我国劳动力人口多维相对贫困测度及影响因素分析
2022-07-12左宇晓卜津月
左宇晓 卜津月
(郑州大学 商学院,河南 郑州 450001)
一、引言及文献综述
全面建成小康社会之后,我国贫困问题并未结束,相对贫困还会长期存在。如何识别并测度相对贫困,找出影响相对贫困的因素,确保脱贫的高效性及可持续性,是现阶段及未来必须关注的重要问题。
基于阿马蒂亚·森的可行能力理论,Sabina和James(2011)提出了贫困识别、加总和分解的多维贫困测度方法,简称A-F法,并给出了A-F的一般模型[1]。联合国开发计划署与牛津贫困与人类发展项目联合发布了以A-F模型为基础的全球多维贫困指数MPI,替代了联合国开发计划署之前的人类贫困指数HPI,MPI包含了教育、健康和生活条件3个维度。国内大多数文献基于A-F法对多维贫困进行测度,王小林和Sabina(2009)利用A-F模型对我国农村和城市进行了多维贫困测量[2]。吕文慧和苏华山等(2018)利用中国家庭追踪调查数据,基于A-F模型构建农村留守儿童多维贫困指标,对农村留守儿童的多维贫困状况进行分析[3]。黄森慰和蒋畅等(2019)依据A-F模型,从健康、教育、住房、耐用消费品、饮用水等11个维度对贫困妇女进行多维贫困测量[4]。姚兴安和朱萌君等(2021)采用A-F模型分别对我国东部、中部和西部地区农村家庭的多维相对贫困指标进行测量和比较分析[5]。
影响多维相对贫困的因素有多种,学者们大多采用计量经济模型对多维相对贫困影响因素进行分析。邹薇和方迎风(2012)通过构造多层次计量模型,考察影响个体生活水平的因素以及导致我国农村区域性贫困陷阱的路径[6]。杨慧敏和罗庆等(2016)通过构建双变量Probit模型,从三个方面考察中国农村家庭贫困状况,并研究其动态特征变化[7]。
本文以我国劳动力人口为研究对象,以A-F模型为基础构建多维相对贫困分析模型,基于中国家庭追踪调查2010年、2014年和2018年的数据,分析我国劳动力人口的多维相对贫困状况,并分地区讨论。通过构建二元Logistic模型,对我国劳动力人口多维相对贫困影响因素进行分析。
二、多维相对贫困模型构建和数据选择
(一)多维相对贫困测量方法
A-F法测算多维贫困指数MPI的核心是通过双临界值识别多维贫困群体。具体步骤如下:
1.单维贫困识别。首先定义X=[xij]是一个n×d维的矩阵,xij表示个体 i在维度 j上的取值,i=1,2,…,n,j=1,2,…,d。假设zj(j=1,2,…,d)表示维度j上贫困剥夺临界值,Z=(z1,z2,…,zd),当个体 i在某个维度下的取值xij<zj时,表明该个体在这一维度上处于被剥夺的状态,赋值为1;反之赋值为0。据此可以得到不同个体的贫困矩阵具体形式可表示为:g0ij=。这是单维贫困的识别过程。
2.多维相对贫困识别。给不同的维度设置权重wj(0<wj<1),对一维贫困剥夺矩阵按照维度赋权之后得到加权贫困剥夺矩阵记 ci=为个体 i遭受剥夺后的加权总维度数(加权贫困值)。比较加权贫困值ci与多维贫困临界值k之间的关系,考察个体i是否处于多维相对贫困状态。当ci≥k时,个体i处于多维相对贫困状态,当ci<k时,个体i未处于多维相对贫困状态。
(二)数据来源与选择
