基于Flume、Kafka 的日志采集系统分析研究
2022-07-11李柯
李柯
(西北工业大学 陕西省西安市 710000)
1 引言
数据的演变非常壮观,在过去数据是字节级的,现在一些公司在同一时间使用大量PB 级数据。美国阿什维尔国家气候数据中心的专家估计如果我们想存储这个世界上所有的数据我们至少需要1200 个exabytes,但不可能确定相关号码。因此,如何从海量数据中提取获得有效的信息成为了大数据产业发展的首要解决问题之一。
数据采集,越来越成为大数据产业发展的根基。数据采集作为从数据被测模块和其他测量仿真模块中采集信息的过程,经历多年的发展,在数据采集的过程中增添了数据的分类和归并操作,为后续的数据处理操作提供了便捷,并简化了相关后续操作。从图1 中描述的Hadoop业务的开发流程中,可以看到数据采集在Hadoop 开发过程中作为十分重要的步骤,也是不可避免的步骤。
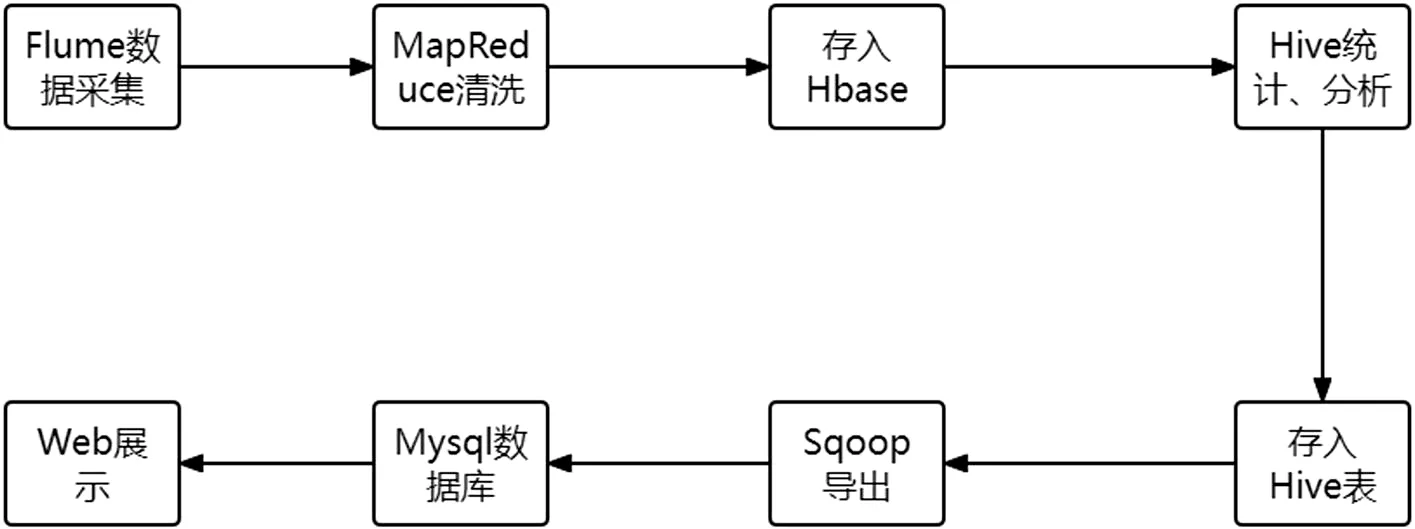
图1: Hadoop 业务的开发流程
在当今的互联网世界,日志文件的分析变得越来越重要。为了分析日志数据,我们利用网络挖掘的帮助从这些日志数据中获得所需的知识。而日志文件生成的速度极快,一天之内,一个数据中心就能生成数十TB 的日志数据。传统的数据采集数据来源于单一,且储存、管理方式较为复杂,解析的数据量也相对较小,而现代大数据采集来源广泛、数据量极大,数据类型繁杂,需要分布式的数据库存储。显然传统的数据采集方式无法适应现代大数据采集的需求,而现在很多互联网企业所采用的事件日志采集方式,在应用体系与数据分析体系间搭建了桥梁,从而将关联解耦。在支持实时分析系统的同时也支持离线分析系统,并能在数据量增加的场合,通过增加节点数量水平拓展。
2 Flume简介
Flume作为一款实时日志采集系统,获得了行业的肯定和应用。从初始发行的Flume OG(original generation)到现在经历核心组件、核心配置以及代码架构重构的Flume NG(next generation),flume 已经是一款十分成熟的日志采集系统。本文也将着重研究Flume NG 的应用改进。
作为一款分布式、安全、高效率的实时日志采集系统,flume 将海量数据进行集成,并可以自由更改数据发送方、对数据进行简单处理交付数据接收分析方。
Flume 不仅提供了采集功能,还提供了对数据进行简单处理并写入数据接收模块的功能。在数据流动的过程中,flume 以事件(event)作为数据载体或数据基本单位,事件携带日志数据并且在头部加入标识信息。一个flume 进程被称为agent,agent 作为flume 的核心由source、channel、sink 组件构成,这三个组件依次串行工作,而event 进入flume 的方式就是通过被source 组件捕获事件生成。Channel作为一个缓冲区,在sink 处理完一个事务之前保存事务数据,sink 将日志数据写入磁盘或者将事务传入下一个Source。Flume NG 的体系结构如图2 和图3 所示,这里特别强调的是channel 组件的重要性,由于sink 处理事件数据时有概率出错,导致数据丢失或出错,在sink 正确处理事件之前,需要channel 对事件进行保存,以免事件处理出错后的数据丢失。

