基于LSTM 的关键词识别系统设计
2022-07-09李爽
李爽
(贵州财经大学 贵州省贵阳市 550003)
在互联网时代,人们经常在网络上发布各种信息,而出于种种原因,人们需要提取信息中的关键词。比如对于政府部门而言,他们需要了解信息是中是否包含一些敏感的关键词;而企业需要结合市场调研的需求了解信息中是否包含某些关键词;部分个人也结合自己的需求,需要在网络中识别关键词。现以在网络上建立一个基于LSTM 的关键词识别系统,它能对网络信息进行快速的获取及分析,并给出相应的评估。
1 基于LSTM的关键词提取系统建立
爬虫的英语名称为Spider,它又称数据采集。这种工具的应用就是模拟浏览器打开网页,然后抓取网页中的资源以后,分析提取需要的数据信息,爬虫工具是人们提取关键词的常用工具,为了满足人们的需求,人们开发了各处各样的爬虫工具。该次应用爬虫工具为Heritrix 来建立关键词提取系统,它是应用java 语言开发的,开源的网络爬虫。它的特点是应用了模块化的设计,允许用户应用控制器CrawlController 来协调,建立自己的关键词抓取逻辑。
建立基于LSTM 的关键词提取流程:
(1)数据获取,这一流程完成网页的抓取;
(2)数据预处理,应用一套规则对网页文本进行预处理,减少系统分析的负担;
(3)测试数据,这是指通过对比,发现与预设的关键词完全一致的字词直接提交;
(4)训练数据,将文本依次交给CBOW 和Skip-gram两种训练模型、NLPIR-ICTCLAS 系统、LSTM 模型进行处理,它们是能够学习捕捉关键词的模型;
(5)输出结果,即它能能够给出与之相近的关键词及所在的网页。这是基于 LSTM 的关键词提取的流程,应用这套流程,就可以以网络爬虫工具Heritrix 为基础,建立基于LSTM 的关键词提取系统。
2 基于LSTM的关键词提取系统建立的原理
随着社会向前发展,人们接受信息的方式发生了很大的变化,互联网平台成为人们接受信息的重要渠道。比如人们经常通过新浪微博、今日头条等网站接收信息。而为了满足用户接收信息的需求,互联网站也会发布大量的信息。此时人们面对一个问题,从社会的角度分析,网站中是否出现了违规信息,这些信息的传播可能会对社会造成不良的影响;从服务的角度分析,网站需要为用户推送他们需要的信息,使他们能够在第一时间发现自己关注的各种信息。无论是从监督的角度,还是从服务的角度,社会的需求提出一个指向,人们需要关键词提取系统。这是因为人工提取关键词,虽然准确度高,但是效率太低,人们需要智能化提取关键词的方法,人们需要应用相关算法智能提取关键词的技术,然后建立关键词提取系统。
关键词抽取方法分为两种,一种是有监督,一种是无监督。有监督是指将关键词提取出来,计算机只需要对关键词作出一个二分判断,即根据字符对比,它是或者不是人们要求获取的关键词。这种方法要求人们建立一个词表,然后计算机基于词表来对比关键词。这种方式需要人们花费太多的时间、精力、成本构建词表,标注语料,一旦人们有了新的关键词提取需求,便需要扩充词表。这种方式受到各种制约,难以被广泛应用。无监督则是基于统计特征抽取算法,然后对比词图模型来分析它是不是人们需要提取的关键词,当前人们已经研发出各种词图模型抽取算法。LSTM 就是算法的一种,它是一种理论完备、实现简单、性能优良的词图模型。如果人们能够建立一套需要提取关键词的词库,那么它就能基于这套词库的基础上开展机器学习,然后以智能化的方式,依照词图模型来提取各种关键词。
