基于网格密度优先的北斗用户目标可视化方法研究
2022-07-12王成宾
高 扬,郭 浩,王成宾,吴 强
基于网格密度优先的北斗用户目标可视化方法研究
高 扬1,2,郭 浩1,2,王成宾1,2,吴 强1,2
(1 西安测绘研究所,西安 710054;2 地理信息国家重点实验室,西安 710054)
结合北斗用户目标的空间分布和属性特点,提出了一种基于关联关系的语义多尺度聚合模型,并对网格聚合算法进行了优化,改进并提出了基于网格目标密度优先顺序聚合和聚合中心的计算方法,在提高聚合效率的同时,改善了聚合显示效果。该方法在某北斗监测系统中得到了应用和试验,结果表明,算法原理简单、运算效率较高,且更贴近于表达北斗用户目标的实际分布特征,为海量空间数据可视化提供了解决方案,具有较高实用价值,基本满足了不同地图比例尺显示场景对用户目标的感知和理解需要。
北斗用户目标;聚合;解聚;关联关系;网格
0 引言
北斗卫星导航系统面向全球用户提供导航定位、短报文通信、信息播发、国际搜救等多类 服务[1],广泛应用于国防军工[2]、救灾减灾[3]、生态环保[4]、交通运输[5]、海洋渔业[6]等多个领域,应用范围和用户数量日益加大,成为导航和位置服务产业发展的重要支撑。北斗用户目标是指空间中所有使用北斗卫星导航系统的人员或单位实体,可进行自身定位和位置报告,具有用户名称、ID号、属性、位置等描述信息。北斗用户目标监控和可视化是北斗卫星导航系统面向位置服务的一个重要应用,也是需要解决的一个基本问题,基本原理是利用北斗高精度定位和北斗短报文功能接收北斗用户目标位置等相关信息[7-8],并在屏幕上以符号化的形式显示出来,用于北斗用户目标的精确定位和实时监测。北斗用户目标可视化要求能够根据不同地图比例尺,及时、全面、准确地展现当前北斗用户目标的属性、位置等,以满足不同显示场景下对北斗用户目标的感知和理解需要。