基于BERT的混合字词特征中文文本摘要模型
2022-07-12劳南新王帮海
劳南新 王帮海
(广东工业大学计算机学院 广东 广州 510006)
0 引 言
在信息爆炸时代,面对呈指数级增长的网络文本资源,如何精准而快速地从中提取出重要的内容,已经是一个十分迫切而有意义的需求。自动文本摘要技术旨在利用计算机强大的计算能力,从较长文本中提炼出关键信息,生成简洁、通顺和凝练的摘要,以帮助用户快速全面地了解文本关键信息。其在下游任务,如新闻标题生成、搜索结果预览和自动报告生成等都有丰富的应用场景[1]。
一般而言,自动文本摘要技术从算法思路上可以分为抽取式(Extractive)和生成式(Abstractive)[1]。抽取式自动文本摘要技术的主要思路是根据一定算法,给每个句子打分,然后按照分数排序,选取前k个句子整合作为文本摘要。其优点是易于实现、语句通顺度高,不存在事实性错误,缺点是灵活性不够,无法生成原文中不存在的词句。其代表算法有LexRank[2]和TextRank[3]。LexRank的主要思路是把句子视为节点,句子间相似度作为边构造出标量图,根据图模型中节点的权重抽取评分较高的句子组合成摘要。TextRank算法则借鉴了PageRank[4]搜索网页排序算法,将词视为“互联网上的节点”,根据词之间的共现关系构建图模型,以马尔可夫链的收敛性质作为理论基础,采用投票机制选取出摘要句。
生成式自动文本摘要技术的进步得益于近些年神经网络的巨大发展。Rush等[5]将基于注意力机制的Seq2Seq架构引入文本摘要领域,证实了循环神经网络对文本摘要任务的有效性。Gu等[6]受人类提取信息的模式启发,首次将复制机制引入了文本摘要模型。See等[7]提出的Pointer-Generator网络则融合了复制和生成模式,并引入了覆盖向量,同时解决了OOV(Out of Vocabulary)和无意义重复的问题。Paulus等[8]提出将有监督单词预测和强化学习结合,以缓解损失目标为交叉熵和以不可导的ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评分[9]为评测目标的不一致性问题。Reinforced-Topic-ConvS2S[10]则结合了强化学习、主题感知和卷积Seq2Seq的优点,在Gigaword、DUC等一系列文本摘要数据集上取得了较大的进展。
近年来,Elmo[11]、BERT[12]和GPT[13]等预训练语言模型的提出使得“预训练+微调”的架构思路提升了一系列自然语言处理任务的分数。Zhang等[14]提出基于BERT的两阶段摘要生成模型,Liu等[15]提出基于BERT的文档级别编码器,都验证了预训练语言模型在文本摘要任务上的可行性与有效性。
在中文文本摘要领域,Hu等[16]构建的LCSTS新浪微博新闻数据集为较为权威的中文短文本摘要数据集,Chang等[17]提出的混合字词编码模型HWC+Transformer首次在LCSTS数据集上取得了较大的进展。
1 中文文本摘要的信息论分析
1.1 文本摘要信息论框架
Peyrard等[18]为自动文本摘要任务定义了系统严谨的理论框架,本节首先讨论该框架与ROUGE评分的关系,并试图在其理论框架基础上,分析中文自动文本摘要的信息论特征,并为混合字词特征的中文文本摘要模型提供理论支持。
一段文本X可以看作是一个以一定概率分布PX发射语义单元ω的信源。相关度(Relevance)定义为摘要和原文档之间的交叉熵,Rel(S,D)=-CE(S,D)。
