基于改进YOLOv4的自然人群口罩佩戴检测方法
2022-07-07薛均晓武雪程王世豪田萌萌
薛均晓,武雪程,王世豪,田萌萌,石 磊
(郑州大学 网络空间安全学院,河南 郑州 450002)
0 引言
近期,国内新冠疫情防控态势依然很严峻,在人流量密集的场所极易出现病毒传播及感染现象。当前首要的防控措施仍为佩戴口罩,目前公共场所的防疫工作主要是人为地检查行人的口罩佩戴情况,这样做极易造成漏检及误检现象的发生。随着深度学习技术的进步,计算机视觉领域也取得了非常大的进展,利用飞速发展的计算机视觉技术来进行自然场景下的人群口罩佩戴检测任务能在很大程度上取得更好的疫情防控结果。
自然场景下的人群口罩佩戴检测任务实则为目标检测任务。近年来,应用神经网络来完成目标检测任务的方法层出不穷,诞生了Faster R-CNN[1]等诸多基于候选区域的目标检测算法。之后相关研究者提出了改进的单阶目标检测算法,与此同时YOLO[2]系列的目标检测算法也取得了迅速发展。
YOLO系列算法最早由Joseph Redmon等于2015年提出,并在YOLO算法的基础上开发了YOLOv2[3],YOLOv3[4]。2020年,YOLO系列算法的研究者Alexey Bochkovskiy提出YOLOv4[5],该算法基于YOLOv3,应用了大量的新兴手段,实现了速度与精度的完美均衡。
现有的主流检测算法应用到自然人群口罩佩戴检测任务中,会受到口罩样式颜色各异、佩戴者肤色以及天气等多种因素的影响,从而导致检测算法的准确率降低、鲁棒性较差以及不能够满足算法实时性要求等。其中,Faster R-CNN虽具有较高的准确率,但由于其网络结构的限制使得检测速率达不到基本的实时性要求;YOLOv3对于小目标物体的检测效果不够理想,并且整体的检测效果也相对较差。基于此,本文基于YOLOv4提出了一种优化的口罩佩戴检测算法。本文在原YOLOv4主干特征提取网络中引入协调注意力机制,并对网络结构进行改进,在后处理阶段使用DIoU-NMS来进行非极大值抑制。实验结果表明,本文提出的算法可以更好地满足疫情防控的实际需求。
1 YOLOv4算法
YOLOv4算法可以分成输入端、主干特征提取网络、加强特征提取网络以及输出端4部分。输入端包含图像预处理、将输入图像的大小变换为规定的输入大小以及对图像信息进行归一化等多种处理;其次是主干特征提取网络,YOLOv4加入融合CSPNet[6]后组成的CSPDarknet53作为主干特征提取网络;YOLOv4的加强特征提取网络由PANet[7]结构组成,用于提升特征表达的多样性以及加强特征信息的融合;最后为输出端,用于进行分类与回归任务以及最终预测结果的输出。
YOLOv4在经过主干特征提取网络之后共有3个输出,分别为L3、L4以及L5。其中L3与L4在经过一次1×1的卷积之后会输出至加强特征提取网络进行相应的特征融合;L5则会经过3次卷积后输入至空间金字塔池化层SPP,之后会进入加强特征提取网络进行特征融合。最后送入输出端便可得到最终的检测结果。
2 改进的YOLOv4算法
2.1 协调注意力机制
