苹果任意姿态下高光谱图像感兴趣区域选取方法
2022-07-09袁旭林郑纪业赵贤段玉林王风云
袁旭林,郑纪业,赵贤,段玉林,王风云
(1.山东省农业科学院农业信息与经济研究所,山东 济南 250100;2.百度在线网络技术(北京)有限公司,北京 100085;3.山东省科学技术情报研究院,山东 济南 250101;4.中国农业科学院农业资源与农业区划研究所,北京 100081)
在基于高光谱成像技术的苹果糖度无损检测过程中,采集到的高光谱图像数据量巨大,且数据之间具有很强的相关性,不仅计算复杂度高,而且影响后续模型建立的速度和精度,因此需要对数据进行压缩。主流的做法是选取感兴趣区域,求取感兴趣区域的平均光谱作为该苹果的特征光谱,可将数据量从GB数量级降到KB数量级,缩小近百万倍,使计算复杂度大大降低,从而提升后续模型的建立速度。可见,感兴趣区域选取是无损检测模型建立的第一步,为后续模型建立提供了原始特征光谱数据,其选取优劣直接影响着后续建立模型的稳定性,是高光谱数据分析中至关重要的一步。
已有很多学者采用高光谱成像技术对水果的内部品质进行检测,一般在进行高光谱图像数据采集时,成像光谱仪垂直放置在水果正上方,水果姿态为沿果核方向水平放置,水果运动方向垂直于成像光谱仪狭缝,但感兴趣区域的选取方式各有不同。徐焕良等[1]基于光子传输模拟与卷积神经网络检测苹果品质时,选取的感兴趣区域为40像素×40像素的区域。Gamal等[2]进行苹果硬度研究时,选取的感兴趣区域为整个苹果区域。郭志明等[3]利用光强度校正方法进行苹果糖度的高光谱可视化预测时,以苹果果梗-花萼连接线与赤道面上方的交叉点为中心提取直径为150个像素点的圆形区域作为感兴趣区域。查启明[4]在进行苹果可溶性固形物和硬度分析时,绕果核方向旋转采集图像,每旋转120°采集一次高光谱数据,一个苹果采集3次,对应3幅高光谱图像,取每幅图像苹果中心赤道部位半径150像素的圆形区域作为感兴趣区域,以3幅图像的感兴趣区域的平均光谱作为该苹果的特征光谱进行建模。冯迪[5]在进行苹果可溶性固形物研究时,采集完一面的高光谱数据后,将苹果以果核为轴翻转180°再采集另一面的数据,每个苹果对应2幅高光谱图像;特征区域选取时,在每幅高光谱图像距离中心点300像素的上下左右四个方位上选取4个边长为50像素的正方形区域,双面共得8个正方形区域,取其平均光谱作为特征光谱进行建模。徐璐[6]在进行砀山梨可溶性固形物分析时,每个样本正反面各采集一幅高光谱图像,然后对每幅图像进行去均值归一化校正,取梨的完整区域作为感兴趣区域,取正反两面感兴趣区域的平均光谱作为该梨的特征光谱。可见,目前研究中高光谱数据的采集都是基于人为辅助下的固定姿态,感兴趣区域的选取也是通过采集软件人工进行选取的,具有很大的主观性,并且有的研究还对同一苹果进行多次数据采集,这距在流水线上实际应用还有很大差距。