图2: Flume 结构示意
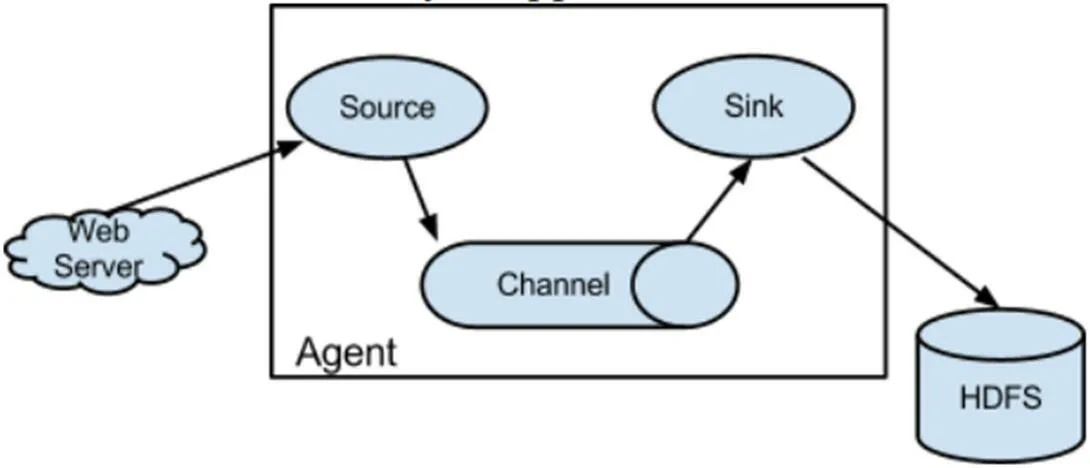
图3: Flume 模型
3 Flume+Kafka
5G 时代的到来以及发展,极大地推动了公共媒体的发展,加速了数据的流动,数据量的极速增长,各种设备记录、消费记录、浏览记录都成为了大数据的来源。由于每天有大量的数据流入流出,平台产生大量的日志文件,文件中的数据包含了用户喜好、舆论走向、社会习惯等信息。这些数据的数据源多种多样,而数据本身体量庞大、变化迅速,如何保质量、高效率、高可靠、避免重复的收集这些数据成为后续数据分析的前提之一。Flume 作为较近出现的实时日志采集系统,可以很好的利用自身的特点满足公共媒体等行业数据采集的需求。本文将基于flume + Kafka 实时日志采集系统对数据收集平台的搭建和优化进行研究,以满足公共媒体等行业数据采集、数据分析的需求。
图2 表示的体系结构图中,flume 的核心agent 前端连接服务器,后端连接Hadoop 分布式文件系统,这是通常的flume 结构表示图。然而使用时,通常将Flume 和Kafka 集成。那么为什么这样做?先从业务需求出发,flume + Kafka 架构通常都是为了进行实时流式的日志处理,处理完成之后在后端连接流式实时数据处理工具,以便于达成日志实时分析的目的。如果在实时计算框架中直接使用flume,如果数据采集速率大于数据处理速率,就极易出现数据堆积甚至数据丢失,而Kafka 是一个可持久化的分布式消息缓存队列,我们可以将其看成一个数据库系统,能够存储一段时间的历史数据,达到缓存数据的目的。
Kafka 作为一款开源分布式事件流媒体平台被成千上万家企业用于高性能数据管道、流媒体分析、大数据集成等领域。它能够使生产集群的范围扩展到极大的代理规模、每天高速的消息流、数PB 的数据规模以及数以万计的分区,并弹性地扩展和收缩、存储和管理。从而在可用性范围上更高效地扩展整个集群,或者跨越地域范围连接单独的集群。
Kafka 作为中间件,一个突出的优点就是将各层解耦,使得出错时由于其封装性不会影响其他部分工作,并不影响其他功能。数据从数据源中被捕获,到flume 中采集分类,再到Kafka 中处理分类时,数据一方面能够同步到HDFS 进行离线运算,另一方面也能够进行实时运算,实现数据的并发操作。同时Kafka 的开箱即用式连接接口还整合了数百个事件源和事件接收器,使得Kafka 可以连接几乎任何接口。图4 表示了flume 与Kafka 搭配之后的结构。