本文数据来源于中国家庭追踪与调查(CFPS)。2014年1月国家出台扶贫工作意见,明确提出建立精准扶贫工作机制,因此本文选取具有代表性的2014年的数据,为了突出对比,又选取2010年和2018年的数据。采用stata14.0筛选16—50岁劳动力人口原始样本,由于数据库样本量较大,故本文对重要变量缺失值和异常值采取了直接删除的方法,得到2010年、2014年和2018年有效数据分为9971个、2355个和2988个。
三、多维相对贫困维度、指标、临界值和权重确定
(一)指标选取基础
首先,参考国际机构公布的贫困指数,如联合国提出的人类发展指数和牛津贫困与人类发展项目的MPI指数。其次,参考国内外学者在研究不同贫困对象时所选取的变量和维度。如王小林关于2020年后中国多维相对贫困标准的研究和张抗私关于当代青年工作贫困指标体系的构建。再次,由于研究对象是劳动力人口,所选指标必须与劳动力人口特质高度相关,才能对其生存和发展产生更大的影响。最后,构建出多维相对贫困测度指标体系。
(二)指标体系
根据以上分析,本文最终确定了5个维度的11个指标。具体见表1。
(三)权重确定
为避免因个人主观性带来的偏差,本文利用SPSS软件,选取客观赋权法中的主成分分析法对指标进行赋权。
根据不同的因子载荷系数测算出每个指标具体权重,并对各个指标进行标准化处理,结果见表2。
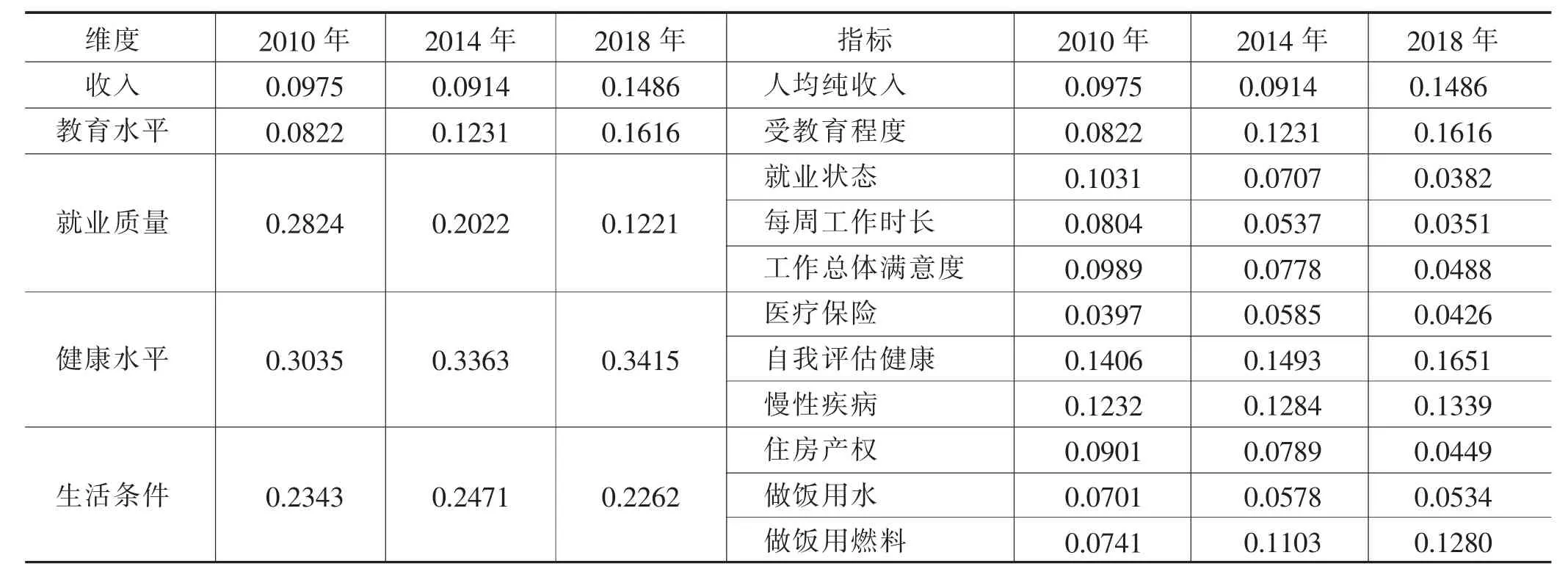
表2 各维度及指标权重
从表2可知,自我评估健康和慢性疾病2个指标所占的权重一直较大,说明健康水平对相对贫困的影响很大。从时间跨度看,人均纯收入、受教育程度和做饭用燃料3个指标的权重随时间的变化不断升高,说明人们开始更多地把目光聚焦在收入、受教育程度方面,在生活条件维度,也越来越重视清洁能源的使用。2010年,自我评估健康、慢性疾病和就业状态3个指标所占权重相对较大;2014年,自我评估健康、慢性疾病和受教育程度3个指标所占权重相对较大;2018年,自我评估健康、受教育程度和人均纯收入3个指标所占权重相对较大。出现次数最多的是自我评估健康、慢性疾病和受教育程度,说明健康和教育对相对贫困的影响较大。
四、多维相对贫困模型测量结果
本文利用A-F模型,采用2010年、2014年和2018年的CFPS数据对我国东部、中部、西部和东北部地区进行多维相对贫困的识别和测量。
(一)各指标贫困发生率测算
结合各指标的临界值,测算不同维度下的指标贫困发生率以及我国劳动力人口多维贫困发生率和多维贫困指数。
由表3可知,总体来看,2010年、2014年和2018年贫困发生率最高的3个指标依次分别是:每周工作时长、工作总体满意度和就业状态;每周工作时长、住房产权和受教育程度;每周工作时长、住房产权和工作总体满意度。每周工作时长每一年都是贫困发生率最高的指标,且在2010年,就业维度的3个指标是贫困发生率最高的3个指标。纵向看,2010—2018年,人均纯收入、受教育程度、就业状态、每周工作时长、工作总体满意度、医疗保险、自我评估健康、慢性疾病和做饭用燃料9个指标的贫困发生率均有所下降,其中人均纯收入、受教育程度、医疗保险、慢性疾病和做饭用燃料5个指标的贫困发生率一直呈下降趋势。就绝对变化来说,贫困发生率下降最多的是人均纯收入和就业状态2个指标,分别下降了23.4%和23.24%;慢性疾病和每周工作时长的贫困发生率下降最少,分别下降了2.55%和2.83%。就相对变化来说,贫困发生率下降幅度最大的指标是人均纯收入,高达66.38%;下降幅度最小的是每周工作时长,仅4.41%。但2010—2014年,就业状态和工作总体满意度2个指标的贫困发生率下降幅度最大,均超过50%。

