基于FCN语义分割的视频人像分割方法
2022-07-09林镇源蒋小莲张文辉
林镇源,蒋小莲,张文辉
桂林电子科技大学,广西,桂林,541000
0 引言
语义分割是计算机视觉领域的重要热门之一,语义分割可以广泛应用于自动驾驶[1]、医疗图像诊断[2]、遥感图像分析[3]等领域。语义分割是主要是根据图像的内在性规则,如像素点之间的明暗关系、像素灰度级等将图像划分为多个子图像区块的过程,以使得每个块都有自己的类别,与其他区块形成显著对比。
语义分割中非常重要的一环就是人像分割,人像分割在行人检测、智能搜救、医学影像、智能驾驶等多个领域都有极其重要的作用,其分割方法分为传统的人像分割方法[4]和基于深度学习的人像分割方法[5]。传统的人像分割方法主要利用了视觉层的图像低级语义信息,如图像的颜色、形状、纹理等信息作为分割依据,但由于传统的典型方法中,基于阈值的分割方法是按照图像灰度值与阈值关系进行分割,对像素点进行分类,但如果人像与背景的灰度值差距不大,就会导致人像与背景无法区分;基于边缘的分割方法是对不同的微分算子进行边缘检测,如Canny算子、Prewitt算子等,但噪声对算子影响较大,所以基于边缘的分割方法能应用于低噪声且构图简单的图像。
由于传统的人像分割方法存在多种不足,因此研究人员提出了基于深度学习的人像语义分割技术。该人像分割技术主要利用了深度学习的相关理论,通过卷积神经网络从大量已标注的人像数据中提取出图像特征并且挖掘出每个像素的语义信息进行分类。Shen等人[6]设计了一种基于全卷积神经网络的人像分割算法,能够有效地分离人物与背景,并且可以较好地处理人物头发边缘,取得了良好的分割效果。
本文基于深度学习的人像分割方法,使用百度开源的PaddleSeg框架进行人像分割,选择开源数据集Supervisely,并选择FCN的网络进行模型训练,在经过多次迭代后,最终达到较好的人像分割效果。
1 数据预处理
在选择的Supervisely数据集中,包含了5711张人像,为了将数据集处理成PaddleSeg能直接运行的数据,需要将人像的mask的灰度值进行预处理,虽然整个mask在肉眼看来均为全黑色,但转为灰度图却有略微的差别,而为了能运用PaddleSeg框架,需要转为其能够直接识别的输入图像,灰度值为0为背景,灰度值为1是人像。因此,对于Supervisely的数据集,采用将灰度值小于等于10的转为0,灰度值大于10的转为255的策略,这样经过处理后,图像就变为黑白图,此时PaddleSeg并不能直接使用,而需要将灰度值为255的转为灰度值为1,才能得到最终可以直接使用的数据集(图1~4)。

图1 人像原图

图2 人像mask灰度图

图3 PaddleSeg使用的mask

图4 通过numpy显示出来的全黑图
2 图像语义分割
2.1 网络结构
FCN网络[6]是基于传统的卷积神经网络(CNN)的改进,将传统的CNN网络最后的全连接层转化为一个个的卷积层。
在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,对应1000个类别的概率,FCN将这3层表示为卷积层,卷积核的大小(通道数、宽、高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,故称为全卷积网络。
传统CNN分割的方法:为了能够对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:(1)存储开销很大,例如对每个像素使用的图像块的大小为15×15,则所需的存储空间为原来图像的225倍;(2)计算效率低下,相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算有很大程度上的重复;(3)像素块的大小限制了感知区域的大小,通常像素块的大小比整幅图像的小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。而FCN经过多次卷积后,得到的图像分辨率按照2的指数层次降低,再经过指数层次上采样,就能恢复到原图大小。这样就不需要消耗非常多的内存,且计算效率大大提高(图5)。
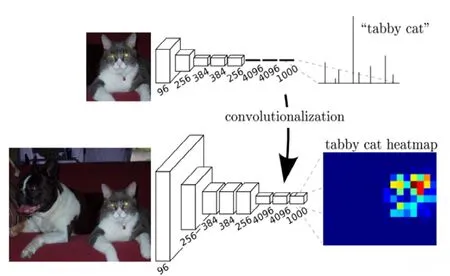
图5 CNN网络改进为FCN网络
2.2 训练数据及参数
训练参数表如表1所示,选择FCN网络作为模型的训练网络,将Supervisely开源的5711张人像图片按照9:1的方式划分为训练集和验证集,将初始的学习率设置为0.05,并采用逐次减半的方式设置学习率,即当loss值并没有在设置的1000次迭代中并没有下降时,将学习率降低一半,用于保证尽可能遍历所有的最优loss,而不会陷入局部最优。

