基于个性化推荐的服装知识图谱构建
2022-07-07潘王蕾
潘王蕾,何 瑛*,2
(1.浙江理工大学 服装学院,浙江 杭州 310018; 2.浙江理工大学 丝绸文化传承与产品设计数字化技术文化和旅游部重点实验室,浙江 杭州 310018)
随着生活水平的不断提高,人们的消费需求逐步个性化。同时,服装的品类和产量不断增加,消费者网购时需要花费大量的精力与时间才能找到心仪的商品,因此服装个性化推荐至关重要。服装个性化系统可以根据用户的需求和偏好推荐服装,减少消费者检索时间,提高购物效率,增加其对所推荐服装的购买意愿。
服装个性化推荐模型主要由服装信息获取和服装推荐算法组成。服装信息获取主要采用视觉图像识别的方法识别服装属性特征,或通过数据爬取、信息挖掘等方式构建推荐模型[1-2]。服装推荐算法主要用于服装属性特征的评价权重分析以及服装属性信息的聚类研究。例如,胡觉亮等[3]、单毓馥等[4]根据用户权重给服装打分,并推荐评分最高的服装给顾客。也有学者通过对用户偏好进行聚类产生用户集合,结合服装基础特征语义推荐合适的服装,以提高推荐准确率[5-6]。但上述大部分研究忽略了服装在购物环境中呈现的外在属性,如服装品牌、服装销售渠道以及在线评论等,这些也是影响用户购买意愿的因素之一。蔡丽玲等[7]提出,线上评论内容对消费者购买意愿有显著影响。因此,可以通过在服装推荐系统中添加辅助信息来补全服装属性,而知识图谱通常包含商品属性以及各项目之间的关系,通过知识图谱中丰富的商品语义,可以深入挖掘用户的潜在兴趣。
知识图谱是2012年由Google正式提出的,用来描述真实世界中存在的各种实体或概念以及它们之间的关系。知识图谱通常采用三元组
文中提出了知识图谱在服装个性化推荐领域的应用方法,结合专家意见、文献资料以及平台调研数据,把在线评论情感分析加入服装属性中,从电商平台获取服装数据,构建服装领域知识图谱,全方位描述服装、用户信息,构建两者间的关系,为服装个性化推荐提供新思路,从而提高消费者购买意愿。
1 服装领域知识图谱构建