表3 各地区不同指标的贫困发生率
分区域看,东部地区在大多数指标上是贫困发生率最低的地区,西部地区在大多数指标上是贫困发生率最高的地区,次高的是东北地区。在人均纯收入和做饭用燃料2个指标上,2010年、2014年和2018年均是东部地区贫困发生率最低,西部地区贫困发生率最高。值得注意的是,在住房产权指标上,东部地区在2014年和2018年都是贫困发生率最高的地区,而中部地区在2010年、2014年和2018年都是贫困发生率最低的地区。在工作总体满意度指标上,东部地区每年均是贫困发生率最低的地区;在做饭用水指标上每年均是西部地区贫困发生率最高,东北地区贫困发生率最低。
(二)我国劳动力人口多维相对贫困测度
本文利用A-F模型,结合指标的贫困临界值,基于主成分分析法对各指标赋权,测算2010年、2014年和2018年我国劳动力人口多维相对贫困发生率和多维贫困指数。在MPI测度中,联合国开发计划署选用k=1/3作为多维贫困的临界值,之后世界各国都使用这一标准,因此本文选取k=1/3,当个体加权贫困值大于等于1/3时,认为个体处于相对贫困状态。测算结果如表4所示。

表4 总体多维相对贫困测算结果(单位:%)
由表4可知,横向看,随着维度上升,相对贫困发生率和多维贫困指数逐渐下降,当k值超过0.8时,二者都逐渐接近于0或等于0,这说明我国劳动力人口极端多维贫困的发生率十分低。2014年,当k=0.1时,相对贫困发生率高达70.62%,当k=1/3时,相对贫困发生率为19.32%,当k=0.6时,相对贫困发生率下降至1.53%。可以看出,在多个维度上处于相对贫困的个体较少,且平均被剥夺份额的增长幅度远小于贫困发生率的下降幅度。纵向看,同一维度上随着时间的推移,相对贫困发生率和多维贫困指数有明显下降趋势,说明我国经济快速发展的同时,扶贫工作成效显著。
以2014年为例,当k=1/3时,我国劳动力人口贫困发生率为19.32%,其含义为:有19.32%的个体处于至少3.6667个维度的贫困中;平均被剥夺份额为44.32%,表明平均每人有0.4432×11=4.8752个维度上是贫困的;多维贫困指数为0.0856。
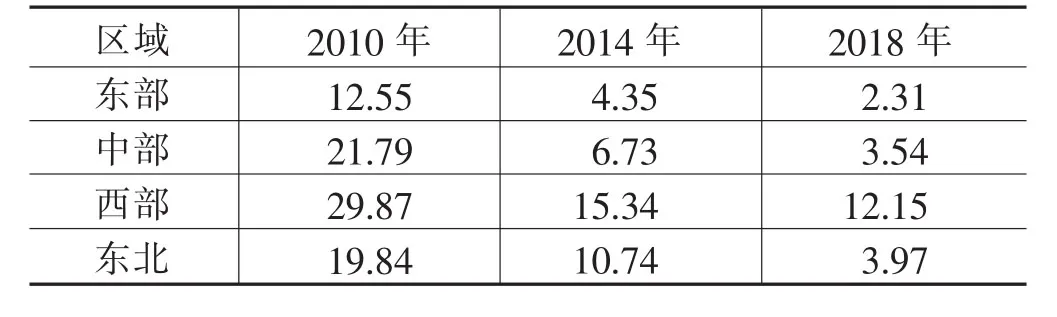
表5 不同区域多维相对贫困指数M0测算(单位:%)
由表5可知,横向看,东部地区多维相对贫困指数最小,西部地区多维相对贫困指数最大。这与东部地区经济发展水平高、基础设施完善,西部地区经济较为落后有关。纵向看,随着时间推移,各个地区的多维相对贫困指数不断下降,从绝对数看,中部和西部地区下降幅度最大,分别下降了18.25%和17.72%。各个地区的多维相对贫困状况都得到了明显改善。
(三)多维相对贫困指数按指标分解
本文将多维贫困指数在各指标上进行了分解,各指标对多维相对贫困指数的贡献率情况见表6。

表6 多维相对贫困指数各指标贡献率(单位:% ,k=1/3)