本研究提出了一种基于随机姿态下的苹果高光谱图像感兴趣区域选取方法,可实现感兴趣区域的自动选取,并基于提出的感兴趣区域选取办法,建立了基于高光谱成像技术的苹果糖度无损检测模型,并进行了实测验证分析,对提出的感兴趣区域选择方法的正确性和有效性进行了评价,以期为流水线上自动化检测苹果糖度提供参考。
1 材料与方法
1.1 试验材料
为了使试验结果具有普适性,在市场上随机购买大小不一、形状各异、着色特征不同(片红和条红)的烟台富士苹果作为研究对象,共135个。试验前将苹果提前放置到实验室环境中12 h,待与室温基本一致后,清洗每个苹果,去除表面污物,用纸巾擦去多余水分,并编号备用。
1.2 设备和仪器
1.2.1 高光谱成像系统 本研究所搭建的高光谱成像系统结构示意图见图1,主要包括成像光谱仪(Pika XC2,Resonon,Bozeman,the United States)、镜头(焦距23 mm)、上位机采集软件、移动平台和一对100 W 的卤素灯杯(JCR 12V 100W BAU,Ushio,Tokyo,Japan),通过开关电源控制光源供应与否。

图1 高光谱成像系统结构示意图
成像光谱仪用于苹果高光谱图像数据的实时采集,采用线扫描方式,光谱范围为400~1 000 nm,光谱分辨率为1.3 nm,光谱通道数为462,空间通道数为1 600,最大帧数为165 fps,位深度为12位。为了避免周围杂散光影响,成像光谱仪、镜头、光源和移动装置需置于暗箱之内。
1.2.2 糖度计 苹果糖度采用杭州陆恒生物科技有限公司生产的LH-B55型数显糖度计测定,该设备测量范围为0.0~55.0°Brix,测量精度为±0.2°Brix,分辨率为0.1°Brix。
1.3 数据采集
1.3.1 高光谱图像数据采集 利用图1所示高光谱成像系统采集高光谱图像数据。成像光谱仪曝光时间设定为5.5 ms,帧率设定为150 Hz,增益设置为0;开启光源预热20 min后采集成像光谱仪的暗场高光谱数据和全反射高光谱数据并保存,用于后期光谱数据的黑白校正;然后将苹果随意放在流水线上的果杯内,以随机姿态穿过成像光谱仪下方,用自行编写的软件自动采集其高光谱数据。共采集到135幅高光谱图像。