在大数据时代,知识图谱是一种重要的知识表达形式,它通过符号对现实世界进行抽象表达。知识图谱主要采用自顶向下和自底向上两种构建模式[13],其中自顶向下模式是在定义实体属性及其相互关系后,进行知识图谱数据的抽取和构建;自底向上模式是指从底层对实体或事件进行归纳后,向上逐步建立实体关系,从而得到知识图谱。将两种方式结合构建知识图谱,可以使多源数据根据概念层知识体系进行精准抽取与存储。
文中采用自底向上及自顶向下混合模式进行服装领域知识图谱构建,具体流程如图1所示。服装知识图谱主要由模式层和数据层两部分构成,模式层采用自顶向下的方式构建,由人工整理出图谱要素,定义实体属性关系,以提高服装知识图谱的构建质量;数据层以模式层为理论基础,通过自底向上的方式构建,在底层获取电商平台数据源信息,根据模式层服装罗列的要素和定义的属性值开展知识抽取、融合和存储等,从而完成服装知识图谱构建。
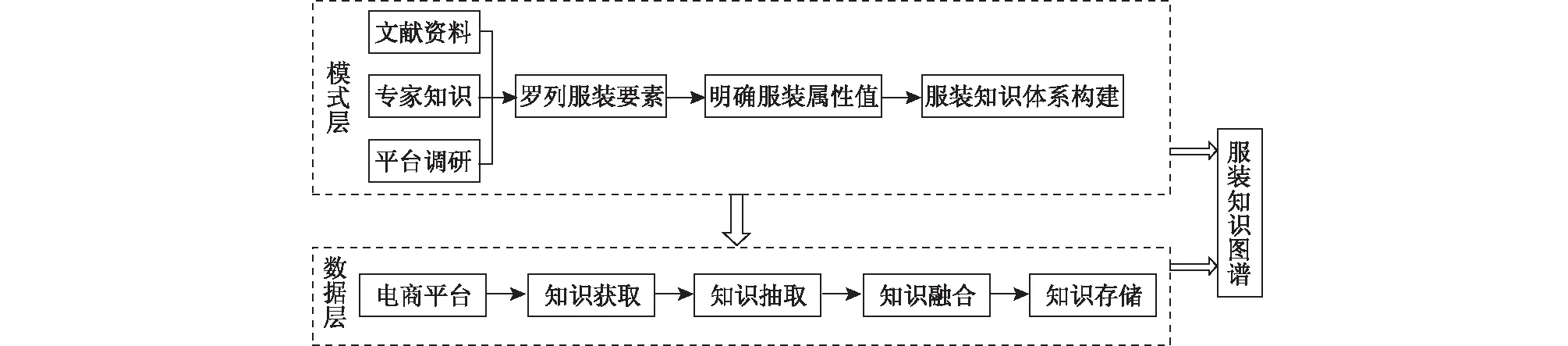
图1 服装知识图谱构建流程Fig.1 Construction process of clothing knowledge graph
1.1 模式层构建
模式层主要是对服装知识体系的构建,是对实体的抽象描述,包含各要素及其关系的集合,并由此形成基础理论框架。模式层构建的主要流程包括知识体系需求分析、要素罗列、属性值构成体系确定。在服装知识体系构建中,主要是对服装各要素进行区分,明确各属性名称。综合国内外研究成果,发现不同研究领域的学者对产品属性的分类有一些差异,在分析产品属性与消费偏好的关系时,产品属性通常被划分为内在属性、外在属性、基础属性、表现属性和价格属性等[14-15]。文中将服装属性分为基础属性、表现属性和外在属性。把服装基础属性与用户属性结合,可以划分年龄、性别等要素,便于确定推荐服装的范围。服装由款式、色彩、面料3个要素组成[16],根据文献和专家访谈可再细分为廓形、风格等属性,作为服装表现属性。
