基于BERT的阅读理解式标书文本信息抽取方法
2022-07-09涂飞明刘茂福张耀峰
涂飞明,刘茂福†,夏 旭,张耀峰
1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;
2.智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065;
3.湖北经济学院湖北数据与分析中心,湖北武汉430205
0 引言
在互联网大数据时代,各大采购平台网站每天都会发布大量招投标和中标公告,这些公告内容涉及方方面面,蕴含着很大的商业价值。对于企业而言,及时获取这些招投标数据,并从中抽取所需信息,具有十分重要的意义。而网站上发布的标书文本多为非结构化文本,这给信息的抽取以及统计工作带来难度。
信息抽取(information extraction)是从非结构化或半结构化的文本中对用户指定类型的实体、关系以及事件进行自动标识和分类,输出为结构化的信息[1]。由于其广泛应用,近年来,信息抽取成为自然语言处理(natural language processing)领域研究的热门课题。信息抽取主要包括命名实体识别(named entity recognition)、关系抽取(relation extraction)和事件抽取(event extraction)三个子任务[2],信息抽取的关键是命名实体的识别。早期常用的是基于规则的抽取方法[3],但该方法存在泛化能力差的问题。
深度学习的发展对自然语言处理领域产生了巨大的影响[4],在信息抽取中使用也相当普遍。在预训练模型发布之前,信息抽取主要模型以CNN和RNN[5]为主。Akbik等[6]通过动态存储每个词的所有上下文嵌入,并对这些嵌入进行池化操作以提取词的全局上下文嵌入,该方法显著提高了命名实体的识别效果。BERT(bidirectional encoder representations from transformers)模型的提出[7],使得多项自然语言处理任务取得了更好的效果,预训练模型被越来越多的学者使用。Xue等[8]提出针对联合实体和关系提取任务的集中注意力模型,该模型通过动态范围注意力机制将BERT模型集成到联合学习中,提高了共享参数层的特征表示能力。Qiu等[9]使用预训练模型,并以问答的方式,实现临床医疗文本的结构化。
近年,有学者将信息抽取任务转化为问答(question answering)任务来处理,取得较好效果。机器阅读理解(machine reading comprehension)是一类基于文本的问答任务,Levy等[10]将关系映射为问题,把关系抽取任务转为简单的阅读理解任务。McCann等[11]将10个不同的自然语言处理任务转化为问答任务,并将10个不同的任务数据集转化为问答数据集。Li等[12]利用阅读理解模型进行多轮对话,从而实现对文本实体-关系信息的抽取。Qiu等[13]提出QA 4IE框架,利用问答的灵活性,在句子间生成更加丰富的关系三元组。Li等[14]针对命名实体识别任务,提出了一个统一的阅读理解框架,能够同时识别出文本中的非嵌套实体和嵌套实体。
