基于迁移学习的磁瓦缺陷分类方法
2022-07-11李昊璇刘海峡
李昊璇, 刘海峡
(山西大学 物理电子工程学院, 山西 太原 030006)
0 引 言
随着自动化技术的快速发展, 磁瓦在永磁电机中的应用越来越普遍, 对相关产品的性能起着重要的作用[1]. 由于冶金技术没有达到标准化程度, 磁瓦在生产过程中不可避免地会产生各种缺陷, 这些缺陷会导致磁瓦剩余磁感应强度、 磁能量以及抗老化等功能受到影响. 因此, 表面缺陷检测过程的自动化已成为磁瓦行业的一项紧迫任务. 目前, 磁瓦表面的缺陷主要由经验丰富的检测人员来评估, 由于检测人员长时间的肉眼观察会导致视觉疲劳, 会产生检测结果不稳定和一定的漏检或误检, 不适合大规模的工业生产[2]. 近年来, 图像处理技术和机器视觉技术在表面缺陷检测领域得到了广泛的应用, 对解决磁瓦缺陷的分类识别有重大意义, 并已在大规模工业生产试验中得到了实践.
蒋红海等[3]使用快速离散余弦变换(Fast Discrete Curvelet Transform, FDCT)提取特征, 并用支持向量机(Support Vector Machine, SVM)分类器进行缺陷分类, 结果显示, 分类正确率可达到83%. Huang等[4]提出了一种局部感受野的极限学习机(Local Receptive Fields Based Extreme Learning Machine, ELM-LRF)方法, 应用于磁瓦表面缺陷检测分类, 将局部感受野概念引入到极限学习机(Extreme Learning Machine, ELM)算法中, 有效提高了缺陷检测的准确性. 传统表面缺陷检测算法通过人为提取特征难以实现较高的检测精度, 刘畅等[5]针对此问题提出一种改进的Unet模型磁瓦缺陷检测识别算法, 检测正确率达到了94%. Huang等[6]提出一种实时多模块神经网络模型, 该模型可以实现在较短时间内对磁瓦表面所含缺陷的检测. 赵月等[7]利用深层卷积神经网络(Deep Convolution Neural Network, DCNN), 并结合Faster RCNN方法来解决人工检测效率低和误检率高等问题, 实现了较高的检测精度. 机器学习方法在工业缺陷检测领域取得了一定的成功, 然而, 当数据量较少时, 传统机器学习方法难以达到较高的识别精度.
迁移学习方法非常适合用来解决这一问题. 迁移学习旨在利用其他领域的数据、 特征或模型中的信息帮助目标领域任务的训练, 它能够加快模型的训练效率并减少网络对训练样本量的需求. 目前, 迁移学习已经广泛应用于计算机视觉、 自然语言处理、 推荐系统、 行为识别等领域[8]. 迁移的模型一般选用DCNN, 迁移策略主要可以分为两种, 一种是在大型图像数据集ImageNet上预训练的经典DCNN, 如Inception系列、 GoogLeNet系列、 ResNet系列、 VGG系列. 张立等[9]使用AlexNet网络, 结合参数迁移学习策略来解决少量样本导致网络过拟合和识别精度低的问题. 另一种是研究人员根据研究任务设计各种DCNN. 两种迁移策略在迁移过程中可以对结构进行调整, 也可以只对参数进行微调.
本文结合第一种迁移策略, 提出了一种磁瓦表面缺陷分类方法. 将图像识别领域中经典的VGG16网络迁移到磁瓦缺陷分类中, 使用VGG16网络在大型图像数据集ImageNet上进行预训练, 调整目标网络结构并将参数迁移, 然后利用磁瓦缺陷图像数据集微调改进VGG16模型, 从而提高模型的识别精度和泛化能力.
1 数据集及预处理
1.1 数据集
本文采用的1 344张磁瓦缺陷数据是由中国科学院自动化所收集的数据集. 由于磁瓦有各种各样的缺陷, 根据缺陷特点的不同, 磁瓦数据集被分为6个子数据集, 如图 1 所示. 数据集中各类型磁瓦图像具体数目如表 1 所示.

