基于知识图谱的长征红色文化资源数字化研究和应用
2022-07-11郭凌宇吴俊潮陈鑫姜赢耿之矗
郭凌宇 吴俊潮 陈鑫 姜赢 耿之矗
(1.北京师范大学珠海分校管理学院 广东省珠海市 519000)
(2.北京师范大学人文和社会科学高等研究院 广东省珠海市 519000)
红色文化资源是指中国共产党领导人民在长期革命斗争实践中形成的精神和史迹,具有教育价值、经济价值、和品牌价值。弘扬、传承、发展红色文化资源是实现民族复兴、建立文化自信、提升人民幸福感的需要。目前红色文化资源的数字化方式仅是载体层面上的数字化,存在分散民间、保护力度低却又不可再生、、信息内容缺乏立体性和直观性、共享性差、表达方式枯燥单一等问题,传统的信息资源数字化手段已经不能适应红色文化发展的需要。
“数字中国”建设实施以来,教育信息化程度不断提高,为红色文化资源更加完整、持久地保存,更好地传承与发展带来了机遇与挑战。长征是红色文化资源的重要组成部分,研究长征文化资源对整个红色文化资源体系的研究具有示范意义。本文以挖掘、整理、数字化长征红色文化资源为主旨,采用知识管理前沿技术知识图谱对长征文化资源进行有机的数字化整理,实现系统直观的信息展现。本研究不仅仅是对长征文化资源的集中整理和保护,更是对长征文化资源教育价值的充分发挥,对研究方法进一步探索,有利于推动重走长征路旅游产业的发展,促进长征沿线革命老区经济发展,助力扶贫工作的进行,对打造长征红色文化品牌生态链,提高人民幸福感具有重要意义。
本文发挥知识图谱的技术优势,关注红色资源载体与人们之间的互动和情感塑造,从长征历史文化丰富的地理信息资源出发,对长征文化资源进行了生动具体、贴近生活的数字化组织,为红色文化资源的数字化保护和弘扬提供应用示范。
1 研究现状
1.1 历史文化资源数字化现状
在历史文化资源数字化技术中,包括以下几种重要技术:数字图像处理技术、多媒体技术、数字内容管理与发布技术、3S 技术(遥感、地理信息系统、全球定位系统)、网络技术、三维技术、虚拟现实技术等。
国外,早在2000 年,美国就已启动“美国记忆”项目对美国国会图书馆和其它文献机构最有价值的历史文化资源进行了数字化保护,让超过500 万份的文献资料被数字化完成并在国会图书馆网站上向大众开放。欧洲数字图书馆(Europeana)是一个多达2300 个图书馆、美术馆、博物馆所参与的庞大的历史文化资源数字化联盟,共收藏了3000多万件元数据,其中有超过百分之三十的数据可以直接下载。该馆还与Google,Wikipedia,Linked Open Data 等合作,扩大数字化的历史文化资源的传播途径。
