基于运维领域知识图谱的智能问答系统应用
2022-07-08李洪巍孙浩莫建坡曲荣胜王宇笙
李洪巍 孙浩 莫建坡 曲荣胜 王宇笙
(北京宝兰德软件股份有限公司 北京市 100089)
1 介绍
知识图谱本质是揭示实体之间关系的语义网络,由Google 于2012 年提出,其最初是为了优化搜索引擎的返回结果,增强用户搜索质量和体验。知识图谱不仅包含着事实类知识,同时也包含着更多的语义知识可为自然语言理解、智能问答及知识推理提供着强有力的支撑。基于知识图谱的智能问答目前主要分为两类方法,即基于信息检索的方法和基于语义解析的方法。
信息检索式的方法一般首先确定中心实体,其本质任务是命名实体识别(Name Entity Recognition),然后通过实体连接(Entity Linking)等技术映射到知识库中实体从而确定候选答案,最终基于候选答案的排序得分以确定结果。Li Dong 等人将候选答案和原问题分别向量化,再使用多通道卷积神经网络 (MCCNN) 计算候选答案与原问题之间的相似度。Siva Reddy 等人将候选实体生成与关系抽取 (Relation Extraction) 结合起来,利用原问题的上下文信息,使用卷积神经网络为候选实体对应的关系进行打分。Bordes A 等人将候选答案周围的边和节点一同作为子图进行 Embedding,再与原问题的向量做点乘作为得分,最终得出得分排序结果。
基于语义解析 (semantic parsing) 的方法一般而言可分解为三个任务,分别是短语检测、资源映射和语义组合。首先利用语义解析理解自然语言问题的语义,将问题转化为具备相同语义的逻辑形式,再通过查询引擎对生成的逻辑形式进行查询处理,得到最终结果。这类方法的优点在于如果解析成功,则能完整获得提问者的意图,从而精确地返回查询结果。与此同时,将生成的逻辑形式展示给用户可以让用户检验系统是否理解正确,哪一步解析发生了错误,从而利用用户反馈进一步改善系统的精度。因此这种方法是一种“可解释”的面向知识图谱的自然语言问答方法。语义解析式的问答系统所生成的逻辑形式一般与对应数据库的查询语言相同,例如 RDF 知识库对应的 SPARQL 语言,从而进行查询。
工业界基于知识图谱的智能问答大多数侧重于简单问题的回答,例如运维领域知识图谱下查询“Linux2174 机器的状态是什么?”,而对于较为复杂多跳问题如“查询K8S_NODE 关联的服务是什么?”,当前KBQA(基于知识库的问答)解决方案大多为对问题进行关系抽取时,多跳问题的多种关系拼接为新的关系标签,从而利用模型进行多跳关系识别,最终将多跳关系拆分再结合实体进行图库查询操作。如上述的二跳问题需要打标为“关联,服务名称”这种二跳标签,但随着知识库不断增大,关系数量愈发增多以及面临更加复杂的三跳问题时,上述方案产生的数据成本便成指数增加,并且覆盖率也会降低。
针对于此,本文提出了一种应用于运维领域知识图谱智能问答系统OMQA,该系统基于分类策略及子图匹配方法解决复杂多跳问题,首先利用预训练语言模型进行多跳问题识别,再进行中心实体的提取,根据中心实体召回多跳子图作为候选答案,最终进行问题与候选答案的相似度匹配确定结果。该方案在运维领域知识图谱的智能问答上的复杂多跳问题上取得了显著效果。
2 系统结构
OMQA 系统基于运维领域知识图谱,旨在通过解析中文自然语言问题,并从知识库中准确获取答案。本系统整体算法流程如图1 所示。其中单多跳分类器主要对输入问题进行单多跳问题区分,实体链指和子图召回部分须通过知识图谱完成候选子图生成;最终通过模型计算输入问题与候选子图的语义相似度进而返回问题答案。
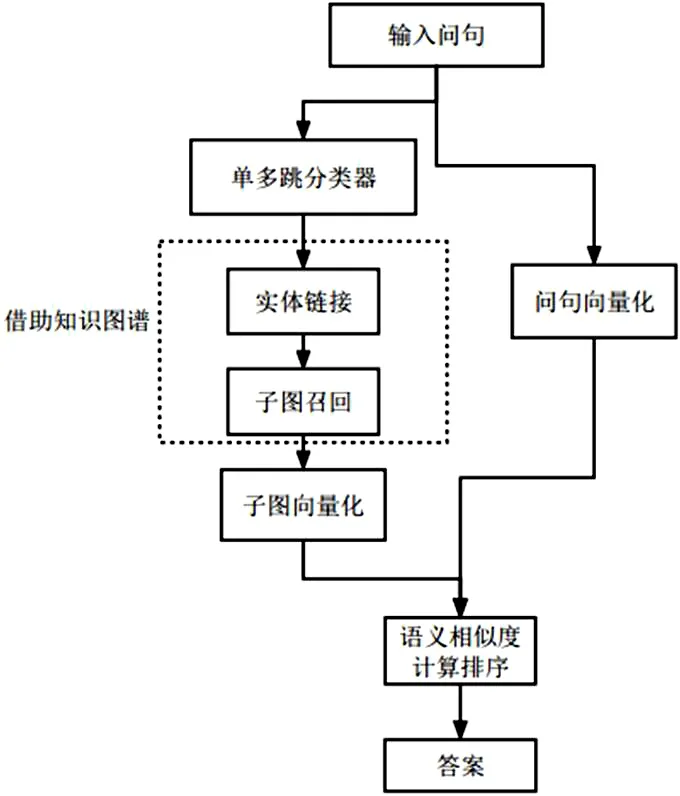
图1: OMQA 系统算法流程
2.1 单多跳问题分类
真实运维场景中,用户对于运维知识的查询问法可包括简单问题和复杂多跳问题,对于简单一跳问题已经很多较为成熟的解决方案,但涉及到多跳问题,工业界的解决思路较为局限。为解决该问题,本文将输入问题划分为一跳、二跳、三跳三类,三跳以上问题比较少见且缺乏实际意义。如表1所示。