随着北斗三号卫星导航系统开通运行,北斗服务能力得到较大提升,北斗用户数量也将迎来井喷式增长,北斗用户目标数量将更加巨大(可能达到百万量级),且具有动态性强、实时性高等特点,如果未加任何处理在有限的屏幕区域内显示(大比例尺),可能造成目标相互重叠挤压,既会影响显示效果,难以满足从概略到详细的不同显示需要,也会对显示设备硬件造成压力,影响显示的实时性和连续性,如图1所示。
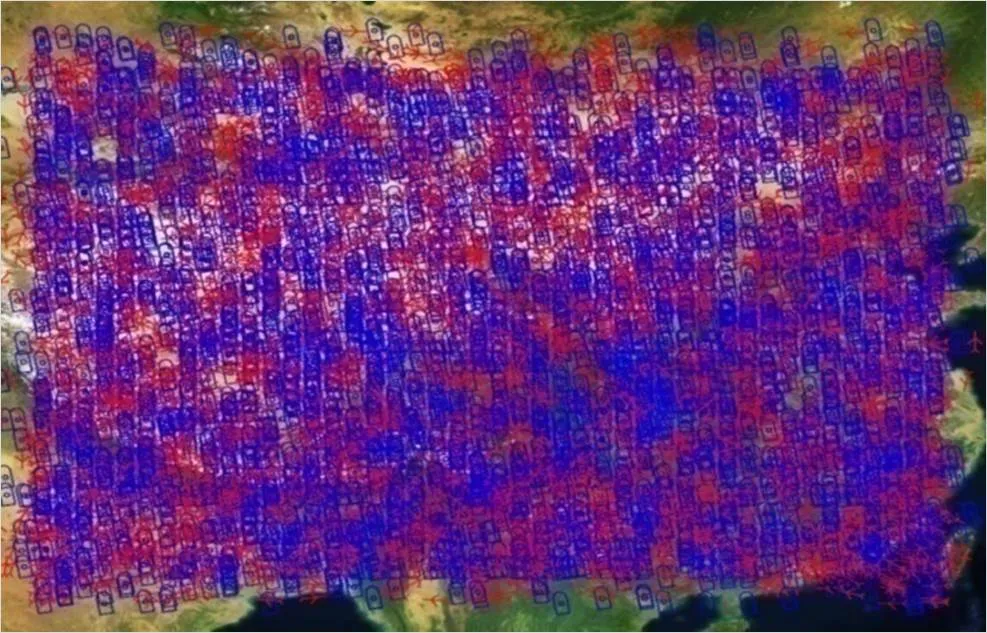
图1 海量北斗用户目标重叠挤压显示效果
针对海量空间目标的显示,普遍采用空间目标聚合的处理操作。所谓聚合,即采用制图综合的方法,将一定范围内具有相似性或相关性的一类或多类目标综合为一个复合目标,形成多对一的对应关系(映射),从而减少目标的显示数量,并给出有关目标更简明的总体信息[9-10]。同时,也可根据需要将聚合得到的复合目标分裂为多个个体目标,称为解聚。通过聚合和解聚操作可以为不同显示场景提供不同详细程度的目标信息。目前应用较多的空间目标聚合显示方法主要有基于网格的点聚合算法[11-12]、基于距离的点聚合算法[13]、基于方格距离的点聚合算法[14]、基于K-means的点聚合算法[15-17]等。丁立国等经对比测试认为:聚合空间点的数量较少时,各算法性能上无明显差异;聚合数据量变大时,基于网格的点聚合算法效率最高,但聚合后目标的分布形态和密集性存在失真现象;基于距离的点聚合算法聚合形态较好,但当点数据量较大时,算法复杂,所需消耗的资源大、响应时间长,且聚合中心的分布存在随机性;基于方格距离的点聚合算法效率在基于网格的算法和基于距离的算法之间,计算出的聚合点能较精确地反映原始点位置分布的疏密特征;基于K-means的点聚合算法,聚合效率最低,对系统资源占用和损耗也最大,但空间点聚合形态较好[18-19]。大多数聚合算法主要根据空间目标的地理坐标进行聚合,即只考虑对象的地理位置(空间邻近性),忽略了目标的类别和关联关系,不能准确地展现目标的空间分布和属性特征,无法适用于北斗用户目标的显示。
