深度图像修复的动态特征融合取证网络
2022-07-13任洪昊朱新山卢俊彦
任洪昊,朱新山,2,卢俊彦
(1.天津大学 电气自动化与信息工程学院,天津 300072; 2.数字出版技术国家重点实验室,北京 100871)
随着互联网技术的快速发展以及智能设备的普及,数字图像已经被广泛应用于社会生活的各个领域。数字媒体时代下,由于图像处理和编辑软件的易操作性,编辑和篡改图像变得便利和简单[1];同时,篡改后的图像是不易被人眼识别的,普通人难以观察到篡改操作留下的痕迹。因此,数字图像的真实性和可靠性受到更多的关注,图像信息安全已经成为一个亟待解决的问题。图像修复取证作为取证领域的一个重要研究课题,受到了研究者的广泛关注[2-4]。
图像修复是一种根据图像已知内容对缺失或损坏区域进行修复重建的计算机视觉技术[5]。传统的图像修复可以分为基于扩散的方法[6-7]和基于样本块的方法[8-9]。但是,它们只适用于填充纹理相似的图像,不能深入理解上下文信息,对于复杂的或模式化的图像修复效果不好。为此,研究者近年来提出了基于深度学习的修复方法[10-11](简称为深度修复)。深度修复通过数据驱动的方式,很大程度上跨越了图像底层特征与高层语义之间的语义鸿沟。它可以生成结构合理、细节丰富的图像内容,大大提升了修复效果。因此,深度修复已经成为图像修复领域的主流。
虽然图像修复技术给人们带来众多便利,但是它也可能被用于恶意的图像编辑和篡改,从而引发许多严重的社会问题。图像修复取证通过提取图像修复在操作过程中留下的篡改痕迹特征,进行篡改区域的识别和定位。因此,图像修复取证不同于一般的图像操作检测技术,它需要在图像操作层面实现像素级分类,也就是“语义分割”。
学术界针对不同的图像修复技术,提出了相应的修复取证方案。文献[12]根据通道内和通道间的局部方差构建特征集以识别基于扩散的修复方法。为了检测基于样本块的修复,文献[13]提出利用零连通特征度量图像块对相似度以识别修复区域;文献[14]在其基础上提出基于跳跃式块匹配的改进算法;文献[15]使用零连通特征识别相似块对和向量滤波的方法搜索可疑区域,并利用多区域关联来减小误警率;文献[2]采用中心像素映射的方式加快了可疑区域的搜索,并利用最大零连通特征和碎像拼接定位修复区域。
基于传统的修复方法是利用扩散或者样本块的匹配机制将非破损区域的低级非语义信息“粘贴”到破损区域。而深度修复[10-11, 16]利用大规模数据学习图像的高级语义特征,可以生成更逼真的图像细节。两者不仅在操作过程的差异性很大,而且深度修复能够创造给定图像中不存在的新对象用于填补破损区域,引入了不同的修复痕迹。因此,上述传统的修复取证方案并不适用于更先进的深度修复方法。
此外,文献[1]设计了一种具有编码器-解码器结构的卷积神经网络(convolutional neural networks,CNN)[17],用于定位基于样本块的图像修复。由于深度修复生成的图像内容在视觉上是难以区分的,直接从RGB图像提取修复痕迹和学习识别特征是效果不好的;同时,CNN 也倾向于学习图像主要的内容特征,而忽略修复过程中遗留的痕迹特征。这些导致该方案对深度修复的取证性能不佳。
目前,关于深度修复的取证(简称为深度修复取证)研究工作相对较少,只有文献[18]提出了一种高通预处理的全卷积取证网络。该算法利用空间高通滤波器以增强修复痕迹,实验结果证明了高通滤波对提取篡改痕迹特征的有效性。但是,深度修复方法是繁杂多样的,同一种方法遗留的痕迹也可能具有多样性和复杂性。因此,采用单一的痕迹增强方式的方案[18]有较大的局限性,鲁棒性不强。
综上所述,根据当前研究方案的不足之处,本文针对深度修复取证任务提出3个问题需要解决:
1)深度修复取证的关键是获取深度修复操作留下的微弱痕迹。由于深度修复的篡改区域与未篡改区域的视觉感知一致性[18],直接使用CNN对RGB图像的取证效果不佳。因此,利用鲁棒性强的篡改痕迹增强方式帮助痕迹特征提取是十分重要的。
2)图像修复取证任务需要对目标图像进行全局的像素级别的二分类。然而,篡改区域是具有不同的尺度大小的。因此,取证网络的决策不能仅仅局限于局部区域或目标。
3)由于取证网络中的卷积和下采样操作会导致特征图的细节信息损失,直接将高层次的特征图上采样后的输出是比较模糊的。
本文提出了一种端到端的深度修复取证网络,用于定位目标图像中经过深度修复操作的篡改区域,见图1。针对以上问题,提出了网络设计如下:采用3种痕迹增强方式将单输入扩展到多输入,通过设计的动态特征融合模块(dynamic feature fusion module, DFF)提取多种痕迹特征,并利用动态卷积[19]实现动态的特征融合。该方法结合RGB信息和CNN易忽略的细微痕迹实现有效的特征学习,具有较强的自适应能力和鲁棒性。为了弥补局部感受野导致的上下文信息不足,在编码器末端设计了多尺度特征提取模块(multi-scale feature extraction module, MFE)以扩展网络的多尺度视角。提出空间加权的通道注意力模块(spatially weighted channel attention module, SWCA)用于跳跃连接,实现有侧重地补充损失细节,避免取证结果模糊的问题。该方案能实现对篡改区域的像素级检测。在多种深度修复数据集上测试,实验结果表明该方案对于目标图像的篡改区域具有良好的定位性能。

