基于K-BERT的情感分析模型
2022-07-15王桂江黄润才
王桂江,黄润才
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引 言
大数据时代的社交媒体为用户提供了反馈和信息交流的平台,对于一件商品,不同的人有不同的看法,了解用户的看法和态度,是改进和优化的重要途径。情感分析是对用户观点的凝练,代表着用户的实际感受。
情感分析的发展经历了3个主要阶段,基于情感词典、基于机器学习和基于深度学习。情感词典作为最早的情感分析方式,通过将人们可能的观点评价构建一个字典,进行内容的匹配,以此来获得用户的情感倾向,这类的方法简单直接,不需要太复杂的方法就能获取到结果,但是情感词典的构建却需要大量的人力、物力和精力。而且随着社会的发展,基于情感词典已经无法跟上时代的变化。机器学习的出现,一定程度上解决了情感词典构建的问题,基于机器学习的方法根据文本提取的特征进行分类,即利用支持向量机(Support Vector Machines,SVM)等分类器,但是这类方法仍然需要人工标注的数据,分类器的结果也取决于数据的标记效果,泛化能力并不强。
随着深度学习的发展,自然语言处理进入了新的发展阶段。基于深度学习的情感分析有3个典型代表:
(1)利用神经网络训练词向量。利用神经网络训练得到词向量,之后将词向量的结果应用到下游任务中。比较典型的方法是利用Word2Vec训练词向量,将训练好的词向量送入循环神经网络(RNN)进行分析。
(2)利用循环神经网络RNN。RNN是处理时序问题的关键技术,基于RNN改进的长短时记忆网络(Long Short-Term Memory,LSTM)、门控循环单元(Gated Recurrent Unit,GRU)。陈帆利用LSTM对微博情感进行分析,并用于微博特定主题的谣言识别;李辉等利用GRU学习文本词语,并引入注意力机制实现了比LSTM有竞争力的效果。但是对于情感分析,获取上下文非常有必要,张俊飞等用BiLSTM来获取上下文信息,将提取到的信息送入分类器,对评教评语进行情感分析。这类方法的效果依赖于特征提取的效果,而且激活函数的选择也关系到最终的分类效果。
(3)无监督学习,并充分考虑上下文信息。基于注意力机制的Transformer模型,使用编码和解码的机制,通过对注意力机制进行不同形式的构造,取得了比RNN更强的效果;基于Transformer的BERT模型,在传统的分类、问答和翻译等十多项任务中取得了历史最好的成绩,郝彦辉等在BERT模型的基础上引入BiLSTM,根据上下文判断情感倾向不明显的内容的真实情感倾向;李文亮等在BERT的基础上融合多层注意力机制,在方面级情感分析上取得了不错的效果。
基于BERT预训练模型,升级和改造出了如ALBERT、XLNET等表现不俗的模型,基于transformer-XL的XLNET使用相对小的数据规模实现了接近BERT的效果;ALBERT使用相对小的模型实现了与BERT接近的表现,甚至在部分场景下效果更好。尽管这一类的预训练模型在特征提取和词向量构建上表现出了较好的效果,但却存在无法理解语义背景的问题,比如:“基督山伯爵在巴黎的住处位于香榭丽舍大街,他很期待在这里遇见莫雷尔先生”是一句包含了地点、人物和社会关系的句子,而且带有开心的语气,如果不能理解其背景,只能感觉他在会见朋友。
综上所述,基于前人的研究成果和优化策略,为更好的获取文本信息的语义特征,增强对于语义信息的理解,提升模型对文本的情感分析能力,本文提出了结合K-BERT和BILSTM的情感分析模型,使用带有知识图谱的K-BERT代替BERT,丰富句子的背景信息,有利于组合句子内容,提高特征提取能力;在K-BERT基础上引入BILSTM,进一步增强对于上下文之间的语义提取;模型在NLP中文文本任务情感分类数据集上表现出了有竞争力的效果。
1 K-BERT语言模型概述
K-BERT是融合知识图谱的语言训练模型,该模型在开放域的8个中文NLP任务上超过了Google BERT,模型由Knowledge layer、Embedding layer、Seeing layer、Mask-Transformer Encoder组成。
1.1 Knowledge layer
Knowledge layer的作用是将知识图谱关联到句子中,形成一个包含背景知识的句子树(Sentence Tree)。知识嵌入句子的过程可以分为知识图谱查询(K-Query)和知识谱图嵌入(K-Inject)。KQuery从知识图谱中查询句子所涉及到的命名实体,K-Inject将查询到的命名实体相关的三元组嵌入到句子中合适的位置上,形成句子树。假设给定句子{,,…,w}和知识图谱(knowledge graph,KG),知识层输出的句子树结构为{,,…,w{(r,w),…,(r,w)},…,w},句子树形状如图1所示。