国内历史文化资源数字化工作的与起步较晚。陕西师范大学历史文化学院袁林教授为代表的一批兼爱中国古代文献和计算机技术的专家学者,完成了“汉籍全文检索系统”软件,目前己升级为4.20 版,收入文献2903 共种。2000 年,北京书同文电脑技术有限公司成功开发了《文渊阁四库全书》电子版。北哈佛大学和复旦大学共同构建的中国地理信息系统(CHGIS)、中华文明之时空基础架构(CCTS)在时空维度上对历史文化资源进行了整合。哈佛大学和北京大学合作的“中国历代人物传记数据库”(CBDB)收集了中国历史人物的信息及其之间的关系。
综上,历史文化资源在数字化方面已经取得不错的成果,但目前的数字化多是单纯的载体层面上的数字化,数字化成果之间没有形成一定的关联,处于相互孤立的状态。本文运用知识图谱,对当前的长征红色文化资源数字化成果作更深层次的数字化,使当前的长征红色文化资源载体数字化成果链接为一个整体,从而实现更好的数字化。
1.2 知识图谱在历史文化领域的应用现状
知识图谱(Knowledge Graph)是在2018 年由谷歌公司提出的概念,一开始的目的是为下一代智能搜索引擎提供技术支持。其主要核心是利用实体、实体之间的关系以及实体本身的属性来解决问题。但随着知识图谱的不断深入研究,这种全新的信息检索模式的应用范围逐渐拓展到了智能搜索、智能问答等领域。作为关系的最有效的表示方式,知识图谱描述了知识资源及本身的内容和它们相互之间的联系。
知识图谱在历史文化领域也获得了许多成果。北京师范大学周亦等人基于历史人物关系知识图谱,构建了历史人物关系可视化的系统。北京大学信息管理系基于哈佛大学费正清中国研究中心、中央研究院历史语言研究所及北京大学中国古代史研究中心三方合作构建的中国历代人物传记资料库(CBDB)数据, 以知识图谱的形式描述了宋代文人的学术师承关系, 为人文领域提供了崭新的研究方向和技术手段。同样的,肖大军利用中国历代人物传记资料库(CBDB)中的人物关系,构建了自动问答系统。
2 长征红色数字文化资源知识图谱的开发拟解决的关键问题
2.1 本体库的构建
本体来源于哲学领域,解释为存在于现实事物之外的“事物本身”。和知识图谱相似的,本体也常根据其涉及的知识的广度和深度被分为通用本体和领域本体。面向不同的领域,本体构建方法一般有:SENSUS 法、七步法等,常用的本体构建工具有WebOnto 等,经常被使用的本体构建语言有:RDF、RDFS、OWL 等。