图1 网络整体架构Fig.1 Architecture of the network
1 输入扩展
由于提取修复遗留痕迹的能力直接影响到取证网络的性能。因此,为了达到理想的取证效果,要充分考虑深度修复原理和现有取证方法的局限性,从而更好地获取修复痕迹特征。现有的取证算法中有许多增强修复和篡改痕迹的方法,其中较为常见的是空域隐富模型(spatial rich model, SRM)[20]。它在隐写分析领域取得良好的效果后,被广泛应用于图像篡改取证领域中[21-23]。文献[24]提出的约束卷积类似于文献[18]使用的空间域高通滤波,对获取篡改痕迹具有积极作用。文献[25]通过引入频域信息以帮助网络定位人脸图像的篡改区域。文献[26]证明了离散小波变换有助于篡改痕迹的获取。
然而,利用上述单一的增强痕迹的方法很难学习到数据的多种特征和底层结构,导致取证网络的性能不够理想。针对这一问题,本文借鉴集成学习[27]的思想提出采用多种痕迹增强的方法用于预处理,将输入的RGB图像扩展到多输入,极大增加了网络对修复痕迹特征的提取能力。
虽然深度修复在视觉上残留的痕迹难以识别,但是在修复区域的形成过程中不可避免地会出现边缘不自然和纹理不连续的现象。因此,RGB图像被直接用于检测视觉的修复痕迹。此外,为了抑制图像内容的影响,在实验测试了已有的增强修复和篡改痕迹的方法后,选择采用SRM滤波、空间域高通滤波和频率域高通滤波3种操作处理图像作为不同的输入:
1)SRM滤波:SRM滤波后的特征图强调的是局部噪声特征[22]。它帮助网络更加关注篡改操作遗留的噪声信息,而忽略语义信息,针对边界不明显和细节纹理丰富[5]的情况可以揭示出视觉不可见的修复痕迹。如图2所示,采用文献[22]选取的3个SRM滤波核作为卷积核,将3通道RGB图像映射到3通道的噪声特征图,得到X1∈RH×W×3。式中,H和W分别为特征图或图像的高度和宽度。

图2 3个SRM滤波核Fig.2 Three SRM filter kernels
2)空间域高通滤波:深度修复侧重于生成逼真的图像内容,却不能模仿原始图像中固有的不易察觉的高频信息[18]。因此,高通滤波能够揭示修复篡改后图像的异常特征,在一定程度上解决视觉差异不明显的问题。如图3所示,采用文献[18]初始化权重的3个高通滤波核作为卷积核,将RGB图像映射到3通道的残差特征图X2∈RH×W×3。其中,卷积核参数设置为可学习的。

图3 初始化的高通滤波核Fig.3 Initialized high-pass filter kernels

(1)
式中:DCT(·)为DCT变换,IDCT(·)为DCT反变换,α∈RH×W×1为低频部分掩膜,⊗为元素相乘。如图4所示,由于DCT变换后的频域图像的低频分量位于左上角,将按照zig-zag顺序前1/18的频率点去除,即频域图像(图4(a))与低频掩膜(图4(b))点乘得到滤波后图像(图4(c))。图4(b)的黑色区域对应低频部分,设置为0,其余白色区域为1。