本文结合北斗用户目标的空间分布和属性特点,提出了一种基于关联关系的语义多尺度聚合模型,并对网格聚合算法进行了优化,在提高聚合效率的同时,改善了聚合显示效果,更加贴合目标的实际分布特征。该方法在某北斗监测系统中得到了应用,基本满足了不同地图比例尺显示场景对用户目标的感知和理解需要。
1 基于网格密度优先的北斗用户目标聚合
1.1 语义多尺度聚合模型
空间目标的聚合显示机制是一个高度面向应用的问题[20]。北斗用户目标根据地图比例尺大小和显示场景约束可划分为不同层级,每一层级表达内容的广度、粒度、频度甚至表现形式都有所侧重,经历了由细到粗、由详尽到概略、由个体到全貌的显示状态变化。它可表征为一个“树”状结构,最底层是每个北斗用户目标显示个体,作为基本数据附着在“叶结点”上,最高层是北斗用户目标聚合体,上一层数据都是从下一层数据聚合而来。
任意一个目标可以定义为是几何语义、特性语义和关联语义的集合,可表示为:

式中,为目标的唯一标示符,可以用北斗ID表示;几何语义定义目标的位置、速度、航向等信息;特性语义定义目标的属性信息,例如名称、类别、从属、层级等信息;关系语义定义目标之间的相互嵌套包含关系,如同属(隶属于同一上级)、同组(属于同一编组)、同类(属于同一类别)等关系信息,由特性语义衍生而来。
目标聚合模型可定义为:
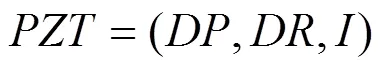
式中,为目标间的几何语义关系,用于反映目标间空间位置的邻近关系,当小于规定阈值、可能相互重叠压盖时,则进行聚合操作;为目标间的关联语义关系,本文定义了隶属、编组、类别三种关系,当多个目标属于同属(多个目标隶属于同一实体)、同组(多个目标在某活动中处于同一编组)或同类(目标类型相同)时,则向上一层级目标聚合;为多级聚合控制因子,即根据当前地图比例尺和显示场景确定聚合显示的目标层级。
本文对于目标间的关联语义聚合关系规定了以下三种情况:
1)按隶属关系聚合
按隶属关系聚合时,将多个同一单位、同级别的目标聚合为上一级目标。例如,车队C包括车辆1、车辆2、车辆3,对车辆1、车辆2、车辆3聚合时,可以按隶属关系聚合为车队C,如图2所示。