长征红色文化资源领域本体构建旨在结构化地表示各类长征红色文化资源以及它们之间的联系。本文基于斯坦福大学开发的开源知识编辑工具Protégé,采用“七步法”进行本体构建。合现有可搜集到的长征数字化红色文化资源的基本结构,再辅以领域专家的指导,构建长征红色文化资源领域本体知识模型,为长征红色文化知识图谱的构建提供逻辑支撑。
“七步法”的主要步骤分别是:
(1)明确本体的范围和领域;
(2)是否存在可用本体库;
(3)列出本体的重要术语;
(4)确定类及其等级;
(5)确定类的属性;
(6)确定属性约束;
(7)创建实例。
2.2 长征红色数字文化资源的获取
可以对“长征红色文化资源”做一个简单的定义:在长征长达两年的时间里(1934 年10 月-1936 年10 月),在长征中做出过有一定影响事迹的、在长征过程中牺牲的革命志士和革命烈士;革命志士或革命烈士曾使用过的物件、战斗过的军事遗迹古战场、居住过的遗址;长征过程中的服饰、创作的诗歌;有着重大影响的长征历史事件;长征沿途革命老区的人文自然风光;后人对长征内容再建立或创作的纪念建筑、画作、雕塑、影视作品,以及评论解读,史实记载,亲历者口述等。红军长征历时两年零五天,行程约二万五千里。其中,中央红军共进行了 380 余次战斗,攻占 700 多座县城,牺牲营以上干部 430 人,击溃国民党军数百个团,跨越 11 个省(江西、福建、广东、湖南、广西、贵州、云南、陕西、四川、西康、甘肃),翻越 18 座大山,跨过 24 条大河。这段历史被称为“地球上的红飘带的历史拥有比较丰富的内容。但是,现阶段部分长征红色文化资源的保护力度不够高却又不可再生,其开发形式也往往单一而不系统,仍未被充分深入挖掘,这对全方位地整理长征红色文化资源并进行数字化提出了迫切需求和挑战。由于已经数字化的长征红色文化资源分布较为分散,目前没有一个较为完备的知识库对所有的长征相关红色数字文化资源进行整合,因此,本文以《红军长征纪实丛书》、《今日长征路图集》、《长征画典》等长征相关书籍中各个长征红色文化资源的名称为关键词,在分散的数据来源间进行数字文化资源采集。长征在线教育网站、长征沿线地方政府数据库、读秀、超星图书馆、中国知网等学术资源数据库中以及网络知识百科中存在着大量已有的长征红色文化电子资源。本文针对不同的数据来源,设计网络爬虫、构建数据标注工具等不同的数据抽取方案,进行特征提取和筛选分类,再构建知识图谱进行数字化整合。在历史领域专家的指导下,对所获得的内容进行筛选分类,融入数字化长征红色文化资源库,并基于该资源库进行知识图谱的映射聚合。
3 模型与流程
3.1 数据获取