图4 去除低频信息Fig.4 Removing low-frequency information
2 取证网络模型架构
如图1所示,本文提出基于CNN的图像修复取证网络,实现对篡改区域的定位预测。由于编码器-解码器网络架构在图像语义分割等低级视觉任务中取得了极大的成功,DF3Net也采用编码器-解码器结构作为取证网络的基本框架。
2.1 动态特征融合编码器
2.1.1 动态特征融合
如图1所示,RGB图像和对其不同操作得到的3种3通道特征图作为4组输入,采用基本卷积块将其均映射到32通道特征图。基本卷积块是由2个连续的卷积单元组成。卷积单元结构设置依次为1个卷积层,1个批量归一化(batch normalization,BN)[28]层和1个ReLU激活函数。其中,卷积层的卷积核大小为3×3,步长为1。文中提到的基本卷积块默认为该卷积块设置。
由于不同的特征图反映了深度修复操作在不同方向和领域的遗留痕迹。为了能够充分结合多种有效的修复痕迹特征的优势,先将4组32通道特征图进行通道维度堆叠,再通过动态卷积[19]将特征图压缩到32通道,得到融合后的特征图Fr∈RH×W×32。其中,动态卷积的并行卷积核数设置为3,卷积核大小为3×3。动态卷积利用通道注意力机制[29]为多个并行的卷积核赋予权重后进行聚合。这种以非线性形式聚合多个卷积核的方式,可以实现对不同的特征图自适应的调整卷积参数,更好地对特征图进行加权和融合,极大地提升了网络的鲁棒性与取证性能。整个过程可以表示为
Fr=PyConv(Conv(X0)⊕Conv(X1)⊕
Conv(X2)⊕Conv(X3)
(2)
式中:X0∈RH×W×3为输入的RGB图像,PyConv(·)为基本卷积块操作,Conv(·)为基本卷积块操作,⊕为通道维的堆叠操作。
2.1.2 编码器主体部分
如图1所示,除DFF和MFE外,编码器主体部分由下采样模块、基本卷积块组成。下采样模块通过步长为2的最大池化操作实现,可以有效减小特征图的尺寸,减少后续计算复杂度。基本卷积块的作用是对特征图提取修复篡改特征。通过DFF得到特征图Fr后,编码器对其依次采取下采样和基本卷积块操作,重复相同过程3次,在1/2、1/4与1/8输入图像尺度下输出的特征图通道数分别为64、128和256。
2.1.3 多尺度特征提取
由于篡改区域的尺度具有不确定性,为了解决网络的局部感受野引起的上下文信息不足,提高全局的分类精度,本文在编码器末端提出了MFE以更好地提取局部和全局的上下文信息,即获取到特征图中不同范围大小的邻域信息。如图5所示,该模块由3个部分构成。
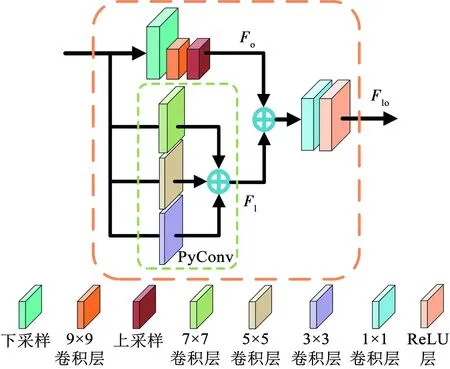
图5 多尺度特征提取模块结构Fig.5 Architecture of multi-scale feature extraction module
1)局部特征提取部分:该部分引入由3个不同大小卷积核的卷积层并行组成的金字塔卷积(pyramidal convolution, PyConv)[30],卷积核大小从上到下分别设置为7×7、5×5和3×3,对应的特征分组数分别为1、4和8,输出特征图通道数分别为输入特征图通道数的1/2、1/4和1/4。最终将3层输出特征图进行通道维度堆叠,实现了局部特征的多尺度上下文信息的聚合,得到局部特征图Fl∈RH×W×256。此外,PyConv在增大卷积核的同时减小了深度,因此不会增加额外的计算成本。
2)全局特征提取部分:为了确保可以获取完整的全局特征,本文在保持合理的空间分辨率的前提下采用自适应平均池化,将输入特征图的空间大小减少到9×9。然后,利用卷积核大小为9×9的卷积层提取特征。最后,使用双线性插值的方法将其映射回初始大小,得到全局特征图Fo∈RH×W×256。
3)局部和全局特征融合:将得到的局部特征和全局特征采用通道维度堆叠后,应用卷积核大小为1×1的卷积层融合不同尺度的信息。在最后增加ReLU激活函数,以有益于网络训练。该过程可以表示为
Flo=δ(Conv1×1(Fl⊕Fo))
(3)
式中:Flo∈RH×W×256为局部特征与全局特征融合后的特征图,δ(·)为ReLU激活函数,Conv1×1(·)为卷积核大小为1×1的卷积操作。
2.1.4 编码器特征可视化
图6展示了编码器中的DFF(图6(a))和MFE(图6(b))的特征可视化图。可视化是通过特征图同一个空间位置在通道维度相加得到的,下文中可视化处理均为该操作方式。图6(a)中RGB特征(1行3列)、SRM特征(2行1列)、空域高通特征(2行2列)和频域高通特征(2行3列)可视化图的差异说明利用多输入提取到的4组特征图反映了深度修复操作在不同方向和领域的痕迹信息。对比真实标签(1行1列)和其他可视化图,对于该幅给定图像,SRM特征(2行1列)和频域高通特征(2行3列)反映了较多的修复篡改痕迹,而动态融合特征(1行2列)揭示的篡改区域的痕迹是最明显的。这证明DFF有效融合了多种痕迹特征的优势,并获取到更优异的篡改痕迹特征。对比图6(b)的真实标签(第4列)和MFE的特征(第1~3列,从1/8图像尺度放大到1图像尺度)可以看出,局部特征(第2列)反映了篡改区域的大致定位,融合全局特征(第1列)后获取到的融合特征(第3列)进一步明确了篡改区域的位置和形状。