表1 训练参数表
2.3 模型评价指标选择
在本模型中,选择的评价指标有损失函数(交叉熵Loss)、均交并比(Miou)、精确度(Acc)、模型一致性(Kappa)和图像分割系数(Dice)。
交叉熵Loss定义为:

其中,M表示分类的类别数,yc是一个onehot向量,元素只有0和1两种取值,如果波类别和祥本的类别相同就取1,否则取0。Pc表示为预测样本属于c的概率。
均交并比(MIoU)[7]定义为:在语义分割的问题上,一个集合为真实值,另一个集合为预测值,求解每个类的IoU,再取平均,即
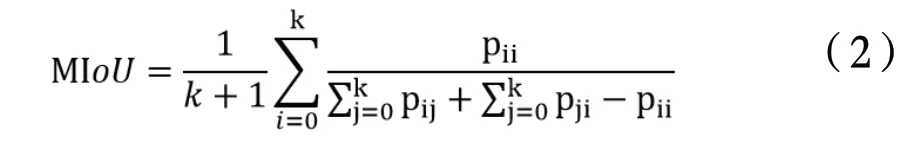
其中,k为类别数,i表示真实值,j表示预测值,pij表示i将预测为j,pji表示将j预测为i[8]。理想情况下,MIoU为1,即预测和真实值完全一致。
精确度(Acc)定义为:模型的正确分类像素占总样本数像素的比例。

其中pii为正确的分类像素,分母为所有分类的像素和。
模型一致性(Kappa)对于分类问题,一致性就是模型预测结果和实际分类结果是否一致。Kappa是基于混淆矩阵的应用。
基于混淆矩阵的kappa系数计算公式如下:

图像分割系数(Dice)是应用于像素级别的指标,取值范围为[0,1],当Dice越接近1时,模型效果越好。

其中,X为预测像素集合,Y为真实值像素集合。
2.4 训练过程详情
如表2和图6所示,在设置的20000次迭代中,模型的验证结果为在19200次迭代时产生最优的MIoU值,因此选择19200次迭代结果作为最优模型。

表2 训练过程各个验证指标值记录表
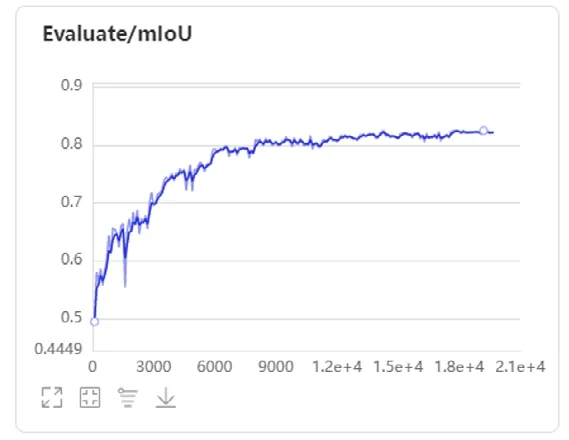
图6 MIoU值变化曲线
2.5 网络输出可视化
训练完成后将原始图像数据输入神经网络直接映射输出像素级图像分割结果,不同类别图像信息按像素值相互区分。网络分割输入、输出mask图像和最终结果如图7、图8和图9所示。

图7 输入图像

图8 输出mask

图9 最终结果
3 结论
本文为深度学习中的人像分割提供了改进方法,提高了分割的精度和效率。这种人像语义分割的方法,其具体步骤简单来说是先对数据集Supervisely进行训练,然后送入语义分割网络进行人像语义分割,最后将分割得到的mask图像贴合到原图像中,从而将人像与背景分割出来。
