环境减灾二号A/B卫星在森林树种识别中的应用
2022-07-12高金萍于慧娜王月婷高显连张晓丽
高金萍 于慧娜 王月婷 高显连 张晓丽
(1 国家林业和草原局林草调查规划院,北京 100714)(2 北京林业大学,北京 100083)
森林是陆地生态系统的主体,也是林业和草原行业主要的空间服务对象,在维护生态平衡、应对气候变化中发挥着重要作用[1]。森林资源的分布状况直接影响国家重大林业和草原资源监测规划与管理政策的制定。森林类型信息是森林管理的基础数据,准确的森林类型及树种识别对绘制林相图、清查森林资源、反演森林地上碳储量、监测物种多样性及森林资源可持续管理具有重要意义[2]。传统的手段基本为人工调查,由于森林分布广、遍布山头地块,野外调查耗费大量人力和成本[3],对于环境复杂、人力无法到达的林区很难开展森林资源调查工作,且重复监测周期较长[4]。近年来迅速发展的遥感技术可全面、快速掌握林草资源各种信息,在森林资源调查及森林树种识别等方面发挥着重要作用,成为越来越重要的林草行业监测技术手段[5-6]。
世界观测-2(WorldView-2)、高分二号等卫星的高分辨率遥感影像具备较高的空间分辨率,近年来在森林树种识别领域研究甚多[7-11]。与中低分辨率影像相比,高分辨率影像的空间信息更加丰富,但其数据量庞大,处理时对计算机性能要求较高,且价格相对昂贵,在较大区域尺度开展森林精确识别应用具有一定的局限。此外,分辨率提升的同时,光谱谱段会有所减小[12]。相对而言,中高分辨率遥感影像既可提供丰富的光谱信息,又可以提供清晰的结构信息,在区域尺度森林树种识别领域具备独特的优势。近年来,我国陆续研发了具备宽覆盖、中高空间分辨率及短重访周期等特征的卫星(如高分一号),利用中分辨率遥感影像进行树种识别的研究也逐步增多[13-14]。
2020年9月27日,我国在太原卫星发射中心以“一箭双星”方式成功发射环境减灾二号A/B卫星,用于接替已在轨运行12年的环境减灾一号A/B卫星。2颗卫星技术状态相同,双星组网可实现不大于2天的多光谱和红外数据无缝覆盖、不大于21天的高光谱数据无缝覆盖,大幅提高我国中分辨率可见光、红外及高光谱遥感数据获取能力,最大限度地满足各行业和部门对中高空间分辨率、高时间分辨率、高光谱分辨率、宽观测幅宽性能卫星影像的应用需求。环境减灾二号A/B卫星多光谱谱段含有丰富的光谱信息,除具有传统卫星的蓝、绿、红、近红外谱段,还多了一个能反映绿色植物生长状况的红边谱段,可提供植被状态的关键信息。目前,森林树种识别方面的研究大多是基于国外卫星数据和其他国产卫星数据,对环境减灾二号A/B卫星数据在树种识别中的应用研究还未开展。