机器阅读理解任务定义为给定一篇文章以及基于文章的问题,让机器给出问题的答案。随着斯坦福大学发布SQuAD(Stanford Question Answering Dataset)阅读理解数据集[15],阅读理解任务获得了大量的关注。Wang等[16]提出了在SQuAD数据集上的第一个端到端的阅读理解模型,该模型先对问题和原文分别进行编码,然后利用Match-LSTM将问题和原文融合,最后使用Pointer-Network从原文中选取答案片段。Seo等[17]在注意力机制的基础上进行改进,提出了BiDAF(bi-directional attention flow)模型,该模型利用双向注意力流,得到一个问题感知的上下文表征,获得更深层次的上下文语义信息。由于之前的SQuAD数据集全为有答案的情况,斯坦福大学又发布了SQuAD 2.0数据集[18],SQuAD 2.0数据集存在原文中没有材料支持,无法作答的情况,其语料更加符合现实应用场景。受人类阅读习惯的启发,Zhang等[19]提出一种回顾式阅读器(retrospective reader),集成泛读和答案验证的模式,在SQuAD 2.0中取得佳绩。
本文提出一种基于BERT的阅读理解信息抽取方法,用于对标书文本中的预算金额、甲方名称、甲方联系方式、代理机构名称和代理机构联系方式5项信息进行抽取。抽取的信息多为单位名、人名以及数字(包括金额和电话号码)这样的实体,若将其视为命名实体识别任务,则有以下两个弊端:1)在标书文本中,公司名多为嵌套命名实体,而传统命名实体识别模型大多是针对非嵌套命名实体识别任务的[20],抽取效果欠佳;2)部分要抽取的信息并不完全是实体,而是包含了其他符号的字符串,如金额“¥35,000.00元”、电话号码“0755-82****88转3454”(为保护隐私,电话号码部分数字已掩盖,下同)以及公司名“内蒙古电力(集团)有限责任公司”等。
本文将标书文本的信息抽取任务看作阅读理解任务,而非命名实体识别任务。对于给定的标书文档,对其提问,如“采购单位”,然后让模型预测出答案,得到的结果即要抽取的甲方名称,其他四项需要抽取的项目以类似的方式进行抽取。基于阅读理解的方法可以同时适用文本中非嵌套实体和嵌套实体的抽取,相比于传统的序列标注方法,基于阅读理解的方法更简单直观,可迁移性也强。另外,基于阅读理解的方法能够让问题编码一些先验语义知识,能够更容易区分具有相似标签的分类,如甲方名称和代理机构名称。
1 数据集构建
从中国政府采购网(http://www.ccgp.gov.cn/)获取标书网页文本1 450份,然后清洗数据,去除JavaScript、CSS代码以及注释文本等代码文本,去除HTML标签,替换部分符号,得到纯净、规范的中国政府采购网发布的标书正文。根据我们对中国政府采购网标书正文的了解,构建出规则库,使用规则对其进行抽取,再进行人工检验,更正规则抽取错误的例子,给出预算金额、甲方名称、甲方联系方式、代理机构名称以及代理机构联系方式5个字段的内容。
将以上5个字段内容转换成SQuAD数据格式,对标书文本提出5个问题,并给出答案文本以及答案开始位置,得到问题-答案对共7 250份。SQuAD格式的数据如例1。
例1

2 信息抽取方法
2.1 整体架构
对标书文本抽取上述5项信息,整体架构如图1所示。首先输入原始标书网页文本,对其进行预处理操作,得到标书纯文本,基于文本内容,匹配问题关键词列表,生成问题,把问题与文本拼接,然后使用BERT阅读理解模型进行预测,得到问题的答案。
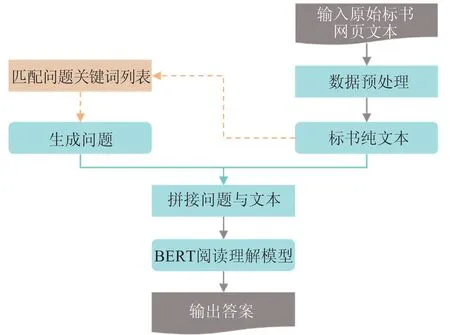
图1 阅读理解式信息抽取方法整体架构Fig.1 Overall structure of information extraction method via reading comprehension
2.2 问题生成
