基于FA-SVM 模型的陕西省物流需求预测研究
2022-07-13马佳玉
詹 芸,马佳玉,张 陵
(1. 西安汽车职业大学,陕西 临潼 710038;2. 西安交通大学,陕西 西安 710048)
0 引 言
“一带一路”战略使陕西成为中国向西开放的中心区域和重要节点,陕西省物流枢纽地位重要性日益凸显,物流需求预测在物流发展规划、物流资源整合等方面发挥着重要作用。物流与各影响因素之间表现为隐含的、错综复杂的非线性数学映射关系,物流需求的预测涉及数据统计技术、计算机技术等,因此建立可靠、高效及精准的陕西省物流需求预测模型面临巨大的挑战。
目前,研究学者构建物流需求预测模型的方法主要分为传统预测方法和现代预测方法。传统预测方法主要包括增长率法、指数平滑法、差分自回归移动平均法等,其中增长率法、指数平滑法默认物流发展为稳定的增长态势,无法准确预测发展趋势多变的短期物流需求,差分自回归移动平均法仅可以建立物流与各影响因素之间的线性关系,预测效果存在偏差。现代预测方法主要包括灰色预测模型、神经网络、支持向量机(SVM)等方法,可以建立物流需求与各影响因素之间的非映射关系,预测效果更为准确。相较于SVM 模型,灰色预测模型、神经网络方法本身理论架构存在不足,模型在初始阶段状态产生误差。SVM 模型以结构风险最小作为算法准则,在小样本、非线性的物流需求预测中表现出良好的适应性。然而传统的SVM 模型在处理高重叠、高纬度的样本数据时,计算速度与效果都会受到影响,整合样本数据、降低数据维度是提高SVM 模型预测效率与准确性的重要步骤。
1 相关理论
1.1 因子分析模型(FA)。因子分析是当前较为常用的多变量统计方法,研究变量间的相互依赖关系,把错综复杂及紧密联系的变量综合成少数公因子的统计方法。基于降维的理念,确保指标信息不丢失的前提下,用较少的公因子指标取代诸多原始指标,使原始的指标体系结构更加简洁易操作,有利于后期指标体系综合评价分析。
因子分析的原理就是把每个研究变量分解成两部分因素,一部分由为代表全部变量共同特征的少数几个公因子F 组成,另一部分是每个变量独自具有的特征,即特殊因子ε。因子分析模型如式(1)。

通过定义核函数K (xx)=φ (x)·φ (x)(φ (x)为非线性函数),将样本数据变换到高维空间进行线性回归,在实际应用过程中,将非线性回归函数转化为其对偶问题进行求解。
2 FA-SVM 的区域物流需求预测模型构建
在进行物流需求预测时,影响预测效率及准确性的因素众多,影响多为非线性、随机性的,同时样本数据维度过高,单一预测模型预测效率低、结果稳定性差。由于FA 模型可以对物流的样本数据进行整合、降低样本维度,SVM 预测模型又可以表征物流需求的非线性、随机性;故此,为了解决物流需求预测模型中的难题,本文提出了FA-SVM 模型,首先构建多影响因素下陕西省物流需求指标体系,并采用因子分析方法(FA) 对数据样本进行降维处理,选取累计贡献度较高的指标,用于反映需求量变化情况;其次采用SVM 模型对2010~2017 年的陕西省物流数据进行训练,确定核函数,用2008~2009 年数据进行模型修正,2018 年数据进行过模型验证;最后对2019~2020 年的陕西省物流需求情况进行预测,具体过程如图1 所示。
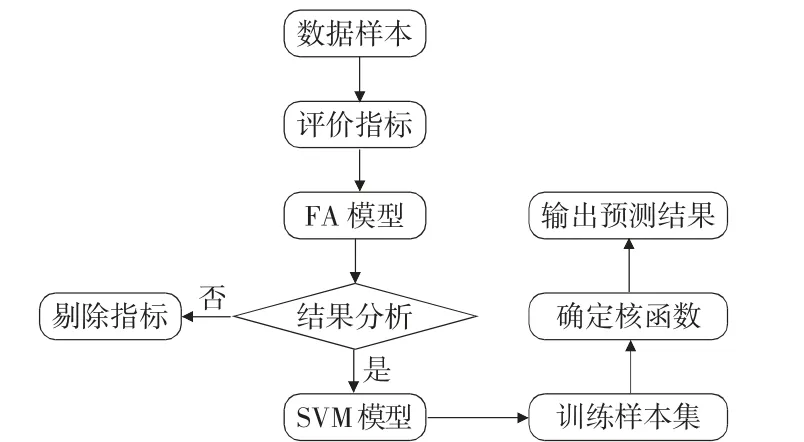
图1 FA-SVM 的物流需求预测流程
3 陕西省物流需求的预测研究
从陕西省的经济水平、贸易水平、服务供给水平3 个角度选取影响因素。对选取影响指标进行收集整理,得到物流需求量指标体系如表1 所示。