长征红色文化资源的来源较为广泛。按照数据的类型,可以分为结构化、半结构化和非结构化数据。例如书本中的内容绝大多数是非结构化知识,而来自网络百科中的内容绝大多数是结构化的知识。针对非结构和半结构化的数据,需要使用一定的手段和工具将其转为所想要的格式。本文主要以Python 为工具,利用网络爬虫、命名实体识别、图像文本识别等技术手段,从知识百科、图书文本以及长征相关博物馆官网等网站中采集数据,从而为下一步的知识抽取任务提供基础。
3.2 知识抽取
本文的数据来源多样,结构也各不相同,需要将这些来源和结构各异的数据转化为想要的统一格式进行存储。同时,在数据的存储过程中,需要有一定的规范约束,保证数据的合法性。Protégé是斯坦福大学医学院基于Java 语言开发的本体编辑工具,用于创建、可视化、操纵各种表现形式的本体,具有严格的语义规则约束。本文使用Protégé 知识编辑工具,提前定义好前文所构建的长征红色文化资源本体库模型,将收集到的结构化后的数据进行编辑录入。这些数据主要包括实体和属性。属性又分为数据型属性和对象型属性。所有的实体关系、实体属性的定义全部都在这一阶段完成。基于Protégé 工具的本体构建,可以很好地将知识图谱约束在定义好的框架内,防止类别分散、实体或属性重名、关系或属性冗余等情况的发生。此外,Protégé 还内接了强大的推理功能,可以帮助拓展完善更多实体间的逻辑属性关系。
3.3 图谱生成
使用Protégé 生成的OWL 文件有效且规范地表示了长征红色文化资源知识图谱的实体、属性及其关系。Neo4j是一个高性能的NOSQL 图形数据库,它将结构化数据存储在图网络中,可以高效地存储和描述数据间地复杂链接关系。使用Python 将OWL 文件转为Json 格式进行结构化数据表示后,采用第三方库Py2neo 将读取的三元组知识导入Neo4j 数据库中,方便知识图谱的存储和使用。
3.4 系统开发
长征红色数字文化资源知识图谱构建完成后,就可以在此基础上实现基于知识图谱的服务模式。本文从数据层、技术层、服务层、应用层四个层面入手,分层设计构建服务,由下层为上层提供支持。为了充分发挥知识图谱的优势在红色文化资源数字化方面的优势,本文基于构建好的长征红色文化资源本体库和长征红色文化资源自身拥有丰富的时空信息这一特点,设计并实现了知识地图和导航、可交互时空地图两大功能应用模块。
4 长征红色文化资源知识图谱服务系统构建
4.1 长征红色文化资源数据获取
党中央部署的党史工作重点项目:“红军长征纪实丛书”几乎穷尽了当前所能收集到的长征亲历者的回忆史料。本文选取“长征纪实丛书”为主要数据来源,再辅以其它一些长征相关书籍,如:蒋建农等主编的《长征画典》、刘益涛,张树军主编的《今日长征路图集》等,对它们进行扫描和文本识别,获取电子版文档作为语料数据。
