的结果相比,该模型提供了更优越的性能。