表1 物流需求量指标体系图
3.1 区域物流需求指标体系构建。本文中涉及到的数据主要来源于陕西省2008~2018 年相关部门统计年鉴以及国家统计局公布数据,如图2 所示。

图2 2008~2018 年物流需求量指标变化图
使用SPSS 软件对区域物流需求量指标体系进行因子分析,得到KMO 和巴特利特检验结果、初始值为1 的X~X指标累计贡献率,如表2、表3 所示。

表2 KMO 和巴特利特检验

表3 累计贡献率
由表2 可知,KMO=0.63>0.5,说明所选指标关联性强,且巴特利特球形度检验Sig.<0.01,证明各指标相关系数矩阵不为单位矩阵,各指标间存在关联性。由表3 可知,X~X均与Y、Y有密切相关性,其中X、X、X、X、X、X、X对研究对象的累计贡献率达到94%,X、X的累计贡献达到70%,证明所选取的指标可靠有效,数据质量较好,构建区域物流需求指标体系,可用于反映需求量变化情况。
3.2 SVM 模型参数及适用性评价。将陕西省各物流需求影响因素作为模型的输入量,分别以客流量、货流量作为输出,在训练和预测过程中,确定本次SVM 模型的约束函数及核函数,以2010~2017 年预测结果的误差(均方根误差、平均绝对误差)作为评价预测效果的标准。
通过多次训练验证,确定核函数为径向基核函数(RBF Kernel),相关参数表4。其中Kernel Scale 为SVM 模型参数Sigma,即“内核宽度”,该参数为径向基核函数的主要表征参数,表明模型核函数选取准确;R均大于98%,表明模型拟合效果较好。