(1)
式中:S代表摘要;D代表原文档;PS为摘要中基于语义单元组合的概率分布;PD为原文档中基于语义单元组合的概率分布;ωi代表第i个语义单元。相关度衡量的是摘要和原文档之间的相关程度,相关度越大,那么摘要就能更好地拟合原文档的概率分布,摘要和原文档之间的信息损失就越小,读者通过阅读摘要就能更大程度地降低对原文档的不确定性。
冗余度(Redundancy)定义为摘要的最大香农熵和实际香农熵之间的差值,其计算式为:
Red(S)=Hmax-H(S)
(2)
式中:Hmax表示在摘要为均匀分布时的香农熵,也即对全体语义单元的集合Ω来说,∀(i,j),PS(ωi)=PS(ωj)。理论上Hmax=log|Ω|可视为常数,因此冗余度也可简写为Red(S)=-H(S)。冗余度越小,表示摘要越简短高效,包含的信息覆盖范围越全面,重复冗余信息越少,信息压缩的效率越高。
设读者拥有一个背景知识库K,则信息量(Informativeness)可定义为摘要和背景知识库之间的交叉熵,Inf(S,K)=CE(S,K)。
(3)
式中:PK表示背景知识库K中基于语义单元组合的概率分布。信息量越大,表示读者在以背景知识库K为基础的条件下,通过阅读摘要,获得的新信息量越大。
综合以上三个维度,可定义一个全面的文本摘要的目标函数,其表达式为:
ΘI(S,D,K)=-Red(S)+αRel(S,D)+βInf(S,K)
(4)
1.2 ROUGE评分与信息论概念的关系
上述文本摘要严谨全面的信息论框架,可以为文本摘要算法模型提供理论指导。但在实际应用计算中,文本的概率分布难以精确取得,因此,文献[18]在实验部分做了以下简化假设:
(1) 选择词作为语义单元。
(2) 一段文本基于词的概率分布可由这段文本基于词的频率分布近似。
短文本摘要中语义单元的出现频率大多在0和1之间,因此在实际工程应用中,衡量摘要的优劣一般采用ROUGE评分[9],其主要通过对比自动生成摘要与人工参考摘要的n元词的共现关系计算自动生成摘要的分数,一般有召回率(Recall)、精确度(Precision)和F值。
(5)
(6)
(7)
为了讨论ROUGE指标与相关度、冗余度、信息量和目标函数ΘI的关系,本文继续做出以下假设。
(4) 由于每位读者背景知识库K都不同,因此假设一个一般的背景知识库,其概率分布为基于所有语义单元的均匀分布。
综上所述,在以上一系列理论假设条件下ROUGE评分与目标函数ΘI基本正相关,因此后续用ROUGE评分来评价文本摘要的优劣具有一定合理性。
1.3 中文语义单元的选择
中文文本与英文文本不同,并不存在天然的以空格分隔的单词,因此对中文文本自动摘要任务进行建模就必须考虑到语义单元的选取问题。一般而言,在读取与理解一段文本的内在涵义上,词比字能更准确地捕捉信息,因此本节提出在提取信息特征的编码器阶段存在着以下关系。
Rel(FW,D)≥Rel(FC,D)
(8)
式中:FW表示以词为语义单元的编码器编码出的信息特征;FC表示以字为语义单元的编码器编码出的信息特征。式(8)表明在编码器提取文本信息特征阶段,以词为语义单元的编码器能更准确地捕获原文信息,产生的与原文的信息损失更小。
在中文中常常存在着缩写现象,如“发展和改革委员会”常被简写为“发改委”。设DW为一语义的全称,DC为同一语义的简写,则在以常识背景知识库K为前提条件下,通过阅读简写DC,能以很高的概率推断出全称DW,或也可表示为条件熵H(DW|DC,K)≈0。因此在解码器生成摘要阶段,本文认为存在以下关系:
Rel(SW,D)≈Rel(SC,D)
(9)
Red(SW)≥Red(SC)
(10)
Inf(SW,K)≈Inf(SC,K)
(11)
式中:SW表示以词为语义单元的解码器生成的摘要;SC表示以字为语义单元的解码器生成的摘要。式(9)-式(11)表明,在解码器端,以字为语义单元生成的摘要相比以词为语义单元生成的摘要,能在保持相关度和信息量基本不变的同时,减少冗余度,从而优化目标函数ΘI。
2 模型设计
BERT预训练模型[12]的提出在一系列NLP任务上都取得了不错的进展,并成为了当今NLP领域十分重要的基础技术。然而由于谷歌官方发布的BERT_base_Chinese中文预训练模型是以字为粒度,遮罩也是以字为粒度,这就导致该模型无法捕捉中文以词语为语义单元更准确的信息。全词遮罩wwm(Whole Word Masking)[19]是BERT的升级版,其主要改进是在预训练阶段,如果一个词WordPiece分词后部分子词被遮罩,那么同属该词的其他部分子词也会被遮罩。Cui等[19]为了解决以字为语义单元的谷歌版BERT的缺陷,将全词遮罩技术引入中文BERT的训练中,使用中文维基百科和通用数据进行训练,在一系列中文NLP任务上都验证了其有效性。
在中文文本摘要任务上,Chang等[17]提出的混合字词模型(Hybrid Word-Character Model)首次在中文文本摘要数据集LCSTS[16]上取得了突破性的进展。在HWC模型中,首先用Jieba分词算法库对原文档进行中文分词,将分词编码成词向量输入编码器,生成中间特征向量,再将该特征向量输入解码器,以字为语义单元生成文本摘要。
本文则认为,在文本的词嵌入表示阶段,进行中文分词的过程可能存在误差,而这种在一开始就由分词造成的误差,在后续则难以纠正。因为从工程实践经验来看,每个领域都有其独特的词语表示,几乎不存在通用的分词系统。比如“南京市长江大桥”,就存在“南京市 | 长江 | 大桥”和“南京 | 市长 | 江大桥”两种分词方案。
同时由于中文词组的可能组合非常多,在分词嵌入阶段构造的词表就会非常大。以字粒度表示的字表只需要记录1万左右的字,而以词粒度表示的词表记录数则往往会达到字表的几十甚至上百倍。这一方面会使得使用词表计算最终词的生成概率的时间复杂度和空间复杂度远远大于字表,另一方面假如为了限制词表的长度只记录出现频率最多的前k个词,则容易导致OOV(Out-of-Vocabulary)词的现象。
因此本文提出在中文文本摘要任务中,为了避免分词误差和使用词表时间复杂度和空间复杂度过大的问题,不必在一开始就进行中文分词,而是采用全词遮罩的BERT_wwm中文预训练语言模型作为编码器,去提取中文文本的词语级别语义特征,BERT的每一个Transformer[20]子模块主要包含以下两个操作。
(12)
(13)
式中:LN表示层规范化(Layer Normalization)操作,MHAtt表示多头注意力机制操作;FFN表示前馈神经网络操作(Feed Forward Net);h表示隐藏层特征向量,上标l表示层的高度。在BERT的最后一层输出包含了中文文本丰富的词语级别语义信息的特征向量hL,再将该特征向量输入多层Transformer[20]解码器中解码生成最终摘要。
S=Trm(Trm(…Trm(hL)))
(14)
式中:Trm表示Transformer解码器操作[20]。
本文提出的基于BERT的混合字词特征中文文本摘要模型如图1所示。
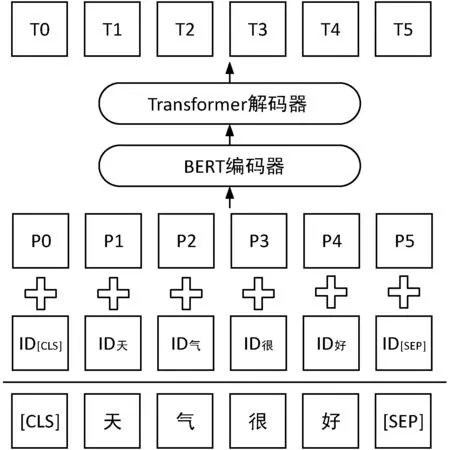