图2 按隶属关系聚合显示
2)按编组关系聚合
多个目标没有隶属关系,但执行同一任务,可将多个目标视为一个组合体进行聚合,如运输编队包括卡车1、面包车2、吉普车3,共同完成货物运输任务,如图3所示。
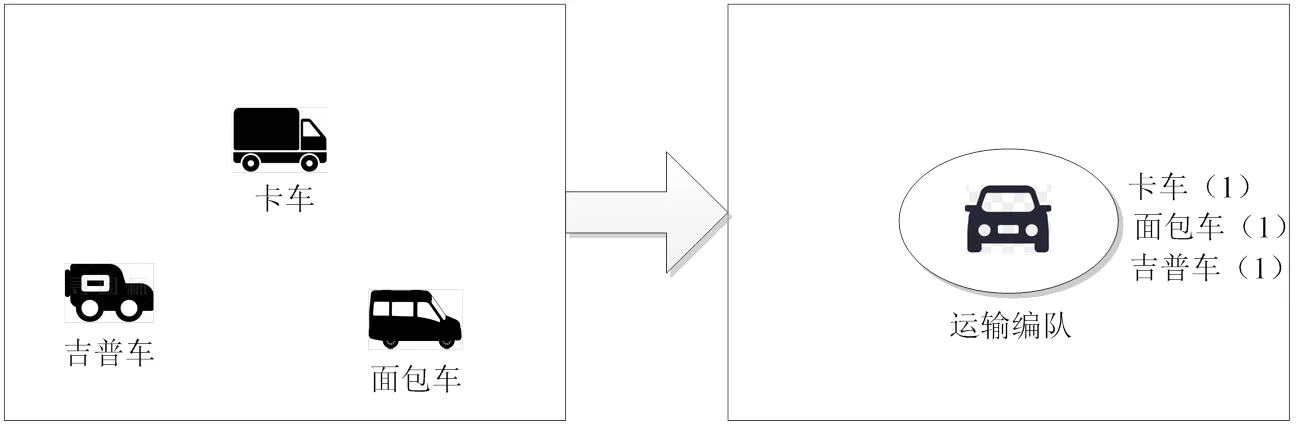
图3 按编组关系聚合显示
3)按目标类别聚合
多个目标没有隶属关系,且互不相干,但属于同一类别,可将多个目标视为一个整体进行聚合。如图4所示,对于多个点状人员目标,可以聚合为一个人员集合目标,并注记表明其数量。

图4 按目标类别聚合显示
1.2 改进的网格聚合算法
基于网格的点聚合算法应用较广,其基本原理是根据缩放级别将显示区域划分为多个规则网格(网格大小根据当前显示比例确定),将同属同一网格的所有空间点聚合显示至网格中心。当网格中没有目标时,不绘制任何目标;当包含1个目标时,绘制为传统显示目标;当包含1个以上目标时,绘制为聚合目标[12,18],如图5所示。该算法只需判断空间点与所属网格区域的包含关系,不用进行距离等复杂计算,运算速度较快,聚合效率较高,相较于其他算法,尤其适合于海量目标聚合计算。但是,由于聚合点选择在网格中心,而不是聚合点的质心,其显示过于规整;此外,对于有些距离较近、聚合度高的点,会因属于不同网格而被强行分在不同的聚合中,不能精确展现目标的空间分布和特点规律。
针对上述问题,本文提出了基于网格密度优先的北斗用户目标聚合算法。算法思路是在网格算法的基础上,对每个网格进一步细化切分成新的网格(本文将原网格切分成3×3个新网格),按照新网格单元数据密度(包含的目标数量)由高到低的顺序,依次以每个新网格中心为聚合中心,将网格内与周围邻近网格包含目标进行聚合,聚合过程如图6所示。
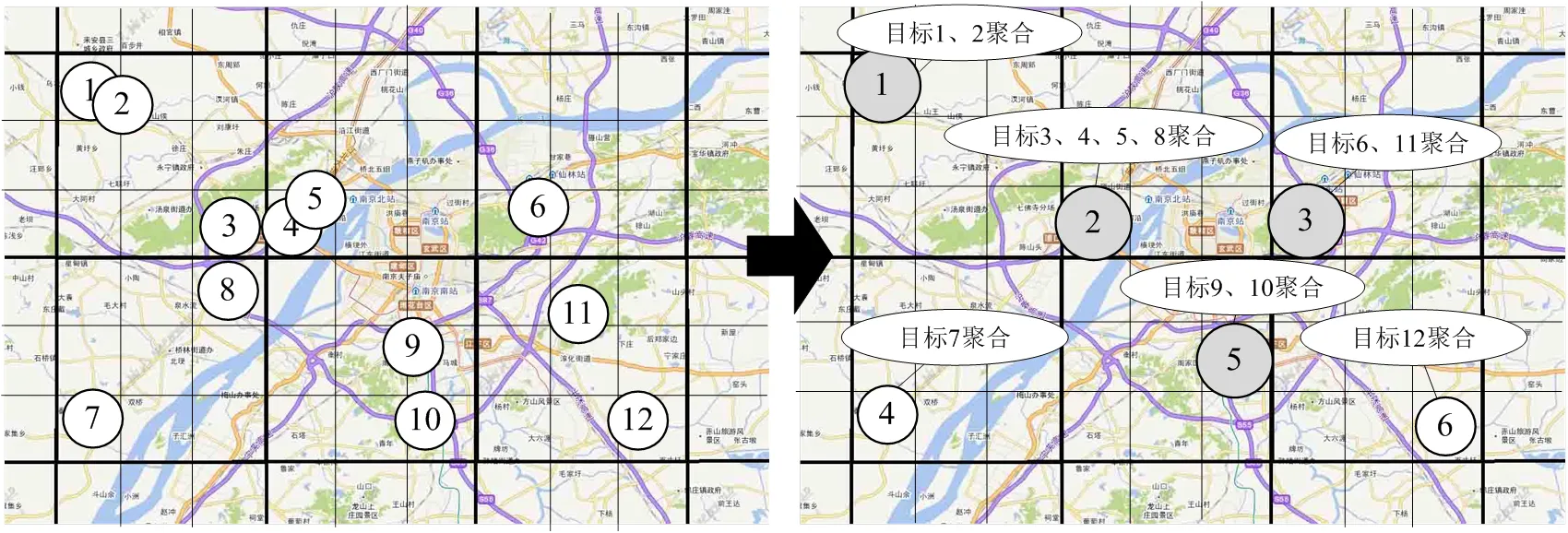
图6 基于网格密度的北斗用户目标聚合算法示意图