图6 编码器特征图可视化Fig.6 Encoder feature visualization
2.2 基于注意力的解码器
2.2.1 解码器主体部分
如图1所示,解码器主体部分由上采样模块、基本卷积块、卷积层和Softmax层组成。在本文中,上采样模块采用步长为2的转置卷积[31]将特征图逐步还原到原图大小。基本卷积块的作用是加强对篡改区域的特征表达。首先,解码器对MFE得到的特征图采取3次上采样操作,每次上采样后堆叠跳连部分得到的加权特征图,并插入基本卷积块操作。在1/4、1/2与1输入图像尺度下输出的特征图通道数分别设置为128、64和32。然后,通过卷积核大小为1×1的卷积层将32通道的特征图映射到两通道得到S∈RH×W×2。最终,利用Softmax分类器对其进行归一化得到输出Y∈RH×W×2:
(4)
式中Ykij和Skij分别为Y和S第k维通道在坐标(i,j)处的元素值。根据Ykij在两通道对应位置大小进行分类得到取证结果。
2.2.2 基于SWCA的跳跃连接
对于卷积和下采样操作引入的篡改区域细节损失,编、解码器之间增加跳跃连接能够有效地补充损失的细节信息。跳跃连接的主要形式之一是将编码器与对应解码器中的特征图堆叠后进行后续处理。虽然采取这种方法达到了细节补充的效果,但是该方法平等地对待所有补充的特征,引入了许多无用信息,限制了网络的特征表达能力。
针对以上问题,本文采用跳连操作重用分辨率高的低层语义信息。同时,考虑到不同层次、不同通道的特征的重要性不同,本文在跳连部分引入了空间和通道两个维度的注意力机制,提出了基于SWCA的跳跃连接。如图7所示,该过程分为4个步骤:

图7 空间加权的通道注意力模块结构Fig.7 Architecture of spatially weighted channel attention module
1)特征的初步提取:通过卷积核大小为3×3,步长为1的卷积层和ReLU激活函数对补充的编码器特征图Fe∈RH×W×C进行初步的特征提取,得到Fp∈RH×W×C。式中C为特征图的通道数。
2)空间位置加权:将初步提取的特征图Fp利用跨通道的平均池化和跨通道的最大池化操作[32]得到两个单通道特征图,堆叠后采用卷积核大小为3×3,步长为1的卷积层和Sigmod激活函数获取到空间权值图β∈RH×W×1。同时,采用卷积核大小为3×3,步长为1的卷积层将Fp映射为Fq∈RH×W×C。然后,对Fq空间位置加权得到Fs=β⊗Fq。其中,元素相乘过程中复制权值图与特征图保持相同维度。
3)通道维度加权:将空间加权的特征图Fs∈RH×W×C通过文献[29]提出的通道注意力机制计算得到通道权值图γ∈RH×W×1,对Fq通道加权获取到输出特征图Fc=γ⊗Fq。其中,通道注意力结构设置依次为1个全局最大池化层,2个全连接层间插入1个ReLU层,1个Sigmod层。
4)特征增强:对空间和通道加权后的特征图Fc∈RH×W×C与解码器中对应尺度的特征图Fd∈RH×W×C采用堆叠操作,得到增强后的特征图Fcd∈RH×W×2C:
Fcd=Fc⊕Fd=
(γ⊗Fq)⊕Fd=
(γ⊗Conv3×3(Fp))⊕Fd=
(γ⊗Conv3×3(δ(Conv3×3(Fe))))⊕Fd
(5)
式中Conv3×3(·)为卷积核大小为3×3,步长为1的卷积操作。
2.2.3 解码器特征可视化
图8(a)和(b)分别展示了解码器中SWCA和主体部分的特征可视化。图8(a)以原图像尺度的基于SWCA的跳跃连接为例,对比真实标签(1行4列),初步提取特征(1行1列)能够反映大部分篡改区域的痕迹,但是存在较多空洞区域和边界模糊的情况。通过空间注意力机制的平均池化(2行1列)和最大池化(2行2列)突出有效信息后,得到空间加权特征(1行2列)。可以看出相较于初步提取特征,空间加权特征显示的篡改区域消除了部分空洞现象,矩形篡改区域的左侧和右侧边界变得更加清晰。再利用通道注意力机制(2行3列,通过放大得到)加权获取到空间加权的通道注意力特征(1行3列),矩形篡改区域在保持左右侧边界清晰的基础上,下侧边界附近的空洞区域也减少。这证明SWCA的空间注意力和通道注意力均起到了加强特征的作用。