当用户购买服装时,除了考虑其穿着偏好外,还会浏览商家信息和商品评论等内容,最终做出购买决定,在此过程中会产生服装、商家及用户之间的交互数据,得到服装外在属性,补全服装知识体系,加深服装和用户的联系。外在属性包含店铺物流、服务、评论得分等,其中商品评论由大量的文本组成,包含用户对商品的情感态度和商品特征,文中提出评论情感得分属性,对评论采用中文分词方法得到高频词后确定特征集X={x1,x2,x3,…,xn}。运用层次分析法将特征成对比较,生成判断矩阵
其中,aij表示特征xi相对于xj对评论情感得分的重要程度。
运用和积法得到特征权重α={α1,α2,α3,…αn},特征值的情感得分根据情感词库情感值进行打分,得到集合β={β1,β2,β3,…,βn}。由此可得到评论情感得分为
F=α·β┰。
(1)
式中:F为评论情感得分;α为特征权重;β为特征值的情感得分。
根据上述理论体系可得到服装属性。根据服装领域属性名称的语义关联,结合文献[3,6,14]以及淘宝电商平台与专家访谈的属性值描述,明确各项服装属性的属性值并得到三元组<服装,属性,属性值>,完成服装知识体系构建,具体如图2所示。
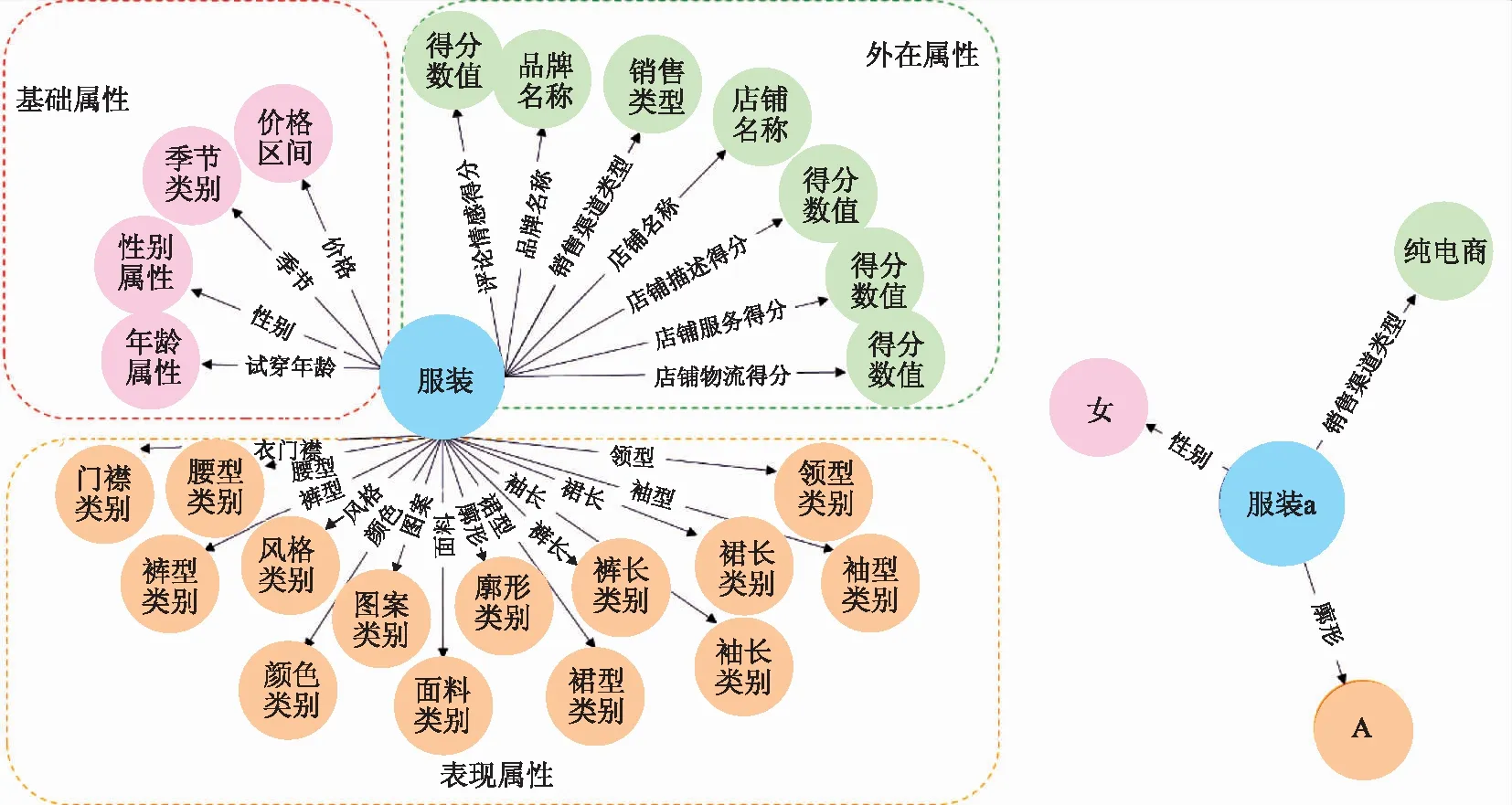
图2 服装知识体系模型Fig.2 Mode of clothing knowledge system
1.2 数据层构建
服装知识图谱的数据层是在模式层框架下描述所得,是实体和属性的关系集合。通过数据的获取、实体关系的抽取、知识的融合和存储可构建数据层知识图谱。
1.2.1服装知识图谱获取 对于网页数据的获取,可通过设置检索关键词得到相关网页,再利用网页爬虫技术获取数据[9]。依据电商平台检索习惯,将服装检索关键词分为服装类别和性别。服装分类的方法较多,文中通过文献[3,17-18]确定服装类别。服装检索关键词见表1。

表1 服装检索关键词
文中运用八爪鱼网络爬虫软件获取服装知识,选择其在淘宝平台的商品列表、详情页和在线评论采集模块进行操作,具体流程为:①点击商品列表采集模块,输入确定的服装类别关键词,如“毛衣男”,通过统一资源定位系统(uniform resource