改进后的算法解决了网格算法显示过于规整的问题,能够确保目标分布密集的区域优先得到聚合,更能真实反映目标的实际分布情况。如图5中3、4、5、8目标相互邻近、聚合度高,若采用网格算法,由于处于不同网格,会被割裂到不同的聚合中,原始分布特征也被改变;而采用改进算法,如图6所示,由于它们所处网格相邻,且密集度高,能够优先进行聚合,较为客观地反映了目标点的位置信息和疏密特征。此外,可以将聚合目标质心而不是网格中心作为聚合中心,从而进一步提高聚合显示的准确性。
聚合目标质心计算如式(3)所示:
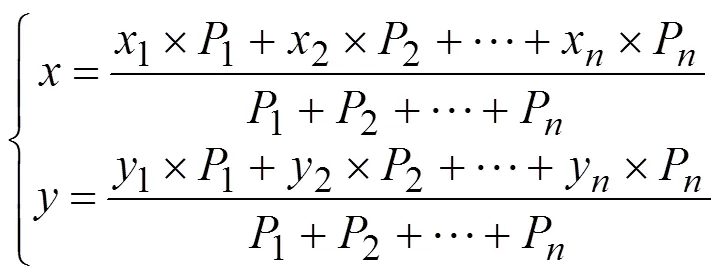
式中,为目标权重,即为目标的大小、层级、分布范围等的综合描述。可以看出,当有一大一小两个目标聚合时,聚合中心更靠近大目标位置;当目标权重相同时,聚合中心为网格内目标的几何中心。
算法中对目标数据集的网格划分、网格内目标数量统计等运算相对简单,效率较高。对算法速度影响较大的主要是对网格密度排序。如果网格尺寸过大,则显示可能过于粗略;如果网格尺寸过小,网格数量过多,尤其空网格或只包含1个目标的网格过多,则会产生很多不必要的计算。因此,需要合理划分网格,才能有效节约系统计算和绘制资源开销。本文将网格宽度按照显示像素设置为聚合后绘制图标宽度的1/3,这样可以确保聚合后显示图标之间不相互重叠压盖,同时设置阈值,当网格密度过低时(如小于或等于1),则不参与排序。此外,采用双线程机制,在后台线程通过预判显示比例和显示窗口变化进行网格切分和排序操作,将排序结果存入缓存,聚合显示时直接读入并根据排序结果进行聚合操作,从而大大提升聚合效率。
考虑到显示过程中对北斗用户目标数量动态变化的实时处理需求,本文采用动态链表结构体来管理所有的北斗用户目标数据,并采用树型结构按照类别、隶属、编组等关联关系构建目标间关系模型。当视图显示范围发生变化(缩放、平移)时,重新建立屏幕像素网格,为每个网格建立一个链表用于存储网格所包含的目标数据,遍历当前视图内的所有可见目标,经坐标转换后填入网格链表中,当实时目标数据更新或视图显示范围发生变化时,重新计算网格内的目标数量。