图1 缺陷样例Fig.1 Defect example

表 1 磁瓦缺陷图像原始数据集说明Tab.1 Description of the original dataset ofmagnetic tile defect images
1.2 数据增强
由于磁瓦缺陷数据样本中各类型分布极不均匀且总样本较少, 导致在模型训练时会出现过拟合的现象. 通常采用数据扩增的方法来防止模型过拟合, 一般采用的数据扩增方法有图像翻转、 旋转、 裁剪和转换. 本文采用图像翻转的方法扩充磁瓦数据样本. 经过数据集的水平翻转后, 破损型缺陷集有170 张图片, 裂纹型缺陷集有 114张图片, 磨损型缺陷集有64张图片, 不均匀型缺陷集有206张图片, 气孔型缺陷集有228张图片, 无缺陷数据集有1 906张图片.
2 基本原理
2.1 迁移学习
迁移学习是机器学习的一种研究方法, 它能够利用从其他任务中获取的知识来帮助进行当前任务试验. 迁移学习可以有效解决数据量小、 任务变化等问题, 其关键点是找出新问题和原问题之间的相似性. 迁移学习过程如图 2 所示, 迁移学习不仅利用目标任务中的数据作为学习算法的输入, 还利用源域中的学习过程(包括训练数据、 模型和任务)作为输入.