表1: 单多跳问题示例
通常情况下,KBQA 处理单多跳问题时,须将一跳问题解析对应于单个三元组(头实体,关系,尾实体),二跳、三跳问题分别对应两个及三个三元组。OMQA 系统首先对单多跳问题进行类别划分,分类模型采用预训练模型RoBERTa。该模型作为Bert 的调优版本主要体现在预训练阶段具备更大的参数量、更大的批大小以及更多的训练数据;在训练方式上,RoBERTa 修改Bert 的静态掩码为动态以及更换文本编码方式进行训练等。在模型结构上还是采用Transformers的编码器为核心组成的多层双向编码语言模型。输入层分别词向量、段落向量及位置向量3 种向量相加,并拼接标志句子起始符[CLS]和分句符[SEP],然后经过核心为self -attention 机制的多层Transformers 编码器,通过多层编码器对于其上下文语义的充分学习后输出序列,此时起始标志位[CLS]包含了其他位置的语义信息,可用作文本分类等相关任务。
OMQA 系统单多跳分类器选择12 层RoBERTa 模型,假定用户输入自然语言语句“查询虚拟机的状态”,模型通过查询字向量表将文本中的每个字转换为一维向量与段落向量和位置向量进行相加得出输入序列I=([CLS],x,x,...,x,[SEP]),经 过12 层Transformers 编 码 器后输出T=(T,T,T,...,T,T)。此时输出向量T包含输入问题语义的全部信息,再利用全连接层进一步训练,最后利用Softmax 函数进行类别划分,最终得出单多跳问题类别结果,如式(1)。
y=softmax(TW+b) (1)
其中,softmax 函数可将输出结果映射为类别概率值,W∈R为隐藏层权重,b∈R为偏执项,K 表示类别数目。
2.2 实体链指
2.2.1 实体提及
实体链指任务大致可以拆分为两步,第一步先从文本中提取实体提及即命名实体识别任务;第二步则是对提及实体进行消歧,将其映射到知识图谱中的实体即实体链接。针对于运维领域KBQA 的命名实体识别任务,此处采用预训练模型BERT 对输入问句进行词向量的生成,与单多跳分类模型不同的是,此处模型经过训练之后输出每个字符的基于上下文的表示向量;然后利用BiGRU 网络则对BERT 的输出进行特征提取以及标签分类。GRU 网络在LSTM基础上合并其遗忘门和输入门改为更新门,简化了模型结构,减少了模型参数同时缩短了模型训练时间,但在效果上与之相当。BiGRU 则是将前向GRU 和后向GRU 的结果进行拼接,最终经过全连接层及Softmax 得到标签类别。此时BiGRU网络的输出经过CRF(条件随机场,Conditional Random Fields)模型用于计算标签序列,CRF 模型训练完成后,采用维特比算法进行解码算出概率最大的标签序列。BERTBiGRU-CRF 模型结构如图2 所示。