locator,URL)转至相应淘宝网页,从页面的服装商品列表中自动爬取商品ID信息;②清洗初步数据,对爬取的商品ID进行分析判断,将相同的服装去重;③点击商品详情页采集模块,导入清洗后的服装ID,通过服装链接得到详情页信息,进一步爬取服装产品参数、商家信息;④点击在线评论采集模块,输入服装ID采集评论,评论时间越近,其有用性感知越高[19],因此文中将评论时间设置为近3个月。知识获取流程如图3所示。
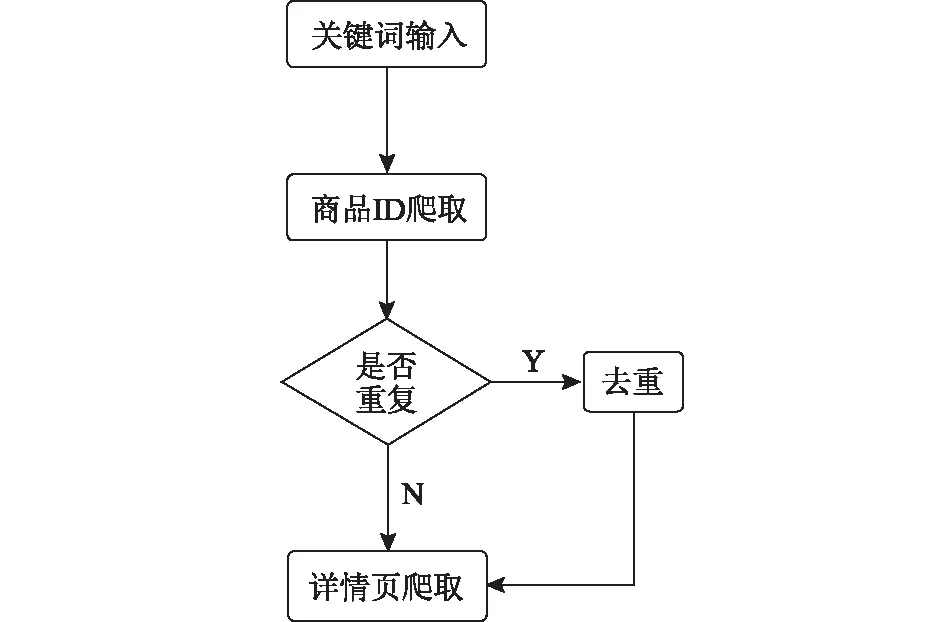
图3 知识获取流程 Fig.3 Knowledge acquisition process
1.2.2服装知识图谱抽取 知识抽取包含实体抽取和关系抽取。抽取的数据源分为结构化数据、半结构化数据和非结构化数据。
由知识抽取部分可知,淘宝平台服装详情页面中的产品参数包含属性及属性值的汇总表,是对实体的结构化总结。相较于其他两类数据源,这类结构化数据的置信度高,数据质量可靠,不易随时间改变。结构化数据可以直接从详情页面中提取实体相关的属性及属性值,简化知识抽取过程,提高工作效率。根据模式层中服装实体属性的定义,对网页中获取的知识进行关系抽取,剔除网页中的冗余信息和不相关信息,如“货号”等属性词。过滤后得到较为有效的语料,构成<服装,属性,属性值>三元组数据。
评论属于非结构化数据,处理非结构性文本一般采用基于规则的方法、基于机器学习的方法等。关系抽取的目的是获得实体间的语义关系,该过程在数据抽取中属于难点。文中通过Python语言库中的Jieba分词处理文本,在分词过程中使用停用词表,以提高文本处理效率及筛选后的高频词提取特征值的准确率。考虑到服装的特殊性,文中在采用中文停用词表、哈工大停用词表和四川大学机器智能实验室停用词库的基础上,自定义343个服装停用词,如“衣服” “穿”“上身”等。
采用汉语分词得到高频词,并对其进行分类,得到特征集合X。针对网购消费者在线评论的特征,以问卷形式向20位服装领域资深专家征询意见,并通过层次分析法得到特征值权重α。对于特征值对应的情感得分,文中使用Python中的SnowNLP语言库对情感值进行打分,分值为0~1。由于已有的服装情感词库语料不够全面,需要通过人工标注对词汇进行扩充,如增加“衣服洗了褪色”“容易皱”“会起球”等语料。为验证补充后词库情感打分的准确性,将文中验证实验得到的积极、中等、消极3种情感比例与商品评论好、中、差评的比例进行对比。
