基于改进Apriori算法的保险产品推荐
2022-07-14朱天宇谭文安
朱天宇, 谭文安
(上海第二工业大学 计算机与信息工程学院,上海 201209)
0 引言
清华大学国家金融研究院中国保险与养老金研究中心发布的《2021中国互联网保险消费者洞察报告》显示,传统线下网点、保险代理人仍然是主要代理渠道,调查人群中88%的人通过线下渠道购买保险。然而,目前保险公司线下推荐保险产品时,主要依靠保险经理人的经验,对于新员工而言,经验的缺乏和普遍的能力不足导致了推荐的产品不满足客户需求的问题,因而销售成功率低、客户满意度低。近年来,数据规模呈几何级数高速成长。海量数据已经成为企业资产的一部分[1],数据分析技术也日渐成熟[2]。在这种情况下,商务智能技术的应用给问题的解决提供了可行方案。数据分析表明,多家公司采用商务智能优化业务方法之后,在规避风险和保留客户方面取得了更好的效果[3]。
Apriori算法是由Agrawal和Skrikant于1994年提出的关联规则算法,用于挖掘频繁项集间的关联规则。但是在大规模数据库中应用Apriori算法的效率非常低,因为Apriori算法使用逐层搜索的迭代方法寻找频繁项集。自Apriori算法出现至今,不少学者从不同角度对该算法提出了优化和改进的方法。周发超等[4]提出了一种Apriori的改进方案I Apriori,通过减少扫描数据库次数,降低候选项集计算复杂度以及减少预剪枝步骤计算量等途径提高了算法的执行效率。张继荣等[5]基于新的数据结构,利用Hash表的存储技术以及对Apriori算法的优化提高了查找频繁项集的效率。胡世昌等[6]提出以二进制编码的项集作为载体载入内存,并在二进制编码的基础上有效地进行等效的集合之间的运算,有效提高了Apriori算法的执行效率和空间利用率。陈晨等[7]提出的Gra-Apriori算法,解决了经典的Apriori无法考虑属性类别关系的问题。郭凯等[8]改进后的Apriori算法大大减少了无效规则的产生,通过关联分析可得到对断面进行调整的有效强关联规则。高海洋等[9]通过数据压缩的方法减少了数据库扫描次数的同时,对生成的候选集进行了多次验证,大大减少了无效候选集的数量。赵学健等[10]对Apriori算法复杂的自连接和剪枝过程进行了优化,简化了频繁项目集的生成过程,提高了Apriori算法的时间效率。Supriyono等[11]将Apriori算法应用到农业领域,提高了农产品销售额。
以上介绍的相关算法实施比较复杂,或者虽有改进但不能较好适用于应用场景问题,本文通过采取Python字典列表[12]以键值方式重新组织数据、根据时序划分数据集、仅仅计算频繁2-项集的差集[13]等方式来提高算法执行效率,通过以客户为主键聚合事务数据来挖掘潜在关联规则,从而达到算法优化的目的,改进了Apriori算法,提出了一种改进的DS Apriori算法,计算出关联规则,以得出已经停售的保险产品的最佳替代产品,来指导保险经理人线下展业,在最大程度上保留客户。
本文将详细阐释改进的DS Apriori算法和具体实现,并对DS Apriori算法与Apriori等算法进行实验和对比分析,最后得出总结及工作展望。
1 改进的Apriori算法
1.1 算法改进方案
1.1.1 问题定义