协调注意力机制是由Hou等[8]提出的一种新颖的注意力机制。协调注意力机制创新性地将空间位置信息嵌入到通道注意力中,进而解决SE(squeeze-and-excitation)中存在的只考虑内部通道信息而忽略位置信息的问题,同时也解决了CBAM(convolutional block attention module)无法获取远距离依赖关系的问题,并且避免引入大的计算开销。由于复杂自然场景下的人群口罩佩戴检测任务极易受物体遮拦或自然环境的影响,并且特征图像的分辨率越高,其感受野相对越小,对于特征的敏感程度也越高并且拥有更为丰富的空间位置信息,因此本文将协调注意力模块放在主干特征提取网络的前端进行指导。协调注意力模块的引入能够进一步提升主干特征提取网络对于小目标物体的捕捉能力,丰富浅层次特征图像的语义信息以及获取到更大区域的位置信息[9]。结合协调注意力机制后的主干特征提取网络能够捕获跨通道信息以及对方向、位置敏感的信息从而更精准地定位和识别目标区域。
协调注意力模块如图1所示,该模块分为两个步骤:坐标信息嵌入以及协调注意力生成。

图1 协调注意力模块Figure 1 Coordinate attention module
在坐标信息嵌入这一部分,协调注意力模块将二维的全局池化转换为分别只对单一维度的特征编码,促使协调注意力模块能够捕捉到具有精确位置信息的远程空间交互。给定输入X,使用尺寸为(h,1)和(1,w)的池化核,分别沿水平坐标方向以及垂直坐标方向对每个通道进行编码。如式(1)及式(2)所示,这两种变换沿着水平方向和垂直方向进行特征聚合并返回一组方向感知的特征图像。
(1)
(2)

在协调注意力生成部分,如式(3)所示,首先对该组方向感知的特征图像进行堆叠并通过卷积压缩其通道数,此时特征通道数为C/r,之后通过BatchNorm以及ReLU对垂直方向和水平方向的位置信息进行编码。接着沿空间维度将f切分为两个单独的张量fh∈RC/r×h和fw∈RC/r×w,再分别利用两次卷积将fh和fw变换为和输入X相等的特征通道数并进行归一化加权处理,得到gh和gw,如式(4)、(5)所示。
(3)
gh=σ(Fh(fh));
(4)
gw=σ(Fw(fw))。
(5)
式中:F1(·)表示首先对输入的两个张量进行堆叠,接着进行1次1×1的卷积,再进行BatchNorm数据归一化处理;δ(·)为ReLU激活函数;gh为生成的垂直方向权重;gw为生成的水平方向权重;Fh(·)以及Fw(·)分别代表一次1×1的卷积,用于调整通道数;σ(·)代表Sigmoid归一化加权处理。
最后对gh和gw进行扩展,作为协调注意力权重,协调注意力模块的最终输出如式(6)所示:
(6)

2.2 网络结构改进
原YOLOv4中的加强特征提取网络虽然在一定程度上可以提升深层次特征图像的语义表征及特征融合能力[10],但在自然场景下的人群口罩佩戴检测任务中,因目标较小及天气等多种因素的影响而导致实际检测结果并不理想。因此本文将空间金字塔池化层SPP前后的卷积层数均提升为5层。受到原始YOLOv4网络结构的启发,本文对L3及L4输出至加强特征提取网络之前的卷积层数进行提升,由原先的1层卷积提升为3层卷积。改进后的YOLOv4网络结构图如图2所示。这样做可进一步提升整体网络的容量及深度,提取到更深层次的特征,进一步扩大感受野,同时提升语义表征能力以及算法的鲁棒性[11]。

图2 改进YOLOv4网络结构图Figure 2 Improved YOLOv4 network structure diagram
2.3 DIoU-NMS