图2 迁移学习流程图Fig.2 Flow chart of transfer learning
在本文方法中, 源域表示ImageNet数据集, 源任务表示ImageNet下的图像分类; 目标域表示磁瓦缺陷数据集, 目标任务表示磁瓦缺陷图像分类. 由于两个数据集均为图像数据, 具有一定的相似性, 所以, 它们的低级特征是通用的.
根据迁移内容的不同, 迁移学习一般可以分为基于样本的迁移、 基于特征的迁移和基于模型的迁移. 基于样本的迁移是将源域中的部分数据通过加权等方式用于目标任务的训练. 基于特征的迁移是利用源域和目标域数据学习新的特征表示. 基于模型的迁移方法是利用预训练好的源模型获取到的具有通用性的结构, 目标模型可以迁移这些通用性的结构, 被迁移的知识是模型参数内含的通用结构. 目前广泛使用的预训练技术就是一种基于模型的迁移学习方法. 具体而言, 预训练是首先使用足够的可能与目标域磁瓦数据不尽相同的源域数据训练深度学习模型, 然后使用一些有标签的目标域数据对预训练的深度模型的部分参数进行微调, 例如, 在固定其他层参数的同时精细调整若干层的参数.
2.2 VGG16
VGG16由牛津大学视觉几何组提出, 是由13个卷积层和3个全连接层组成的卷积神经网络结构. VGG16网络没有采用大尺寸的卷积核, 而是采用多个大小为3×3的卷积核, 这种结构在提高网络特征提取能力的同时, 减少了网络参数[10]. VGG16网络相较于AlexNet网络有更多的隐藏层, 并且其作者发布了多个版本的VGGNet, 其中最常用的是VGG16和VGG19, 数字表示网络内部隐藏层的数目. VGG16网络结构如图 3 所示.
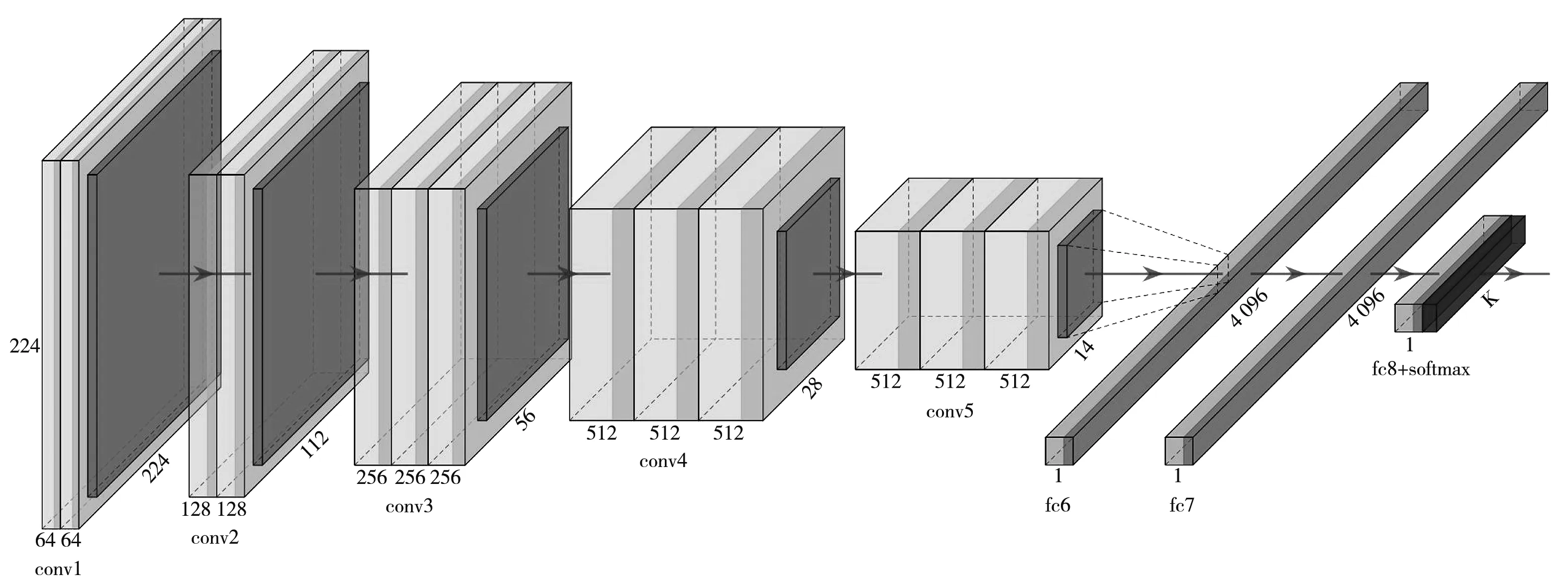
图3 VGG16网络结构图
VGG网络包含卷积层、 激活层、 池化层和全连接层4个层次结构. 卷积层在CNN中起着非常重要的作用. 一方面, 通过权重共享, 同一特征图中的神经元共享相同的参数, 减少了参数总数, 但也使得CNN对位置和移动不太敏感[11]. 另一方面, 由于每个卷积运算针对的是一小块输入, 因此, 提取的特征保留了输入的固有拓扑结构, 有助于识别模式. 卷积层之后通常是一个池化层, 其作用是降低特征图的分辨率, 同时参数和计算量也相应减少. 在全连接层中, 神经元从2维转换为 1维. 当前层中的每个单元都连接到前一层中的所有单元, 它以更复杂的方式提取特征, 以便深入挖掘更多信息, 并且将不同位置的模式连接起来.
本文通过对VGG16网络全连接层结构进行微调, 来适应对样本量较少的磁瓦缺陷图像的分类识别. 调整后的VGG16网络结构如表 2 所示.
原始VGG16网络中第2个全连接层神经元的个数为4 096, 因为该全连接层和softmax分类层连接, 所以其神经元个数需要参考实验的类别数来设置. 原始的VGG16网络是在ImageNet图片数据集下训练的, 该数据集的类别数为1 000, 而本文中缺陷数据集的类别数为6, 所以, 该参数设置不宜太大, 否则会导致全连接层参数量过多, 容易引起网络过拟合. 本文将该参数分别设置为32, 64, 128, 256进行实验, 并对实验结果进行比较. 结果显示, 将其设置为128时, 训练效果最好, 因此, 本文将第2个全连接层神经元个数设置为128, 并将分类层的输出类别数由1 000改为6. 调整后的网络训练参数大大减少, 更适用于少样本磁瓦缺陷数据的分类.