本文针对环境减灾二号A/B卫星,利用在轨测试期间获取的数据首次开展森林类型及主要树种识别的业务应用研究,采用卫星多光谱和高光谱数据,提取光谱特征、植被指数和纹理特征等信息,通过支持向量机(SVM)、原型网络等分类方法进行试验区森林类型及主要树种的识别,初步评价环境减灾二号A/B卫星数据在林业和草原行业的业务应用能力,为后续充分发挥其应用潜力、更好地服务林业和草原行业奠定基础。
1 试验区概况
综合已有的地面调查数据、森林植被代表性、在轨测试期间卫星影像覆盖情况等因素,选择福建武夷山国家公园和东北虎豹国家公园2个区域作为试验区。
1.1 福建武夷山国家公园
武夷山国家公园位于福建省北部与江西省交界处,地理坐标为117°24′13″E-117°59′19″E,27°31′20″N-27°55′49″N,总面积1001.41 km2。武夷山国家公园地处内陆山区,主要山脉大致呈东北-西南走向,地势为西北、东北高,西南、东南低,自西向东分别属于中山、中低山和丘陵地貌区,海拔1630 m(九重天),属中亚热带季风气候区。武夷山四季气温较均匀,温和湿润,总体年均气温17~19 ℃,1月均温6~9 ℃,极端最低气温可达-9 ℃,7月均温28~29 ℃;年均降水量1684~1780 mm,是福建省降水量最多的地区。
武夷山国家公园以森林生态系统为主体,森林覆盖率达到87.86%;有常绿阔叶林、针阔叶混交林等多种植被类型,是世界同纬度保存最完整、最典型、面积最大的中亚热带森林生态系统。
1.2 东北虎豹国家公园
东北虎豹国家公园位于我国吉林省和黑龙江省交界处,地理坐标为129°5′0″E-131°18′48″E,42°31′06″N-44°14′49″N,总面积为1.492 6×108km2。虎豹公园海拔在1500 m以下,大部分山体海拔在1000 m以下,相对高度在200~600 m。以中低山、峡谷和丘陵地貌为主,土壤以暗棕壤和沼泽土为主,属大陆湿润性季风气候区,年平均气温5 ℃,年降水量变化在450~750 mm。
东北虎豹国家公园以森林生态系统为主体,森林面积1.387 3×104km2。森林类型以针阔混交林为主,面积9.668×103km2,占森林面积的68.97%;阔叶林3.383×103km2,占24.38%;针叶林89.1 km2,占6.42%。原生性红松阔叶混交林仅呈零星分布,次生林分布广泛,以白桦林、山杨林、栎林为主。该区域树种组成复杂、分布零散,了解该区域主要森林类型或树种组成对反映该区域森林资源丰富程度及天然林保护状况具有重要意义。
2 采用数据
2.1 遥感数据