4.2 长征红色文化资源知识抽取
4.2.1 长征人物知识抽取
根据获得的《红军长征纪实丛书》语料数据,对全文进行OCR 文本识别,提取文本后,使用hanlp 自然语言处理工具对全文进行命名实体识别,获得长征有关的所有人名并存储。以保存的人名作为对象进行网络爬虫,提取其百度百科词条并进行解析,过滤掉词条中不包含“长征”这个关键词的所有词条,剩下保留的人物词条就视为是与长征有关的所有人物,保存这些人物的词条百科,获得长征人物语料库。
针对百度百科这样的网络百科知识抽取,由于其本身已经对知识做了结构化的处理,因此对这类资料只需采用基于模式匹配的方法,使用Python 的Beautiful Soup 模块解析下载好的知识百科词条,提取其中结构化知识即可。如图1 所示,<dt class=”basicInfo-item name”></dt>标签和<dt class=”basicInfo-item value”></dt>标签的内容即为当前百科词条的表格键值对结构,根据网络知识百科的词条构成规则,制定专门的解析策略,进而实现百科词条的结构化知识抽取。

图1:百度百科结构化知识
4.2.2 长征地理信息知识抽取
长征拥有丰富的地理信息。地理位置跨度较大,对地点的信息采集粒度就不需要过细。本文使用高德地图的行政区域查询API对这11 个长征途经省份的所有下辖地点信息进行遍历,保存(遍历到县级行政区为止)。主要保存的信息是地名和地点的经纬度,以及各个地点之间的下辖和隶属关系。
4.2.3 长征遗存、艺术作品知识抽取
《今日长征路图集》、《长征画典》中包含了大量的长征旧址文物、纪念建筑和艺术作品信息。从读秀上获取文献的扫描件后,使用Python 的OpenCV 库和和GUI 图形界面开发库Tkinter 构建标注工具,将信息摘取下来。标注工具的界面如下:
如图2 所示,为标注工具的操作界面。操作界面分为两大部分,左边是控制面板,右边是图片(来自《长征画典》)。控制面板从上到下依次为:当前标注实体的编号、给当前实体携带的额外信息、额外信息输入框、实体标注内容选项卡及其状态指示灯、总控制按钮。对一个实体的标注首先需要通过额外信息输入框修改携带的额外信息(非必要操作),随后点击“图片主体”选项,在右边的图片部分拖拽选择“送别_版画_邹达青”这幅画的主体部分并点击回车,此时“图片主体”的状态指示灯由红色变为绿色,表示当前实体的这部分内容已标注完毕,对“命名区域”的标注同理。在“图片主体”和“命名区域”两部分都显示为绿灯后,一个完整的实体就标注完毕,此时系统后台会生成 “实体标号_main.png”和“实体标号_name_额外信息.png”两个文件,分别表示当前标号实体的“图片主体”和“命名区域”内容,及其所携带的额外信息(没有额外信息则不会添加)。一个完整的实体标注完毕后,即可通过总控制按钮来进行下一个实体的标注或打开下一张图片标注实体。