图1 句子树结构Fig.1 Sentence tree structure
其中w是从知识谱图中查询到的命名实体;r是与w相关的第个分支;w是与w相关的第个分支对应的值。
1.2 Embedding layer
Embedding layer层包含token embedding、softposition embedding和segment embedding,其作用是将句子树转换成为序列,同时要保留句子树的结构信息。
Token-embedding主要用于实现句子树的序列化,将句子中的每个token映射成为一个维度的向量表示,并在每个句子的开头添加一个[CLS]标记;
一是明确专项工作包联主体。项目引进之后,党委政府明确牵头领导和责任单位,将辖区管理和职能部门有效连接,给予回乡创业项目全面、实时、无缝的服务,尽最大努力协调解决项目遇到的困难。二是加强基础设施建设力度。地方党委政府加快推进农村路网、管网、电网、通信网等基础设施建设,为回乡项目提供硬件条件支持。三是督促项目规范有序运作。地方党委政府除了服务项目运作,还积极担负起监督项目规范运作的职责,督促企业规范运用各类优惠政策,遵纪守法、安全生产,做好相关职工维权和矛盾调处工作,真正确保项目健康运作、良性发展。
Soft-position embedding在BERT中,所有句子的输入信息都对应一个位置信息,在K-BERT中,将句子树的内容平铺以后,当分支中的token插入到对应的主干节点之后,主干节点后续的token会发生移动,导致原有的位置信息发生变化,软位置(Soft position)通过对句子树的位置进行二次编码,将其原有的顺序信息进行恢复,理顺了句子的结构。
Segment embedding该层用以区分一个句子对中的两个句子,当包含多个句子时,第一个句子中的各个token被赋值为,第二个句子中的各个token被赋值为,当只有一个句子时,segment embedding为。
1.3 Seeing layer
Seeing layer层的作用是通过一个可视化矩阵来限制词与词之间的关系,解决句子树软位置编码后的一对多现象。对于一个可视化矩阵,相互可见的取值为0,互不可见的取值为-∞,定义如式(1):

1.4 Mask-Transformer
Mask-Transformer的核心思想是让一个词的嵌入只来源于其同一个枝干的上下文,而不同枝干的词之间相互不受影响,可视化矩阵解决了句子树位置不同但编码相同的问题,通过在softmax函数中添加可见矩阵,控制注意力的影响系数。Mask-Transformer由12层mask-self-attention堆叠,mask-self-attention的定义如式(2)~式(4):

其中:W,W,W是需要学习的模型参数;h是隐状态的第个mask-self-attention块;d是缩放因子;为可见矩阵。
Embedding layer、seeing layer、句子树和可见矩阵是K-BERT的处理的关键技术,四者之间的关系如图2所示。从knowledge layer得到句子树后,对句子树同时构建可视化矩阵和送入embedding layer编码,这两个过程得到的信息归并后输入到maskselft-attention中进行计算。

图2 K-BERT处理的关键技术Fig.2 Key technology of K-BERT processing
2 一种改进K-BERT的情感分析模型
本文在K-BERT的基础上,通过引入双向LSTM,增强模型对于上下文的语义关联能力,使模型既有丰富的背景知识,又能很好的关联上下文,获取更多的语义信息,从而实现情感分类效果的提升。本文的模型如图3所示,称其为KB-BERT。

图3 KB-BERT情感分析模型Fig.3 KB-BERT sentiment analysis model
BILSTM层:双向LSTM层的目的是学习文本所含特征,K-BERT层计算输出的词向量在LSTM层进行再次学习,获取句子的上下文信息,对语义信息进一步增强;
Softmax层:经过双向LSTM提取到的特征信息被输入到softmax层中进行分类,将情感分为正面和负面。
2.1 BiLSTM层
LSTM是一种基于RNN的网络结构,LSTM由输入门、遗忘门、记忆单元和输出门4部分组成,LSTM结构如图4所示。

图4 LSTM网络结构Fig.4 LSTM network structure

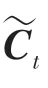
遗忘门:
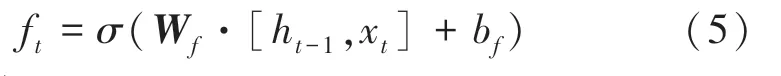
输入门:

输出门:

其中,和b分别为遗忘门的权重矩阵和偏置;和b分别为输入门的权重矩阵和偏置;为候选向量;和b分别为输出门的权重矩阵和偏置;和b分别是计算单元的权重矩阵和偏置。
2.2 Softmax分类层
经过处理后的信息使用soft max层进行情感分类。softmax为每个输出分类的结果均赋值一个概率,表示每个类别的可能性,式(11):

其中,z为第个结点的输出值;C为输出结点的个数;s是当前元素与所有元素的比值,即当前元素的概率。
3 实验
3.1 实验环境及数据集
本实验环境:处理器:E3-1281-V3 3.7 GHz八核;内存:16 GB 1 600 MHz DDR3;GPU:华硕1070Ti 8G;系 统 环境:Ubuntu 18.04 LTS;编程语言:python3.7,pycharm开发环境,深度学习库为Pytorch。
本文使用Book_review和Weibo两个情感数据集,正面情绪标签为1,负面情绪标签为0。Book_review从豆瓣获取,包含正负情绪各20 000条;Weibo从新浪微博获取,包含正负情绪各60 000条。
3.2 评价指标
为了验证模型的有效性,采用准确率()对测试集和验证集进行分别验证,准确率的计算公式(12):

其中,T表示正面评价样本中被预测为正面的样本总数;T表示负面评价样本中被预测为负面的样本总数;F表示负面评价样本中被预测为正面的样本总数;F表示正面评价样本中被预测为负面的样本总数。
3.3 对比实验设置
为证明本文方法的有效性,取以下对比方法进行验证:
(1)Google BERT。首先将输入的文本进行词向量编码,对于获取到的词向量进行信息提取,之后运用分类器进行结果分类。
(2)K-BERT。首先对输入的句子进行命名实体识别,之后对识别到的命名实体从知识图谱中查询关联词,将查询到的关联词插入到句子中形成包含背景知识的句子树,对输入的句子树编码,得到信息丰富的词向量,将得到的词向量直接送入分类器进行结果分类。
(3)KB-BERT。首先使用K-BERT获取信息丰富的词向量,将得到的词向量送入LSTM循环网络二次特征提取,丰富上下文提取,最后将得到的词向量送入分类器进行结果分类。
3.4 实验参数
实验一共训练5个epoch,每次的信息输入量batch_size为8,使用dropout防止过拟合,dropout的值设置为0.5,使用12层mask-self-attention,学习率设置为0.000 02。
3.5 结果分析
在本地实验条件下,KB-BERT、K-BERT和Google BERT在Book_review和Weibo数据集上的表现如图5和图6所示,其中图5是验证集上的效果,图6是测试集上的效果。

图5 不同模型在验证集上的准确率(%)Fig.5 Accuracy of different models on the validation set(%)

图6 不同模型在测试集上的准确率(%)Fig.6 Accuracy of different models on the test set(%)
在Book_review数据集上,KB-BERT的效果最好。在验证集上较K-BERT提升0.6%,较BERT提升0.9%;在测试集上,较K-BERT提升0.2%,较BERT提升0.1%。这说明,在数据内容为长文本的情况下,引入LSTM有助于对上下文信息的获取,本文优化后的模型在Book_review数据集上的表现最佳,准确率在验证集上达到87.97%。
在Weibo数据集上,BERT、K-BERT和KBBERT表现近乎一致。这说明,在文本内容较为稀疏无规则的情况下,引入知识图谱不能很好的得到命名实体,但是简短的稀疏文本在使用LSTM后,对于上下文的语义获取有一定的提升,说明在简短稀疏的文本内容中,LSTM网络对于增强语义获取仍旧发挥效果。尽管三者的区别不大,但本文所用方法在Weibo数据集上仍然取得最佳的效果,准确率在验证集上达到98.28%。
引入双向LSTM的KB-BERT模型,由Book_review和Weibo数据集上的表现说明,对于增强上下文语义理解,提升准确率均有效果。在涉及专业知识或背景知识的情况下,对于长文本的分析结果表现更佳,对于短文本和稀疏文本,所提模型仍然有效。
4 结束语
本文给出了一种具有知识图谱背景的情感分析模型KB-BERT。首先,通过K-BERT对输入的内容进行处理,丰富其知识背景,增强语义的理解能力;其次,引入双向LSTM网络,进一步增强对于语义的上下文内容理解。实验结果表明,改进后的KB-BERT在涉及背景信息的长文本数据上表现更好,在Book_reivew和Weibo两个中文数据集上,准确率分别达到87.97%和98.33%,证明了本文方法的有效性。