1.3.2 糖度数据采集 用刀在采集完高光谱图像的苹果赤道部位,每隔90°切下中心厚度约10 mm的切片,去除果皮,在切片中心取边长约20 mm的正方形果肉(图2),将4块果肉放入手动榨汁器,挤压出5 mL左右的汁液,搅拌均匀,作为原始测量样本,然后用LH-B55数显糖度计测定糖度。每份样本重复测量3次,取其平均值作为该样本最终的糖度测量值。

图2 苹果果肉选取区域
1.4 感兴趣区域的选取
受苹果表面曲率的影响,采集到的苹果高光谱图像不同区域的光谱强度不同,中心区域光谱强度较高,四周的光谱强度低(图3);不同区域对应的光谱数据如图4所示,可见,不同区域的光谱曲线具有不同的特性。感兴趣区域就是从所采集的苹果高光谱图像中选取一定大小的目标区域,使其代表整个苹果的光谱信息。

图3 苹果高光谱图像不同区域展示

图4 高光谱图像不同区域的光谱曲线
1.4.1 感兴趣区域选取的原则 ①为了保证运算速度,感兴趣区域不宜过大;②尽量选择光谱强度大的区域,光谱强度越大其信噪比越高;③果梗和果萼区域因结构比较复杂,光谱曲线与正常果肉区域不同,为了提高建立模型的稳定性,需要剔除该区域;④由于高光谱图像数据量较大,所采用感兴趣区域选取方法的时间复杂度应尽可能小。
1.4.2 感兴趣区域选取流程 根据上述原则,提出如下流程进行苹果感兴趣区域的选取:
(1)观察图4中6个不同区域的光谱曲线,可以发现其光谱强度值都在700 nm附近达到最大值,因此,选用各像素点700 nm的光谱强度值进行后续阈值分割。
(2)将高光谱图像各像素点按700 nm处的光谱强度值进行直方图统计,获得各像素点光谱强度值大小关系,按照百分比依次剔除光谱强度值低的像素点,之后进行一次形态学腐蚀操作,以去除果梗或果萼区域和背景中高反射率区域,观察去除效果。
(3)观察图4中⑤号区域的光谱数据,可以发现其光谱强度值过大,达到了最大值4 095,光谱数据严重失真,因此需将其剔除。产生这一现象的原因有两方面,一是苹果过大,引起光程变短,光照强度变大,从而引起曝光过度;二是苹果本身光泽度较高,反射率大,也造成曝光过度。剔除的方法为采用700 nm附近波长的光谱强度值进行曝光过度判断,当光谱强度值大于3 900时则判定该像素点曝光过度。
(4)经过上述步骤即可得到原始感兴趣区域。为进一步缩小感兴趣区域,对原始感兴趣区域内的像素点按700 nm波长的光谱强度值进行直方图统计,分别取光谱强度值前10%、20%、30%、40%、50%、60%、70%、80%、90%、100%的像素点集合作为感兴趣区域,建立不同大小感兴趣区域的偏最小二乘回归(partial least squares regression,PLSR)预测模型。