图2:标注工具操作界面
标注完毕后,即可调用百度图片文本识别OCR接口,对每个实体的“实体标号_name_额外信息.png”文件进行识别,获得其命名,结合对应实体标号的“实体标号_main.png”文件生成文件名为实体名的实体文件,如图3 所示。

图3:标注工具生成命名实体文件一览
获得来自书本的知识后,再以这些实体名字中的部分关键词在网络上进行人工检索和筛选,即可得到更多拓展的长征红色文化资源知识内容,其主要来源网站包括但不限于表1。

表1:知识主要来源网站
4.3 长征红色文化资源图谱生成
为了保证构建的知识图谱足够规范化,本文在记录知识时使用Protégé 进行知识录入,生成OWL 文件后,再使用Python 解析OWL 文件中的知识,通过Py2neo 库连接并导入Neo4j 数据库方便取用。
按照上述方法将知识存入Neo4j 数据库后,可以通过其查询语言Cypher 方便快捷地获得数据库中的知识。如在Neo4j 控制台中输入 match(n) where n.name=’周恩来’return n 即可获得“周恩来”实体在数据库中的关系网络可视化。
4.4 长征红色文化资源知识图谱系统开发
考虑到系统的可维护性和后期系统的可拓展性,本文最终采用分层设计的方法设计系统,将系统从下层到上层分为:数据层、技术层、服务层和应用层。下层为上层的基础,上层可以调用下层,体系架构设计如图4 所示。
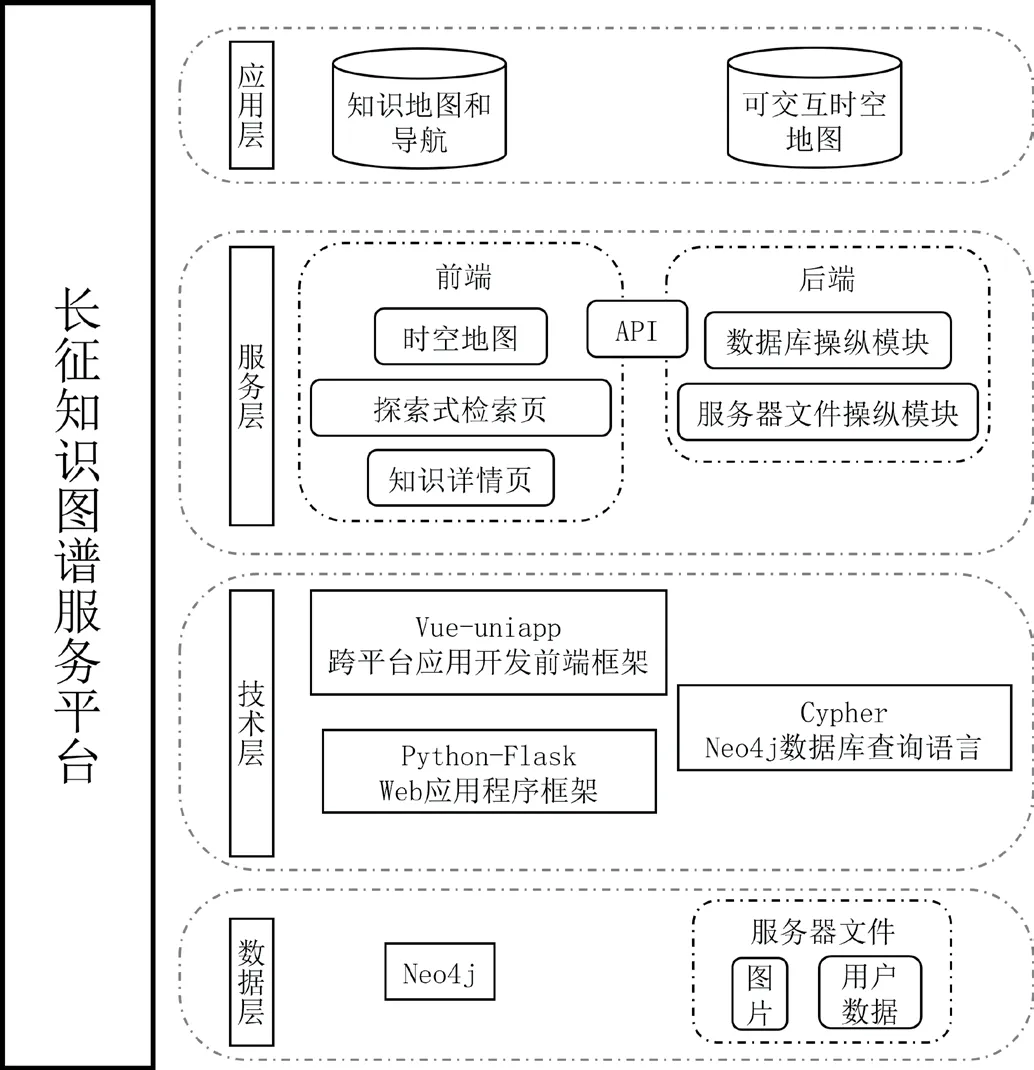
图4:服务平台体系架构设计
(1)数据层:该层由Neo4j 数据库和服务器中存储的图片和用户数据构成,主要为服务提供数据支撑。知识图谱存储在Neo4j 中,结合一些标记信息绑定服务器文件中的对应图片,向服务传输完整的知识图谱数据。
(2)技术层:Cypher 是Neo4j 图数据库管理系统提供的一种简单快捷的操作语言,它可以使我们快速地获得知识图谱中的信息,提供与数据层的对接,为服务器提供数据支持;Flask 是基于Python 语言的Web 应用程序框架,为前端页面提供远程服务;基于Vue 的uniapp 框架用于构建跨平台的前端应用。
(3)服务层:根据最终应用的需求,搭建不同的前端页面并开发相应的服务器接口。