设J={I1,I2,···,Im}是项的集合,设数据D是数据库事务的集合,其中每个事务T是一个非空项集,使得T⊆J。每个事务都有一个标识符,称为TID。设A是一个项集,事务T包含A,当且仅当A⊆T。关联规则是形如A⇒B的蕴涵式,其中A⊂J,B⊂J,A/=∅,B/=∅,并且A∩B=∅。规则A⇒B在事务集D中成立。具有支持度s,其中s是D中事务包含A∪B的百分比。它是概率P(A∪B)。规则A⇒B在事务集D中具有置信度c,其中c是D中包含A的事务同时也包含B的事务的百分比。这是条件概率P(B|A),即:
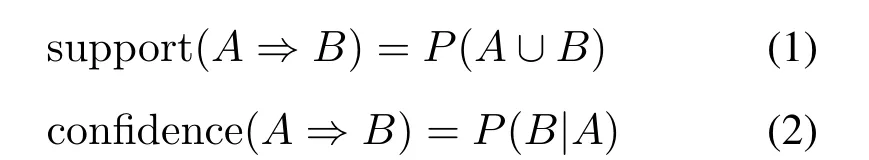
同时满足最小支持度阈值(min sup)和最小置信度阈值(min conf)的规则为强规则,项的集合称为项集,包含k个项的项集称为k项集,如集合X={I1,I2}是一个2项集。
1.1.2 数据准备
保险产品通常具有时效性,保险产品的推陈出新已是司空见惯[14]。传统的Apriori算法没有对数据进行针对性的划分,由于数据中包含已经停售的产品,在产生关联规则时,会产生停售产品之间的关联规则,既浪费了宝贵的计算性能,又没有意义。这里按照保险产品A的停售时间,将完整数据集CompleteSale集中停售之前的数据划分出来,称为BeforeStopSale集。通过重新划分数据集,为差集的计算提供数据准备,以此来挖掘新旧产品之间的关联规则。
传统的算法是以单次保险销售记录为一个事务,一条销售记录往往只包含一份保单的内容;如果直接在此基础上采用Apriori算法,单次销售记录的不连续忽略了用户所购买产品在时序上的相关性;不能够很好地将同一用户的多次购买记录关联起来,导致了潜在关联规则的丢失,关联规则挖掘效果受到影响。因此,本文重新组织了数据,将同一用户的所有购买记录整合为一条事务记录加入运算,建立起用户所购买产品之间的时序联系;使用Python的字典列表数据结构,通过键值对保存用户购买的产品以及该产品的购买次数,以此保留了原始数据作为多重集合的数据特征如表1所示;同时将购买次数也加入支持度计数的计算,用户重复购买这一行为在数据中得到了体现(见表2),更能体现用户的购买偏重。采用内存数据库Redis保存键值对数据,以此优化数据加载速度,进一步提高算法性能。

表1 Apriori算法输入数据格式Tab.1 The input data form for Apriori algorithm

表2 DSApriori输入数据格式Tab.2 The input data form for DSApriori algorithm
1.1.3 算法改进
传统的Apriori算法因为效率低下很少用在大规模数据挖掘中。本文放弃其迭代搜索全部的频繁项集的思路,转而搜索目标项目的频繁2-项集,只挖掘目标项目的二项关联规则,减少连接操作,以此解决频繁的连接操作造成的性能问题。
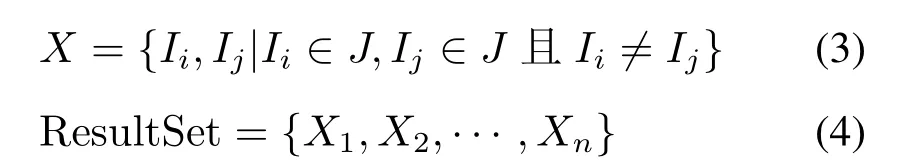
式中,X为频繁2-项集;ResultSet为频繁2-项集的集合。由先验性质的数学原理可得,产生频繁2-项集并不需要剪枝,再次提高了算法的效率。在BeforeStopSale数据集和CompleteSale数据集产生频繁2-项集得到结果ResultSetBeforeStopSale和ResultSetCompleteSale之后,分别计算出各自的关联规则集合RuleSetCS和RuleSetBSS

最终得到的关联规则集合RuleSettarget,即可推出保险产品A的替代产品。
1.2 DS Apriori算法伪代码
改进的Apriori算法伪代码描述如下:

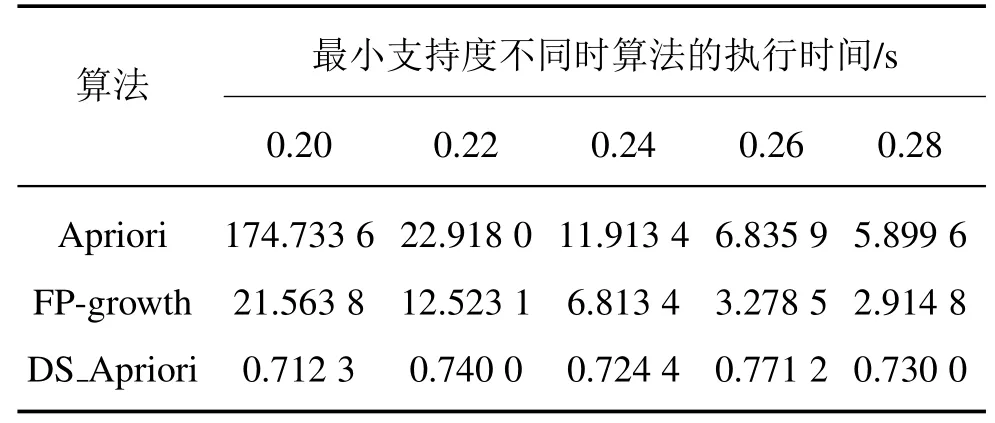
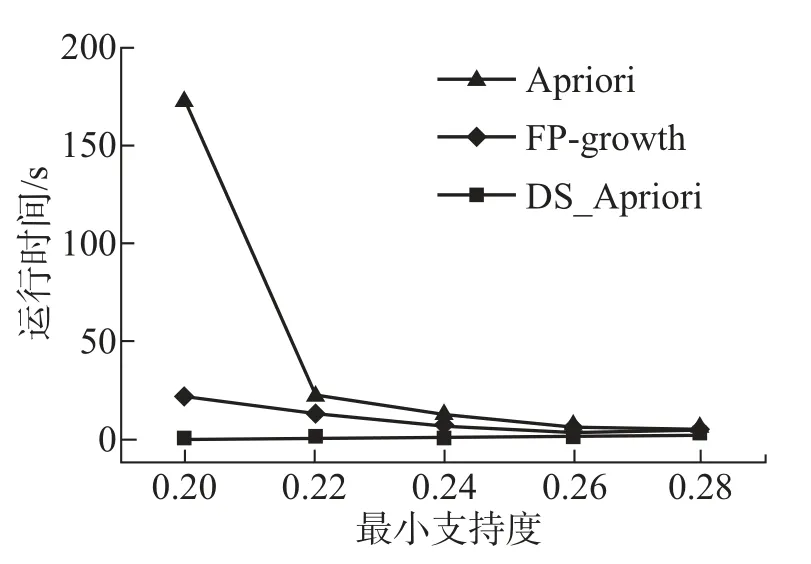
Algorithm 1 DS Apriori Input:D,min sup Output:L,frequent 2-itemset in D.1. L1=find frequent 1 itemsets(D);2. C2=apriori gen(L1);3. for each transaction t∈D{4. C t=subset(C2,t);5. c.count++;6.}7.for each candidate c∈C t;8. L2={c∈C2|c.count>=min sup}9.Return L2;10.Procedure apriori gen(L1:frequent 1 itemset)11. for each itemset l1∈l1 12. for each itemset l2∈l1 13. if(l1[1]=l2[1])∧···∧(l1[0]=l2[0])∧(l1[1] 改进的DSApriori算法创新工作主要包括如何构造频繁2-项集和关联规则两部分。 1.2.1 频繁2-项集构造 构造频繁2-项集目的是找出所有可能存在的二元关联项集,其构造步骤如下: (1)从生产数据库中获取原始数据,利用SQL语句重新组织数据,以字典列表的数据结构存储以用户ID为TID的事务数据集合BeforeStopSale集和CompleteSale集;BeforeStopSale是保险产品A停售之前的所有保险销售数据;CompleteSale是所有的保险销售数据。 (2)输入预定的最小支持度计数min sup,扫描事务数据集合,计算每个1-项集的支持度计数(即每个产品的购买次数);删除小于最小支持度计数的集合,得到频繁1-项集的集合L1。 (3)连接步:使用L1自连接[15]产生候选2-项集的集合C2。 (4)剪枝步:根据先验性质,删除子集不是频繁1-项集的候选2-项集,得到剪枝后的C2,需要注意的是,这一步并没有候选项从C2中删除,因为这些候选的每个子集也都是频繁的。 (5)计算每个候选2-项集的支持度计数,删除小于最小支持度计数的候选2-项集,得到频繁2-项集的集合L2。 (6)对BeforeStopSale和CompleteSale分别执行步骤(2)~(5),得到频繁2-项集ResultSetBeforeStopSale和ResultSetCompleteSale。 1.2.2 关联规则构造 关联规则的作用是确定关联项之间的关联关系,其构造步骤如下: (1)设置置信度阈值min conf; (2)构造L2中频繁2-项集的项之间的关联规则A⇒X,此处仅构造目标产品A与其蕴含的项集之间的关联规则,并计算置信度; (3)删除小于置信度阈值的关联规则,最终得到满足条件的强关联规则; (4)分别对频繁2-项集ResultSetBeforeStopSale和ResultSetCompleteSale执行(1)~(3)步骤,得到强关联规则集合RuleSetBSS和RuleSetCS; (5)依据RuleSettarget=RuleSetCS-RuleSetBSS,求得RuleSettarget集合中关联规则右端即为保险产品A的最可能替代产品。 为了验证所提出算法的有效性和高效性,将所提出的DS Apriori算法与经典的Apriori和Han等[16]提出的不产生中间项集的FP-growth进行了对比试验。