对于每个要抽取的字段,都会为其设置一个问题,然后让阅读理解模型根据问题给出预测答案。为生成阅读理解数据集,我们构建了规则库用于信息的初步抽取,统计到标书文本中常见的信息关键词,生成问题关键词列表,表1为部分问题关键词列表。我们为每个字段设置一个默认问题,然后在文本中查找这些问题关键词,匹配成功则生成对应问题;否则,使用默认的问题。本文生成的问题均为伪问题。比如,例2中标书文本包含“招标单位”关键词,抽取甲方名称时,就生成问题:“招标单位”。
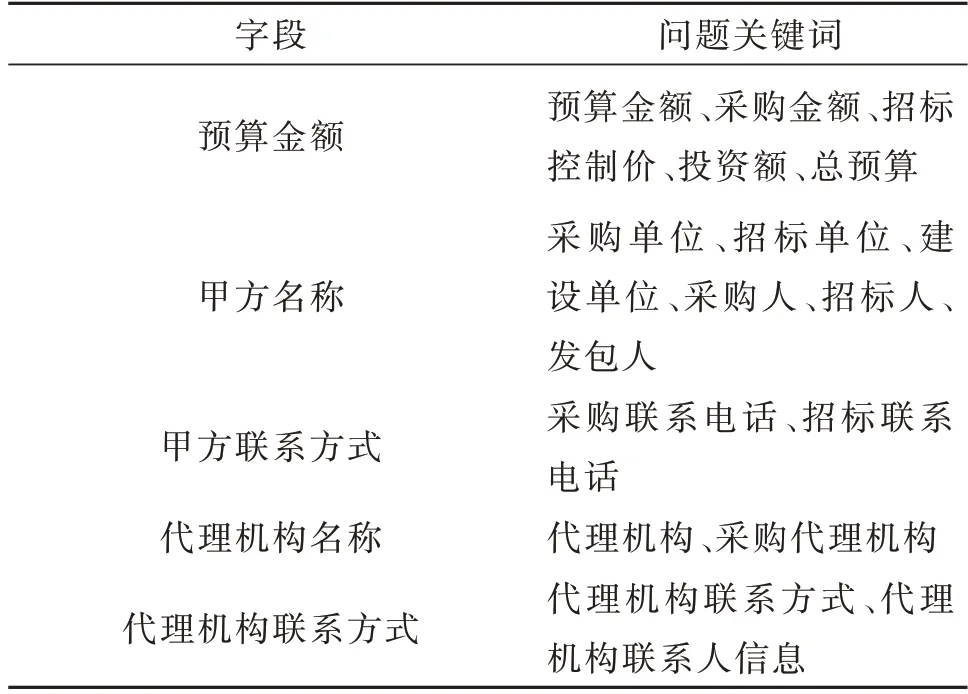
表1 部分问题关键词列表Table 1 The partial of question keywords list
例2
段落:…项目概况如下:1.项目名称:沈阳市红十字会医院棋盘山分院污水处理站运维服务项目2.项目编号:LNWX21046-C 3.招标单位:沈阳市红十字会医院…
问题:招标单位
答案:沈阳市红十字会医院
对于阅读理解模型而言,问题包含了重要的先验语义信息,能够帮助模型确定答案的位置。所以,合适的问题对于答案的正确预测有着重要作用。
2.3 基于BERT的阅读理解模型
在得到问题和文本后,使用BERT模型进行预测。阅读理解的任务是,给定问题(question)和包含答案的段落(paragraph),模型需要预测答案文本的起始位置和结束位置,从而给出答案文本,这实际上是一种抽取式问答。本文使用预训练好的BERT中文语言模型[21],针对阅读理解任务进行微调。
如图2所示,在阅读理解任务中,BERT将问题和段落组成一个序列,序列的第一个字符为一个特殊字符[CLS],并用一个特殊字符[SEP]将问题和段落区分开。E为输入序列,特殊字符[CLS]的最终隐藏向量表示为C∈RH,第i个输入词的最终隐藏向量表示为Ti∈RH,其中H为隐藏层的维度。

图2 BERT阅读理解模型框架图Fig.2 BERT-based reading comprehension model framework
微调过程中,引入向量Vstart∈RH和Vend∈RH,Vstart表示答案起始位置判断向量,Vend表示答案结束位置判断向量。表示第i个词是答案片段开始的概率,通过Ti和Vstart点积,再接上段落中所有词的softmax计算得到
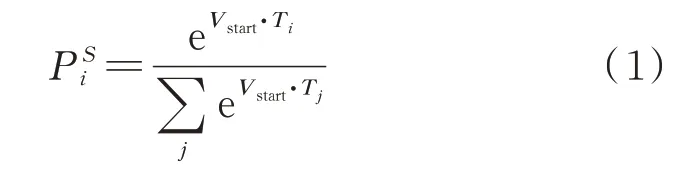

从位置i到位置j的候选答案片段分数表示为Vstart·Ti+Vend·Tj,选取分数最高的片段作为预测结果,同时保证i≤j。
3 实验部分
3.1 评价指标
本文使用两个评价指标:EM(exact match)和F1值,计算评价指标时忽略标点符号。
EM:对于每个问题-答案对,若模型预测结果与标准答案完全匹配,单个样例EM为1,否则为0,最后取全部测试集数据的均值。EM用于计算预测结果与正确答案是否完全匹配,反映了精准匹配度。
F1:首先得到预测结果与标准答案的最长公共子串(longest common substring,LCS),根据LCS的长度和标准答案的长度计算召回率(R),根据LCS的长度和预测结果的长度计算精确率(P),再由R和P计算F1,如公式(3),然后同样取全部数据均值。F1用于计算预测结果与标准答案之间字符级别的匹配程度,反映了模糊匹配度。
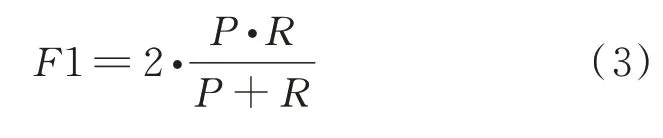
3.2 实验结果