图2: BERT-BiGRU-CRF 模型结构
2.2.2 实体链接
鉴于运维知识图谱中实体具有很强的领域专业性,如实体为ip的纯数字类、机器编码等的纯字母类以及汉字与字母、数字混合类等。因此,模型从问题中识别的实体(实体提及)与知识库中真实存在的实体需要做实体链接。OMQA 系统将实体链接分为两步:候选实体集合生成和候选实体排序。
(1)候选实体集合生成。
候选实体的生成主要基于字符串匹配机制完成, 具体步骤为:
1. 对实体提及进行分词, 分词后得到集合E=[e,ep1,ep2,…epn],其中e 为实体提及,epi 为分词后的实体子词部分;
2.计算分词权重,如“虚拟机资源管理系统”经过分词得“虚拟机”、“资源”、“管理”、“系统”、“资源管理系统”,统计分词得到的子字符串和实体提及“虚拟机资源管理系统”,按照字数进行权重分配,权重系数分配公式见式(2)。

其中,S为实体提及的字符串总长度,S为子词长度。由此可计算出每个子词的权重系数。
3.遍历所有分词结果在知识库中进行匹配查找,得到所有候选实体,候选实体对应的权重为字符串的权重。
通过上述步骤可得出候选实体集合,然后需要对候选实体进行消岐排序得到最终实体。
(2)候选实体排序。
实体提及和候选实体集合的实体消岐在语义特征下主要进行问题与候选实体描述语义相似性计算,最终从候选实体集合中获得语义相似性最高的实体作为最终实体。语义相似性基于二分类的思想,训练数据采用链接实体作为正例,负例为候选实体集合中其他实体。首先将问题与候选实体描述文本拼接输入到BERT 模型,经过多层编码器后输出取[CLS]位置向量,如式(4)再经过全连接层及Sigmoid 函数得到候选实体的概率值,对所有候选实体的概率值进行排序,得到语义特征下的候选实体排序集合。

其中,K为BERT 输出的[CLS]位置向量,W∈R为隐藏层权重,b∈R为偏执项。
最后,结合语义特征维度计算得出的候选实体排序集合取得分最高者为链接实体。
2.3 子图召回与排序
OMQA 系统对于问题答案的获取需要经过问题的分类、实体识别及链接以及通过实体召回知识库候选子图并排序,最终完成答案输出。对于候选子图召回问题,例如问题1“查询虚拟机linux2071 的状态”和问题2“查询虚拟机2071 关联的节点的状态”分别为单跳和两跳问题,链接实体为“虚拟机linux2071”,从知识库中召回顶点为该实体的候选子图如图3 所示。

图3: “虚拟机linux2071”候选子图
图3 可以看出,实体“虚拟机linux2071”召回的子图共有6 条路径,如表2。

表2: 子图路径示例
从候选子图中获取问题答案采用基于孪生网络架构的SBERT模型进行文本相似度匹配,如图4 所示。
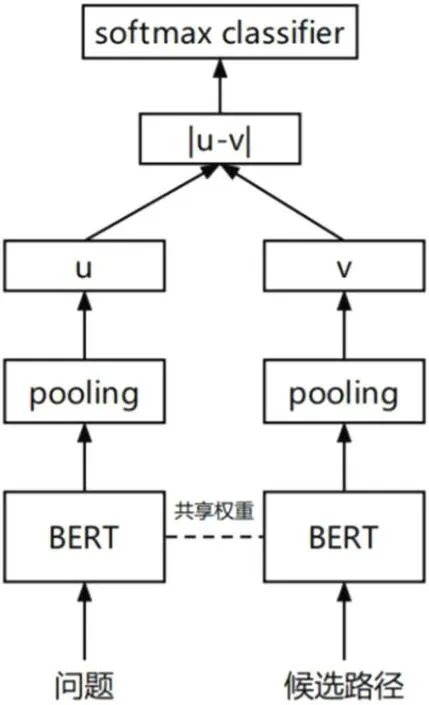
图4: SBERT 模型结构
模型输入分别为问题和候选子图路径,如二跳问题“查询虚拟机2071 关联的节点的状态”和对应两跳子图路径“虚拟机linux2071(节点)NODE_1(状态)正常”,两个文本同时输入到具有相同结构和权重的BERT 模型,然后模型输出的句子向量做平均池化处理,分别得到1×768 维向量u 和v,然后对向量u 和v 做差并取绝对值,最后经过全连接层及Softmax 函数预测类别(相似或不相似)。
3 实验分析
3.1 数据准备
本文实验使用数据基于运维领域构造的问答数据集以及运维领域知识图谱数据,问答数据约为6.5 万,知识图谱约4 万个实体和160 万个三元组。问答数据如表3 和表4 所示。