图1 基于BERT的混合字词特征中文文本摘要模型
图中ID表示原文中每个字词通过字词表映射为对应的ID数字序号,P表示位置嵌入,T表示最终生成的摘要文本单元,由于本文并未采用下一句预测这一预训练任务,因此模型并没有使用分段嵌入来标记句子。
由于从原始文本生成摘要可以看作一个所生成摘要文本同原始文本的相关度不变或稍微减少,而同时生成文本冗余度减少的过程,相关度和冗余度的关系可由KL散度描述。
KL(S‖D)=Red(S)-Rel(S,D)
(15)
相关度越高,冗余度越小,那么KL散度的数值就越小,说明模型对原文进行信息提取与压缩的能力越强。由第1节的分析,ROUGE评分可近似综合体现相关度和冗余度,因此根据控制变量法,在解码器框架不变的条件下,如果ROUGE评分越高,则说明编码器提取信息特征的能力越强。由于中文字与字之间的组合情况千差万别,如果在一开始就对中文文本进行分词,限定了字与字之间的可能组合,不仅一开始可能因为分词偏误引入误差,而且还无法利用模型强大的信息处理能力对特定领域的中文文本字与字之间更优的组合方式进行调整与学习。因此本文的模型基于如下假设,全词遮罩BERT编码器能够在后续训练中学习到更优的语义单元组合信息,其提取信息特征的能力强于在起始先分词后再进行编码的编码器。假设编码器提取出的中间特征能与真实文本在语义单元上抽象对应,那么该假设可表述为:
KL(FBERT_wwm‖D)≤KL(Fseg‖D)
(16)
式中:FBERT_wwm表示采用全词遮罩BERT作为编码器提取出的信息特征,Fseg表示先中文分词再进行编码后提取的信息特征。式(16)含义表示全词遮罩BERT能通过训练与调整捕捉到更优的字与字之间的组合方式,提取出的中间信息特征具有更高的相关度,更低的冗余度,从而使得与原文的KL散度更小。
后续本文分别采用了BERT_base_Chinese、BERT_wwm_Chinese、BERT_wwm_ext_Chinese和RoBERTa_wwm_ext_Chinese四种BERT预训练语言模型作为编码器。其中,RoBERTa[21]是BERT的改进版,相比BERT,其主要在预训练过程中采用动态遮罩技术,连续多句NSP(Next Sentence Prediction),以及采用更大的mini-batch和更多的训练数据。
3 实验及结果分析
实验在Intel Core i7- 6800K CPU @ 3.40 GHz×12处理器、24 GB内存、250 GB硬盘、Nvidia GeForce GTX 1080/PCIe/SSE2显卡、8 GB显存、Ubuntu 18.04.2 LTS 64位操作系统、Python 3.7.3和Pytorch 1.0.1的环境中运行。
3.1 数据集描述
本文在较为权威的中文短文本摘要数据集LCSTS[16]上进行了实验。该数据集爬取自新浪微博权威的新闻媒体账号,其主要由三部分组成。
实验按中文短文本摘要领域内的惯例,采用第I部分进行训练,在评测时则以第III部分中相关度评分大于等于3的725条数据为测试集。
3.2 实验模型设置
公开的BERT模型是基于中文维基和通用数据进行的预训练,将其应用于文本摘要生成任务有必要针对性地进行预训练微调。尽管原始的BERT模型有遮罩预测与下一句预测两个预训练任务,但根据文献[22],去除下一句预测任务且遮罩连续的片段效果更好,同时一般摘要句长度不会超过原文长度的1/3,因此本文将原文与摘要句进行拼接。
[CLS]原文[SEP]摘要句