其中,PLSR预测模型建立方法为:首先对感兴趣区域内的像素点进行高光谱数据的黑白校正,计算感兴趣区域的平均光谱作为苹果的特征光谱;然后采用基于联合X-Y距离的样本划分法(SPXY)[7]将数据集按3∶1分为校正集和测试集,用校正集建立特征光谱与苹果糖度的PLSR模型,用测试集特征光谱对模型进行实测验证。以测试集的测试集均方根误差(root mean square error of prediction,RMSEP)作为最终感兴趣区域大小选择的依据。
1.5 模型的建立
本试验中使用的成像光谱仪每帧数据1 600个采样点,每个采样点有462个波段的数据,一个苹果平均对应750帧数据,即一幅高光谱图像的数据规模为1 600×462×750,考虑到光谱仪位深为12位,一个数据要占2个字节,故一幅高光谱图像的数据约1 GB,数据总量巨大,直接使用这些原始数据建模,不仅计算复杂度高,而且影响模型建立的速度和精度。为了减少计算量、降低数据计算复杂度,取感兴趣区域的平均光谱作为特征光谱进行预测模型的建立。
1.5.1 感兴趣区域的黑白校正 确立苹果高光谱图像的感兴趣区域后,为了提高信噪比,需要消除图像采集过程中暗电流、背景光强度及光源分布不均匀等产生的噪声的影响[8]。采用黑白校正对此类噪声进行消除:首先对反射率为99%的标准白色正板进行图像采集,得到全白的标准图像W,然后关闭光源,拧上镜头盖,采集全黑标定图像D[9]。黑白校正公式为:

其中,Rλ,n表示校正后的高光谱数据,Sλ,n表示苹果样本原始高光谱数据,Dλ,n表示暗场高光谱图像数据,Wλ,n表示全反射高光谱图像数据,λ、n表示在λ波长下的第n个像素。
1.5.2 光谱数据预处理 采集的高光谱图像数据中,往往还存在着仪器本身电噪声、传动装置运动过程中的震动、周围环境的杂散光、苹果形态差异等产生的噪声信号,为了提高后续建立的回归模型的稳定性,就需要对采集到的高光谱数据进行预处理以减弱此类噪声信号的影响。本研究选用几种常见的光谱预处理方法进行对比分析,包括标准化处理、中心化处理、Savitzky-Golay(SG)多项式卷积[10]、一阶导数(first-order derivative,D1)、多元散射校正(multiplicative scatter correction,MSC)[11]和标准正态变换(standard normal variate,SNV)[12]。