根据网格密度采用冒泡法对网格进行排序,按照从高到低的顺序,依次将网格与其相邻的8个网格进行聚合,具体操作是将相邻8个网格链表存储的目标弹出并压入中心网格链表中。在绘制时,遍历网格链表,链表为空时,即屏幕网格目标数量为0时,不进行绘制;当链表对象数量为1时,即屏幕网格目标数量为1时,绘制正常的目标符号;当链表对象数量大于1时,即屏幕网格目标数量大于1时,按照目标间的关联关系对目标进行聚合,计算目标质心作为聚合中心,在聚合中心绘制聚合目标符号,并标注聚合目标的数量。
2 算法实现与实验验证
本文算法在某北斗监测系统进行了实现与应用。系统基于PIE-Map平台,采用QT框架进行开发。为进一步提高目标显示效率,采用了以下措施:
1)通过图形处理器(Graphics Processing Unit,GPU)实现目标的二三维一体化绘制引擎,即将大批量动态目标按照网格分块并处理成OpenGL可渲染的对象,进而分块绑定到GPU中,从而解决了大批量目标数据的反复加载以及数据处理过程的阻塞;
2)采用多级缓存显示技术。显示流程如图7所示,显示时首先从GPU中寻找对应的瓦片;如果GPU中没有,检索内存缓存中的瓦片,内存中有瓦片,就加载到GPU中;如果内存中没有,就去本地瓦片缓存文件夹中加载瓦片,再通过相应的缓存算法,放入缓存列表中。
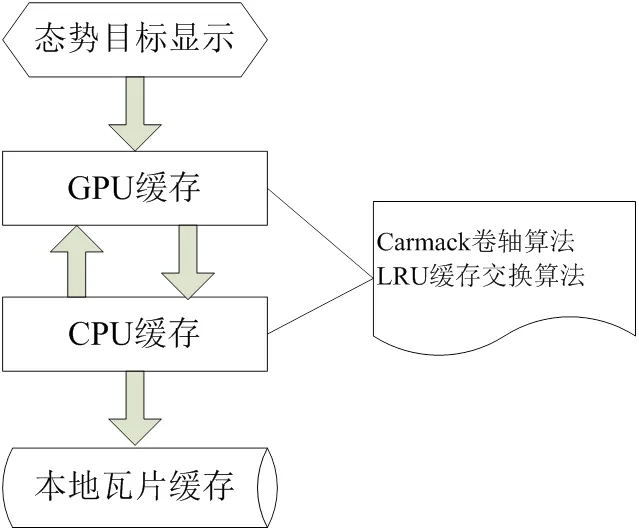
图7 多级缓存调度示意图
如图7所示,通过Carmack卷轴算法和LRU缓存交换算法实现多级缓存交换与调度,使目标显示查询效率得到进一步提高,显示时缓存列表中缓存了多级瓦片,在窗口平移和缩放过程中,配合使用多级瓦片查找和显示策略,最终达到无缝实时漫游的显示效果。