实验环境参数如表3所示,算法使用Python语言实现。测试数据集mushroom.dat来自UCI公共数据集[17]。 表3 实验环境参数Tab.3 Experiment environment parameters Mushroom数据集包括对姬松茸和Lepiota家族中23种鳃蘑菇的假设样本的描述,包含8 124条数据,存在缺失值,用1代替;共23个属性。 为了消除单次实验带来误差的影响,本文采用了多次取平均的方式,统计在不同最小支持度的情况下算法的执行时间。对Mushroom数据集应用Apriori等算法和本文算法的执行时间如表4所示。 表4 Mushroom数据集的实验结果对比Tab.4 Experiment results of Mushroom data set 为了更加直观地展现3种算法执行时间的对比情况,表4中执行时间的可视化如图1所示。 图1 Mushroom数据集的实验结果对比Fig.1 Experiment results of Mushroom data set 图1所示为各算法计算得出635个2项关联关系的运行时间对比。从表4可以看出,DS Apriori算法在效率上明显优于Apriori算法,略优于FPgrowth算法,在最小支持度较小时尤为明显。随着最小支持度增加,Apriori算法与FP-growth算法的执行时间呈下降趋势,但是DS Apriori算法的执行时间却基本持平。从图1可以直观地看出,DS Apriori算法随最小支持度的增大,其执行时间曲线几乎趋于水平,而Apriori算法的下降幅度却很大,尤其在最小支持度为0.20和0.22时表现得尤为明显。但是当最小支持度为0.28时,两种算法的执行时间基本一致。这主要是因为最小支持度越大,过滤掉的频繁k-项集(k>2)越多,运算量也越相近。 在以上实验中,以Mushroom数据集为对象,对Apriori、DS Apriori算法与FP-growth算法进行了比较,改进算法在效率上优于后两者。同时,从上述实验结果可以看出,在不同的最小支持度取值下,Apriori算法在执行时间上的波动幅度明显大于改进算法。FP-growth算法的执行时间随着最小支持度的增加较为平稳的下降,不断逼近DS Apriori算法。综上所述,本文改进算法DS Apriori的执行效率大幅高于Apriori算法与FP-growth算法,是一种行之有效的频繁2-项集生成算法。 DS Apriori算法与Apriori、FP-growth算法得出关联规则的原理相同。Apriori、FP-growth算法得到的是二元及以上的关联规则,DS Apriori算法得到的是二元关联规则,在精准度上一致。在业务要求下,Apriori、FP-growth算法产生了冗余的关联规则,DS Apriori算法效率更高、更符合要求。 本文提出了一种改进的DSApriori算法,创新工作表现在:①通过数据重组以挖掘出更多潜在的关联规则;②通过计算频繁2-项集的差集代替迭代搜索,减少搜索次数,降低了算法的时间复杂度,为大规模数据实时处理提供了可行方案。依据此关联规则得到某款已停售保险产品的最佳替代产品,为保险业务员线下展业提供指导。由于算法对数据要求较为严格,数据预处理花费较多时间。今后工作可考虑实现DSApriori算法与大数据存储技术以及并行计算相结合,整体上提高算法的效率。2 实验结果与分析
3 结 语