表4 SVM 模型核函数参数表
经过SVM 模型处理后,得到2010~2017 年货运量及客运量的预测结果,如图3、图4 所示。
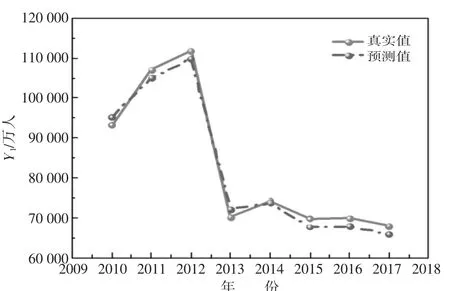
图3 客运量预测结果拟合图
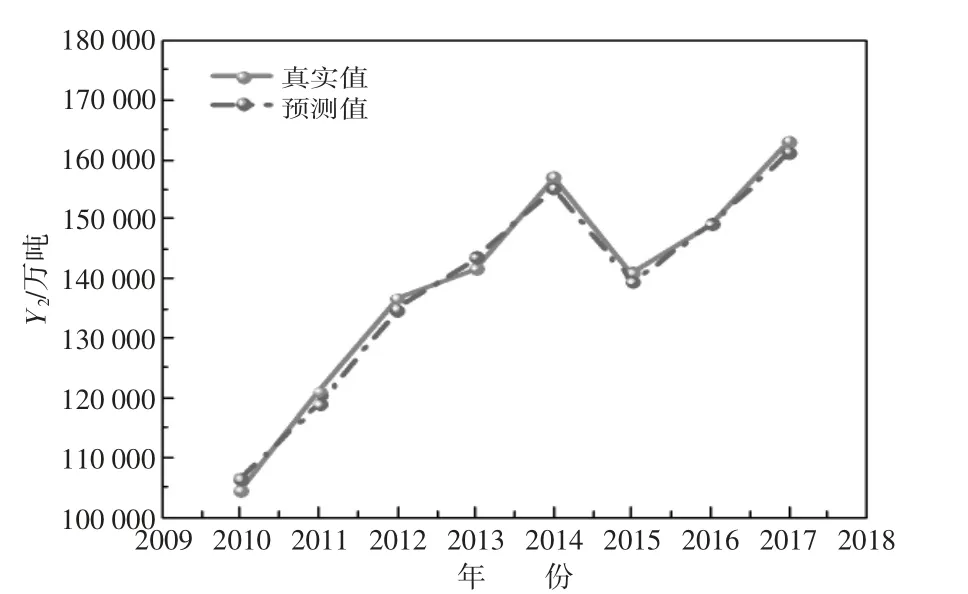
图4 货运量预测结果拟合图
从客运量、货运量预测图来看,预测模型拟合程度高,变化趋势表征明显,证明本文研究对象的影响因素指标选取得当,能够很好地反映客、货运量的变化趋势。在后续对本地区物流发展情况进行研究时,可根据不同领域影响因素指标的重要程度着手调节管控,从而提高区域物流水平。
根据表5 SVM 模型得出的预测结果与真实值的误差分析可得,Y货运量、Y客运量的MAPE 分别为2.23%、1.21%,表明预测值与真实值之间误差极小,模型选取合适。

表5 预测结果误差表
3.3 FA-SVM 模型在陕西省物流预测中的应用。依据FA-SVM 的区域物流需求预测模型,对2018~2020 年陕西省货运量Y及客运量Y进行预测,预测结果与实际值如表6 所示。2018 年Y、Y预测值与实际值的误差分别为3.85%、2.83%,2019 年Y、Y预测值与实际值的误差分别为6.39%、5.46%,预测效果整体较为准确;2020 年Y、Y实际值较模型预测发展趋势差异较大,主要原因为新冠疫情严重降低了国内人员及货物的流动性、国际航运和进出口冷链产品的货运量。

表6 区域物流预测结果与实际值对比
随着疫情防控形势的好转,疫情所带来的影响会逐渐削弱,陕西省的货运量及客运量仍将保持增长趋势,建立稳定高效的应急物流服务体系将为物流业的发展提供可靠保障。
4 结 论
本文提出了一种“FA-SVM”新模型,并对陕西省近年物流需求展开了预测、分析和研究,主要得出以下结论:(1) 构建了经济水平、贸易水平、服务供给水平三方面的陕西省区域物流需求量指标体系,通过因子分析发现地区生产总值(X)、物流业增加值(X)、物流业固定资产投资额(X)、区域消费零售总额(X)、区域进出口总额(X)、区域货运周转量(X)、区域旅客周转量(X)等指标对陕西省物流需求的累计贡献率高于94%,区域邮电业务量(X)、物流从业人数(X)等指标对陕西省物流需求的累计贡献率高于71%,指标选取恰当,能够反映区域物流变化趋势特点。(2) 获取整理了陕西省区域物流量数据集,将其应用于FA-SVM 模型的训练、修正、验证及使用,确定支持向量机模型的核函数为RBF Kernel,得到关于客运量(Y)、货运量(Y)的R和MAPE 分别为0.9879 和0.9924、2.23%和1.21%,拟合效果优秀,模型选取恰当。(3) 运用FA-SVM 模型对2018~2019 年区域物流需求进行预测分析,得到2018 年客运量(Y)、货运量(Y)预测值与实际值的误差分别为3.85%、2.83%,2019年客运量(Y)、货运量(Y)预测值与实际值的误差分别为6.39%、5.46%。(4) FA-SVM 的区域物流需求预测模型有效改善了预测效率及精度,其对陕西省物流需求的预测结果良好,也为其他省市的物流需求预测提供了一种行之有效的途径。