算法在i7 CPU 3.5 GHz,16 G内存,8 G显存,Windows 7系统环境下进行了测试。测试中,选择显示目标数分别为300、5 000、10 000、50 000、100 000、200 000共6组数据,分别计算不聚合显示和本文方法聚合显示的响应时间。测试结果如表1和图8所示。
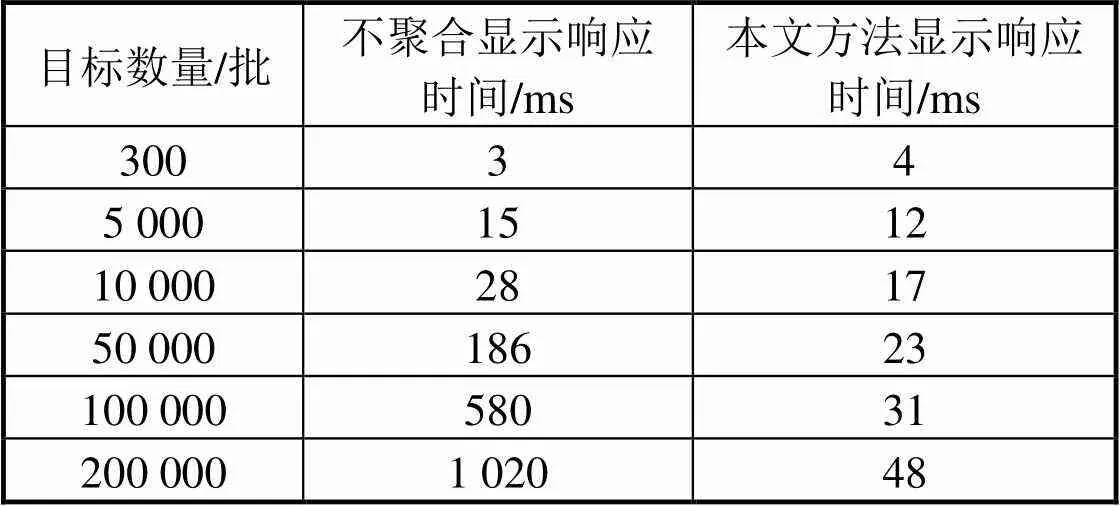
表1 目标聚合显示性能对比
由表1可以看出,相较于不聚合方法,本文方法由于对显示的北斗用户目标进行了网格划分,绘制的聚合目标数目最大为网格数目,减少了目标符号化的时间,提高了显示效率。在目标数少的情况下,聚合算法提升效率不高,甚至可能带来效率降低;在大批量目标显示时,聚合方式的时长明显小于不聚合方式,且目标数越多,目标分布越集中,节约时长越多,性能提升越明显。
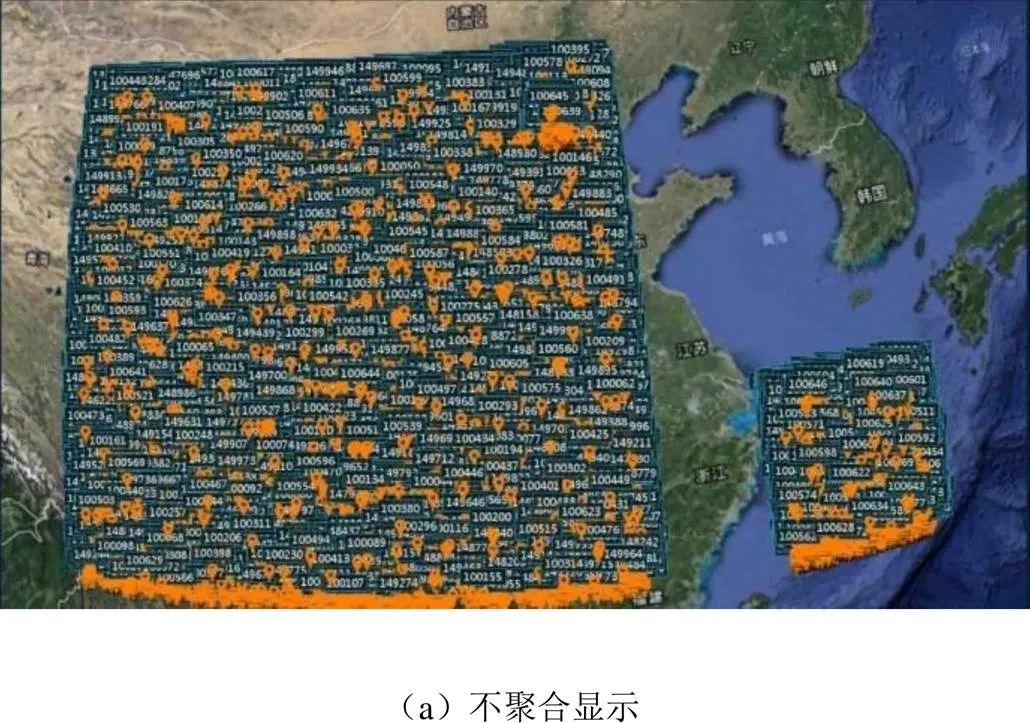
由图8可以看出,本文方法解决了目标显示相互压盖的问题,能够更精确简明地反映当前北斗用户目标的实际分布情况,实现对目标的全面、准确监测。
3 结束语
目标聚合为海量空间目标数据可视化提供了解决方案,其本质上是地图综合技术在地理信息系统的创新应用。本文提出了基于关联关系的语义多尺度聚合模型,对网格聚合算法进行了优化,算法原理简单、运算效率较高,且更贴近于表达北斗用户目标的实际分布特征,适用于千万量级北斗用户目标的显示。本文方法除适用于北斗应用系统目标显示外,还可应用于其他地理信息系统,具有较高实用价值。
[1] YANG Y X, GAO W G, GUO S R, et al. Introduction to BeiDou-3 Navigation Satellite System[J]. Navigation, 2019, 66(1): 7-18.
[2] 张杰,何玉晶,厉剑. 北斗用户机应急指挥系统研究[J]. 测绘与空间地理信息,2020,43(12):133-135.
[3] 张志峰,李中学. 应急状况下北斗短报文通信功能的应用[J]. 计算机测量与控制,2018,26(10):276-279.