图4: Kafka topic 数据收集以及flume 的sink 将数据传入HDFS
3.1 Flume
Flume 系统的核心基础单元agent,共包含以下三个组件:source、channel、sink。但是组件中的channel 如使用MemoryChannel,虽然可以实现高速传输但其有限的容量在数据传输高峰时刻或agent 中止时会造成数据丢失;如使用FileChannel,有较大的容量在agent 中止后可以恢复数据,但却只有较慢的吞吐速度。所以系统所使用的channel 组件是自定义的,以同时解决数据丢失和吞吐速度的问题。
3.2 Kafka
Kafka 主要用于管理用户访问日志数据(PV、UV 等),这些数据一般以日志方式存储。将消息队列技术应用至数据处理,有助于提高实时日志系统的日志解析效率。而Kafka也包含三个组成部分:Producer、Topic、Consumer,如图5所示:
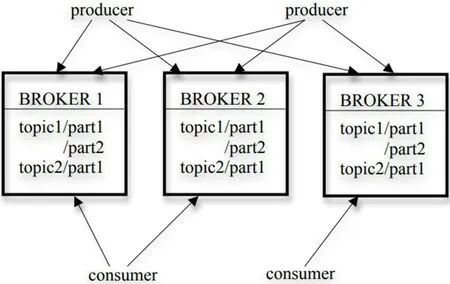
图5: Kafka 结构示意
Producer:消息和数据的生产者,向Kafka 的一个topic发送消息。
Topic:如同它的名字一样,topic 是一个将producer 发来的消息加以隔离分类的部分,不同的消息将会被推入不同的topic 中,当producer 向topic 发送消息时,就会向指定的topic 中传入消息。
Costumer:消息和数据的消费者,接收topic 的消息并处理其传入的消息。
在 本 文 的flume 与Kafka 的 应 用 中,producer 就 是flume。Flume 的最后一级sink 采集的数据流将数据发送给Kafka 的topic。使用检测文件夹变化的Spool Source、高吞吐的MemoryChannel、自定义sink。
4 系统研究
4.1 系统简单设定
在~/flume/conf 文件夹下新建spool.conf,在spool.conf中进行Spool Source 和自定义sink 的编写并将channel 设置为MemoryChannel:


4.2 自定义channel组件
虽然系统的整体已经基本完成,但是我们仍然在使用MemoryChannel,之前提到过MemoryChannel 可以实现高速传输但其有限的容量在数据传输高峰时刻或agent 中止时会造成数据丢失;FileChannel 有较大的容量在agent 中止后可以恢复数据,但却只有较慢的吞吐速度。两者并不能完全符合一个拥有高速数据流量的实时数据收集系统的需求,所以我们寻求将MemoryChannel 和FileChannel 各自的优势结合起来,为系统自定义一个channel。


4.3 另一种解决方式
在我浏览flume 的系统文件时,在flume-ng-channel 文件夹下,发现了一个flume-kafka-channel 的文件夹,这就是flume 系统提供的KafkaChannel,同时也成为该系统channel的另一个解决方案:利用flume 自带的KafkaChannel 对MemoryChannel 进行替换。而KafkaChannel 的优势在于source 读取日志文件后,传输给KafkaChannel 后,Kafka Channel 直接将数据传送给Kafka,不再需要sink,即使数据量很大时也可以正常工作,并且可以采用TailFile Source读取日志文件。
5 实验结果
利用模拟生成日志如图6 所示。

图6: 用户的访问日志
统计过去时间段的访客和来源,如图7、图8 所示。

图7: 对应IP 以及访客数量(次数)
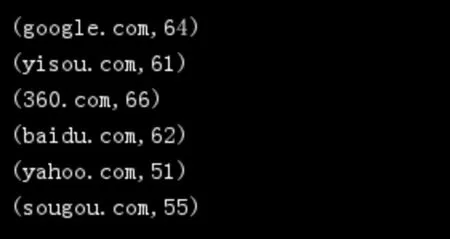
图8: 对应网站的访客数量(次数)
6 结论
Flume 所提供的多种source、channel 以及sink 组件,让我们针对数据采集处理的各种不同情况有了更多的组合方式,同时也拥有更高的采集处理效率。Kafka 将数据安全地存储在一个分布式、高可靠、高可用、高容错的集群中,通过连接、聚合、筛选、转换等方式处理数据流。而Kafka 也可以作为flume 的channel 组件,由flume 的sink 将数据传入HDFS、HBase、Hive 等数据库或文件系统,在实现负载均衡的同时也实现数据在前期采集、预处理的加工。