NMS(non maximum suppression)是目标检测任务中后处理阶段必备的算法,其目的在于去除冗余检测框,保留最为准确的检测框。
传统NMS(traditional-NMS)只使用IoU指标来抑制冗余框,但是这种方法对于目标重叠以及遮拦的情况经常出现错误的抑制;soft-NMS与传统NMS的区别仅在于对于目标所得预测分数的处理,并不能避免由于目标重叠以及遮拦导致的错误抑制的发生。基于上述问题,本文选取DIoU-NMS(Distance-IoU-NMS)来替代传统NMS。DIoU-NMS将DIoU作为NMS的准则,其在进行抑制的过程中不仅只考虑IoU指标,而且还考虑两个检测框之间的中心点距离。DIoU-NMS的优势在于如果两个检测框的IoU值相同则会对两个检测框的中心点距离进行比较:当两个检测框中心点距离较远时,DIoU-NMS则判定它们可能位于不同的目标上,并且DIoU-NMS对于IoU阈值的选取也并不苛刻。
DIoU-NMS的评价公式如式(7)及式(8)所示:
Si=0,fDIoU(M,Bi)≥thresh;
(7)
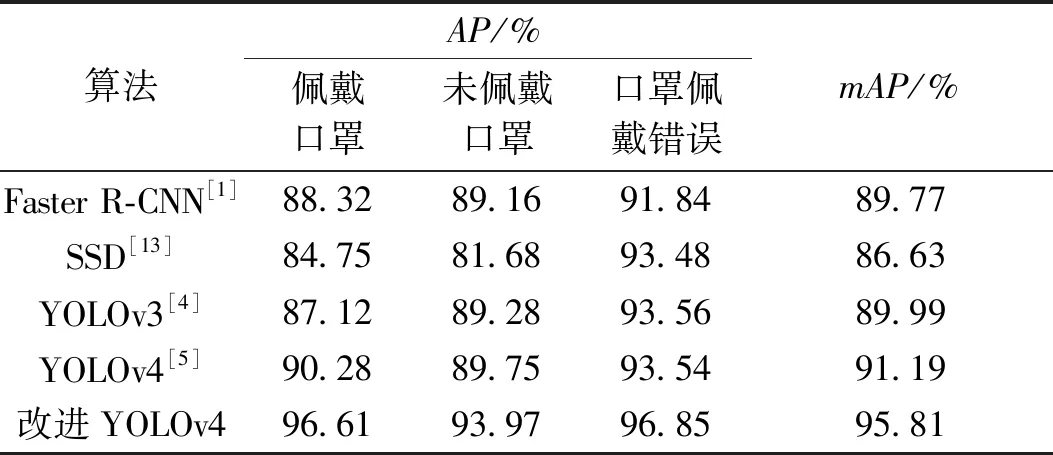
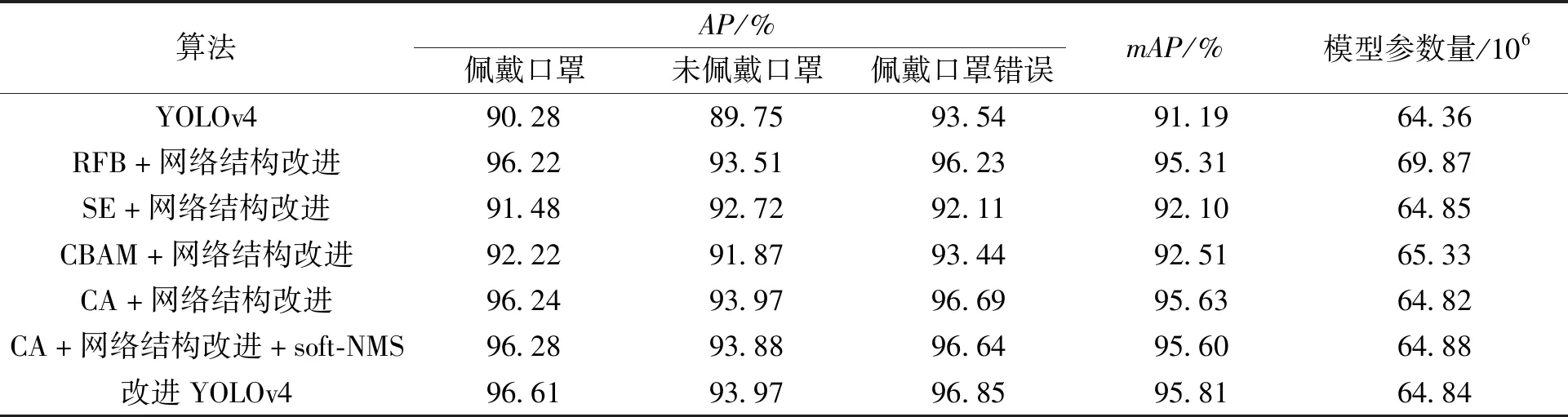
Si=Si,fDIoU(M,Bi) (8) 式中:thresh为设定的IoU阈值;fDIoU(M,Bi)为DIoU-NMS的判定结果;Si=0表示该检测框为冗余框,Si=Si表示该框为不同的目标框。 由于DIoU的特性使得本文对于IoU阈值的选取不再那么苛刻,并且将冗余框与得分值最高的检测框的中心点距离考虑进来,更有助于缓解目标存在遮拦而被错误抑制的现象。 本文实验基于PyTorch 1.8.1框架,编程语言为python3.7,操作系统为Ubuntu16.04,GPU为NVIDIA RTX2080Ti,集成开发环境为 PyCharm。网络的输入大小为 416×416,优化器使用Adam优化算法。权重衰减值decay设置为0.000 5,共训练120个epoch,其中在冰冻训练阶段共训练30个epoch,初始学习率设置为 0.001;在解冻训练阶段共训练90个epoch,初始学习率设置为0.000 1,采用余弦退火衰减学习率调整策略[12]。 目前有关自然场景下人群口罩佩戴检测任务的数据集很少,且普遍缺少口罩佩戴错误这一类别的数据。因此本文的数据集主要为利用网络爬虫技术爬取到的符合本文要求的图片,从RMFD等开放数据集中选取符合本文要求的一部分图片,以及通过网络视频抽帧获得的部分图片,除此之外又自制了部分图片进而构成了本文的原始数据集。原始数据集中共计7 854张图片,包含佩戴口罩、未佩戴口罩、口罩佩戴错误3个类别,涉及公共街道、地铁站等多个公共自然场景。口罩佩戴错误的情况主要包含未遮住鼻子、未遮住口鼻以及口罩在下巴处这3种最常见的口罩佩戴错误示例。数据集依照Pascal VOC格式进行标注,使用的标注工具为LabelImg。由于算力的限制以及Mosaic数据增强方法的不稳定性,针对原始数据集中数据量相对较小及所含口罩佩戴错误类别数据数量较少的情况,本文采用包括仿射旋转变换、高斯模糊、高斯滤波等多种方法在内的随机几何数据增强方法。图3(b)~3(d)均为本文使用上述随机几何数据增强方法的示例。数据增强之后数据集中图片的总数量为11 447,佩戴口罩、未佩戴口罩以及口罩佩戴错误这3个类别的数目分别为13 458、8 123、7 164。 