环境减灾二号A/B卫星均配置了4类光学载荷,包括16 m相机、高光谱成像仪、红外相机和大气校正仪。其中:16 m相机由4台可见光CCD相机组成,通过视场拼接可提供幅宽为800 km的多光谱影像;高光谱成像仪幅宽为96 km;红外相机幅宽为720 km;大气校正仪可在轨同步获取与16 m相机同视场的大气多谱段信息,进行大气辐射校正。卫星多光谱数据空间分辨率为16 m,包含B1(0.45~0.52 μm),B2(0.52~0.59 μm),B3(0.63~0.69 μm),B4(0.77~0.89 μm),B5(0.69~0.73 μm)共5个谱段。高光谱数据在0.45~0.92 μm包含100个谱段,空间分辨率为48 m,平均光谱分辨率优于5 nm;在0.90~2.5 μm谱段包含115个谱段,空间分辨率为96 m,平均光谱分辨率优于14 nm。
在福建武夷山国家公园和东北虎豹国家公园2个试验区,选取云量不超过5%、质量较好的多光谱影像各2景,数据等级为L1A级,数据获取时间分别为2020年12月6日和2020年10月20日,能基本覆盖2个试验区。在福建武夷山国家公园试验区内选取质量较好的高光谱影像,影像获取时间为2021年2月20日,云量为0%;东北虎豹国家公园试验区内没有合适的数据源,故该试验区不采用高光谱数据。
2.2 样地调查数据
获取2个试验区的实测样地数据,样地为半径为15 m的圆形,均匀分布于各试验区。以样地的优势树种信息作为选取主要树种分类的训练和验证样本数据的依据。
3 研究方法
森林类型及树种识别应用主要包括数据预处理、特征提取、训练分类和精度评价等关键环节,总体技术过程见图1。
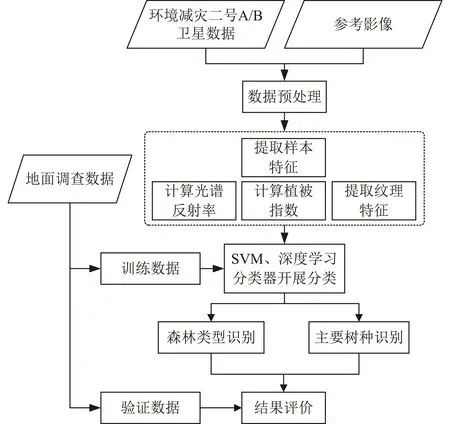
图1 森林类型及树种识别过程Fig.1 Process of forest type and tree species identification
3.1 数据收集和预处理
收集在试验区获取的地面调查数据,建立试验区调查样本集。数据预处理主要包括辐射校正、大气校正、几何校正、正射校正等步骤。①辐射校正和大气校正。利用提供的数据定标参数完成辐射校正,利用快速大气校正模型对数据进行大气校正。②几何校正。基于哨兵-2(Sentinel-2)卫星数据,在影像上手动选择控制点,利用仿射变换模型对影像进行几何精校正。③正射校正。利用影像产品自带的有理多项式系数模型(RPC)文件进行自动正射校正,利用该模型和中国科学院计算机网络信息中心地理空间数据云平台(http://www.gscloud.cn)获取的30 m分辨率先进星载热反射和反辐射仪数字高程模型(ASTER DEM)数据对影像进行二次卷积法重采样处理,得到正射校正影像。
3.2 特征提取