图8 解码器特征可视化Fig.8 Decoder feature visualization
图8(b)展示了解码器主体部分的特征可视化图。对比真实标签(2行4列)和解码器在3个不同图像尺度(1/4、1/2和1)下的跳连前特征(1行1~3列)以及对应的跳连后特征(2行1~3列)可以看出,随着尺度的增大,解码器逐步解码获取到更准确的篡改区域的形状和位置。此外,在1图像尺度下跳连前特征(1行3列)融合SWCA得到的空间加权的通道注意力特征(1行4列)得到跳连后特征(2行3列),明显看出跳连后特征比跳连前特征可以更清晰地反映篡改区域,有效增强了篡改区域的边界细节。对比其他尺度下可以得到相同的结论。因此,引入SWCA的跳跃连接实现了有侧重地编码器特征补充,减少了无用信息的影响,使得解码器获取到其所需要的增强信息,达到了更好的边界细节补充效果。
2.3 损失函数
由于取证问题本质上是计算机视觉中的分割问题,最常见的损失函数是标准交叉熵损失。但是一般情况下,目标图像中的篡改区域(正样本)比未篡改区域(负样本)要小得多,这将导致正负样本的不平衡。如果用标准交叉熵损失来监督网络的训练,占主导地位的负样本会贡献大部分的损失。网络模型会严重偏向负样本,导致对篡改区域分类效果较差,取证性能不佳的结果。
为了减轻类别不平衡的影响,同时减少计算量,提升模型的训练速度,本文采用加权交叉熵对输出结果的逐个像素点进行监督。损失函数可以表示为
ω2(1-Jij)log(1-Ykij)
(6)
式中:ω1和ω2分别为正样本和负样本的权重因子,Jij为one-hot标签(i,j)处的像素值,只有1和0两种取值,分别为篡改区域和非篡改区域。
3 实验结果
为了检验所提出网络的取证性能,本文利用多种深度修复方法获取实验数据集,并且将本文方法的取证结果和最先进的相关算法进行主观与客观的对比分析。同时,通过设置消融实验以证明网络不同组件的有效性。此外,将该模型应用于抗JPEG压缩和噪声攻击的实验以检验其鲁棒性。
3.1 图像数据集
首先,在Place2数据集[33]中随机选取了19 350张256×256大小的彩色图像。然后,选择具有代表性的3种深度图像修复方案,分别是方案一(contextual attention,CA)[16],方案二(globally and locally consistent,GLC)[10]和方案三(pyramid-context encoder network,PEN)[11]。利用它们训练好的网络模型分别对每幅图像进行修复篡改操作,共得到19 350×3幅修复后的图像。篡改区域的形状有圆形、矩形和不规则形状,篡改区域的面积与图像面积之比设置为1%、5%和10%。每种参数情况对应的被操作图像个数是一致的,篡改位置是随机选取的。最后,随机选择18 000×3张修复篡改后的图像作为训练集,450×3张图像作为验证集和900×3张图像作为测试集。图9为按上述规则获取到的待修复图像样本。其中,图中绿色掩膜为待修复区域。