表 2 调整后的VGG16结构Tab.2 Adjusted VGG16 structure
3 实验结果及分析
3.1 深度学习环境
本文实验环境配置如下: 英特尔 Xeon(至强)E5-2680 v4 14核处理器, Nvidia Quadro P1000主显卡, CUDA-11.1、 CUDNN-11.1深度学习库, keras深度学习框架, 64 GB 内存, Windows 10 操作系统.
3.2 网络模型超参数设置
模型的超参数对模型性能有一定的影响, 合适的超参数可以提高模型的收敛速度和精度[12]. 批量大小表示模型训练过程中每一步使用的图像数量, 这个数量决定了梯度下降最快的方向. 模型收敛速度随着批量大小的增加而加快. 批量大小的选取应该适中, 若批量大小过大, 可能导致显存不够和训练loss不下降; 若批量大小过小, 则每个batch包含的信息过少, 网络不易收敛. 因此, 本文选择批量大小为 64 来训练模型.
学习率是影响模型收敛速度的主要因素. Adam是一种学习率的自适应梯度更新方法, 对初始学习率的设置依赖较小, 可有效减少局部最优解的出现. 因此, Adam 被选为学习率优化方法. Adam优化算法虽然对初始学习率不是很敏感, 但它仍然是影响模型收敛速度的重要超参数. 合适的初始学习率可以加快模型的收敛速度. 初始学习率过大时, 可能会直接收敛到局部最小值点; 学习率过小又会导致收敛速度缓慢. 通过多次的训练调试, 当学习率为10-4时, 可以有较好的训练过程, 故选择10-4作为初始学习率.
参数的设置对分类器训练有着非常重要的作用, 在正式对磁瓦数据进行网络训练之前, 需要预训练网络模型, 进而选取合适的模型参数. 卷积神经网络模型参数设置如表 3 所示.

表 3 深层卷积神经网络的模型参数Tab.3 Model parameters of deep convolutional neural network
3.3 实验结果分析
为验证本文缺陷分类方法, 按照8∶2的比例将每类缺陷样本划分为训练集和测试集, 再将6类样本的训练集和测试集分别合并, 构成总的训练集和测试集, 这种划分方式可以保证训练集和测试集中各类样本比例相同. 为便于对网络进行调整, 使用同样的方法再将训练集中20%的样本划分为验证集, 磁瓦数据分布如表 4 所示. 由于数据集的图像大小不同, 统一将磁瓦缺陷图像大小调整为224 × 224×3, 以适应VGG16网络的输入格式.
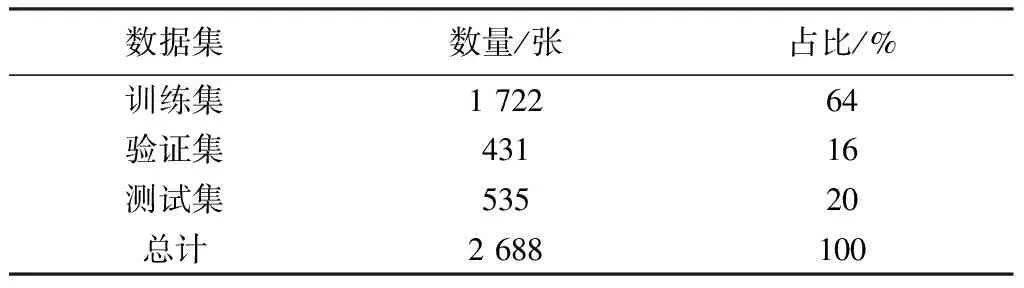
表 4 训练集, 验证集和测试集数据占比Tab.4 The proportion of training set, validation setand test set data
图 4 和图 5 分别为磁瓦缺陷识别正确率和损失函数随迭代轮数变化曲线图, 虚线代表训练过程, 实线代表验证过程. 可以看出, 模型大概在迭代轮数为20时趋于稳定; 当迭代轮数为40时, 训练正确率为100%, 验证正确率为97.52%; 模型在测试集上的分类识别率可以达到98.69%.
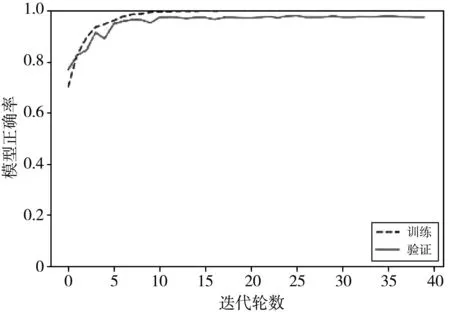
图4 磁瓦缺陷识别正确率曲线Fig.4 Accuracy rate curve of magnetic tile defect identification