很多森林树种之间比较相似,区分度不高,仅依靠光谱特征常会出现同物异谱或异物同谱的现象。文献[15-17]中结果表明:在光谱特征基础上结合纹理特征、植被指数等信息,能更准确地区分森林树种信息,有效提升树种识别的精度。
1)光谱特征
不同地物类别因组成与结构差异而具有不同辐射特征和谱段反射率,在遥感影像中具有不同的亮度值,以此来区分不同地物。谱段反射率均值计算公式为
(1)
式中:i为谱段序号;ρi为第i个谱段的反射率;n为谱段数。
2)植被指数
归一化植被指数(NDVI)是应用最广的植被指数,该指数可以监测植被生长状态,有效反映植被覆盖情况,其取值范围是[-1,1],在植被区域显示为正值,值越大代表植被覆盖度越高。NDVI计算公式为
(2)
式中:INDVI为归一化植被指数值;ρN为近红外谱段反射率;ρR为红光谱段反射率。
3)主成分变换变量
主成分分析是基于变量之间的相关关系,在尽可能不丢失信息的前提下进行的线性变换,常用于信息增强和数据压缩。它是对某一多光谱影像X,利用变换矩阵A进行线性组合,而产生一组新的多光谱影像,表达式为
Y=AX
(3)
式中:X为变换前的多光谱空间的像元矩阵;Y为变换后的主成分空间的像元矩阵;A为X空间协方差矩阵∑X的特征向量矩阵的转置矩阵。
变换后,前三主成分能够包含90%以上的信息,第四主成分多数为噪声,在谱段组合时只使用前三主成分即可。
4)纹理特征
影像中地物的重要信息可以通过纹理分析获取,灰度共生矩阵(GLCM)是从影像上像素之间的灰度空间相关角度来描述纹理。影像灰度的变化包括方向、相邻间隔和变化幅度等综合信息,都可以通过GLCM反映。基于GLCM可提取8个纹理特征[18],即对比性(CO)、协同性(HO)、二阶矩(SE)、熵(EN)、均值(ME)、相异性(DI)、方差(VA)、相关性(CC)。纹理特征是基于主成分分析后的第一主成分提取的,窗口大小设置为3×3,方向为45°,步长为1。
3.3 分类方法
机器学习理论与方法已成为遥感影像分类的重要技术手段,遥感影像的样本数量相对较少,是制约分类精度的关键因素。SVM和原型网络方法分别作为浅层机器学习和深度学习中小样本分类的代表方法法,已得到了广泛应用。
(1)SVM从20世纪90年代被提出,在影像识别领域已经得到了广泛应用,理论基础和技术方法较为成熟[19]。典型的SVM需要一组输入数据和训练目标,对于每个给定的输入,其分类结果可能是两个类。给定一组训练样本,每个样本都被标记为属于两个类别之一,SVM算法通过建立一个模型从而把新的样本分类到一个或者另一个类别中去。该算法模型把在空间中表示为点的对象映射为两类,而且两类样本之间的分类间隔最大。新的对象将会被映射到同样的空间并基于其落在间隔的哪一边来预测属于哪一种类别。这一算法是基于定义决策边界的决策平面的概念,一个决策平面用来区分一系列具有不同类别成员关系的对象。SVM模型中具有不同的可用的内核,常用的核函数有线性核、多项式核、高斯核和径向基核,其中,径向基核函数是SVM使用的内核中最为普遍的一种选择[20]。