[4] 李邦训,陈崇成,黄正睿,等. 基于北斗与ZigBee的生态环境参数实时采集系统[J]. 福州大学学报(自然科学版),2019,47(4):460-466.
[5] 王洵,欧志伟,柳井明,等. 交通运输行业北斗系统国际化应用综述[J]. 卫星应用,2021(4):12-16.
[6] 莫云音,吴盛洪,陈亮,等. 北斗船载终端可视化气象预警信息技术研究[J]. 计算机技术与发展,2020,30(10):199-203.
[7] 刘兴科,张之孔. “北斗一号”车辆监控管理系统的设计[J]. 测绘与空间地理信息,2012,35(6):15-18.
[8] 杨涛,邢建平,王胜利,等. 高精度高可靠性车联网位置服务整体解决方案[C]. 卫星导航定位与北斗系统应用2019——北斗服务全球融合创新应用,2019:230-235.
[9] Chen J H, Chen J X. Research on Point Aggregation Algorithm Based on WEBGL[C]. Proceedings of the 3rd International Conference on Electronic Information Technology and Computer Engineering, 2019(10): 1243-1246.
[10] 吕德奎. 聚合算法在电力GIS中的应用[J]. 电力信息化,2012,10(5):37-40.
[11] Beilschmidt C, Fober C, Mattig M, et al. A Linear-Time Algorithm for the Aggregation and Visualization of Big Spatial Point Data[C]. Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, 2017(11): 1-4.
[12] 薛雯,王唯圳,吴瑞祥. 基于网格聚合的态势展现方法[J]. 信息化研究,2019,45(1):33-36.
[13] Desislava D, Lars L. Data Aggregation and Distance Encoding for Interactive Large Multidimensional Data Visualization [C]. Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, 2018(3): 225-235.
[14] Habibullayevich G K, CHEN X, Shin H. Efficient Filtering and Clustering Mechanism for Google Maps[J]. Journal of Advanced Management Science, 2013, 1(1).
[15] 苏锦旗,薛惠锋,詹海亮. 基于划分的K-均值初始聚类中心优化算法[J]. 微电子学与计算机,2009,26(1):8-11.
[16] 周爱武,于亚飞. K-Means聚类算法的研究[J]. 计算机技术与发展,2011,21(2):62-65.
[17] 熊平,顾霄. 基于属性权重最优化的k-means聚类算法[J]. 微电子学与计算机,2014,31(4):40-43.
[18] 丁立国,熊伟,周斌. 专题图空间点聚合可视化算法研究[J]. 地理空间信息,2017,15(5):6-10.
[19] 曾绍琴,李光强,廖志强. 空间聚类方法的分类[J]. 测绘科学,2012,37(5):103-106.
[20] Lin K H, Pan Y B, Wang X L, et al. Effective Dynamic Algorithms for Massive Mark Point Aggregation Display[C]. Proceedings of the 12th International Conference on Computer Science and Education, 2017(10): 331-336.
Beidou User Objects Visualization Method Based on Grid Density Priority
GAO Yang, GUO Hao, WANG Chengbin, WU Qiang
Combined with the spatial distribution and attribute characteristics of Beidou user objects, a semantic multi-scale aggregation model based on association relationship is proposed, optimizes the traditional grid aggregation algorithm, improves and puts forward the calculation method based on grid object density priority aggregation and aggregation center, which improves the aggregation display effect while ensuring the aggregation efficiency. This method has been applied and tested in a Beidou monitoring system. The results show that the algorithm has simple principle, high operation efficiency, and is closer to expressing the actual distribution characteristics of Beidou user targets. It provides a solution for massive spatial data visualization, has high practical value, and basically meets the needs of perception and understanding of user targets in different display scenes of map scale.
Beidou User Objects; Aggregation; Disaggregation; Association Relationship; Grid
TN967.1
A
1674-7976-(2022)-03-157-07
2022-04-28。
高扬(1969.12—),陕西西安人,博士,正高级工程师,主要研究方向为卫星导航应用。