那么基于LSTM 的关键词提取系统的应用原理,实际上就是:建立一套系统,让系统能够自动的获取网站信息,并将网站中的信息视为文本信息,它将对文本信息进行预处理;建立词表,根据人们输入的关键词,建立关键词的特征,在实际应用中,汉语与英语的语言表达特征不同,人们需要结合这两种语言的特点建立词表;基于LSTM 建立词图模型,它是抓取关键词的依据;对系统进行评价,对系统的技术应用进行微调,让应用效果达到人们的关键词提取需求。
3 基于LSTM的关键词提取系统的关键技术
3.1 数据获取的预处理技术
受到时间、技术的限制,人们需要对数据进行预处理,这一步的工作目的是确定提取关键词的范围和规则。结合这一次设计的需求,对数据进行以下的预处理:
(1)时间的限制,该次设计将3 个月以内的数据作为数据处理的范围。
(2)限定数据分析的批次,即限定爬虫抓取关键词的周期,该次设计24 小时为一个周期,即每天完成一次关键词的提取。
(3)设计数据规范化及去除无关数据或重复数据,为了减少分析范围,提高关键词提取效率,现设计设计数据规范化及去除无关数据或重复数据,将常见的无意义关键词作为无关词汇,比如“ok”、“同意”等。
3.2 Word2vec原理
为了能够让系统能够自动的学习关键词,有效的捕捉与之相似的词汇,人们研发了相似词汇聚类的技术。CBOW和Skip-gram 两种训练模型就是这种技术应用的典型,参看图1,CBOW 模型能够快速的根据上下文来预关键词,而Skip-gram 模型则能根据关键词来预测上下文。它们的算法都是以w(t)来分析 2a 个词向量的方式来抓取关键词。应用了Word2vec 原理,它能够逐渐的学习文本中各种关键词的组合方式,从而让关键词的抓取更加准确。

图1: CBOW 和Skip-gram 两种训练模型
3.3 中文关键词提取技术
在中文语境下,人们不仅提出要抓取英文关键词,还提出抓取中文关键词的需求。然而与英文不同,汉语词语之间没有界限。为了能够学会提取中文文本的关键词,现应用NLPIR-ICTCLAS 系统来对中文文本进行分词处理。参看表1,这套系统收集了一套庞大的中文词汇库,它将词汇进行了分类处理,然后对汉语语言的词汇进行了编码。将这套人工智能技术引入到系统中,能让系统学会捕捉中文文本中的关键词,并且这套系统的庆用既可以增加分词获取的准确性,又确保分词提取的效率。

表1: NLPIR-ICTCLAS 系统对中文文本进行分词处理(部分)
3.4 LSTM 模型
LSTM 模型是能长短时间记忆神经网络 (Long Short Term Memory Neural Network, LSTM)的算法。是它是基于时间序列的链式形式提取关键词的算法。该次建立的LSTM模型主要涉及到计算过程如下:
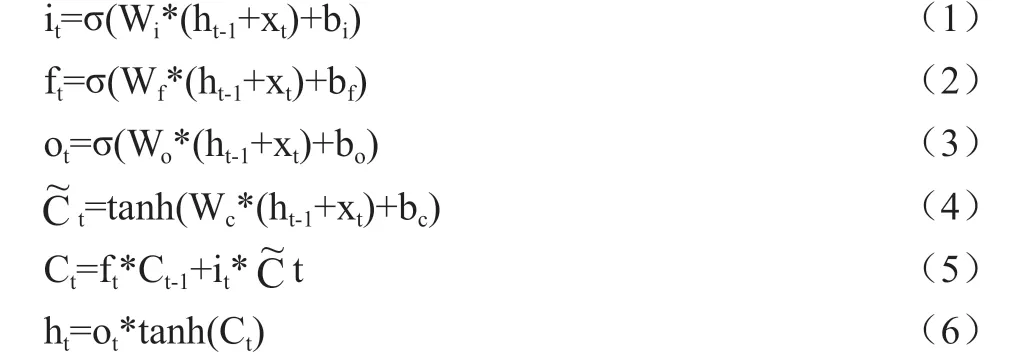
(公式1)~(公式3)建立了遗忘门的规则,它分别对应着时间、批次、规范化的约束。比如在中文文本模型中,为了有效的抓取关键词,现设名词“俄罗斯”作为关键词,那么在“俄罗斯与乌克兰进行了一次交易”中,当发现了“俄罗斯”这个名词时,那么其它的名词就会被遗忘。(公式4)与(公式5)建立了更新门的规则,即它能够根据关键词对后续的文本进行预测,(公式4)中预测了关键词是不是会出现。比如当出现了“俄罗斯”这个关键词后,它能自动预测出后面的词性是什么,即预测出后面的文本是不是会出现关键词。然而人们发现有时关键词会出现一些变体,比如与“俄罗斯”有关的词汇还包括:“俄”、“俄国”、“鹅”、“大鹅”,这些词汇有可能是简写、有可能是繁写、有可能是主观因素或客观因素写错了,这些变体词汇实际上与关键词是一个意思,为了抓住这些变体的词汇,现应用(公式6)进行约束,应用这一规则,就能够结合规则,结合前后文语境来分析关键词,从而分析出变体的关键词。(公式6)是最后呈现关键词抓取最后的计算结果。LSTM 模型是一种基于叠加的线性形式处理序列数据信息的模型,它的应用优点为避免梯度消失,支持较长周期的学习。