验证实验以连衣裙为对象,从淘宝爬取400件不重复商品的17 003条评论。为提高实验准确性,清除评论数不足10条的服装,最终得到379件服装,共计16 856条评论,并标记好、中、差评。将数据集以9∶1的比例划分训练集和验证集,得到的对比结果如图4所示。由图4(a)可知,积极-中等的情感分界值在0.5~0.7时,准确率和F值随着情感分界值的增加呈上升趋势;情感分界值在0.7~0.9时,准确率和F值随着情感分界值的增加呈下降趋势。由图4(b)可知,中等-消极的情感分界值在0.1~0.3时,准确率和F值与情感分界值呈正相关;情感分界值在0.3~0.6时呈负相关。因此,当情感分界值为0.7和0.3时,服装评论的准确率最高,此时F值分别为0.92和0.73,整体召回率数值较好,因而情感分类效果最优。对基于服装情感词库的SnowNLP库进行情感分析,得出积极、中等、消极情感的数量接近于实际商品评论好、中、差评的数量,分析结果准确度高,可以用于服装评论情感打分。
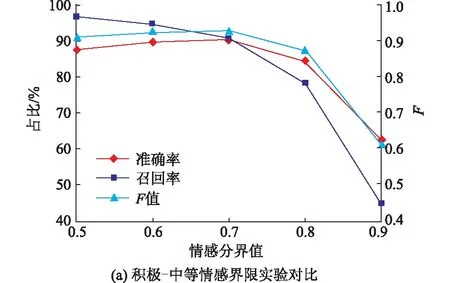
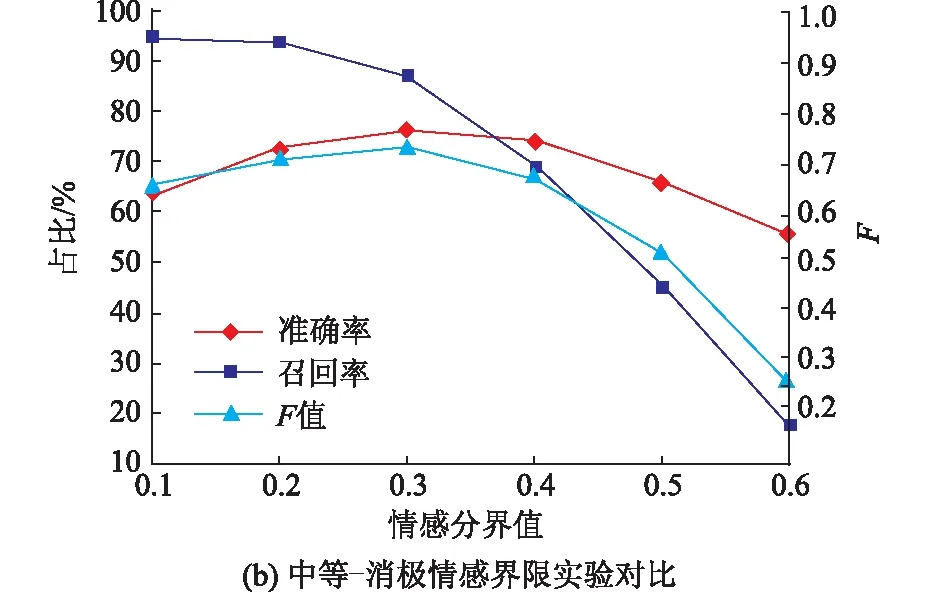
图4 不同情感界限实验结果对比Fig.4 Experimental comparison results with different emotional boundaries
1.2.3服装知识图谱融合 知识融合是通过对同类知识的融合,实现对已有知识图谱的补充、更新和去重。文中以模式层中服装知识体系的属性值为理论标准,对数据层中知识抽取得到的不规范名词属性值进行融合,从而保证知识图谱中的数据一致性和准确性。以颜色的属性值为例,杏色、柠檬黄、姜黄色属于黄色系,红色系、黄色系、橙色系属于暖色系,服装a的颜色是姜黄色,用三元组可表示为

表2 知识融合前后对比