由表6可知,从总体看,2010年、2014年和2018年对多维相对贫困指数贡献率最大的3个指标依次是:工作总体满意度、就业状态和每周工作时长;受教育程度、做饭用燃料和人均纯收入;受教育程度、人均纯收入和做饭用燃料。不难发现,从2010年到2014年,就业维度的3个指标对多维相对贫困的贡献率大幅下降。2009年,在金融危机导致部分企业发展困难,经济下行的大背景下,就业成为最大难题。为此国家出台了一系列支持和促进就业的政策,就业水平维度的3个指标尤其是就业状态指标贫困发生率和对贫困指数贡献率的大幅度下降,表明这些政策取得了显著成效。受教育程度指标的贡献率随着时间的增加而增加,且在2014年和2018年贡献率都达到了最大,说明当前造成个体陷入多维相对贫困的最主要原因是教育贫困。人均纯收入贡献率逐年增加,在2018年与受教育水平指标共同构成对多维相对贫困指数贡献率最大的2个指标。在健康水平维度,健康状况对多维相对贫困的贡献率最大,且随时间增加而增加,随着医疗体制改革以及医疗体系完善,医疗保险的贡献率较低且在呈下降趋势。可以看出,做饭用燃料指标的贡献率也较高,因此解决天然气等配套设施问题有重要意义。由以上分析可知,收入相对贫困是基础,但要从多个维度来衡量贫困,这对缓解我国相对贫困具有重要意义。
分区域看,东部地区的人均纯收入和做饭用燃料2个指标贡献率较低,西部地区的人均纯收入和做饭用燃料2个指标贡献率较高,东部及东北地区住房产权的贡献率较高,而西部和中部地区较低。西部地区受教育程度贡献率高,东北地区低。不同区域各指标贡献率与总体大致保持一致。
五、我国劳动力人口多维相对贫困的影响因素分析
(一)模型构建与变量描述
被解释变量“是否为多维相对贫困”是一个二分类变量,因此本文选取二元Logistic模型进行分析。被解释变量用Y来表示,Y=1表示多维相对贫困,Y=0表示非多维相对贫困,具体模型如下:

其中,xi表示影响多维相对贫困的第i个因素,p表示多维相对贫困发生概率,β1是自变量xi的相关系数,u表示误差项。
本文主要从个体特征及地区方面来考虑多维相对贫困的影响因素,最终确定8个指标考察其对我国劳动力人口多维相对贫困的影响是否显著。变量具体情况见表7。

表7 变量选取与定义
(二)实证结果分析
本文选取k=1/3作为多维相对贫困临界值,对我国劳动力人口多维相对贫困的影响因素进行分析,这里以2018年的数据为例,样本量为2988个。Logistic回归结果显示,在模型系数的Omnibus检验中,p值均小于0.05,表示拟合模型的变量中至少有一个变量的OR值具有统计学意义,即模型总体有意义。在Hosmer—Lemeshow检验中,p=0.532> 0.05,说明模型拟合优度较高。具体的回归分析结果见表8。

表8 Logistic回归分析结果
由表8可知,在1%的显著性水平下,地区、受教育程度、城乡、婚姻状况、就业状况和健康状况对劳动力人口多维相对贫困的影响是显著的。性别和年龄对劳动力人口多维相对贫困的影响不显著。地区变量中是以东部地区为参照对象,分析结果显示,东北地区和西部地区都是显著的,各自对应的优势比0R=EXP(B)分别是1.881和4.396,表示东北地区劳动力人口陷入相对贫困的概率是东部地区的1.881倍,西部地区劳动力人口陷入相对贫困的概率是东部地区的4.396倍。而中部地区与东部地区相比贫困与否在1%水平下不显著。由此可见西部地区和东北地区是相对贫困发生的主要地区。受教育程度分为五级,以大学本科及以上学历为参照对象,小学及以下水平发生相对贫困的概率是大学本科及以上的55.625倍,初中水平发生相对贫困的概率是大学本科及以上的3.483倍。