图9 不同修复区域的图像样本Fig.9 Image samples of different inpainting regions
3.2 训练细节
本文所提出方法基于PyTorch框架实现,在Ubuntu环境下使用 NVIDIA 1 080 Ti GPU完成模型的训练和测试。在网络训练时,初始学习率设置为0.001,批尺寸设置为8,采用动量衰减指数β1=0.9,β2=0.999的ADAM优化器对模型进行优化。迭代次数为50次,学习率每10次迭代衰减为之前的0.75。权重因子ω1和ω2分别设置为5和1。为了评估所提出方法的取证性能,本文采用现有的两种取证网络进行了对比实验,包括文献[1]提出的编、解码器结构的CNN和文献[18]提出的深度修复取证网络。此外,典型的语义分割算法DeepLabv3+[34]也被用作对比方案之一。其中,对比方案[18]采用该方案提出文献提供的训练方式,而方案[1]和DeepLabv3+算法均采用和本文相同的训练方式。
本文采用以下4种评价指标进行取证性能评估:F1分数,交并比(intersection over union, IoU),真阳率(true positive rate, TPR)和假阳率(false positive rate, FPR)。下文中的实验结果数据均为在测试集上测试的平均值。此外,F1分数、IoU、TPR和FPR分别表示如下:
(7)
(8)
(9)
(10)
3.3 性能比较
图10展示了不同方案对深度修复方案CA修复篡改的6幅图像样本的修复取证结果。对比图像修复取证方案的定位结果(图10(c)~(f))和真实篡改区域(图10(b))可以看出,每一种方案均能够在一定程度上定位目标图像的篡改区域。对于面积较大的(如图10第3和6行)或者规则的(圆形和矩形)篡改区域样本(如图10第1和2行),不同的方案均具有相对较好的检测性能。但是对于面积较小的不规则篡改区域的样本(如图10第4行),即取证难度较大的一类样本。对比方案[1](图10(c))对篡改区域产生了漏检,DeepLabv3+(图10(d))则是完全的误检,方案[18](图10(e))也产生了较大范围的误检。然而,本文方法(图10(f))仍能够相当准确地定位篡改区域。综合来说,所提出方法(图10(f))不仅在输出结果上有极少的虚警像素,还能在位置和形状上更好地拟合真实的篡改区域。而其余对比方案(图10(c)~(e))的定位结果均具有不同程度的形状失真现象。由此可见,本文所提出的取证网络能够更有效地提取修复痕迹特征,对于不同篡改区域形状和面积的变化具有很强的鲁棒性。

图10 针对CA的不同方案的定性比较Fig.10 Qualitative comparison of different methods for CA
表1和表2为各种方法的定量对比结果。以不规则篡改区域的样本为例,可以观察到,当篡改区域面积占比为10%时,本文所提出方法达到最高的98.99%的F1分数,98.01%的IoU(表1第11列)以及99.39%的TPR(表2第11列)。虽然随着篡改区域面积的减小,网络的取证性能略有下降,但是仍在篡改区域面积占比为1%时分别取得了96.55%、93.38%(表1第9列)和98.87%(表2第9列)的良好结果。性能下降的原因可能是更小的篡改面积导致修复操作特征不显著。同时,所提出方法的FPR指标也保持着极低的数值,最大值为0.16%(表2第1列),可见误警率极小,并且会随着篡改区域面积的减小得到略微改善。对于圆形或矩形篡改区域的测试图像,各项指标也得到了类似的结果。其他对比方案也具有相似的趋势变化规律,但是相较于本文方法取证性能均下降很多。以IoU指标为例,所提出方法在900张整体测试集上比方案[1]、DeepLabv3+和方案[18]分别高出19.82%、15.12%和26.29%(表1第12列)。总体来说,对于各种形状和面积的篡改区域,本文方法在各项指标中都获得了明显优于其他对比方案的测试结果。