本文进行了基于BERT的命名实体识别抽取任务的实验,将数据集格式转换为适用于命名实体识别任务的格式,设置预算金额、甲方名称、甲方联系方式、代理机构名称以及代理机构联系方式5类命名实体,实验目标为从文本中抽取这5类命名实体,并同样使用EM和F1评价指标,用于对比阅读理解的抽取方法。为了比较不同阅读理解模型的抽取效果,本文进行了一系列阅读理解模型对比实验,选用Match-LSTM、BiDAF和Retro-Reader模型进行对比实验,实验结果如表2,其中“BERT”为本文模型。
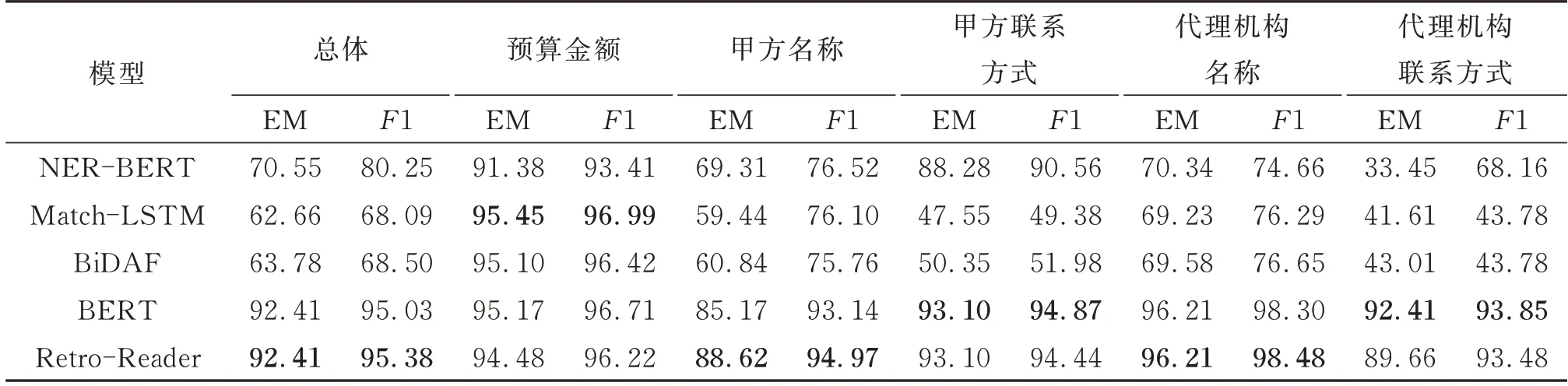
表2 实验结果Table 2 Exper imental results %
因为金额的特征比较明显,多为数字加“元”或“万元”,适合Match-LSTM模型识别抽取,所以在“预算金额”上Match-LSTM表现较好。在其他字段BERT和Retro-Reader模型的抽取效果都比其他模型好。在“甲方联系方式”和“代理机构联系方式”两个字段上BERT抽取效果要优于Retro-Reader。Retro-Reader模型预测集成了粗读和精读两个阶段,粗读阶段判断问题是否可以回答;精读阶段寻找答案片段,验证问题是否可以回答,给出最终的判断。Retro-Reader适合处理包含无法回答问题的阅读理解任务,而本文的语料均包含抽取的信息,因此更适合BERT。另外,BERT的解码阶段直接采用线性网络层连接,设计上相比Retro-Reader更简单,训练时资源耗费更少。
3.3 实例分析
例3
context:…采购代理机构信息(如有)名 称:辽源市宏基建设工程招标有限公司地址:辽源市隆基华典55号楼门市 联系方式:0437-31****3…
question:代理机构联系方式
answer:0437-31****3
NER-BERT:0437
Match-LSTM:-
BiDAF:-
BERT:0437-31****3
Retro-Reader:0437-31****3
如例3,对于代理机构联系方式的抽取,命名实体识别任务的抽取结果为“0437”,丢失了部分内容。阅读理解任务的Match-LSTM和BiDAF预测答案为“-”,而BERT以及Retro-Reader预测答案为“0437-31****3”,与标准答案一致。标准答案的位置相对文中“采购代理机构信息”位置较远,预训练模型更能学习到上下文语义信息,在阅读理解任务上更具有优势。
例4
context:…项目名称:成安县经济开发区污水处理厂设施恶臭气体设备采购项目…采购人信息名称:成安县环洁公司…
question:采购人
answer:成安县环洁公司
NER-BERT:成安县环洁公司
Match-LSTM:成安县经济开发区
BiDAF:成安县经济开发区
BERT:成安县环洁公司
Retro-Reader:成安县环洁公司
如例4,对于甲方名称的抽取,标准答案是“成安县环洁公司”,命名实体识别任务的抽取结果为“成安县环洁公司”,Match-LSTM和BiDAF错误地从标书文本的项目名称中选取“成安县经济开发区”片段作为答案,BERT和Retro-Reader则是从文本中选取位置与“采购人信息名称:”相近的“成安县环洁公司”作为答案,使用预训练模型,更能准确定位到答案位置。
4 结语
本文提出了一种基于BERT的标书文本阅读理解式信息抽取方法,该方法将信息抽取任务转换成阅读理解任务,对于给定标书文本,生成问题对模型提问,然后模型从文本中抽取片段给出预测结果。使用BERT预训练模型能够增强语言表征能力,提升阅读理解抽取效果。实验结果显示:对于标书文本信息抽取,阅读理解抽取方法相比传统的命名实体识别抽取方法具有更好的效果。在今后的工作中,将完善数据集的构建,尝试用更多的方法实现文本信息抽取任务。