(2)原型网络分类的原理是每个类的点都围绕1个原型进行聚类。通过神经网络学习输入到嵌入空间的非线性映射,并以支持集的平均值作为其在嵌入空间中类的原型。然后,查找最近的类原型,即可对嵌入式查询点进行分类。以窗口大小为S·S的切片数据作为原型网络的输入源。嵌入函数架构根据裁剪数据窗口大小由不同数量卷积块组成(Layer 1,…,LayerN,Layer last)。每个卷积块包括1个卷积层(Conv2d),1个批量归一化层(Batch_norm),1个非线性激活函数(Relu)及1个最大池化层(Max_pool2d)。全连接层(Flatten),将最后1个卷积块的输出(1×1×F,F为通道数)作为输入,通过全连接层(Flatten)转化为F个特征值。计算投影空间中查询集到各个类原型的欧氏距离,使用Softmax激活函数计算属于各个类别的概率,作为分类依据[21-22]。
本文使用的原型网络以5个谱段作为输入,采用的卷积层的输出特征值数F为64,卷积核为3×3。最大池化层的池化核为2×2。此网络结构将产生64维输出空间。使用相同的嵌入函数对支持集和查询集进行运算,并将其作为损失和精度计算的输入参数,所有的模型都是通过Adam-SGD优化器进行训练的,初始学习率为1×10-3,每2000次训练将学习率减半。使用欧式距离作为度量函数,训练原型网络。
3.4 精度评价
(1)SVM分类精度评价。通过检验样本建立混淆矩阵,检验分类结果的准确性,选取的精度验证指标包括分类精度、Kappa系数、总精度。
(2)原型网络分类精度评价。原型网络分类精度包括网络训练精度和测试精度。训练精度通过训练过程中最后1个epoch的精度(LEA)表示,即每次迭代的平均总体精度。测试精度通过总精度与Kappa系数表示。
4 测试结果与分析
针对环境减灾二号A/B卫星的多光谱和高光谱数据,分别提取2个试验区影像的光谱特征、NDVI和基于主成分第一分量的8个纹理特征。其中,高光谱是基于前100个可见光谱段,提取了主成分分析后的前5个特征变量作为分类的特征量。
4.1 武夷山国家公园分类结果
根据野外实测样地的优势树种信息,选取针叶林、阔叶林、杉木样本各200个,同时结合目视解译和影像质量,选取裸地、水体、农田和道路建筑4类地物,每类地物各选取样本200个。每类地物及森林树种各选取90个验证样本。分别采用SVM和原型网络分类进行试验区主要地类和森林树种识别,并对识别结果进行精度评价。