表3: 运维问答单多跳数据集描述

表4: 运维问答单多跳数据集示例
3.2 实验设置
OMQA 系统采用的模型设置如表5,实验采用CentOS系统及Tesla P40 显卡用于模型训练,采用Pytorch、Hugging face 库等构建模型。

表5: OPSQA 系统模型选择
以单多跳为例,RoBERTa 预训练模型采用的是基于Tensorflow 框架实现的RoBERTa_zh_L12,Bert 直接加载,具体设置如表6。

表6: 单多跳问题RoBERTa 模型参数
实验结果评价指标采用准确率(P)、召回率(P)、F1 值(P),具体计算公式如下:

3.3 实验结果与分析
在本文构建的OMQA 系统中,智能问答及各个子任务的实验结果如表7 和表8 所示。

表7: OMQA 实验结果
由表8 可以看出,OMQA 系统的实验最终结果F1 值为83.9%。召回率较低,为82.3%。在各个子任务中,单多跳问题分类实验准确率较高可达96.7%,可见分类模型对于问题的单、二、三跳问题识别较好。资源名称实体识别任务中,模型对于实体识别的准确率为88.6%,其中模型对于问句例如“查询虚拟机192.168.1.24_emoer 的状态”的实体“虚拟机192.168.1.24_emoer”识别结果准确率较低,针对于该类较为复杂的实体可增加此类实体的训练数据量。实体链接任务中,对于部分实体提及,实体链接可有效进行修正,例如“查询B 域-电渠周边的服务id”通过模型可提取实体“B 域-电渠”,利用实体提及搜索知识库构建候选实体集合进行实体链接时可链接到“B 域-电渠周边”,候选实体排序模型结合实体特征和语义特征两种方法所得到的结果最高分作为链接实体,两种维度分别的实验结果如表9,可见两种方法的结合对于实体链接准确率有较大地提升作用。

表8: OMQA 系统子任务实验指标

表9: 候选实体排序结果
OMQA 系统实验流程主要为根据单多跳问题分类与问题实体链指的结果召回知识库候选子图,然后根据候选子图的文本化表示与问题进行相似度匹配,过程中子图排序任务仅为问题与候选子图集合的匹配任务,该任务实验准确率较高为92.1%,在子图排序任务中,单多跳问题分别对应单多跳子图集合,如二跳问题对应于二跳子图集合,对于减少子图集合数量及提高了准确率有着显著效果。但整体系统基于管道流程设计,整体实验最终结果依赖于前面模型步骤,如实体链接依赖于实体识别模型效果,子图排序结果依赖于单多跳问题分类以及实体识别及链接效果,形成链式误差传递,因此在系统的整体流程设计以及未来工作研究中还需要继续改进该问题。
4 结束语
本文提出了一种基于运维领域知识图谱的智能问答系统OMQA。系统首先对于问题进行单多跳分类,分类模型采用预训练模型RoBERTa;然后选择BERT-BiGRU-CRF 模型对问题进行资源名称实体识别,在实体链接方面,结合实体相似度与语义相似度结合链接候选实体。最后通过链接实体召回候选子图集合,单跳、多跳问题分别召回单跳、多跳子图,最终将候选子图的文本化表示与问题利用SBERT 进行语义相似度匹配,确定问题答案。实验结果表明,该系统方案可有效解决知识图谱问答的复杂多跳问题,并且极大提升了系统性能。
但同时,系统方法存在着一定程度的不足,例如管道流程设计所导致的误差传递问题,单多跳分类任务的误差、实体链指的误差都会降低子图匹配的准确率。因此,在后续的工作研究中还需要针对于该问题提出更好的解决方案。