图5 磁瓦缺陷损失曲线Fig.5 Defect loss curve of magnetic tile
实验使用混淆矩阵方法对试验结果进行分析. 如图 6 所示, 背景颜色代表分类准确率, 颜色越深, 则识别精度越高. 混淆矩阵的每一行代表磁瓦数据的真实样本类型, 该行的数据总数表示该类型的样本数目; 每一列代表预测样本类型, 该列的数据总数表示预测该类型的样本数目. 从图可以看出, 磨损缺陷的识别正确率最高, 为100%; 破损缺陷的识别率最低, 为94.11%.
精确率表示预测为某类样本中实际为该类别的比例, 召回率是某类样本中预测正确样本的比例,F1值是模型精确率和召回率的一种调和平均. 精确率、 召回率和F1值计算公式如下
精确率为
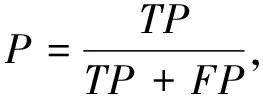
(1)
召回率为

(2)
F1值为

(3)
式中:TP,TN分别为被正确分为正类或负类的样本数目;FP,FN分别为被错误分为正类或负类的样本数目. 测试集分类结果如表 5 所示.

图6 混淆矩阵Fig.6 Confusion matrix
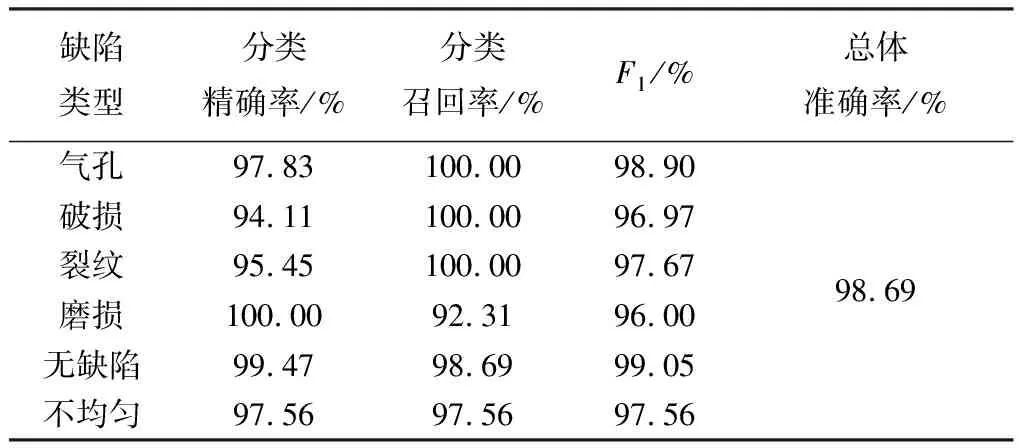
表 5 测试集分类结果Tab.5 Test set classification results
3.4 算法对比
为验证本文方法用于磁瓦缺陷分类的性能, 使用扩增的数据集, 分别将本文方法与支持向量机SVM, 人工神经网络(Architectural Neural Network, ANN), 极限学习机(ELM)3种分类算法的性能进行了比较, 结果如表 6 所示. 基于迁移学习的VGG16方法的训练准确率为100%, 测试准确率为98.69%, 在4种分类方法中均为最高, 表明该方法在磁瓦缺陷检测分类中具有显著的优越性.

表 6 4种分类方法分类结果对比Tab.6 Comparison of classification results of fourclassification methods
4 结 论
本文提出了一种基于迁移学习的磁瓦缺陷检测分类方法, 以解决由于磁瓦缺陷样本少引起的网络过拟合和网络训练时间过长等问题. 相对于传统的表面缺陷检测分类方法, 本文方法明显提高了磁瓦缺陷的检测效率, 降低了通过人为选取特征对系统检测精确度的影响. 这一结果也表明了迁移学习的优越性. 该方法借助在相关领域训练好的模型, 仅作部分微调就能够在少量训练样本上得到较高的识别效果. 实验结果同时也证实了磁瓦表面缺陷检测使用深层卷积神经网络的可行性, 满足了工业生产实时在线检测的需求, 为以后工业生产的实际应用创造了有利的条件. 本文仅采用翻转的方式扩充数据, 数据量仍然较少, 在下一阶段工作中, 将考虑采用生成对抗网络的方法扩充缺陷数据, 以实现更好的分类效果.