1.5.3 特征波段提取 由于高光谱数据分辨率较高,具有几十甚至数百个波段,维度高且波段间的相关性较高,数据冗余,直接用全波段进行模型建立,不仅计算量大,有些无用波段的数据还会影响最终模型的预测精度,因此需要对特征波段数据进行提取,以提高模型的运算时间和预测精度[13,14]。本研究采用连续投影算法(successive projections algorithm,SPA)[15-17]、主成分分析(principal component analysis,PCA)[18,19]、反向区间偏最小二乘法(backward interval partial least squares,BiPLS)[20,21]、蚁群算法(ant colony optimization,ACO)[22]和竞争性自适应重加权算法(competitive adaptive reweighted sampling,CARS)[23,24]五种方法进行特征波段数据的提取,并对其提取效果进行比较分析。
1.5.4 模型建立 采用目前光谱分析中应用主流的偏最小二乘回归(PLSR)[25,26]方法建立苹果高光谱数据与糖度之间的回归模型。
2 结果与分析
2.1 原始感兴趣区域的选取
试验发现,当剔除60%光谱强度值低的像素点后,即选取光谱强度值高的前40%像素点区域,可以很好地将果梗或果萼区域及背景亮斑区域去除,同时还可将光谱强度值低的苹果区域和普通背景区域去除;用700 nm波长的光谱强度值大于3 900的阈值判断,可以很好地去除曝光过度区域。本试验方法只采用了两次阈值分割和一次腐蚀操作即实现了感兴趣区域的选取,简单快速。选取的苹果原始感兴趣区域的掩膜如图5所示。
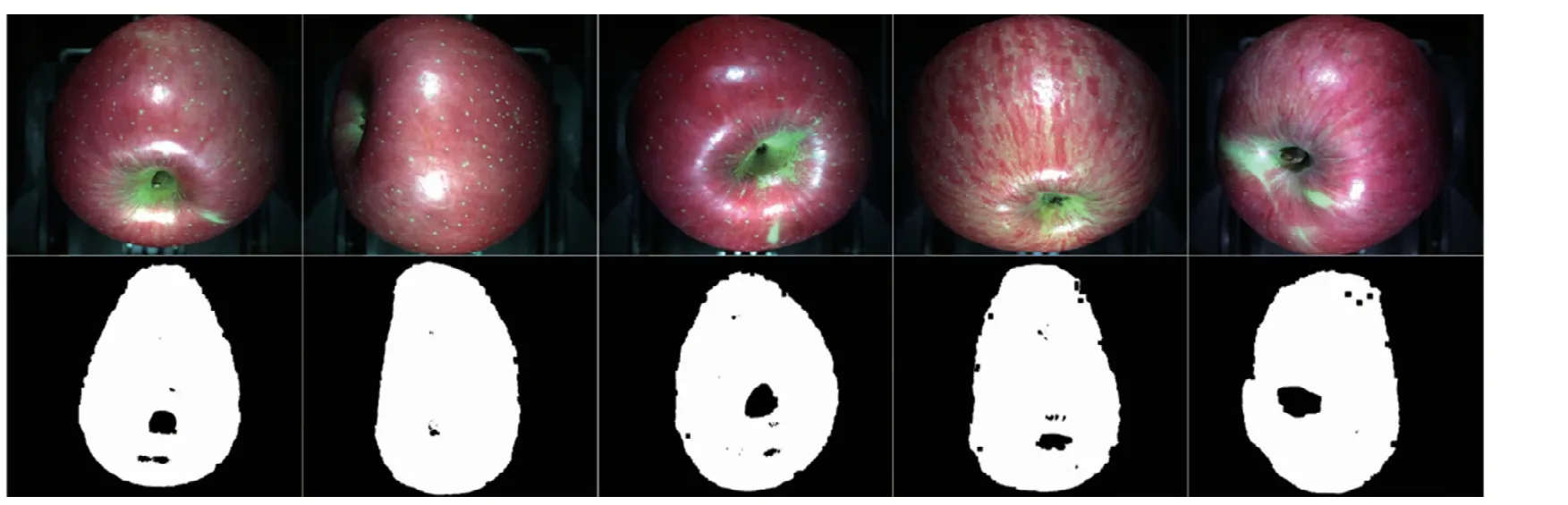
图5 选取的苹果原始感兴趣区域的掩膜
2.2 不同大小感兴趣区域对模型精度的影响
图6是苹果原始感兴趣区域光谱强度值前10%、20%、30%、40%、50%、60%、70%、80%、90%、100%的像素点集合掩膜。
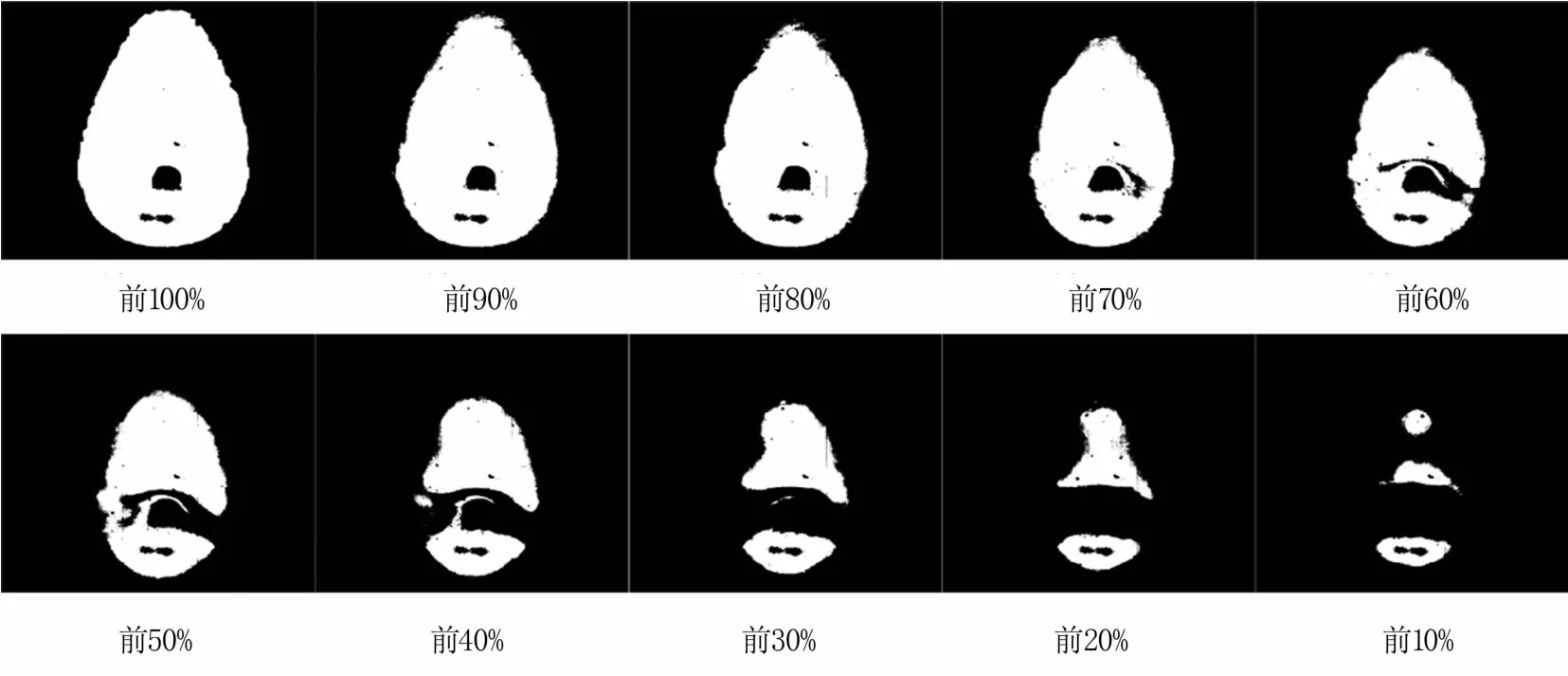
图6 不同大小感兴趣区域掩膜
建立不同大小感兴趣区域的PLSR预测模型,模型测试集的RMSEP变化趋势如图7所示,可以看出,随感兴趣区域的扩大,RMSEP减小,这是由于感兴趣区域越大越能代表整个苹果的光谱信息;当取原始感兴趣区域光谱强度前70%的区域时,RMSEP最小;选取区域再扩大,RMSEP变化不明显,这是由于继续扩大感兴趣区域虽然更能表征整个苹果的信息,但却引入了噪声数据,从而导致RMSEP变化不明显。因此,取原始感兴趣区域中前70%光谱强度值的区域作为最终的苹果感兴趣区域,以其平均光谱作为后续模型建立的原始数据。
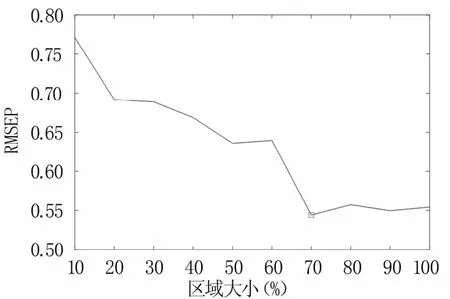
图7 PLSR模型预测集均方根误差随感兴趣区域选取大小的变化趋势