4 基于LSTM的关键词提取系统的代码实现
该次应用Java语言完成代码的编写,该次的设计思想为:
(1)网页获取,应用Jsoup.connect(url).get 语句来获取网页,然后应用getElementsByClass()或者select()来提取源代码。
(2)关键词的设计,应用keywords=的语句来输入关键词,应用这一方式,能够把关键字字符串和前面的网址连接起来。
(3)页数变化的支持,应用pagenum=来设定最多可以读取几页网址,应用这一设计,能够将多页面的网址拼接起来,合并处理。
(4)关键词范围的设计,应用select(“div.zx-tl”)提取关键词,实际上网页的关键词信息都在zx-tl 的div 块标签里,那么将抓取范围设计为getElementsByClass(“zx-tl”)。
(5)设置文章链接的范围,实际上关键词都在类名为artical-content 的div 块里,那么应用select(“div.articalcontent”)或getElementsByClass(“artical-content”)提取 关键词。
(6)将文章的标题和抓取的内容写入txt 文件。基于LSTM 的关键词提取系统的代码实现(部分)如图2 所示。

图2: 基于LSTM 的关键词提取系统的代码实现(部分)
5 基于LSTM的关键词提取系统应用效果
5.1 分句数据提取特点分析
为了说明基于LSTM 的关键词提取系统的分句提取特点分析,现应用这一系统来寻找:“新冠肺炎”这一关键词。该次在凤凰网的新闻版块抓取了5000 个网页,然后获得了分句总计182902 个,统计分句频率94573 个。现对抓取的分句进行分析:
(1)分句重复性比较高,它抓取了大量表述比较相似的分句,这些分句的表达比较相近。由此可以看到,这一次的系统能够抓出与预先输入非常相似的句子。
(2)能够抓取句子中存在语病的句子,有些用户写句子的时候,出现了写错字、写漏字的句子都被抓出来了。由此可以看到系统具有一定的学习效果,它能够结合语境分析出与关键词相关的句子。
(3)能够抓住简繁体不一致的句子,这与应用了智能化的NLPIR-ICTCLAS 系统有关,它将简繁体关键词关联,于是它能识别出简繁不一致的句子。
5.2 关键词提取准确度分析分析
分析刚才提取网页中关键词提取的准确度,统计结果如表2:从统计的结果中可以看到,它统计字级别的特殊为90.8%,即它统计出现了“新冠肺炎”这四个相同字的准确率非常高。统计单词级别的特殊为85.8%,即它统计出现了“新冠”、“肺炎”这样相同的词汇准确率比字的准确率略低。统计字词级别的特征准确率为87.6%,即它统计出现了“新冠肺炎”中任意出现了一个字,然后出现了与这个“新冠肺炎”相似语境的词汇,比如“非典型肺炎”这样词汇也会被抓取出来,它的准确率比基于词级别的特征词汇略高,却低于字级别的特征。统计出现了单词级别的特征准确率为88.8%,比如该次抓取了“非典型肺炎”,系统认为它与“新冠肺炎”十分相似,于是把它作为关键词提取出来。由实验可以看到,系统对于“字”的识别准确率高于“词”,然后抓取的准确率还是能够达到人们的要求。

表2: 关键词提取的准确度
6 总结
该次应用了Heritrix 来建立关键词提取系统,应用了数据获取的预处理技术、Word2vec 原理、NLPIR-ICTCLAS 系统中分词提取及映射的系统、LSTM 模型作为关键词的提取技术,应用Java 语言完成代码的编写,通过测试,发现它对分句及关键词的提取准确率良好,能够达到人们的需求。这一系统的应用,能够满足部分群体对出现“关键词”网页获取的需求,取得较好的应用效果。