表1 针对CA不同方案的F1和IoU比较Tab.1 Comparison of F1 and IoU of different methods for CA %
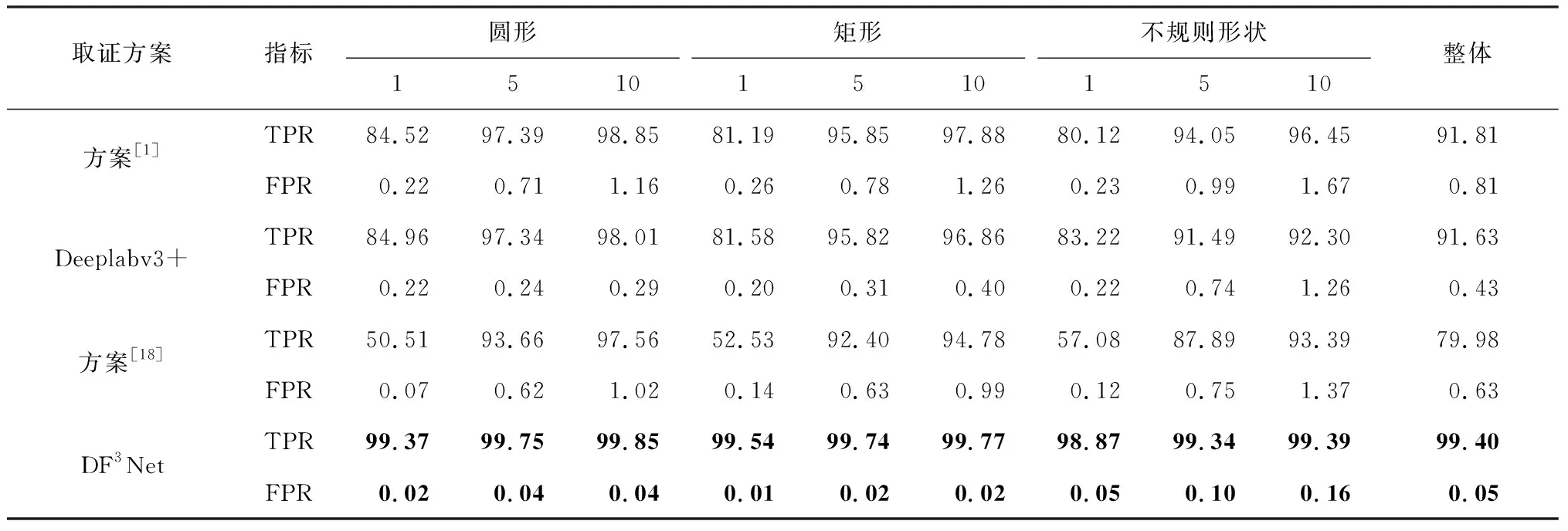
表2 针对CA不同方案的TPR和FPR比较Tab.2 Comparison of TPR and FPR of different methods for CA %
特别要指出的是,对于取证难度更大的小尺寸篡改区域,所提出方法相较于对比方案具有更显著的优势。以IoU指标为例,本文方法对于篡改区域面积占比为1%的圆形、矩形和不规则样本较次优方案分别高出27.31%、29.84%和24.58%(表1第3、6、9列),说明所提出方法能更好地针对困难样本。此外,根据各项指标的统计结果显示,对于圆形和矩形篡改区域样本的取证性能接近,但是对于规则篡改区域样本的取证性能优于不规则篡改区域样本。这可能是因为不规则区域的边界细节信息更丰富,而卷积和降采样操作会丢失更多细节信息导致的。
3.4 针对其他典型修复方案的取证性能测试
本文进一步在整体测试集上测试了所提出方法面对另外两种深度修复方案GLC和PEN的取证性能,实验结果见表3和表4。相较于在深度修复方案CA上的实验结果,本文方法对于GLC的测试结果是更优异的,而面对PEN各项性能指标则是均有所下降的。以IoU指标为例,在修复方法CA、GLC和PEN上分别达到98.12%、99.21%和84.23%。这是由于取证网络对不同修复操作形成的篡改区域的敏感性是有差异的。但是,面对这两种修复方法,所提出方案对于FPR、F1分数和IoU指标性能也均明显优于其他对比方案。同时,FPR也保持着较低的水平。综上所述,面对不同的深度修复方法,本文方法均优于其他对比方案,达到令人满意的取证检测性能。

表3 针对GLC不同方案的性能比较Tab.3 Performance comparison of different methods for GLC %

表4 针对PEN不同方案的性能比较Tab.4 Performance comparison of different methods for PEN %
3.5 在更多数据库上的取证性能测试
为了进一步测试网络模型在更多数据库上的取证性能,本文在CELEBA[35]、DTD[36]和ImageNet[37]数据库上随机各选取了900张图像,并以PEN修复方法为例建立了3个测试集。表5为直接使用在Place2数据集上训练好的模型的测试结果。可以看出,相对于模型在Place2数据库上取得的最佳的实验结果,各项指标除了在DTD数据库上有小幅度下降以外,在其他数据库上基本不变,均保持着很高的性能水平。这证明面对不同的图像数据库,本文所提出的网络仍然具有很好的取证性能。

表5 针对PEN在不同数据集的测试结果Tab.5 Results for PEN on different datasets %
3.6 鲁棒性评估
JPEG图像压缩作为最常见的图像处理操作之一被广泛使用。为此,对根据CA得到原始数据集分别进行压缩因子为95、85和75的JPEG压缩。不同方案与前文各自的训练方式保持一致,将训练好的网络模型在篡改区域面积占比不小于5%的图像测试集上的测试结果见图11。可以观察到,随着压缩因子的减小,所有方案都有着不同程度的性能下降。JPEG压缩因子的减小代表更多的修复操作信息被移除,必然导致取证性能的下降。但是,所提出方法在不同的压缩因子下始终明显优于其他方案,说明其具有更佳的抗JPEG压缩性能。