图3 原图与数据增强后图片对比Figure 3 Comparison between the original image and the images after random data augmentation 在本文的实验中所选取的算法性能评价指标为平均精度(AP)和平均精度均值(mAP)。AP值从准确率P和召回率R两个方面来衡量模型的性能。准确率P表示实际是正类并且被预测为正类的样本占所有预测为正类的样本的比例;召回率R表示实际是正类并且被预测为正类的样本占所有实际为正类样本的比例,公式如式(9)、(10)所示: (9) (10) 式中:TP为被检测为正样本的正样本;FN为被误检为负样本的正样本;FP为被误检为正样本的负样本。 AP值由准确率-召回率曲线积分计算。AP的值越高,模型表现越好。mAP是各个类别AP值的平均值,用于衡量多个目标类别的平均检测精度。mAP值的大小可体现出模型对所有类别综合检测性能的高低。 (11) (12) 式中:Ci代表各个类别的AP值;c为任务中所需要检测的类别数目。 改进YOLOv4的平均精度如图4所示。最终算法的mAP值为 95.81%。与原 YOLOv4相比,mAP值提升了4.62%。 图4 平均精度图Figure 4 Diagram of average precision 为综合评估本算法的性能,本文将改进YOLOv4的实验结果与其他主流目标检测算法的实验结果进行对比,具体实验结果如表1所示。由表1可以看出,改进YOLOv4算法相较于Faster R-CNN、SSD、YOLOv3以及原YOLOv4的AP值均有较大提升;同时,改进YOLOv4算法的mAP值也优于以上4种基线方法。本文提出的YOLOv4算法改进方案加强了对图像特征的提取能力,进一步提升了对小目标物体的检测能力,以及特征图像的语义表征能力,扩大了深层次特征图像的感受野,同时对细节特征的处理也有所提升。通过对比目前主流的检测算法,进一步证实了本文 表1 不同主流检测算法的性能对比Table 1 Performance comparison of different mainstream detection algorithms 针对自然人群口罩佩戴检测任务提出的算法设计方案的有效性。 对于自然场景下的人群口罩佩戴检测任务而言,要求算法具有较好的实时性。因此本文对算法的实时性也进行了测试,设置样本数量为5,在同一台设备上对改进YOLOv4算法以及主流的目标检测算法的实时性进行了测试,测试结果如表2所示。由表2可以看出,本文提出的算法在较大幅度提升检测精度的前提下,其检测速率为24.40帧/s,比原YOLOv4算法仅下降1.29帧/s,仍能够满足基本的算法实时性要求。 表2 检测速率对比Table 2 Comparison of detection rates of different mainstream detection algorithms 本文提出了一系列的消融实验方案来验证算法改进方案的有效性。消融实验中共设置有7组实验,具体方案如下所示:第1组,原YOLOv4算法,设置该组实验的目的在于作为对照以确定改进是否有效;第2组,RFB(receptive fields block)模块+网络结构改进;第3组,SE模块+网络结构改进;第4组,CBAM模块+网络结构改进;第5组,CA(coordinate attention)模块+网络结构改进;第6组,CA模块+网络结构改进+soft-NMS;第7组,CA模块+网络结构改进+DIoU-NMS,即改进YOLOv4。 