接着对摘要句进行整体遮罩,构建出如下的数据格式来对BERT模型进行遮罩预测任务的预训练微调。
[CLS]原文[SEP][MASK][MASK]…[MASK]
第二阶段再将微调好的BERT模型对原文提取出的文本特征送入Transformer解码器进行文本摘要的生成。
在编码器端采用BERT预训练语言模型结构,隐藏层数为12,隐藏层节点数为768,注意力头为12个,注意力层和隐藏层的dropout概率设为0.1,最大位置编码为512,隐藏层激活函数采用高斯误差线性单元GELU(Gaussian Error Linear Units),表示为:
GLUE(x)=xP(X≤x)=xφ(x)
(17)
式中:φ(x)是高斯正态分布的累积分布。
在解码器端采用6层Transformer,隐藏层节点数为768,注意力头为12个,最大目标文本长度为32。
损失函数采用Label Smoothing,表示为:

(1-ε)H(q,p)+εH(u,p)
(18)
在测试生成阶段采用集束搜索Beam Search,选取出条件概率近似最大的句子,表示为:
…,x
(19)
3.3 预训练微调分析
对四种BERT模型进行预训练微调的结果如图2所示,可见尽管四种BERT模型在预训练微调时的交叉熵损失之间差距不超过0.2,但仍能看出原始的BERT_base模型的预训练微调效果稍差于其他采用了全词遮罩的BERT模型,同时RoBERTa_wwm_ext模型的预训练微调交叉熵损失相较其他模型更优。
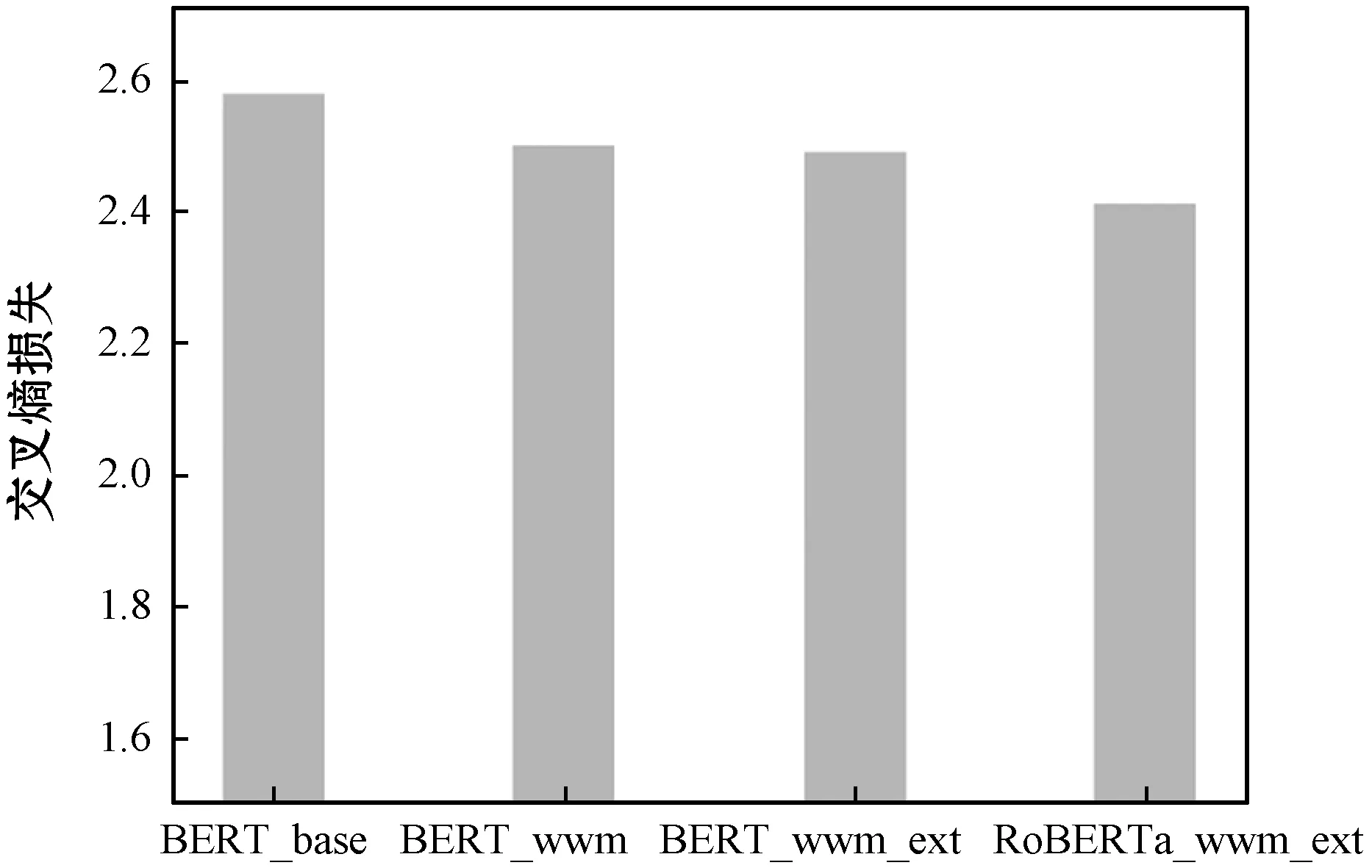
图2 BERT预训练微调对比图
3.4 评估方法
实验采用自动文本摘要领域通用评价标准ROUGE[9]作为实验结果的评估方法,n元词的ROUGE计算公式已在本文第1节中叙述。ROUGE-N固定了n元词的长度n,对于文本流畅度的评估存在不足,而ROUGE-L则是对比自动生成摘要和人工参考摘要的最长公共子序列来计算分值的一种方法。
(20)
(21)
(22)
3.5 摘要生成结果分析
实验结果如表2所示,可见相比单纯Transformer模型,BERT+Transformer的ROUGE-1、ROUGE-2和ROUGE-L的F1分数都有一定提升,并且采用了全词遮罩技术的BERT_wwm效果好于谷歌发布的以字为遮罩粒度的BERT_base模型。其中RoBERTa_wwm_ext_Chinese+Transformer达到了最好效果,ROUGE-1、ROUGE-2和ROUGE-L的F1分数分别达到了44.60、32.33和41.37,效果好于起始先进行中文分词后再进行编码的HWC+Transformer方法,这验证了式(16)的假设。

表2 ROUGE评测的F1分数
训练过程loss值随时间的变化情况如图3所示,可以看出RoBERTa_wwm_ext_Chiinese+Transformer的收敛速度比其他模型快,整体loss曲线也明显低于其他三种方法,具有更优的收敛性质。

图3 loss值随训练时间变化的关系