2.3 异常样本的剔除和样本集划分
2.3.1 异常样本剔除 由于人为操作失误、周围环境变化、仪器本身原因,可能会使采集到的高光谱数据或苹果糖度数据异常,进而对最终建立模型的精度产生极大影响,因此需对这部分异常数据进行剔除。本研究采用的剔除方法为蒙特卡洛交叉验证法[26](Monte Carlo cross validation,MCCV),算法步骤为:随机从总样本集中选取80%的数据作为校正集,剩下20%作为测试集;在校正集建立PLSR模型,然后将测试集数据代入,得到预测值,共进行2 000次循环,得到每个样本的一组预测值;计算各样本预测值的均值(Mean)和标准差(STD),做Mean-STD图(图8);以Mean的阈值为1.5、STD的阈值为0.5剔除均值大于1.5及标准差大于0.5的样本,共剔除异常样本11个,其编号分别为5、11、22、26、45、54、55、59、61、111、112,用剩余的124个样本数据进行后续分析。

图8 均值-方差图
2.3.2 样本集划分 用SPXY方法将剔除异常样本后余下的124个样本划分为校正集和测试集,划分比例为3∶1,其糖度数据分布情况如表1所示。可见,糖度最大值和最小值均包含在校正集内,测试集标准差小于校正集,数据划分合理。

表1 校正集和测试集糖度数据分布 (°Brix)
2.4 高光谱数据预处理方法的选择
由于光谱曲线两端的波长光谱强度较低,信噪比较低,在实际运用时去除两端数据,只保留中间436~940 nm的数据,共380个波段。之后分别采用标准化、去中心化、S-G多项式卷积(2阶33点,为多次试验的最优值)、一阶导数、多元散射校正(MSC)和标准正态变换(SNV)方法对原始数据进行预处理,建立预处理数据与苹果糖度的PLSR模型,结果(表2)显示,经SNV方法预处理后建立的PLSR模型RMSEP最低,预测精度最高,可有效去除噪声信号,因此选用SNV方法对光谱数据进行预处理。
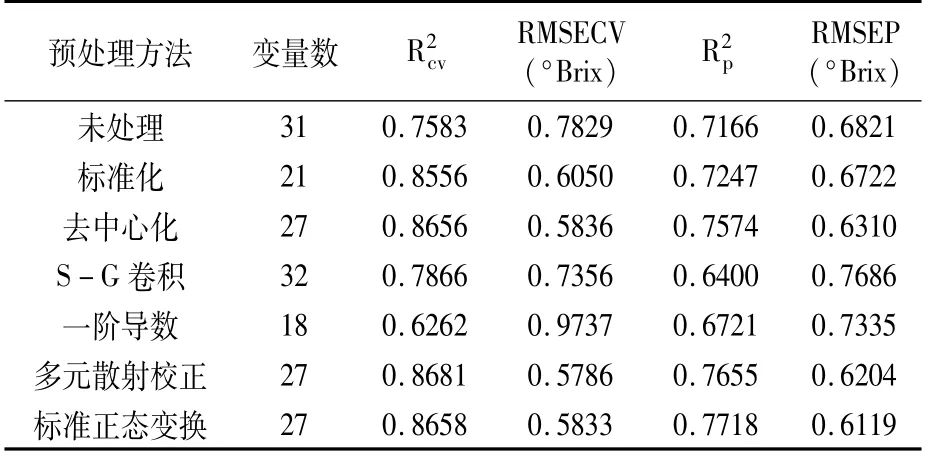
表2 高光谱数据不同预处理方法对模型精度的影响
2.5 不同方法对特征波段的选取结果分析
2.5.1 连续投影算法(SPA) SPA是一种前向的特征波段选择方法,能够利用向量空间的简单运算使所选变量之间的共线性最小,被广泛应用于光谱特征波段的提取中。将校正集数据输入SPA,设定最大提取波段数为30,对交叉验证均方根误差(root mean square error of cross validation,RMSECV)随特征波段选取数目的变化进行分析,结果(图9)发现,当选取的波段数为20时,RMSECV达到最小值。此时选取的特征波段见图10。