(4)应用层:最终,服务器向知识地图和知识导航、可交互的时空地图两个应用提供服务。
时空演化模块最重要的两大功能块分别为可交互地图和时间轴。可交互地图通过基于JavaScript 的数据可视化图表库ECharts来实现,在“全国地图”页面,在页面被打开时,向服务器请求所有的长征重大事件数据,其中事件的发生地点经纬度来自高德地图API,定位到最小行政单位为县级。此外,处于相同地理位置的地图标记点,需要使用点聚合的方法,将其合并为一个可以点击展开的点。时间轴额外编辑好TimeLine.vue 组件后,在使用地图的页面调用该组件,监听用户拖动时间轴到了哪个刻度,传输当前刻度到地图页面,地图页面再显示当前时间点下的长征大事件信息。
最终实现的时空演化模块APP 界面如下:
如图5 所示,图左下方为可拖动的时间轴,通过拖动时间轴可以选取不同的时间点,正中间的地图上会显示出当前时间点下发生的长征大事件的发生地点,处于同一地点的大事件会被聚合,聚合的点会显示其聚合的事件数量。通过点击不同的事件或省份模块(可点击、含有长征信息的省份已被标深灰),APP 下方会出现事件或省份的信息弹框,通过弹框,可以进入事件或省份的详细信息界面。图5 右为贵州省的详细信息,贵州省内含有的长征红色文化资源及其所处的地理位置会在省份地图上显示,通过下方弹框的分类标签可以快速浏览贵州省内不同长征红色文化资源的信息。
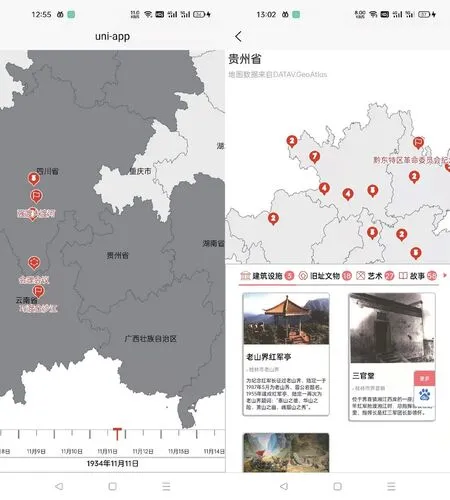
图5:时空演化模块APP 界面
本文将长征红色文化资源进行了细分后,在知识导航页面将其按照本体库的分类进行分类标签展示。此外,还需要构建模糊搜索模块。在检测到检索框的内容发生改变时,传输修改后的关键词到后端,得到修改后的关键词得到的检索结果。Flask后端与neo4j数据库的交互通过Py2neo模块实现。
最终实现的知识导航模块APP 界面如下:
如图6 左,可以通过切换不同的分类标签,显示知识库中不同分类的长征红色文化资源,通过在检索框输入检索关键词,如图6 右的弹框会实时显示当前关键词下的推荐长征红色文化资源内容。
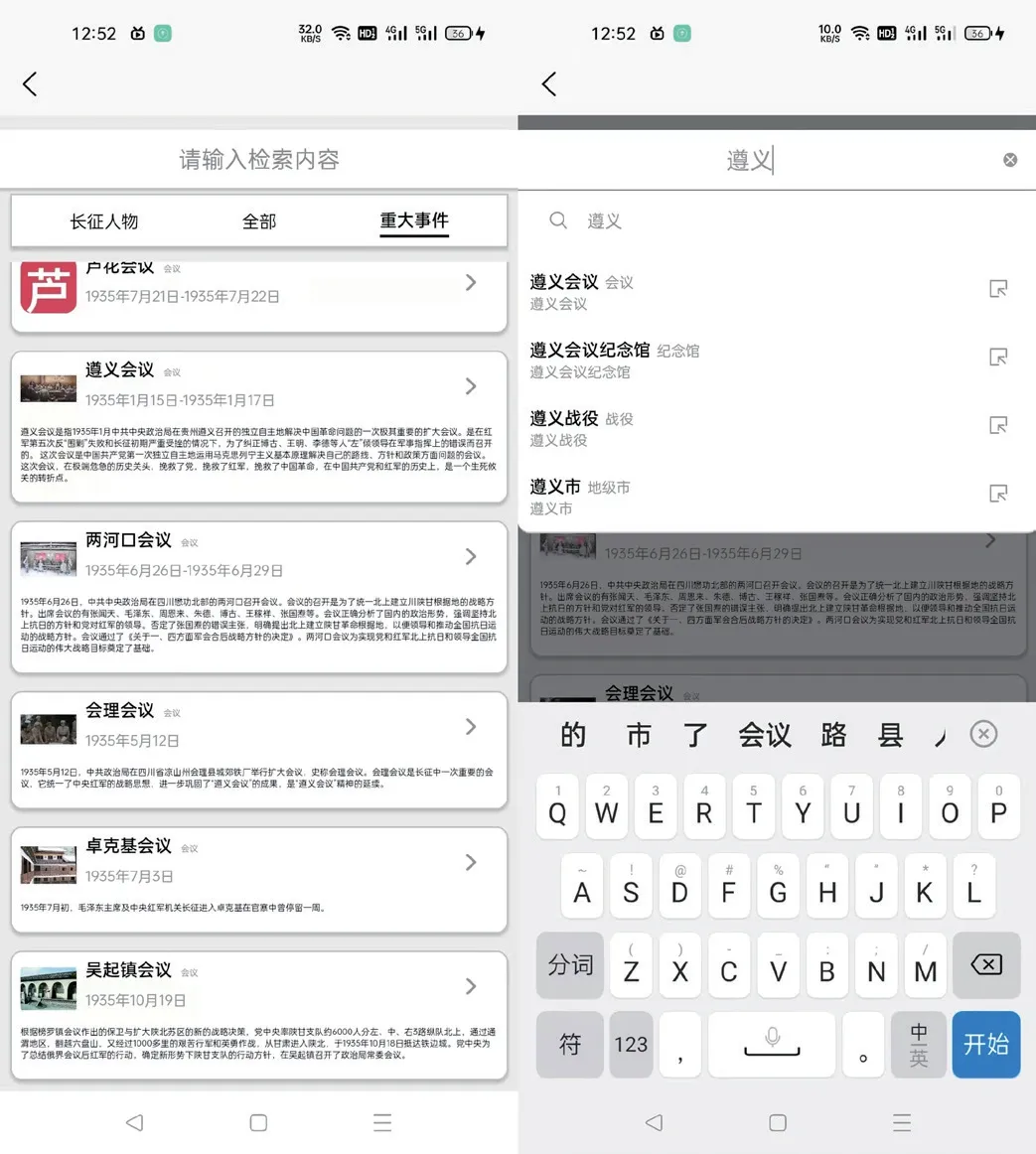
图6:知识导航和模糊检索APP 界面
5 结语
本文采用知识图谱技术对长征红色数字文化资源进行了描述、组织和关联,并在此基础上设计和构建了基于知识图谱的知识服务系统。为发挥知识图谱的技术优势,关注红色资源载体与人们之间的互动和情感塑造,从长征历史文化丰富的地理信息资源出发,对长征文化资源进行了生动具体、贴近生活的数字化组织,为红色文化资源的数字化保护和弘扬提供了应用示范。