此类融合方式在服装个性化推荐过程中可以缓解用户数据的稀疏性。例如,当用户想购买黄色服装时,则会一同推荐暖色系中的其他颜色,提高推荐结果的多样性。
1.2.4服装知识图谱存储 服装知识图谱中的知识通过资源描述框架(resource description framework,RDF)表示,在存储后运用。基于图结构的存储是知识存储的主要方式,可以利用有向图对知识图谱的数据进行建模。在图模型结构中,实体为节点,属性为带标签的边,数据在实际存储时需借助存储系统。常用的存储数据库有Neo4j,InfoGrid,InfiniteGraph等。文中运用Neo4j图形数据库存储系统将结构化数据存储在图中。Neo4j作为基于文件的数据库,在运用过程中不需要启动数据库服务器,可直接在本地进行操作,有利于加快访问速度。
2 图谱在产品单元的应用
为验证知识图谱在服装领域的可行性,文中以连衣裙为例,展示服装知识图谱的构建过程:①在模式层构建连衣裙服装知识体系,在数据层中通过淘宝平台搜索关键词“连衣裙”后爬取连衣裙数据;②重新爬取500件连衣裙ID,分别进入商品详情页和评论进行实体、属性爬取;③经过数据清洗,剩余463件连衣裙和20 657条评论,对连衣裙的评论进行分词处理得到高频词词云(见图5);④选择质量、价格、外观、物流和服务5个特征值,通过问卷法和层次分析法确定相应权重(见表3);⑤通过SnowNLP语言库对情感值打分,根据式(1)得到评论情感得分属性值;⑥对详情页进行知识抽取,得到23个属性,1 325个实体,经过知识融合后,得到23个属性,881个实体; ⑦利用Neo4j图形数据库存储系统对数据进行存储,形成连衣裙的知识图谱(见图6),知识融合所得到的实体和属性分别构成服装知识图谱的节点和边。

图5 连衣裙评论高频词词云Fig.5 High-frequency word cloud of dress comments
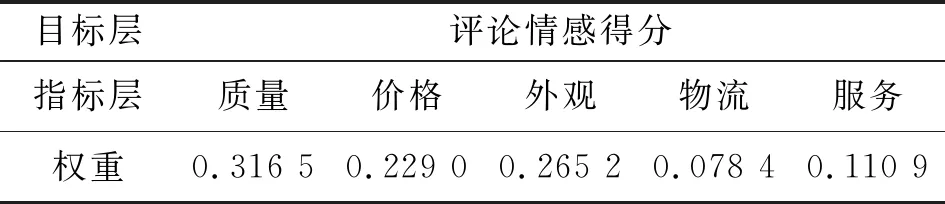
表3 连衣裙评论的特征权重