图4选取了在测试时LCSTS数据集的第III部分的部分样例,可看出,BERT_wwm_Chinese+Transformer的模型能生成原文中并不存在的“透露什么信号”等词句,可见其能理解并捕捉原文关键信息并重新用更简洁的词句表达,说明其具有较强的理解与生成能力。但同时也注意到在Article(2)中,HWC+Transformer和BERT_wwm_ext_Chinese+Transformer生成的摘要有歧义,原文意思是“小米等互联网盒子和路由都和我们没法比”,它们生成摘要的意思却分别是“小米和路由没法比”和“互联网盒子和路由没法比”,会给读者造成误导。如何防范摘要对原文意思过份简略而导致歧义,将是文本摘要后续研究的一大重点。通过对比也可看出,RoBERTa_wwm_ext_Chinese+Transformer生成的摘要其概括能力、正确度、流畅度与可读性都显著强于其他模型,已相当接近人类摘要的水平。

Article(1):除了出访或是参加重要活动,李克强总理都会在周三主持召开国务院常务会议。7个月,23次常务会议(20次在星期三),如果将这些会议的主题用一条红线串起来,看到的不只是大政方针变化的轨迹,更有本届政府的执政之道、治国之策。Reference:23次常务会议透视李克强执政之道。Transformer:国务院常务会议的红线串起来。HWC+Transformer:解读李克强7个月23次常务会议。BERT_base_Chinese+Transformer:李克强总理周三主持召开国务院常务会议。BERT_wwm_Chinese+Transformer:总理7个月23次常务会议透露哪些信号?BERT_wwm_ext_Chinese+Transformer:李克强总理7个月23次常务会议透露什么信号。RoBERTa_wwm_ext_Chinese+Transformer:从国务院常务会议看李克强执政之道。Article(2):对即将改名“中科云网”的湘鄂情,孟凯充满期待,“外界说我们是做大数据玩概念,但我相信升级改造广电网络的工作,将会相当于给广电配上核武器。”“小米等互联网企业那些盒子和路由加一起,都和我们没法比。”Reference:湘鄂情搞有线电视:小米们加一起都和我们没法比。Transformer:孟凯:互联网盒子和路由加一起都没法比。HWC+Transformer:湘鄂情董事长谈升级改造广电网络:小米和路由没法比。BERT_base_Chinese+Transformer:湘鄂情董事长孟凯:互联网公司要改造广电网络。BERT_wwm_Chinese+Transformer:湘鄂情孟凯:改造广电网络相当于给广电配核武器。BERT_wwm_ext_Chinese+Transformer:湘鄂情董事长孟凯:互联网企业盒子和路由没法比。RoBERTa_wwm_ext_Chinese+Transformer:湘鄂情孟凯:小米等盒子和路由加一起都和我们没法比。
4 结 语
本文认为文本摘要可视为一个信息处理过程,可由一套严谨系统的信息论框架描述。首先探讨了文本摘要信息论框架与ROUGE评分标准的关系,并对中文文本摘要的词级语义单元和字级语义单元的信息论特征进行了分析,根据文本摘要的相关度、冗余度和信息量等特征。为了解决在HWC方法在一开始进行中文分词导致引入误差以及词表过大造成的时间复杂度和空间复杂度过大的问题,提出采用全词遮罩BERT_wwm+Transformer的中文文本摘要模型。在LCSTS上的实验结果表明,在本文实验的四种模型中,RoBERTa_wwm_ext_Chinese+Transformer模型效果优于当前较好的方法,也优于在一开始就进行中文分词的HWC+Transformer方法。从测试集中抽取的样例显示,RoBERTa_wwm_ext_Chinese+Transformer模型生成的摘要具有较强的理解能力、抽象能力、正确度、流畅度与可读性,具有较好的应用前景。未来下一步将探究BERT在长文本摘要上的应用。