1)应用SVM的森林树种识别
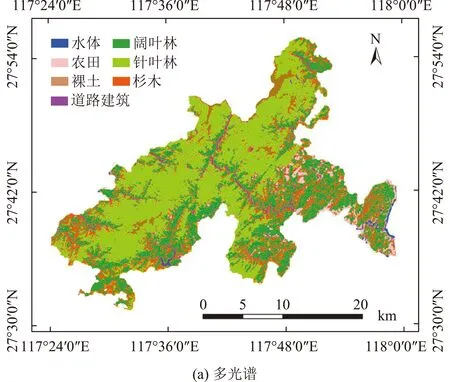
本文采用多光谱数据,选择高斯核函数,设置参数gamma为0.2,惩罚因子为100。基于特征变量对各类地物及森林主要树种进行识别,并利用验证样本进行精度评价,结果见表1。其中:针叶林和阔叶林的多光谱分类精度分别为88.61%和86.36%,杉木的多光谱分类精度略低,为54.47%;总精度为86.37%;Kappa系数为0.83。图2为应用SVM的武夷山国家公园主要树种识别情况。
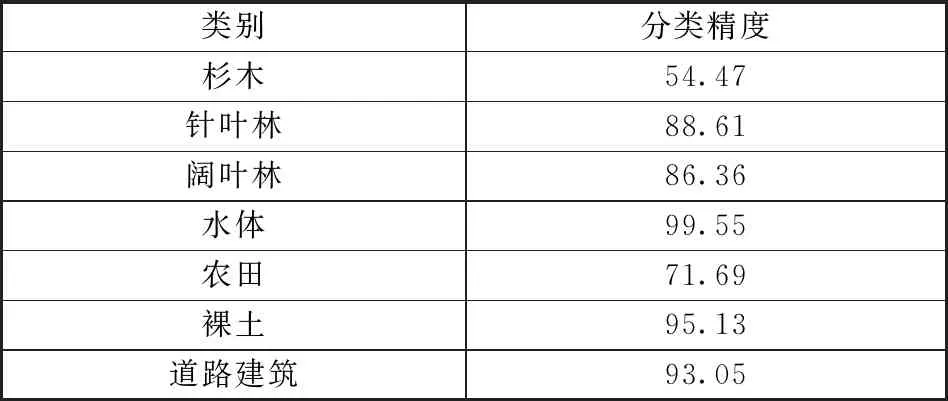
表1 应用SVM的主要树种识别分类精度Table 1 Classification accuracy of main tree species identification using SVM %
2)应用原型网络分类的森林树种识别
本文分别采用多光谱和高光谱数据,通过设置不同窗口大小来比较分类精度,最终设置窗口大小分别为21×21像元和17×17像元。利用验证样本对分类结果进行精度评价,见表2。其中:针叶林和阔叶林的多光谱分类精度分别为94.62%和79.66%,杉木的多光谱分类精度为92.96%,较SVM方法有了明显提升;多光谱和高光谱总精度分别为91.11%和83.79%,Kappa系数分别为0.90和0.81。图3为应用原型网络分类的武夷山国家公园主要树种识别情况。
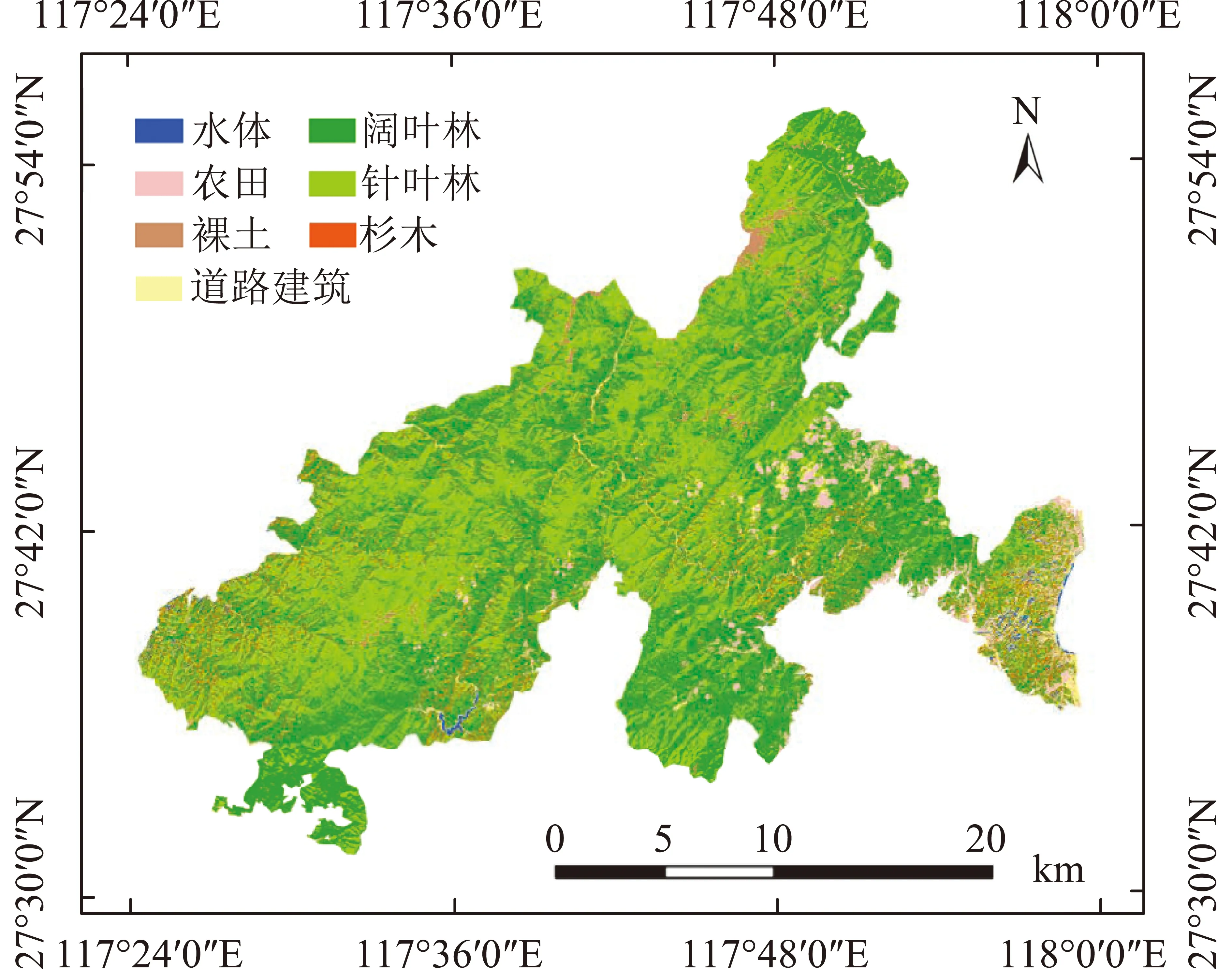
图2 应用SVM的武夷山国家公园主要树种识别情况Fig.2 Main tree species identification using SVM in Wuyishan National Park
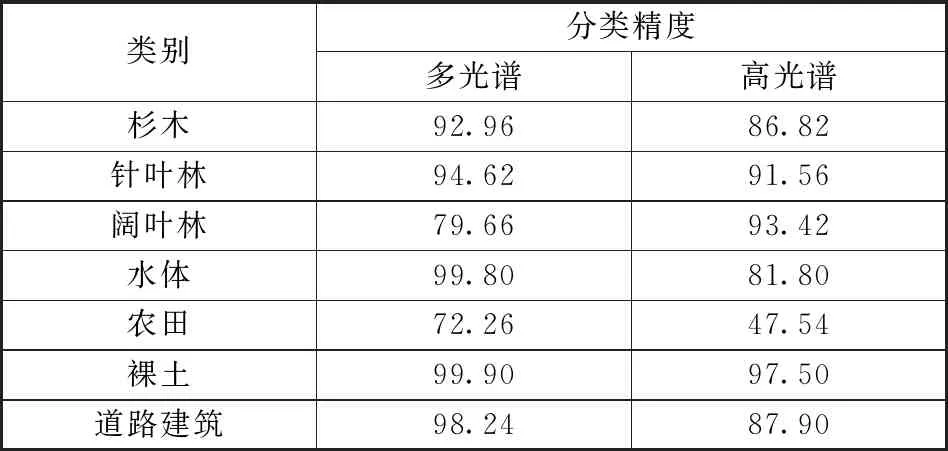
表2 应用原型网络分类的主要树种识别分类精度Table 2 Classification accuracy of main tree species using prototype network classification %
4.2 虎豹国家公园分类结果
根据野外实测样地的优势树种信息,选取针叶林、阔叶林、云杉样本各200个。同时,结合目视解译和影像质量,选取了裸地、水体、农田、道路建筑、云和阴影6个类别,每个类别各选取样本200个。每个类别及森林树种各选取90个验证样本。
1)应用SVM的森林树种识别
基于特征变量对各类别及森林主要树种进行识别,并利用验证样本进行精度评价,见表3。其中:云杉、针叶林和阔叶林的分类精度分别为90.14%,88.65%,79.29%;总精度为91.77%;Kappa系数为0.90。图4为应用SVM的东北虎豹国家公园主要树种识别情况。