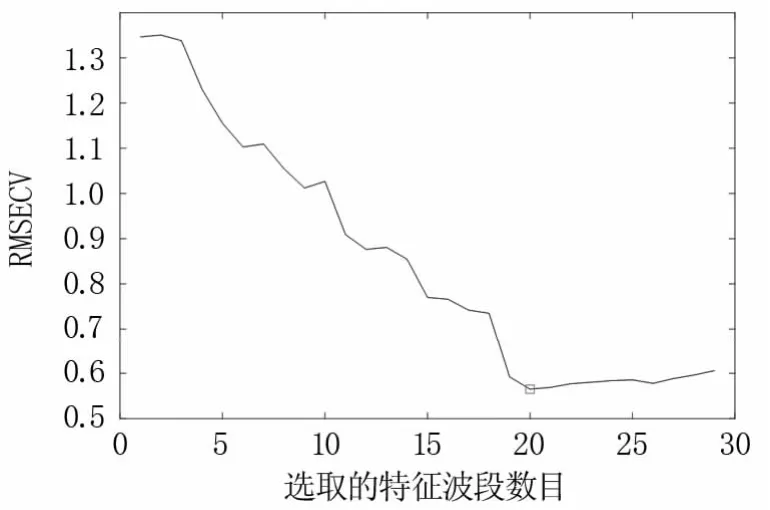
图9 连续投影算法的交叉验证均方根误差随特征波段选取数目的变化趋势

图10 选取的特征波段分布
2.5.2 主成分分析(PCA) PCA可将原有高维度的光谱数据投影到另一个低维度的特征空间中,用几个综合性强的变量来替代众多的原始变量[17],进而达到对特征数据的提取。在此算法中,提取的主成分个数(k)至关重要,k值过小会导致提取的主成分遗失原始高光谱数据中的部分重要信息,k值过大则会导致提取的主成分过多,达不到降低计算量的目的。通过RMSECV随k值的变化趋势(图11)可以看出,随着k值的增加,RMSECV逐渐减小,当k值达到41后,RMSECV变化不再显著,且k值过大,模型计算的复杂度也会增大,因此,最终选取41个主成分,其累计贡献率大于99.99%。
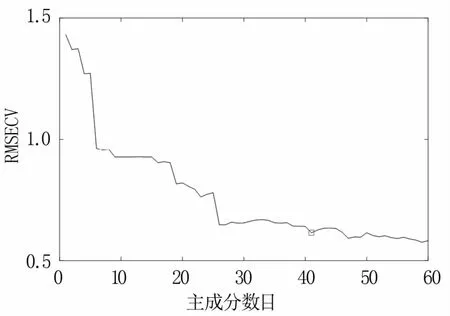
图11 主成分分析中交叉验证均方根误差随主成分数目的变化趋势
2.5.3 反向区间偏最小二乘法(BiPLS) BiPLS是对全波段进行划分,选取其中最具代表性的光谱区间组合。BiPLS算法中子区间个数(n)的确定至关重要,直接影响后续模型的精度。因此,本研究设置从5到60,步长为5,共12个取值,通过分析模型的RMSECV随n值变化(图12),发现当n为25时RMSECV值最小。以初始子区间个数为25,设计不断增加去除子区间的个数,以进一步优化子区间数目,结果(图13)显示,随去除子区间数目的增加,RMSECV整体趋势为先下降后上升,在去除17个子区间后,RMSECV最小。此时剩余8个子区间即为最终选定的区间,其编号为11、13、15、16、18、20、22和24,波段分布见图14。

图12 反向区间偏最小二乘法中交叉验证均方根误差随子区间数目的变化趋势
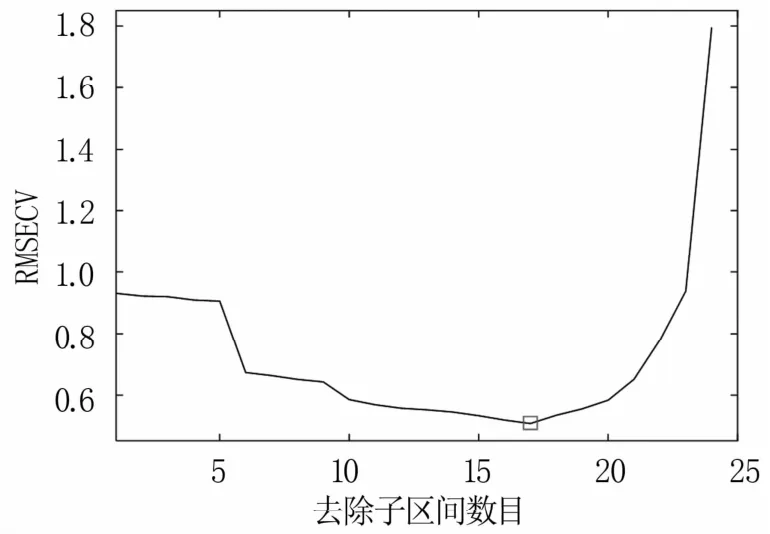
图13 交叉验证均方根误差随去除子区间数目的变化趋势
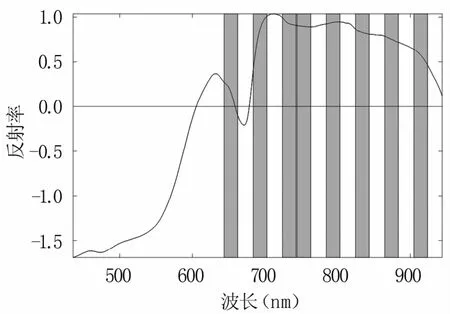
图14 BiPLS最终选定子区间的分布
2.5.4 蚁群算法(ACO) ACO是一种寻找优化路径的概率型算法,具有信息正反馈、分布式计算和贪婪启发式搜索的特征[21]。采用ACO在全波段中进行特征波段的筛选时,算法中的超参数需经过多次试验确定,因此,本试验设置最大迭代次数为50,种群大小为40,最大选取波段数为50,挥发因子为0.65,显著因子为0.01,训练完成后得到每个波段被选择的次数(图15),将波段按照被选次数的多少进行排序,依次对排序前60的波段进行PLSR建模,发现取前38个被选次数多的波段进行建模时,RMSECV最小。因此,这38个波段即为选定的特征波段,其在光谱曲线上的分布如图16所示。