图11 针对CA在不同JPEG压缩因子下的IoU指标Fig.11 IoU for CA with different JPEG quality factor
增加噪声作为一种修复篡改图像的常见后处理操作,常被用于对抗取证方案的检测。在JPEG压缩因子为75的条件下进行加噪测试,通过在测试集上增加信噪比分别为50、40 dB和30 dB的高斯白噪声获取到加噪测试集。表6为直接使用训练好的不同的网络模型的测试结果。可以看出,随着信噪比的减小即增加更多的噪声,所提出方案的IoU指标在加噪50、40 dB时基本保持不变甚至有略微上升,而在30 dB时不同指标均有小幅度的下降,其他方案趋势变化类似。同时,DF3Net的取证性能始终明显优于其他对比方案。综上所述,证明所提出方法具有很强的抗噪声攻击的能力。

表6 针对CA在不同噪声下的IoU指标Tab.6 IoU for CA with different noise
3.7 消融实验
本文设计了如下两组消融实验对所提出模型各个组件的有效性进行验证:一组实验设置为在本文完整网络模型(full model,FM)上分别去除RGB信息(removing RGB information,RR)、SRM滤波(removing SRM filtering,RS)、空间域高通滤波(removing high-pass filtering of spatial domain,RHPS)、频域高通滤波(removing high-pass filtering of frequency domain,RHPF)以及利用普通卷积代替动态卷积(convolution instead of dynamic convolution,CIDC)。表7为在修复方案CA上得到的F1分数和IoU结果,相较于完整网络FM,去除DFF中的任何一个输入以及普通卷积替换动态卷积,都会引起指标F1和IoU不同程度的下降。其中下降最明显的是去除频域高通滤波的网络RHPF,F1和IoU指标分别降低了1.71%和3.22%。这说明,通过采用多输入特征和动态特征融合模块,不同的特征在相应的领域均发挥了积极作用,提取到更有效的修复痕迹特征,从而大大提升了取证性能。
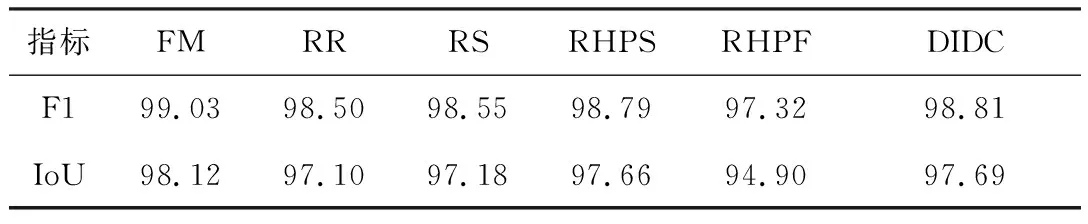
表7 消融实验(针对CA): 组件有效性研究一Tab.7 Ablation experiments(CA):component validity study Ⅰ %
另一组实验设置为:仅带有DFF的网络模型(model with DFF, MD)、带有DFF和MFE的网络模型(model with DFF and MFE, MDM)和带有DFF和引入SWCA的跳跃连接的网络模型(model with DFF and skip connection introduced SWCA, MDS)。表8为面对修复方案CA的取证结果,相较于模型MD,引入MFE的模型MDM和增加基于SWCA的跳跃连接的MDS在IoU 和F1分数均有着不同程度的改进,综合使用两者的完整模型则有着更大的提升。以IoU为例,MDM、MDS和FM较MD分别提升了0.52%、2.17%和2.74%。因此,MFE和引入SWCA的跳跃连接均能够有效提升取证网络的性能。

表8 消融实验(针对CA): 组件有效性研究二Tab.8 Ablation experiments(CA):component validity study Ⅱ %
4 结 论
本文提出了一种基于动态特征融合的深度修复取证网络DF3Net。该网络针对深度修复遗留的细微特征扩展输入后,利用DFF使得多种有效的痕迹特征得以被充分地获取到。此外,为进一步提升取证性能,编码器通过增加MFE以更好地获取上下文信息,解码器引入基于SWCA的跳跃连接以实现细节信息的针对性补充。实验结果表明,本文提出的取证网络对比现有方法均取得较优性能,同时面对JPEG压缩和噪声攻击具有较强的鲁棒性。