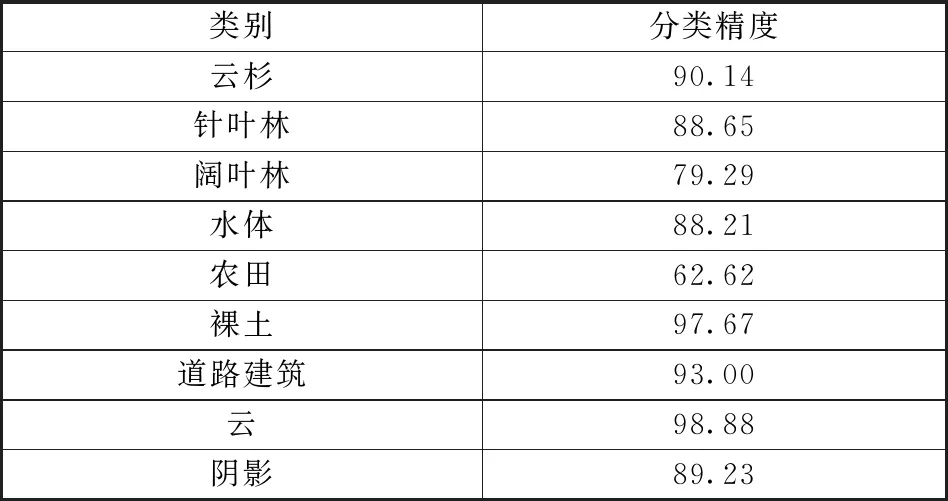
表3 应用SVM的主要树种识别分类精度Table 3 Classification accuracy of main tree species identification using SVM %
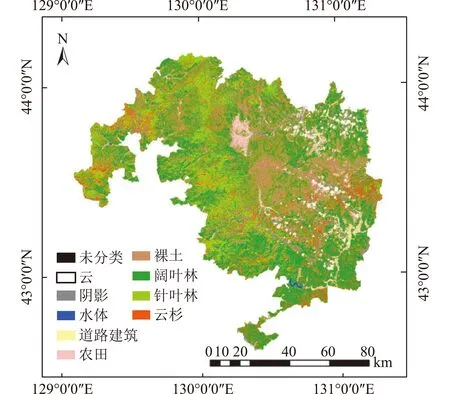
图4 应用SVM的东北虎豹国家公园主要树种识别情况Fig.4 Main tree species identification using SVM in Hubao National Park
2)应用原型网络分类的森林树种识别
通过设置不同窗口大小来比较分类精度,最终设置窗口大小为17×17。基于特征变量对各类别及森林主要树种进行识别,并利用验证样本进行精度评价,见表4。其中:云杉、针叶林和阔叶林的分类精度分别为79.32%,96.32%,92.21%;总精度为91.34%;Kappa系数为0.90。图5为应用原型网络分类的东北虎豹国家公园主要树种识别情况。
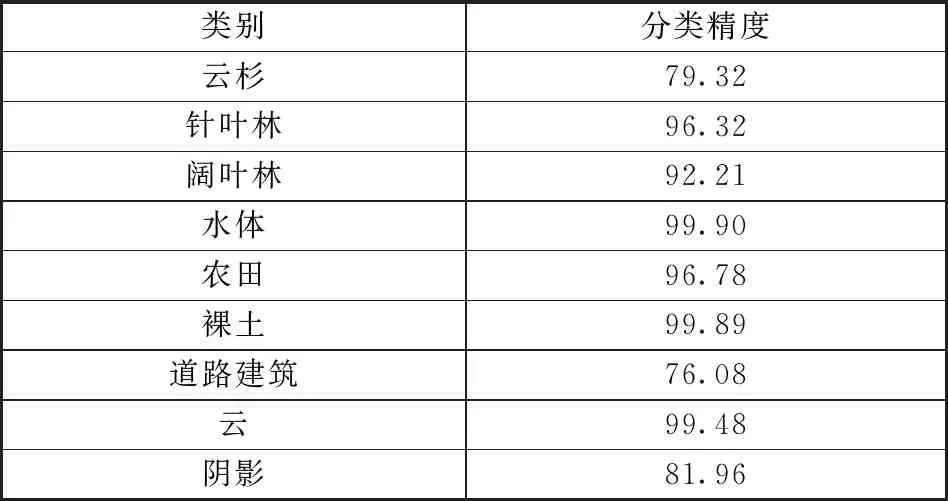
表4 应用原型网络分类的主要树种识别分类精度Table 4 Classification accuracy of main tree species identification using prototype network classification %
5 结论
本文采用环境减灾二号A/B卫星多光谱和高光谱数据,在福建武夷山国家公园和东北虎豹国家公园2个试验区开展森林类型及主要树种识别的应用研究,总结如下。
(1)分类模型的选择对于分类效果具有重要影响。在福建武夷山国家公园试验区,原型网络分类对主要树种识别的精度整体要优于SVM;在东北虎豹国家公园试验区,SVM对云杉的识别精度更好,但在针叶林和阔叶林的识别上,原型网络分类表现更佳。
(2)2个试验区的主要树种识别精度较高,杉木和云杉最优分类精度分别为92.96%和90.14%。东北地区森林结构相对简单,而福建森林结构更为复杂,树种类型众多交错,因此福建武夷山国家公园森林类型及主要树种识别精度略低于东北虎豹国家公园。
(3)环境减灾二号A/B卫星在轨测试期间,由于时间和数据等约束条件,只做了局部试验区的在轨测试,实现了部分类型地类和树种的识别和分类。为提高卫星在林业和草原资源监测的应用能力,后续需要持续探索卫星数据在我国不同地区、不同地类、不同树种分布等多种情况下的应用能力。