此处设置第3组及第4组实验的目的在于确定本文所使用的CA模块的有效性。设置第6组实验的目的在于与第7组实验进行对比,以确定后处理阶段DIoU-NMS的有效性。 第2组实验只关注对于深层次特征图像的语义表征能力的提升。文中使用RFB模块来替代原先网络结构中的空间金字塔池化层,得以进一步扩大感受野,目的在于进一步提升深层次特征图像的语义表征能力,进而与第5组实验形成鲜明对照。消融实验结果如表3所示。 表3 消融实验结果Table 3 Results of ablation studies 本文通过消融实验,证实了CA模块相较于SE模块以及CBAM模块在该任务中的有效性及网络结构改进的有效性,同时也证实了DIoU-NMS相较于传统NMS以及soft-NMS在处理目标重叠以及遮拦而发生错误抑制问题时的有效性。除此之外,本文还证实了同时加强深层次特征图像以及浅层次特征图像的语义表征能力的效果,要优于仅加强深层次特征图像的语义表征能力的效果。最终在没有过多增加参数量的情况下,本文提出的算法改进方案的mAP值比原YOLOv4算法提高了4.62百分点。 分析可知,本文提出的改进YOLOv4算法性能提升的原因在于将CA模块应用于主干特征提取网络的前端进行指导,致使浅层次特征图像的语义表征能力更强;同时,网络结构的改进进一步提升深层次特征图像的语义表征能力。因此本文提出的算法改进方案使得3个中间特征图像L3、L4、L5在输入至加强特征提取网络之前含有比原YOLOv4更加丰富的语义信息,并且使网络可以更加精准地定位和识别目标区域。 实际检测效果对比如图5所示,其中图5(b)为改进YOLOv4检测效果图,图5(a)为原YOLOv4检测效果图。在复杂的自然人群场景下原YOLOv4存在着较为严重的漏检以及错检现象,并且对于人物侧脸以及受物体遮挡的情况处理效果不佳,而改进YOLOv4的检测结果中目标漏检以及错检的现象均有所缓解,同时算法提升了对于人物侧脸以及受物体遮挡情况的处理效果。 图5 改进前后YOLOv4检测效果图Figure 5 YOLOv4 test results before and after improvement 本文提出一种基于改进YOLOv4的口罩佩戴检测算法。该算法针对主干特征提取网络提取的浅层次特征拥有更丰富的空间位置信息但匮乏语义信息这一特性,通过引入协调注意力机制来加强主干特征提取网络在复杂自然场景下对于小目标物体的检测能力;增加空间金字塔池化层SPP前后的卷积层数,以及L3和L4在输出至PANet之前的卷积层数进而提升整体网络的容量和深度;在后处理阶段应用DIoU-NMS来缓解错误抑制的现象。实验结果表明,本文提出的改进YOLOv4具有良好的性能,能够满足疫情防控场景下的实际需求。下一步将会在保证高准确率的基础上进一步对模型进行剪枝以及优化,以期获得更高的检测速率,进而更好地提升算法的实时性。3 实验及结果分析
3.1 数据集介绍

3.2 评价指标及实验结果分析
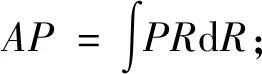


3.3 消融实验
3.4 检测效果对比

4 结论