而高中/中专/技校/职高和大专与本科及以上学历相比,在1%水平下贫困与否不显著。说明教育对个人是否相对贫困的影响很大,随着当前人们受教育水平越来越高,九年制义务教育已不能满足社会需求。结果还表明,农村劳动力人口陷入多维相对贫困的概率是城镇的3.442倍。婚姻状况中,其他(未婚、离婚、同居、丧偶)情况发生多维相对贫困的概率是已婚的1.720倍。失业/退出劳动力市场的劳动力人口多维相对贫困发生概率是在业的4.071倍。健康状况中,不健康的劳动力人口多维相对贫困发生概率是非常健康的41.344倍,健康状况一般的劳动力人口陷入多维相对贫困的概率是非常健康的1.803倍。
六、结论及建议
(一)结论
本文利用中国家庭追踪调查(CFPS)2010年、2014年和2018年的数据,采用A-F模型对我国劳动力人口多维相对贫困进行了识别、测量和分解,然后建立二元Logistic模型,对我国劳动力人口多维相对贫困的影响因素进行分析。由此得出以下结论:
1.总体说,2010—2018年,每周工作时长是贫困发生率最高的指标。贫困发生率下降最多的是人均纯收入和就业状态2个指标;最少的是慢性疾病和每周工作时长2个指标。住房产权及面积的贫困发生率逐年上升。
2.东部地区在人均纯收入和做饭用燃料2个指标上每年均是贫困发生率最低的地区,西部地区贫困发生率最高。住房产权指标贫困发生率最高的地区是东部地区,贫困发生率最低的地区是中部地区。
3.横向看,随着维度的上升,相对贫困发生率和多维贫困指数逐渐下降。东部地区多维相对贫困指数最小,西部地区多维相对贫困指数最大。纵向来看,同一维度上随着时间的推移,相对贫困发生率和多维贫困指数有明显下降趋势。
4.总体看,2010年对多维相对贫困指数贡献率最大的3个指标分别是:工作总体满意度、就业状态和每周工作时长,3个指标从2010年到2014年贡献率大幅下降。2014年到2018年,人均纯收入和受教育程度2个指标的贡献率上升较多,排在贡献率最大的前2名。医疗保险的贡献率一直较低且呈下降趋势。
5.在1%的显著性水平下,地区、受教育程度、城乡、婚姻状况、就业状况和健康状况对劳动力人口多维相对贫困的影响是显著的。性别和年龄对劳动力人口多维相对贫困的影响不显著。
(二)建议
1.继续落实稳就业政策,全面提升就业质量。严格落实劳动法规定的劳动者工作时长限定,提高劳动者的工作满意度。加大劳动力就业政策扶持力度,对处于较严重工作贫困的劳动人口,在政策制定上给予一定侧重。针对存在就业困难的群体开展就业宣讲与招聘。
2.扩大城镇居民医疗保险和新农合医疗保险制度范围,使受惠居民的范围更广更深,完善医保制度,有效减少返贫现象。
3.重点关注贫困人口的教育问题。贫困家庭往往因为收入低而没有过多的资金投入到教育当中,而受教育程度又会影响一个人的收入,这样循环下去,贫困群体极有可能陷入代际贫困。
4.加大对西部地区的政策支持力度。西部地区一直是贫困发生率和多维相对贫困指数最大的地区,我国在发展经济的同时要保障各地区经济持续发展,缩小区域间发展差距。
5.继续提高对农村问题的重视。研究发现,农村劳动力人口陷入多维相对贫困的概率是城镇的3.442倍,政府要加强对乡镇企业的补助,重视农村地区技术和方法的引进,同时加强对促进城乡一体化发展机制研究。