通过连衣裙的基础属性、表现属性和外在属性,可以描述服装之间的关系。以连衣裙a,b,c为例,假设用户甲购买连衣裙a,用户乙购买连衣裙b,c,则可用以下三元组表示其中的几条路径:
<用户甲,购买,cloth_a>→
<用户甲,购买,cloth_a>→
<用户甲,购买,cloth_a>→
从上述路径可以推理得到,用户甲可能会购买连衣裙b,c。由此可见,将知识图谱带入到服装推荐中,可以提高推荐结果的合理性。
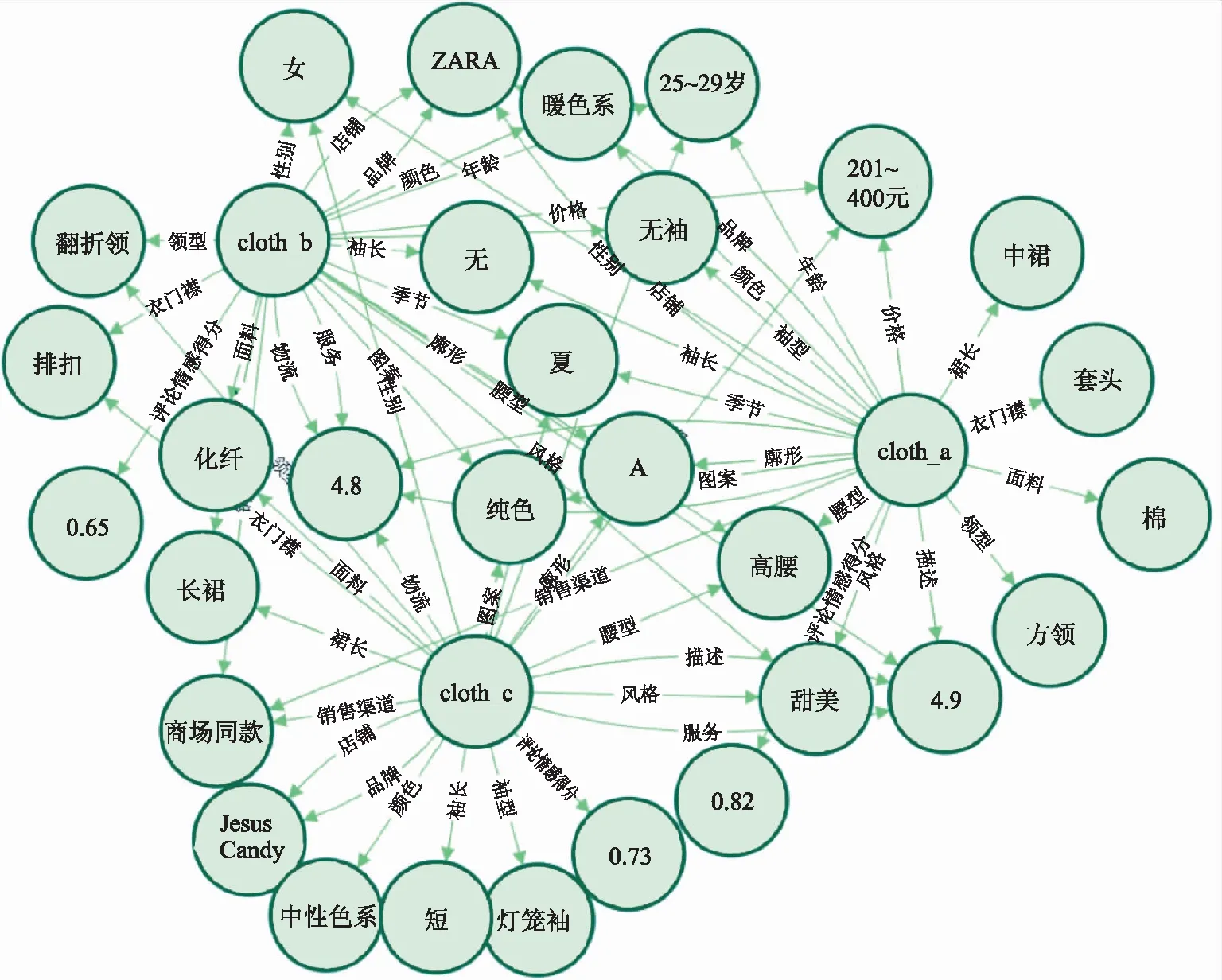
图6 连衣裙知识图谱Fig.6 Dress knowledge graph
此外,基于知识图谱的服装个性化推荐可以利用图谱中物品的语义关联内容作为辅助信息,丰富对用户和物品的描述,以此提高推荐准确性;同样也可以利用知识图谱中物品的交互数据挖掘从用户到物品的不同路径[20]。服装知识图谱的三元组表达了实体与属性间的语义关系,通过知识表示学习(knowledge representation learning,KRL)模型,将图谱中的语义关系映射到向量空间,计算服装间的相似度。常见的知识表示学习模型有距离模型、翻译模型等,其中翻译模型运用广泛[21-22],TransE模型是典型代表[23]。将三元组
(2)
相似度为
(3)
根据式(2)、式(3)计算服装间的相似度,并通过K-最近邻(K-nearest neighbor,KNN)算法选择对象,排序得到评分最高的k件相似类型服装组成推荐列表进行推荐。
3 结 语
个性化服装推荐可以提高购物效率。文中研究构建了一个能够显示服装间关系的服装领域知识图谱,将专家知识和文献研究引入服装建模,把服装属性分为基础要素、表现要素和外在要素,并将在线评论的情感分析引入服装外在属性,从而构建服装领域知识体系;通过大数据爬取服装数据后,依据知识体系构建出知识图谱。服装知识图谱点边游走路径和语义相似度可用于服装推荐,通过考虑用户和用户、用户和服装以及服装和服装之间的关系,发现用户的潜在兴趣,得到满足消费者需求和偏好的服装信息,更好地实现服装个性化推荐。未来需要进一步研究服装领域知识图谱以及基于知识图谱的新推荐技术,以提供更准确的个性化建议。