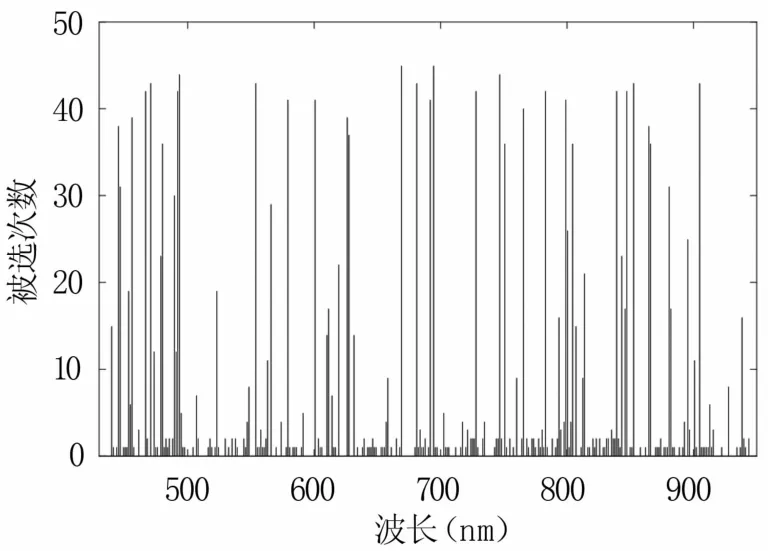
图15 蚁群算法中波段被选次数分布
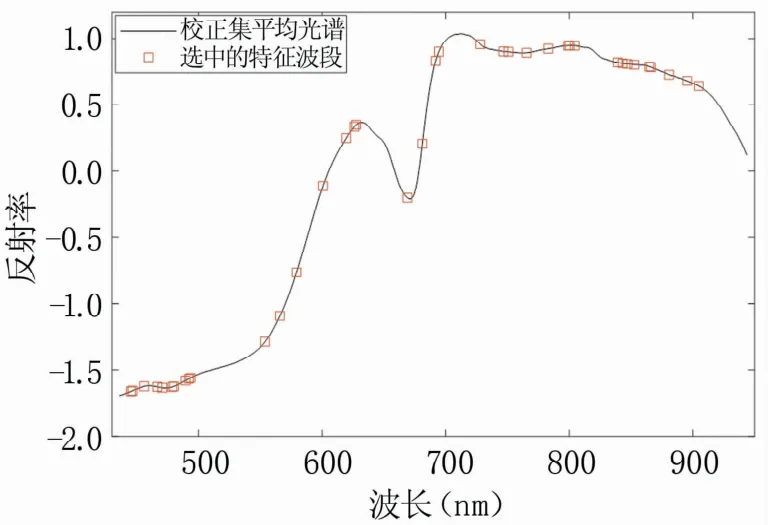
图16 蚁群算法选定的特征波段的分布
2.5.5 竞争性自适应重加权算法(CARS)CARS方法可利用PLSR的回归系数简单有效地选取全光谱中的最优波段组合。本试验利用校正集数据,采用CARS算法,设置最大迭代次数为100,进行特征波段的选取,结果(图17)显示,随着迭代次数的增加,保留的波段数呈指数函数减少,其中前期为变量的粗选,后期为精选;RMSECV整体呈先下降后上升的变化趋势,在第20次循环采样时RMSECV达到最小值,此时对应的保留波段数目为40个,即为选出的特征波段,其分布如图18所示。

图17 竞争性自适应重加权算法中变量个数和RMSECV随迭代次数的变化趋势
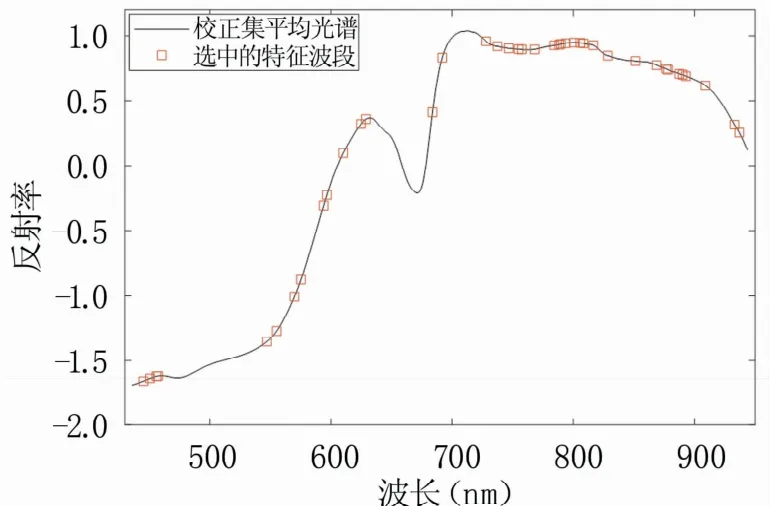
图18 CARS算法选出的特征波段的分布
2.6 回归模型的建立及最优模型的选取
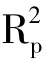
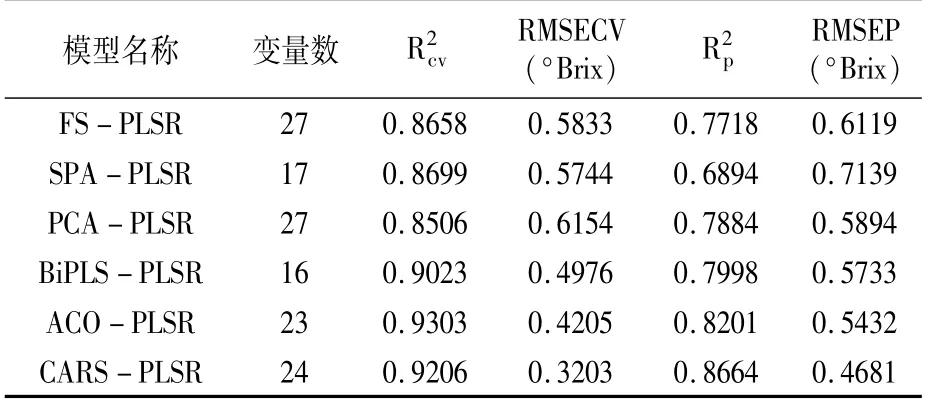
表3 不同方法建立模型的预测结果
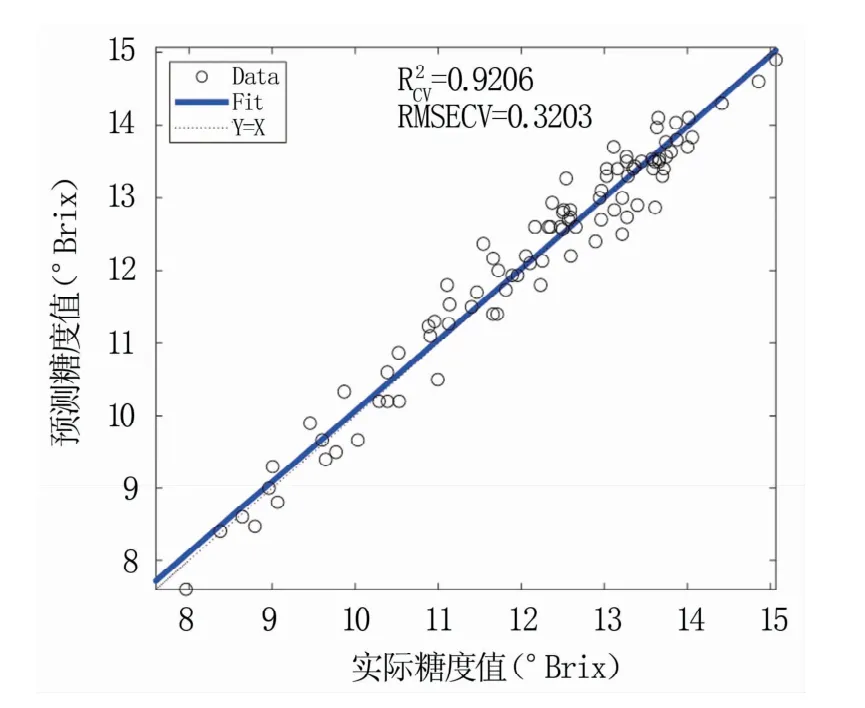
图19 校正集预测结果散点图
3 结论
本研究提出了一种适用于任意姿态苹果的高光谱图像感兴趣区域选取方法,与以往对固定姿态苹果图像人工选取感兴趣区域不同,本方法更适宜流水线的自动化要求。
该方法首先采用高光谱图像各像素点700 nm波长的光谱强度值进行阈值分割,选取700 nm光谱强度值前40%的区域进行形态学腐蚀操作,去除背景区域、果梗或果萼区域及光谱强度较低的区域,之后再去除保留区域中700 nm光谱强度值大于3 900的像素点,从而获得苹果原始感兴趣区域;然后,建立不同大小感兴趣区域对应的特征光谱与苹果糖度的PLSR模型,根据预测精度进一步缩小感兴趣区域,最终选取原始感兴趣区域光谱强度前70%的区域作为苹果感兴趣区域。
总之,本研究建立的苹果感兴趣区域选择方法准确性和有效性较高,可为后续基于高光谱成像技术的苹果在线分级系统的设计奠定理论基础,具有重要的实用价值。
